في مجال إدارة البيانات، يشير التحليل إلى تحويل المحتوى—مثل النصوص والصور والجداول والبيانات الوصفية—إلى تنسيق قابل للاستخدام (مثل النص العادي، البيانات المنظمة، أو الصور) يمكن معالجته أو تحليله لاحقًا. لا يتضح ذلك أكثر من مجال تحليل PDF، حيث يدخل عالم التحليل، وهو عملية حيوية تحول المعلومات الخام إلى بيانات منظمة وقابلة للاستخدام. تتناول هذه الدليل الشامل تفاصيل تحليل PDF، موضحة تعريفه، ونطاق البيانات التي يمكن استخراجها، والعقبات التي يواجهها، وتطبيقاته المتعددة، ووفرة الطرق المتاحة للاستفادة من إمكانياته الكاملة. ستستكشف طرق التحليل المختلفة، مع التركيز بشكل خاص على تحليل PDF وكيف تبرز أدوات مثل AnyParser عن البقية.
فهم أداة تحليل PDF: ما هو التحليل؟
ما هو التحليل: عملية دقيقة لالتقاط البيانات
في جوهره، يشير تحليل PDF إلى عملية استخراج وتفسير البيانات من ملفات PDF (تنسيق المستندات المحمولة). نظرًا لأن ملفات PDF مصممة أساسًا للعرض بدلاً من تخزين البيانات المنظمة، فإن التحليل يتضمن تحويل المحتوى—مثل النصوص والصور والجداول والبيانات الوصفية—إلى تنسيق قابل للاستخدام (مثل النص العادي، البيانات المنظمة، أو الصور) يمكن معالجته أو تحليله لاحقًا. يتطلب التحليل تحليلًا عالي المستوى لتحديد واسترجاع عناصر معينة داخل ملف PDF، ممتدًا إلى ما هو أبعد من النصوص والصور ليشمل الخطوط، والتنسيقات، والجداول، والبيانات الوصفية. هذه العملية ليست مجرد تقنية، بل ضرورة في صناعات متنوعة مثل المالية، والقانون، واللوجستيات، والرعاية الصحية، حيث يعد إعادة استخدام المعلومات أمرًا بالغ الأهمية.
البيانات التي يمكن تحليلها من PDFs
البيانات القابلة للاستخراج من PDFs متنوعة وشاملة، بما في ذلك:
-
فقرات نصية: تسلسلات من الكلمات والرموز.
-
حقول بيانات فردية: عناصر فردية مثل التواريخ، وأرقام التتبع، والأسماء.
-
بيانات جدولية: معلومات منظمة في جداول وقوائم.
-
صور: محتوى رسومي مضمن داخل ملف PDF.
-
عناصر متقدمة: رؤوس، وأجسام، وجداول مرجعية، ومقطوعات، وبيانات وصفية، والتي تتطلب أدوات تحليل أكثر تطورًا.
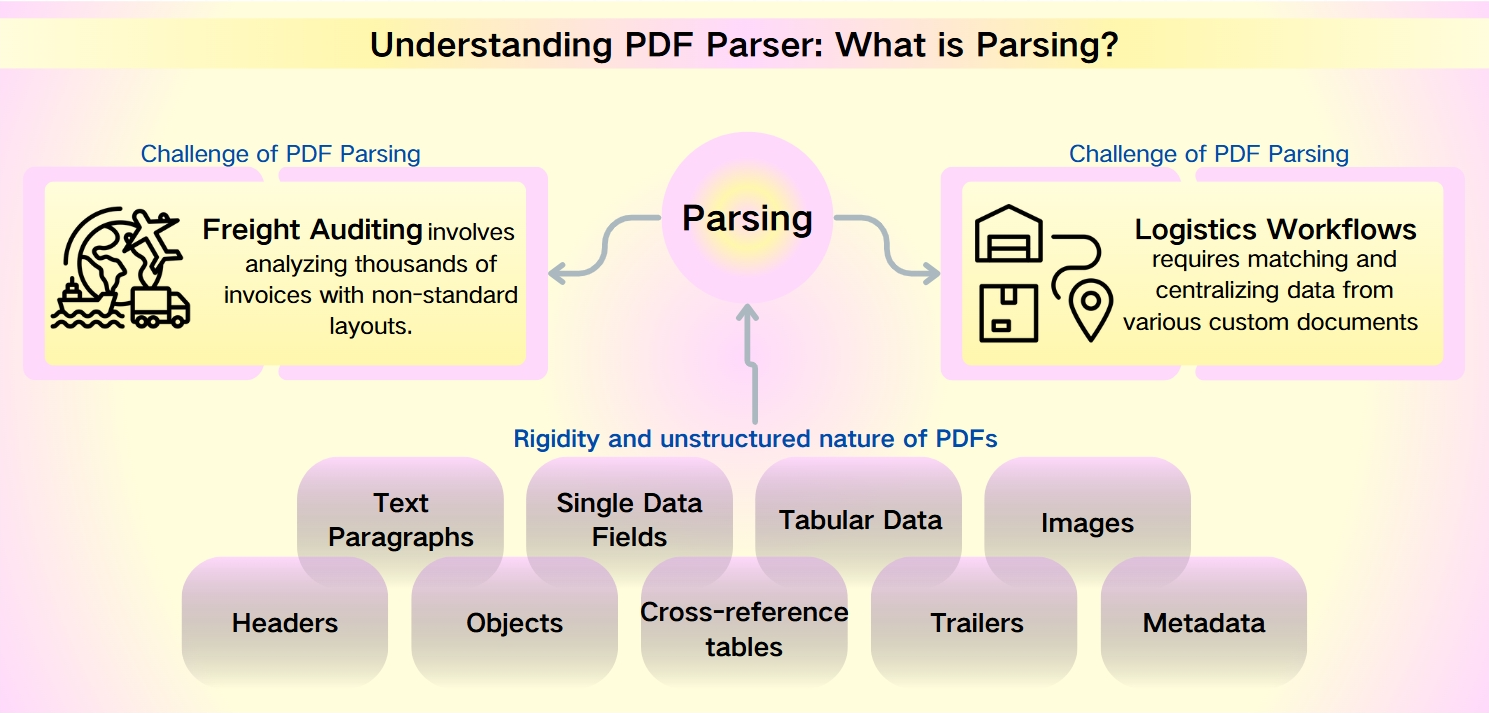
تحديات تحليل PDF: الطبيعة غير المنظمة للبيانات الوصفية في PDF
على الرغم من قوة ملفات PDF—المعروفة بأمانها، وتوافقها مع الأجهزة، وأحجام الملفات الصغيرة—إلا أن استخراج البيانات منها يمثل تحديًا كبيرًا. تعيق صلابة وطبيعة PDFs غير المنظمة التحليل السريع واسترجاع المعلومات. يتجلى ذلك بشكل خاص في سيناريوهات مثل تدقيق الشحن وتدفقات العمل اللوجستية، حيث تضيف التخطيطات غير القياسية ومجموعات البيانات الضخمة إلى التعقيد.
يتضمن تدقيق الشحن تحليل آلاف الفواتير ذات التخطيطات غير القياسية. تتطلب تدفقات العمل اللوجستية مطابقة وتجميع البيانات من مستندات مخصصة متنوعة مثل قوائم التعبئة، والفواتير التجارية، وسندات الشحن.
أهمية التحليل
يلعب التحليل دورًا حيويًا في مجالات متنوعة، من تطوير الويب إلى التقاط البيانات. يمكّن الشركات من استخراج رؤى قيمة من مصادر البيانات غير المنظمة، مثل مستندات PDF، وملفات HTML، وبيانات XML. يسهل التحليل:
-
تحسين اتخاذ القرار من خلال رؤى مستندة إلى البيانات.
-
تعزيز دقة البيانات وتناسقها.
-
تبسيط معالجة البيانات وتحليلها.
-
استرجاع المعلومات وتخزينها بكفاءة.
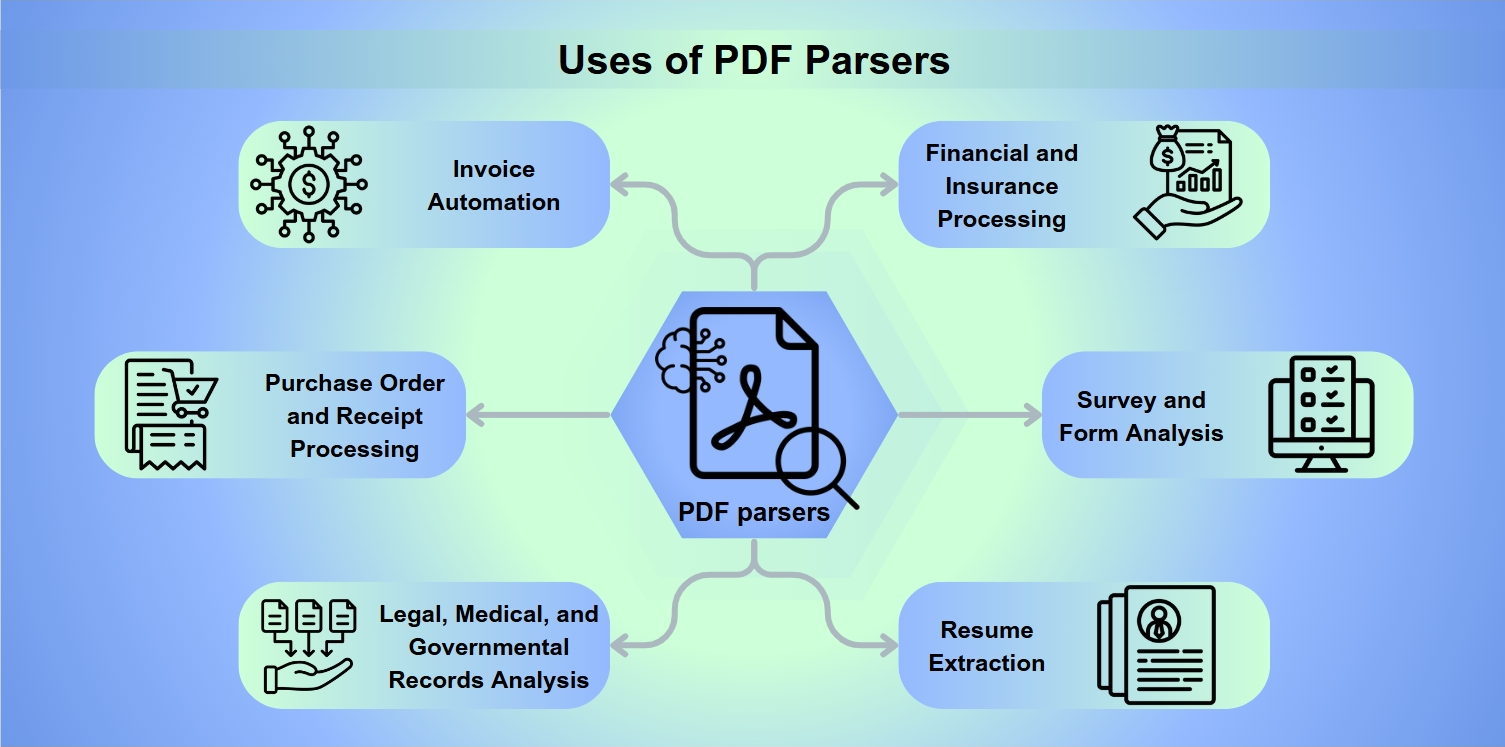
استخدامات أدوات تحليل PDF
تعد أدوات تحليل PDF أدوات لا غنى عنها في مجموعة من التطبيقات، بما في ذلك:
-
أتمتة الفواتير: تبسيط معالجة ودفع الفواتير.
-
معالجة أوامر الشراء والإيصالات: تسهيل عمليات الاسترداد والتعويضات.
-
تحليل السجلات القانونية والطبية والحكومية: تمكين استخراج البيانات المتعمق للتحليل.
-
معالجة المالية والتأمين: تقييم المخاطر وتحليل الميزانيات.
-
تحليل الاستبيانات والنماذج: جمع وتفسير ردود النماذج.
-
استخراج السير الذاتية: مساعدة المجندين في تصنيف المرشحين.
مقارنة بين طرق التحليل المختلفة
تطورت طرق تحليل البيانات بشكل كبير على مر الزمن. غالبًا ما تعتمد الطرق التقليدية لالتقاط البيانات على التعبيرات العادية (regex) لاستخراج أنماط معينة من النص. على الرغم من قوتها، يمكن أن تصبح regex معقدة وصعبة الصيانة لمهام التحليل المعقدة. تقنية شائعة أخرى هي معالجة السلاسل، والتي تتضمن تقسيم ومعالجة النص بناءً على الفواصل أو الرموز المحددة. على الرغم من أن هذه الطرق لا تزال مفيدة في بعض السيناريوهات، إلا أنها قد تواجه صعوبة مع تنسيقات البيانات غير المنظمة أو غير المتسقة.
تخدم مجموعة متنوعة من الطرق مجال تحليل PDF، كل منها له مزاياه وعيوبه الفريدة:
-
محولات/أدوات تحليل PDF عبر الإنترنت: مثل Zamzar وSmallpdf، تقدم الراحة والسرعة ولكنها محدودة في الوظائف وقد تكون غير آمنة.
-
Adobe Acrobat: تحافظ على الهيكل والتنسيق ولكن قد تتطلب تعديلات يدوية بعد التحويل.
-
النسخ واللصق: يوفر تحكمًا كاملاً ولكنه مرهق وعرضة للأخطاء.
-
المنصات الآلية: تستفيد تقنيات التحليل الحديثة مثل AnyParser من التعلم الآلي ومعالجة اللغة الطبيعية (NLP) للتعامل مع هياكل البيانات الأكثر تعقيدًا.
يمكن أن تفهم هذه الأساليب المدفوعة بالذكاء الاصطناعي السياق والدلالات، مما يجعلها فعالة بشكل خاص في تحليل النصوص غير المنظمة أو الوثائق ذات التنسيقات المتنوعة. تستخدم بعض أدوات التحليل المتقدمة نماذج التعلم العميق لتحديد واستخراج المعلومات ذات الصلة بدقة عالية، حتى من تخطيطات الوثائق غير المعروفة سابقًا.
كيفية إجراء تحليل PDF: أفضل أداة مجانية لتحليل بيانات PDF الوصفية
فهم بيانات PDF الوصفية
تحتوي بيانات PDF الوصفية على معلومات حيوية حول مستند، بما في ذلك عنوانه، ومؤلفه، وتاريخ إنشائه، والكلمات الرئيسية. يعد استخراج هذه البيانات الوصفية بكفاءة أمرًا ضروريًا لتنظيم، والبحث، وإدارة مجموعات كبيرة من ملفات PDF. يمكن لأداة تحليل PDF قوية تبسيط هذه العملية، مما يوفر الوقت ويعزز إنتاجية سير العمل.
الميزات الرئيسية لأفضل أدوات تحليل PDF
تقدم أفضل أدوات تحليل PDF المجانية مزيجًا من الدقة، والسرعة، والمرونة. يجب أن تكون قادرة على التعامل مع تنسيقات PDF المختلفة، بما في ذلك المستندات الممسوحة والتي تحتوي على تخطيطات معقدة. ابحث عن أدوات التحليل التي يمكنها استخراج ليس فقط البيانات الوصفية الأساسية ولكن أيضًا الحقول المخصصة والمعلومات المخفية. بالإضافة إلى ذلك، غالبًا ما توفر أدوات التحليل من الدرجة الأولى خيارات لاستخراج بيانات PDF لمعالجة الدفعات والتكامل مع أنظمة البرمجيات الأخرى.
ميزات AnyParser
تعتبر AnyParser، التي طورتها CambioML، جديرة بالملاحظة بشكل خاص بسبب دقتها، وخصوصيتها، وقابلية تكوينها. تجعل قدرة AnyParser على التعامل مع تنسيقات ملفات متعددة، وواجهة المستخدم سهلة الاستخدام، وقابليتها للتوسع خيارًا ممتازًا للشركات من جميع الأحجام. علاوة على ذلك، يسمح واجهة برمجة التطبيقات (API) الخاصة بها بالتكامل السلس في سير العمل الحالي، مما يعزز كفاءة إدارة الوثائق بشكل عام. إليك بعض الميزات الرئيسية التي تجعل AnyParser خيارًا ممتازًا لتحليل PDF:
-
الدقة: تم تصميم AnyParser لاستخراج النصوص، والأرقام، والرموز بدقة مع الحفاظ على التنسيق والتخطيط الأصلي. تستخدم نماذج لغوية متقدمة لتعزيز فهم الوثائق واستخراج المعلومات، حيث تتمتع بمعدل دقة يصل إلى ضعف النماذج التقليدية للتعرف الضوئي على الحروف (OCR).
-
الخصوصية: تدعم كل من تحليل البيانات المحلية والسحابية، مما يضمن بقاء المعلومات الحساسة خاصة وآمنة.
-
قابلية التكوين: يمكن للمستخدمين تخصيص قواعد الاستخراج وصيغ الإخراج لتناسب الاحتياجات المحددة.
-
دعم مصادر متعددة: تدعم AnyParser مجموعة متنوعة من أنواع الوثائق، بما في ذلك PDFs، والصور، والمخططات.
-
الإخراج المنظم: يمكن تحويل المعلومات المستخرجة إلى تنسيقات منظمة مثل Markdown، وExcel، أو JSON، مما يسهل المزيد من المعالجة والتحليل.
-
خيارات النشر السحابية: يمكن نشر AnyParser SDK في السحابة، أو مراكز البيانات، أو بشكل خاص، مما يوفر المرونة وقابلية التوسع.
-
واجهة مستخدم سهلة الاستخدام: توفر الأداة واجهة برمجة تطبيقات بسيطة تسمح بإتمام مهام تحليل الوثائق المعقدة بعدد قليل من أسطر التعليمات البرمجية.
-
أداء عالي: تضمن الخوارزميات المحسّنة معالجة سريعة لعدد كبير من الوثائق، أسرع بخمس مرات من نماذج LLM العامة مثل GPT4o.
-
دعم المجتمع: كمشروع مفتوح المصدر، تستفيد AnyParser من مجتمع نشط وترحب بالمساهمات.
-
حصة الاستخدام المجانية: تقدم AnyParser حصة استخدام مجانية مع كل حساب، مما يسمح للمستخدمين باختبار قدرات الأداة قبل الالتزام بخطة مدفوعة.
-
ملاحظات العملاء: أشاد المستخدمون بـ AnyParser لدقتها العالية، والحفاظ على الخصوصية، وكفاءتها في استخراج البيانات، مع دراسات حالة تظهر توفيرًا كبيرًا في الوقت وتحسين جودة البيانات.
تجعل هذه المزايا AnyParser أداة قيمة لاستخراج بيانات PDF لتحليل الوثائق واستخراج المعلومات، خاصة للمستخدمين في المؤسسات الذين يحتاجون إلى دقة عالية وأمان. مع التقدم التكنولوجي المستمر والمشاركة النشطة من المجتمع، من المتوقع أن تلعب AnyParser دورًا متزايد الأهمية في مجال تحليل الوثائق واستخراج المعلومات.
الشرح الفني لأدوات تحليل PDF
يتشارك تحليل PDF أرضية مفاهيمية مع استخراج البيانات من الويب، لكنه يفتقر إلى الهيكل المنظم لـ HTML. بينما يتم تحليل مستندات الويب من خلال علامات HTML القابلة للوصول، تقدم PDFs مصفوفة مسطحة من الأحرف والبكسلات، مما يتطلب خوارزميات ومكتبات أكثر تطورًا لاستخراج البيانات.
أداة تحليل PDF مقابل أداة تحليل PDF بلغة بايثون: الاختلافات الرئيسية
تعد أداة تحليل PDF غالبًا أداة مستقلة كأداة لاستخراج البيانات من PDF أو مكتبة مصممة خصيصًا لاستخراج البيانات من ملفات PDF. تقدم هذه الأدوات عادةً واجهات سهلة الاستخدام وتتطلب معرفة برمجية بسيطة. من ناحية أخرى، تعتبر أدوات تحليل PDF بلغة بايثون وحدات أو مكتبات تندمج في نصوص بايثون، مما يوفر مزيدًا من المرونة ولكنه يتطلب خبرة برمجية.
يمكن للمطورين ضبط عملية التحليل، وتنفيذ تحليل نصوص متقدم، ودمج استخراج بيانات PDF بسلاسة في تطبيقات بايثون الأوسع. بينما توفر أدوات تحليل PDF، على الرغم من كونها أكثر محدودية في التخصيص من أدوات تحليل PDF بلغة بايثون، ميزات جاهزة للاستخدام لحالات الاستخدام الشائعة، مما يجعلها مثالية للمستخدمين الذين يحتاجون إلى نتائج سريعة دون برمجة مكثفة.
مزايا AnyParser مع VLM لتحليل البيانات
-
دقة عالية: تضمن VLMs الخاصة بـ AnyParser أن استخراج البيانات يحتفظ بدقة عالية، حتى مع تخطيطات الوثائق المعقدة.
-
السرعة: تتصدر في سرعة التحويل، مما يعزز الإنتاجية من خلال تقليل الوقت اللازم لمعالجة الوثائق.
-
سهولة الاستخدام: تقدم AnyParser واجهة بسيطة، مما يجعلها متاحة للمستخدمين من جميع المستويات.
-
المرونة: بالإضافة إلى PDFs، تعمل AnyParser كأداة قوية لتحويل الصور إلى Excel، داعمة لأنواع مستندات متنوعة.
الخاتمة
يعد تحليل PDF أكثر من مجرد عملية تقنية؛ إنه بوابة لتحويل كيفية تعامل الشركات مع البيانات. على الرغم من التحديات، جعلت تطورات الحلول البرمجية الأمر أكثر سهولة من أي وقت مضى. سواء كنت تتعامل مع معالجة الفواتير أو تحليل البيانات المعقدة، فإن اختيار أداة تحليل PDF المناسبة أمر ضروري. يتعلق الأمر بالعثور على الأداة التي تقدم التوازن المثالي بين الدقة، والأمان، والكفاءة لتمكين مبادراتك المستندة إلى البيانات.
ابدأ تجربتك المجانية اليوم
هل أنت مستعد لإحداث ثورة في معالجة مستنداتك؟ جرب AnyParser مجانًا دون الحاجة إلى بطاقة ائتمان على https://www.cambioml.com/sandbox. تتيح لك التجربة المجانية معالجة ما يصل إلى 10 صفحات لكل مستند، مع حد أقصى لحجم الملف يبلغ 10 ميغابايت. عِش التجربة بنفسك كيف يمكن لأداة تحليل PDF من AnyParser أن تحول نهجك تجاه البيانات غير المنظمة واستخراج الوثائق. لا تفوت هذه الفرصة لتعزيز قدرات تحليل البيانات الخاصة بك وتبسيط سير العمل الخاص بك باستخدام تقنية الذكاء الاصطناعي الحديثة.