Introduktion
Tabeller er en hjørnesten i struktureret datarepræsentation og anvendes bredt i industrier som finans, sundhed og forskning. Dog er det en udfordring at udtrække tabelinformation fra formater som PDF-filer, scannede dokumenter eller billeder på grund af varierende layout og kompleksitet.
Kunstig intelligens (AI) har revolutioneret dokumentbehandling og muliggør nøjagtige og effektive løsninger på problemer som hvordan man udtrækker en tabel fra en PDF eller konverterer en tabel-PNG til strukturerede data. Ved at udnytte avancerede AI-teknikker kan virksomheder nu nemt transformere ustrukturerede visuelle elementer til handlingsorienterede indsigter, herunder at konvertere et billede til en tabel for problemfri integration i arbejdsgange.
Denne blog udforsker, hvordan AI tabeludtrækning styrker industrier, fremhæver de underliggende teknologier og viser dens potentiale til at forenkle komplekse dokumentbehandlingsopgaver.

Udfordringer ved Traditionel Tabeludtrækning
Manuel udtrækning af tabeldata fra dokumenter som PDF-filer eller billeder er tidskrævende, fejlbehæftet og ineffektiv. Nedenfor er nogle af de almindelige udfordringer, der opstår med traditionelle metoder:
-
Komplekse Tabelstrukturer: Tabeller har ofte uregelmæssige layout, såsom indlejrede celler, flerlagsoverskrifter eller sammenlagte rækker, som er svære at fortolke. Traditionelle værktøjer fejler i at udtrække tabeller fra PDF i sådanne scenarier.
-
Diverse Formater: Tabeller vises i en bred vifte af formater, herunder scannede dokumenter, tabel-PNG-filer og PDF-filer. At udtrække data fra disse kræver avancerede genkendelsesteknikker, der går ud over simpel OCR.
-
Kontekst og Betydning: Traditionelle systemer har svært ved at bevare forholdet mellem rækker og kolonner, hvilket er afgørende, når man konverterer et billede til en tabel eller behandler store datasæt.
Disse udfordringer understreger behovet for intelligente løsninger som AI-drevet tabeludtrækning, der kan håndtere komplekse layout og diverse formater, samtidig med at de sikrer høj nøjagtighed.
Hvad Er AI Tabeludtrækning?
AI tabeludtrækning er anvendelsen af intelligente dokumentbehandlingsteknikker skræddersyet til at identificere, udtrække og organisere strukturerede data fra tabeller i forskellige dokumentformater. I modsætning til traditionelle regelbaserede metoder udnytter AI-drevne tilgange avancerede teknologier til at tackle komplekse udfordringer, såsom ikke-standardiserede layout, sammenlagte celler og flerlagsoverskrifter.
Et centralt fremskridt inden for dette område er brugen af Vision-Language Models (VLM'er). VLM'er kombinerer styrkerne fra computer vision og naturlig sprogforståelse, hvilket gør dem i stand til at fortolke både visuelle og tekstlige elementer inden for et dokument. Denne dobbelte kapacitet gør det muligt for VLM'er at:
- Identificere tabelstrukturer visuelt, selv når de mangler eksplicit formatering.
- Forstå indholdet kontekstuelt, såsom at skelne mellem overskrifter, data og noter.
- Tilpasse sig forskellige dokumenttyper, herunder scannede billeder, PDF-filer og håndskrevne noter.
Ved at udnytte VLM'er er AI tabeludtrækning blevet mere nøjagtig og alsidig, i stand til at håndtere flersprogede dokumenter og udtrække relationer mellem datapunkter, som traditionelle metoder ofte overser.
Nøgleteknologier Bag AI Tabeludtrækning
AI tabeludtrækning er afhængig af en række avancerede teknologier, der arbejder i harmoni for at overvinde traditionelle udfordringer. Blandt disse skiller Vision-Language Models (VLM'er) sig ud som en transformativ innovation. Nedenfor er en opdeling af nøgleteknologier og den centrale rolle, som VLM'er spiller:
-
Optisk Tegngenkendelse (OCR): Udtrækker tekst fra billeder eller scannede dokumenter. Når det kombineres med VLM'er, forbedres OCR-resultaterne, fordi modellerne forstår både den visuelle struktur og den tekstlige betydning.
-
Vision-Language Models (VLM'er): VLM'er revolutionerer tabeludtrækning ved at integrere visuel og sproglig databehandling. De excellerer i:
- At genkende komplekse tabel-layouts og uregelmæssige grænser.
- At fortolke relationer mellem rækker, kolonner og overskrifter.
- At håndtere tabeller i forskellige formater, herunder billeder og PDF-filer, med flersproget support. VLM'er muliggør en dybere kontekstuel forståelse, hvilket sikrer, at de udtrukne data bevarer deres oprindelige betydning og struktur.
-
Naturlig Sprogbehandling (NLP): Analyserer og organiserer de udtrukne data, hvilket sikrer semantisk sammenhæng. VLM'er forbedrer yderligere NLP ved at give kontekstuelle ledetråde fra visuelle mønstre.
-
Deep Learning Algoritmer: Træner modeller til at opdage tabelgrænser, cellehierarkier og mønstre i ustrukturerede dokumenter. Når de beriges af VLM'er, opnår disse algoritmer større præcision og tilpasningsevne.
Ved at fremhæve VLM'er er AI tabeludtrækning gået fra en opgave med simpel dataudtrækning til en med kontekstuel forståelse, hvilket gør den uvurderlig for industrier, hvor nøjagtighed og nuancer er afgørende.
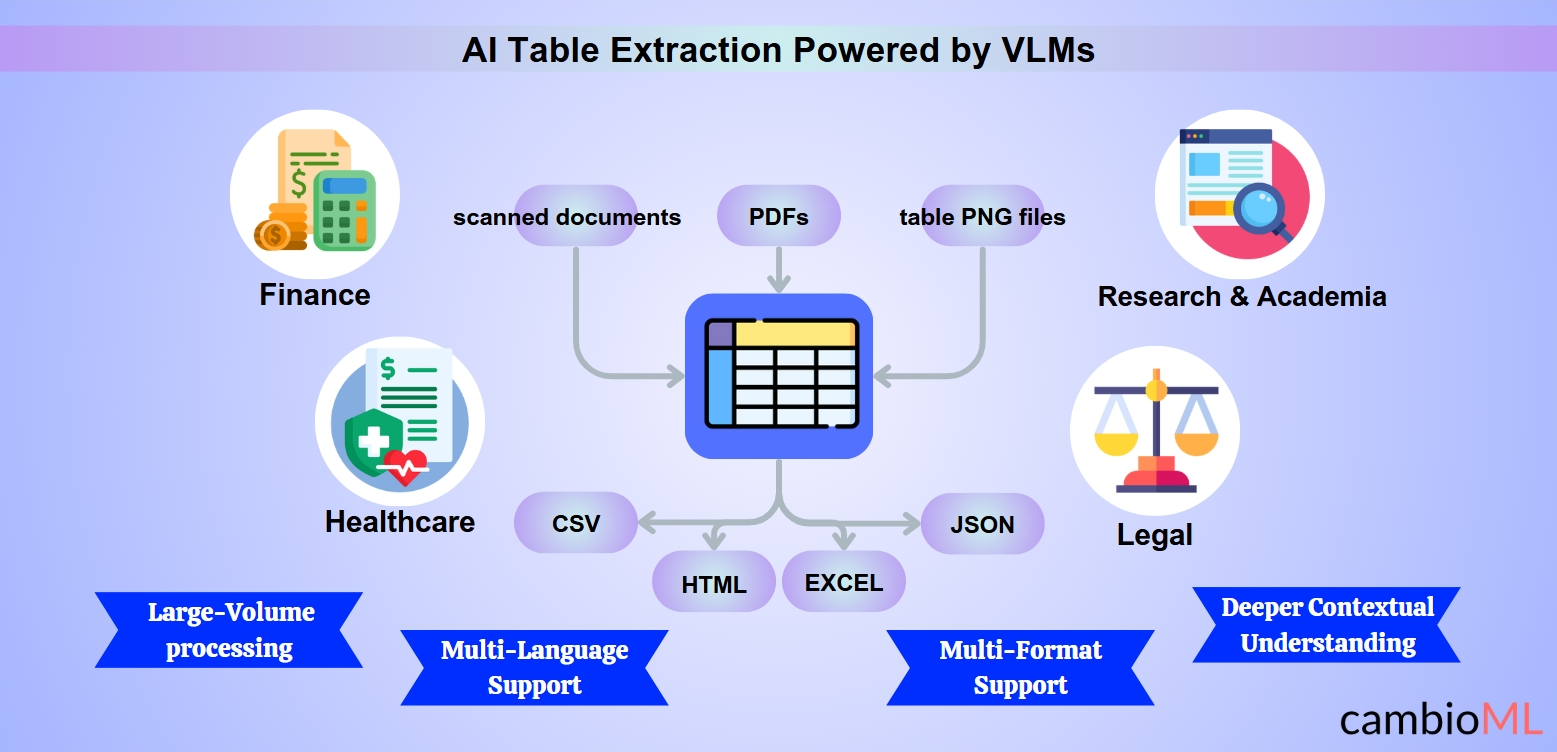
Anvendelsesområder for AI Tabeludtrækning
AI-drevet tabeludtrækning transformerer industrier ved at automatisere processen med at udtrække og organisere tabeldata fra forskellige dokumentformater. Nedenfor er nogle bemærkelsesværdige anvendelsesområder, hvor intelligent tabeludtrækning har vist sig uvurderlig:
-
Finans: At udtrække strukturerede data fra finansielle erklæringer, fakturaer og rapporter er ofte en arbejdsintensiv opgave. AI gør det problemfrit at kopiere PDF-tabel til Excel, hvilket muliggør hurtigere afstemning, analyse og rapportering.
-
Sundhed: Organisering af kliniske forsøgsresultater, patientjournaler eller medicinske forskningsdata er forenklet. For eksempel kan sundhedsudbydere nemt kopiere tabel fra en PDF til Excel, hvilket sikrer, at data er klar til integration i elektroniske sundhedsregistre (EHR).
-
Jura: At analysere kontrakter og udtrække strukturerede klausuler fra indlejrede tabeller hjælper juridiske teams med at arbejde mere effektivt. AI-modeller gør det ligetil at kopiere PDF-tabel til Excel, hvilket sparer tid på overholdelseskontroller og retssagsforskning.
-
Forskning og Akademia: Forskere kan hurtigt udtrække data fra videnskabelige artikler, hvilket forenkler opgaven med at overføre nøglemetrikker ved at bruge værktøjer til at kopiere tabel fra PDF til Excel, hvilket gør datasæt klar til statistisk analyse.
AI tabeludtrækningens evne til nøjagtigt at behandle forskellige dokumentformater revolutionerer arbejdsgange, hvilket gør det lettere at kopiere, organisere og analysere tabeldata i Excel-ark.
Fordele ved Intelligent Tabeludtrækning
AI tabeludtrækning tilbyder en række fordele, især med hensyn til at forbedre effektiviteten, nøjagtigheden og skalerbarheden. Ved at udnytte avancerede teknologier, herunder Vision-Language Models (VLM'er), kan virksomheder overvinde traditionelle udfordringer i tabeludtrækning:
-
Automatisering og Tidsbesparelser: Gentagne opgaver som manuelt at kopiere tabeller fra PDF til Excel elimineres, hvilket giver medarbejdere mulighed for at fokusere på aktiviteter med højere værdi.
-
Forbedret Nøjagtighed: AI-modeller reducerer betydeligt fejl, der er almindelige, når brugere manuelt kopierer PDF-tabel til Excel eller stoler på grundlæggende værktøjer. Disse modeller sikrer, at data bevarer sin struktur og betydning.
-
Skalerbarhed til Storskala Behandling: AI-værktøjer er designet til at håndtere bulkdataudtrækning. Uanset om det er finansielle optegnelser, forskningsdokumenter eller overholdelsesfiler, forenkler de processen med at udtrække og organisere data i Excel.
-
Multi-Format og Multi-Sprog Support: Intelligente systemer kan behandle dokumenter i forskellige formater og sprog, hvilket muliggør problemfri udtrækning og kopiering af tabel fra PDF til Excel, selv i komplekse, flersprogede sammenhænge.
AI tabeludtrækning strømline ikke kun arbejdsgange, men sikrer også dataintegritet i konteksten, hvilket transformerer, hvordan industrier håndterer tabelinformation. Denne effektivitet er kritisk i dagens datadrevne verden, hvor hurtig og nøjagtig behandling af tabeldata er en konkurrencefordel.
Håndtering af Multi-Format og Multi-Sprog Udfordringer
Moderne AI-løsninger excellerer i at tackle variabiliteten af formater og sprog, hvilket sikrer konsekvent nøjagtighed og effektivitet på tværs af forskellige datasæt:
-
Multi-Format Kapaciteter: AI-drevne værktøjer kan ubesværet behandle PDF-filer, scannede dokumenter og billedfiler som tabel-PNG. Denne alsidighed er især kritisk, når brugere har brug for at udtrække tabel fra PDF eller konvertere et billede til tabel til analyse og rapportering.
-
Multi-Sprog Support: AI-modeller er trænet på flersprogede datasæt, hvilket gør dem i stand til at håndtere dokumenter på forskellige sprog. Denne funktion er uvurderlig for globale industrier, der beskæftiger sig med international dokumentation.
-
Bevarelse af Datarelationer: Uanset om man behandler et billede til tabel eller udtrækker en kompleks struktur fra en PDF, sikrer AI-systemer, at overskrifter, rækker og kolonner bevares, hvilket opretholder dataintegriteten.
Ved at tackle disse udfordringer har AI-løsninger etableret sig som uundgåelige værktøjer for organisationer, der håndterer storskala, flersprogede og multi-format dokumentation.
Fremtiden for AI i Tabeludtrækning
Fremtiden for AI tabeludtrækning ser lys ud, med fremskridt, der vil forbedre dens kapaciteter yderligere:
-
Forbedrede Vision-Language Models (VLM'er): Nye VLM-teknologier vil give endnu mere sofistikerede måder at udtrække tabel fra PDF og konvertere komplekse tabel-PNG-formater til strukturerede data. Disse modeller vil bygge bro over kløften mellem visuelle elementer og tekstforståelse.
-
Integration med Generativ AI: Ved at integrere generativ AI kan fremtidige løsninger ikke kun udtrække tabel fra PDF eller billeder, men også analysere de udtrukne data for indsigter, resuméer og anbefalinger.
-
End-to-End Automatisering: AI-drevne værktøjer vil strømline arbejdsgange ved automatisk at konvertere filer, såsom at transformere et billede til tabel, kategorisere data og direkte fodre det ind i analysepipelines.
-
Bredere Tilgængelighed: AI-systemer vil blive mere brugervenlige og tilgængelige, hvilket gør det muligt for selv ikke-tekniske brugere at behandle tabel-PNG-filer eller udtrække data ubesværet.
AI tabeludtrækning er klar til at redefinere dokumentbehandling, hvilket gør dataudtrækning hurtigere, smartere og mere tilpasningsdygtig til udviklende industri behov. Virksomheder, der adopterer disse løsninger, vil opnå en konkurrencefordel i at håndtere og udnytte deres data effektivt.
AnyParser: En Spilændrende Løsning i Dokumentbehandling og Tabeludtrækning
AnyParser er i frontlinjen af intelligent dokumentbehandling og tilbyder virksomheder en effektiv og pålidelig måde at udtrække data fra selv de mest komplekse dokumenter. Dens avancerede kapaciteter er især tydelige, når det kommer til tabeludtrækning, hvilket sikrer præcis og skalerbar datacapture for forskellige industrier.
Nøglefordele ved AnyParser til Tabeludtrækning
-
Omfattende Format Support: Uanset om man arbejder med PDF-filer, billeder eller andre filtyper, forenkler AnyParser datacapture ved nøjagtigt at udtrække tabelinformation uanset format.
-
Høj Præcision og Kontekstuel Forståelse: I modsætning til traditionelle værktøjer bevarer AnyParser strukturen, relationerne og konteksten af tabeldata, hvilket leverer resultater klar til analyse og integration.
-
AI-Drevet Effektivitet: Drevet af Vision-Language Models (VLM'er) excellerer AnyParser i flersprogede og multi-format miljøer, hvilket sikrer problemfri datacapture i stor skala.
-
Tilpasselige Arbejdsgange: Platformen tilpasser sig dine unikke behov, uanset om du udtrækker finansielle tabeller, sundhedsoptegnelser eller forskningsdata.
Med AnyParser kan virksomheder optimere deres processer, minimere fejl og spare tid ved at automatisere den komplekse opgave med at udtrække tabeller til struktureret datacapture.
Konklusion
AI-drevet tabeludtrækning har redefineret, hvordan virksomheder behandler og udnytter strukturerede data. Uanset om opgaven er at udtrække tabeller fra PDF-filer, behandle billeder eller opnå nøjagtig datacapture, gør værktøjer som AnyParser det lettere end nogensinde at transformere ustrukturerede dokumenter til handlingsorienterede indsigter. AnyParser er din betroede løsning til at forenkle dokumentbehandling og levere uovertruffen nøjagtighed og effektivitet. Med sin evne til at håndtere forskellige formater og kontekster, giver AnyParser organisationer mulighed for at automatisere deres arbejdsgange og låse op for det fulde potentiale af deres data.
Call to Action
Hvorfor vente med at opleve næste niveau af dokumentbehandling? Lås op for det fulde potentiale af AnyParser ved at prøve dets funktioner i et praktisk miljø!
Klik på linket nedenfor for at komme ind i Sandbox, hvor du kan udforske, hvordan det forenkler:
- Nøjagtig datacapture fra PDF-filer og billeder.
- Problemfri udtrækning af tabeller til integration i analysetools.
- Pålidelig ydeevne på tværs af komplekse og store datasæt.
Gå ikke glip af chancen for at se, hvordan AnyParser kan revolutionere dine arbejdsgange. Test det i dag og opdag, hvor ubesværet dokumentbehandling og tabeludtrækning kan være!