يمكن أن يكون تحويل ملفات PDF المعقدة إلى Markdown تحديًا. هناك العديد من المكتبات مفتوحة المصدر المتاحة لاستخراج النص من PDF، ولكن عندما يتعلق الأمر بملفات PDF التي تحتوي على عناصر معقدة مثل الجداول والرسوم البيانية، فإن النتائج غالبًا ما تكون غير مرضية. يمكن لنماذج اللغة الكبيرة الشهيرة مثل GPT أو Claude التعامل مع هذه المهام، لكنها تميل إلى أن تكون بطيئة وأحيانًا تنتج مخرجات غير دقيقة. أدوات OCR التقليدية، على الرغم من فعاليتها في الوثائق الأبسط، غالبًا ما تكافح للحفاظ على الهيكل الدقيق والمعنى الدلالي للمحتوى الأصلي. من ناحية أخرى، قد تتخيل نماذج اللغة البصرية أحيانًا، مما يؤدي إلى نتائج تحليل خاطئة. ستشرح هذه المدونة ما يعنيه التحليل وتفصل نتائج تحليل مقارن لعدة نماذج باستخدام معايير متعددة.
ماذا يعني التحليل؟
في سياق تحليل PDF، يشير "التحليل" إلى عملية استخراج بيانات محددة من ملف PDF باستخدام برنامج متخصص يعرف باسم محلل PDF. يقوم محلل PDF بتحليل محتوى مستند PDF ويحدد عناصر مثل النصوص والصور والخطوط والتنسيقات وحتى البيانات الوصفية. يمكن تنظيم البيانات المستخرجة وتصديرها إلى تنسيقات مختلفة مثل XML أو JSON أو Excel/CSV، والتي يمكن استخدامها لأغراض متعددة مثل تحليل البيانات أو حفظ السجلات أو أتمتة سير العمل.
فهم ما يعنيه التحليل أمر ضروري لتقييم فعالية حل التحليل، خاصة عند مقارنة أدوات تحويل PDF إلى Markdown، حيث يتطلب محلل PDF أكثر من مجرد استخراج نص بسيط - بل يتطلب التعرف على الهيكل الدلالي للمستند والحفاظ عليه.
كيف نقيس جودة حلول التحليل هذه؟
لقد حددنا سلسلة من المعايير على مستوى الكلمات لتقييم أداء النماذج المختلفة، مع التركيز على عوامل رئيسية مثل:
-
الدقة، الاسترجاع، ومقياس F: تقييم جودة واكتمال التحليل.
-
درجة BLEU وANLS: مفيدة لتقييم اللغة وهيكل التنسيق.
-
مسافة التحرير، تباين جنسن-شانون، ومسافة جاكارد: معايير محددة لمجال OCR، مفيدة بشكل خاص لفهم دقة إعادة إنتاج المحتوى.
تظهر نموذجنا للغة البصرية، AnyParser، أداءً استثنائيًا، حيث يجمع بين السرعة والدقة، خاصة في التنسيقات المعقدة مع الجداول والعناصر الدلالية. AnyParser يتفوق على الحلول الأخرى، حيث يقدم تحسينًا في السرعة بمقدار 20 مرة مقارنة بالنماذج مثل GPT/Claude مع تحقيق دقة أعلى.
مقارنة شاملة ضد النماذج الرائدة في التحليل
الكائن الإحصائي
لإظهار قدرات AnyParser بشكل حقيقي، أجرينا مقارنة شاملة ضد النماذج الرائدة في التحليل في الصناعة ونماذج اللغة الكبيرة المعروفة (LLMs). شمل تقييمنا:
1. نماذج اللغة الكبيرة
- AnyParser
- GPT-4o من OpenAI
- Gemini 1.5 Pro من Google
- Claude 3.5 Sonnet من Anthropic
2. خدمات قائمة على OCR
- LlamaParse
- Amazon Textract
- Google Cloud Document AI
- Azure Document Intelligence
تقديم النتائج والتحليل
التجربة 1
أولاً، نجري سلسلة من المقارنات الدقيقة لأداء نماذج الذكاء الاصطناعي المختلفة على أكثر من 5 معايير أدناه: BLEU، الدقة والاسترجاع، مقياس F وANLS. يمكنك العثور على التعريف الرياضي لهذه المعايير في الملحق.
النماذج المقارنة هي: AnyParser-base، AnyParser-pro، Textract، Llama-Parse، GPT4o، Gemini-1.5-pro، GCP-DocAl، وAzure-DocAl.
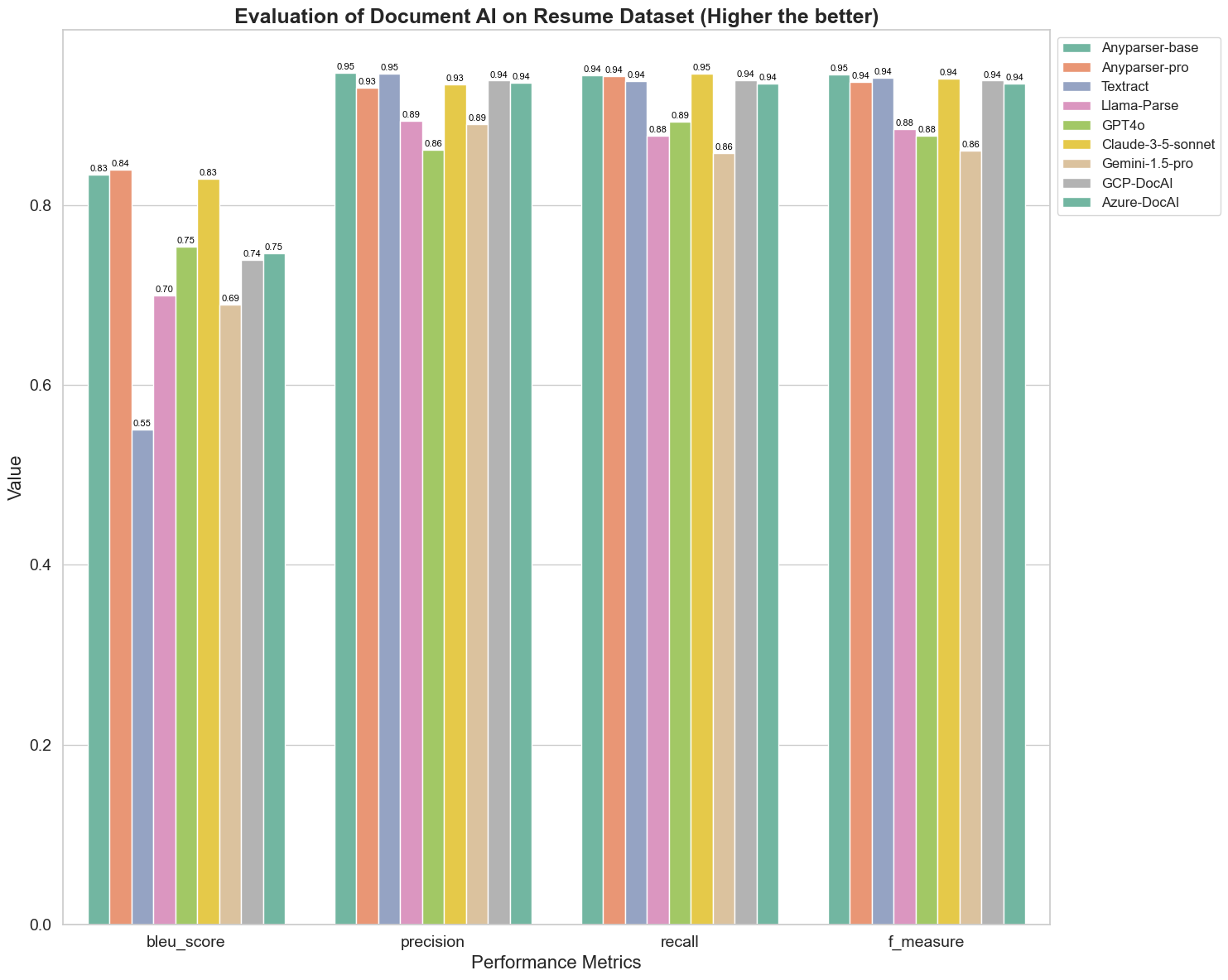
تستخدم درجة BLEU كتقييم لجودة الترجمة الثنائية لاختبار جودة النماذج في معالجة العبارات. من خلال مقارنة نتائج هذه النماذج التحليلية تحت طريقة تقييم BLEU، نجد أن: درجات AnyParser-base وAnyParser-pro أعلى بكثير من درجات النماذج الأخرى، بينما سجل Amazon Textract أدنى درجة، وكانت نتائج درجات النماذج الأخرى في منتصف مستوى متوسط نسبيًا.
عادة ما يتم تمثيل دقة التعرف بواسطة الدقة والاسترجاع، حيث تمثل الدقة النسبة المئوية للنتائج الصحيحة حقًا من بين النتائج التي حكم عليها النموذج بأنها صحيحة، وتمثل الاسترجاع النسبة المئوية للنتائج الصحيحة التي حكم عليها النموذج من بين جميع النتائج الصحيحة فعليًا. من خلال مقارنة الدقة والاسترجاع لهذه النماذج التحليلية، نجد أن: باستثناء Llama-Parse، GPT4o وGemini-1.5-pro، جميع النماذج الأخرى في مستوى عالٍ. من بينها، تبرز AnyParser وAmazon Textract أكثر في الدقة، بينما تبرز AnyParser-base وAnyParser-pro أكثر في الاسترجاع. تشير الدرجة الأعلى للنموذج في الدقة إلى أن النموذج ينتج معلومات صحيحة أكثر في النتائج، وتشير الدرجة الأعلى في الاسترجاع إلى أن النموذج أكثر قدرة على الحصول على معلومات صحيحة من العينة. تظهر نتائج الدرجات أن AnyParser لديه ميزة واضحة من حيث دقة التعرف لاستخراج النص من PDF.
مقياس F هو مؤشر تقييم شامل للدقة والاسترجاع على هذين المؤشرين. من خلال مقارنة درجات هذه النماذج التحليلية تحت مقياس F، يمكننا أن نرى بشكل أكثر وضوحًا أن النماذج الخمسة، AnyParser-base، AnyParser-pro، Amazon Textract، GCP-DocAI وAzure-DocAI، لديها قوة أفضل من حيث دقة التعرف مقارنة بالنماذج الأخرى. يمكننا أن نرى بشكل أكثر وضوحًا أن النماذج الخمسة لديها قوة أكبر في دقة التعرف من النماذج الأخرى، وAnyParser لديه أعلى درجة تحت مقياس F، مما يوضح بشكل أكبر الميزة الواضحة لـ AnyParser في دقة التعرف لاستخراج النص من PDF.
ANLS، كمؤشر تقييم شائع عند قياس الدقة والتشابه بين النص الأصلي والنص المستهدف على مستوى الحرف، هو أيضًا مفيد جدًا لقياس مستوى التحليل للنماذج. تعكس الدرجات الأعلى لـ AnyParser-base وAnyParser-pro وAzure-DocAI مستوى التحليل الأعلى لهذه النماذج مقارنة بالنماذج الأخرى.
بشكل عام، يتفوق AnyParser-base وAnyParser-pro على النماذج الأخرى.
التجربة 2
نقارن أيضًا أداء نماذج الذكاء الاصطناعي المختلفة على ثلاثة معايير مختلفة: مسافة التحرير، تباين جنسن-شانون، ومسافة جاكارد. تُستخدم المعايير لقياس التشابه بين مخرجات النماذج ومستند مرجعي. تشير القيم الأقل إلى أداء أفضل.
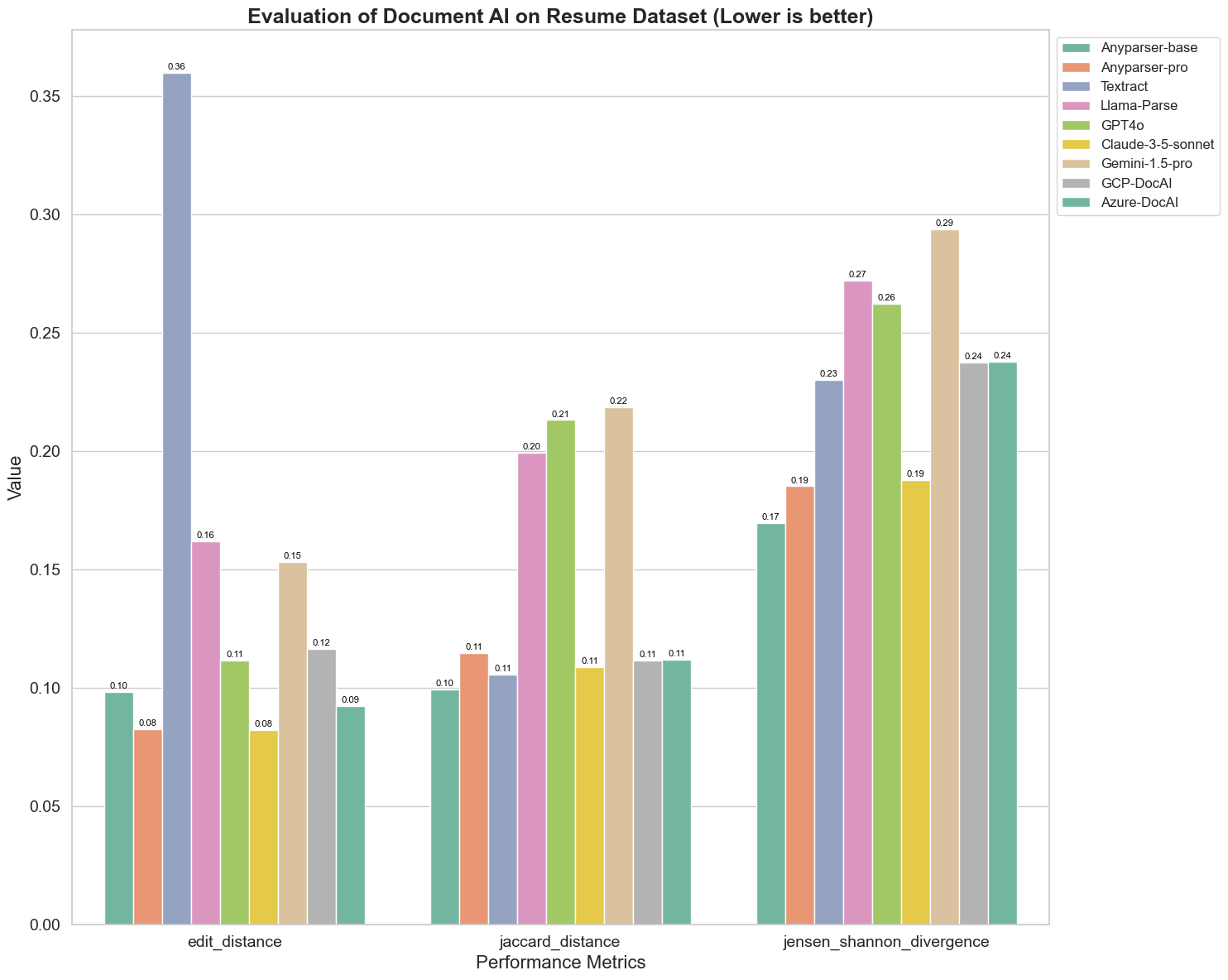
إليك بعض الملاحظات الرئيسية من الرسم البياني:
-
مسافة التحرير: النماذج AnyParser-base وAnyParser-pro تحقق الأداء الأفضل بأقل مسافة تحرير، مما يشير إلى أن مخرجاتها كانت الأقرب إلى المستند المرجعي.
-
تباين جنسن-شانون: النماذج AnyParser-base وAnyParser-pro لديها أقل تباين، مما يعني أن مخرجاتها هي الأكثر تشابهًا مع المستند المرجعي من حيث توزيع الكلمات.
-
مسافة جاكارد: بخلاف Llama-parse، GPT4O، Gemini-1.5، جميع النماذج الأخرى تؤدي بشكل جيد مع أقل مسافة جاكارد، مما يشير إلى أن مخرجاتها لديها أعلى تداخل مع المستند المرجعي من حيث مجموعة الكلمات المستخدمة.
الخاتمة
بشكل عام، تشير اختباراتنا الدقيقة إلى أن AnyParser-base وAnyParser-pro تؤدي بشكل جيد عبر معايير مختلفة، مما يدل على إمكانياتها في معالجة الوثائق بدقة. من الرسوم البيانية، يمكننا أن نرى أن نماذج OCR التقليدية مثل Amazon Textract الشهير تسجل درجات أقل بكثير من نماذج اللغة البصرية. ومع ذلك، يختلف أداء النماذج المختلفة اعتمادًا على المعيار المستخدم، مما يبرز أهمية النظر في معايير تقييم متعددة عند مقارنة نماذج الذكاء الاصطناعي.
تقديم خط أنابيب التقييم مفتوح المصدر الخاص بنا
لتبسيط التقييمات، أنشأنا خط أنابيب تقييم يوفر طريقة قياسية في الصناعة لمقارنة نماذج التحليل. في مثالنا، نظهر استخدامه في مجال الموارد البشرية، حيث يكون تحليل السيرة الذاتية شائعًا. قمنا ببناء مجموعة بيانات اصطناعية متنوعة من 128 سيرة ذاتية، تم إنشاؤها باستخدام ملفات صورة-Markdown مزدوجة. باستخدام GPT-4، قمنا بإنشاء محتوى HTML، وتحويله إلى صور، واستخدمنا النص المستخرج كحقيقة مرجعية للمقارنة.
وإليك الجزء الأفضل: لقد جعلنا هذا الإطار التقييمي مفتوح المصدر على GitHub! سواء كنت مطورًا أو مستخدمًا تجاريًا، يتيح لك خط الأنابيب الخاص بنا تقييم ومقارنة جودة التحليل لنماذج مختلفة على مجموعة بياناتك الخاصة.
ابحث عن دليل البدء السريع في مستودع GitHub وانظر كيف تتراكم نماذج التحليل المختلفة ضد بعضها البعض. نعتقد أنه من خلال عرض قوة نموذجنا في العلن، يمكننا جذب المزيد من المستخدمين الذين يرغبون في قدرات تحليل موثوقة وسريعة ودقيقة.
الملحق - المعايير
1. الدقة
تقيس الدقة دقة المحتوى المحلل، موضحة كم عدد العناصر المسترجعة كانت صحيحة. في التحليل، هي النسبة المئوية للكلمات المستخرجة بشكل صحيح من بين جميع الكلمات المستخرجة.
الدقة = الإيجابيات الحقيقية (TP) / (الإيجابيات الحقيقية (TP) + الإيجابيات الكاذبة (FP))
- الإيجابيات الحقيقية (TP): الكلمات التي تم التعرف عليها بشكل صحيح بواسطة المحلل.
- الإيجابيات الكاذبة (FP): الكلمات التي تم التعرف عليها بشكل غير صحيح بواسطة المحلل.
2. الاسترجاع
يشير الاسترجاع إلى اكتمال التحليل، أو كم عدد الكلمات ذات الصلة من الوثيقة الأصلية تم استرجاعها.
الاسترجاع = الإيجابيات الحقيقية (TP) / (الإيجابيات الحقيقية (TP) + السلبيات الكاذبة (FN))
- السلبيات الكاذبة (FN): الكلمات في الوثيقة الأصلية التي فاتت على المحلل.
3. مقياس F (درجة F1)
درجة F1 هي المتوسط التوافقي للدقة والاسترجاع، مما يوازن بين كلا المقياسين لتقديم مقياس شامل لجودة التحليل.
درجة F1 = 2 × (الدقة × الاسترجاع) / (الدقة + الاسترجاع)
4. درجة BLEU (تقييم ثنائي اللغة)
تقيس درجة BLEU التشابه بين المحتوى المحلل والنص الأصلي، مع التركيز بشكل خاص على ترتيب الكلمات. إنها مفيدة بشكل خاص لتقييم التناسق في اللغة والبنية في الوثائق المحللة، حيث تعاقب المخرجات التي تختلف في التسلسل عن الأصل.
5. ANLS (متوسط التشابه المعدل ليفنشتاين)
يقيس ANLS التشابه بين المحتوى المحلل والأصلي، باستخدام مسافة التحرير المعدلة. يتم حسابه من خلال متوسط التشابه المعدل ليفنشتاين (NLS) لكل زوج من الكلمات في النصوص المحللة والمرجعية. يتم حساب NLS كما يلي:
NLS = 1 - (مسافة ليفنشتاين (LD)(الكلمة المحللة، الكلمة الأصلية)) / max(طول الكلمة المحللة، طول الكلمة الأصلية)
ثم، يكون ANLS هو متوسط NLS عبر جميع أزواج الكلمات:
ANLS = (1/N) × Σ(NLS_i) لـ i=1 إلى N
6. مسافة التحرير
تحسب مسافة التحرير عدد العمليات على مستوى الكلمات (الإضافات، الحذف، الاستبدالات) المطلوبة لتحويل النص المحلل إلى الأصل.
7. تباين جنسن-شانون
يقيس تباين جنسن-شانون التشابه بين توزيعات الاحتمالات المنفصلة لعدد الكلمات المحللة والأصلية، مما يبرز الاختلافات في تكرار الكلمات.
JSD(P || Q) = (1/2) × KL(P || M) + (1/2) × KL(Q || M)
حيث M = (1/2)(P + Q)، وKL(P || Q) هو تباين كولباك-ليبلر
8. مسافة جاكارد
تقيس مسافة جاكارد عدم التشابه بين مجموعات الكلمات في المحتوى المحلل والأصلي، وهي مفيدة لتقييم تداخل الكلمات.
مسافة جاكارد = 1 - |A ∩ B| / |A ∪ B|
حيث |A ∩ B| هو عدد العناصر المشتركة بين A و B،
و|A ∪ B| هو العدد الإجمالي للعناصر الفريدة في كلا المجموعتين.