I datahåndteringens verden involverer parsing konvertering af indhold—såsom tekst, billeder, tabeller og metadata—til et brugbart format (f.eks. almindelig tekst, strukturerede data eller billeder), der kan behandles eller analyseres yderligere. Intet er dette mere tydeligt end i domænet for PDF parsing, hvor parsing er en afgørende proces, der transformerer rå information til strukturerede, brugbare data. Denne omfattende guide dykker ned i nuancerne af PDF parsing, forklarer dens definition, spektret af data, den kan udtrække, de udfordringer, den står overfor, dens mangeartede anvendelser og de mange metoder, der er tilgængelige for at udnytte dens fulde potentiale. Du vil udforske forskellige parsingmetoder med særlig fokus på PDF parsing og hvordan værktøjer som AnyParser skiller sig ud fra mængden.
Forståelse af PDF Parser: Hvad er Parsing?
Hvad er parsing: omhyggelig datafangstproces
I sin kerne refererer PDF parsing til processen med at udtrække og fortolke data fra PDF (Portable Document Format) filer. Da PDF'er primært er designet til visning snarere end struktureret datalagring, involverer parsing konvertering af indhold—såsom tekst, billeder, tabeller og metadata—til et brugbart format (f.eks. almindelig tekst, strukturerede data eller billeder), der kan behandles eller analyseres yderligere. Parsing indebærer en høj-niveau analyse for at pinpoint og hente specifikke elementer inden for en PDF, der strækker sig ud over blot tekst og billeder til at omfatte skrifttyper, layouts, tabeller og metadata. Denne proces er ikke blot en teknikalitet, men en nødvendighed i industrier så forskellige som finans, jura, logistik og sundhedsvæsen, hvor genbrug af information er altafgørende.
Data der kan parses fra PDFs
De data, der kan udtrækkes fra PDFs, er varierede og omfattende, herunder:
-
Tekstafsnit: Sekvenser af ord og tegn.
-
Enkeltdatafelter: Individuelle elementer som datoer, sporingsnumre og navne.
-
Tabeldata: Information organiseret i tabeller og lister.
-
Billeder: Grafisk indhold indlejret i PDF'en.
-
Avancerede elementer: Overskrifter, objekter, krydsreferencetabeller, trailers og metadata, som kræver mere sofistikerede parsingværktøjer.
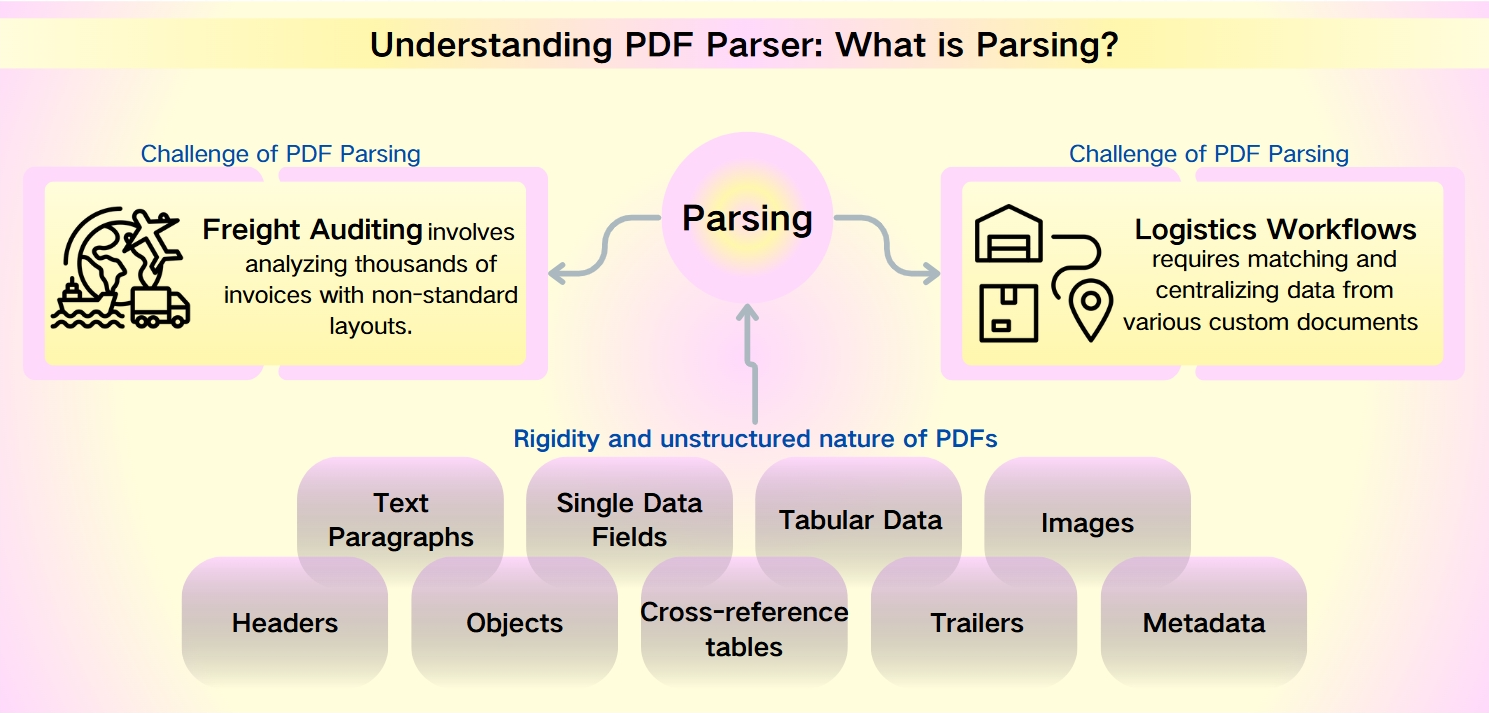
Udfordringer ved PDF Parsing: ustruktureret natur af PDF metadata
På trods af robustheden af PDF'er—karakteriseret ved deres sikkerhed, enhedskompatibilitet og kompakte filstørrelser—udgør udtrækning af data fra dem en formidable udfordring. Den stivhed og ustrukturerede natur af PDF'er hindrer hurtig analyse og informationstilgang. Dette er særligt udtalt i scenarier som fragtrevision og logistikarbejdsgange, hvor ikke-standard layouts og store datasæt komplicerer kompleksiteten.
Fragtrevision involverer analyse af tusindvis af fakturaer med ikke-standard layouts. Logistikarbejdsgange kræver matchning og centralisering af data fra forskellige tilpassede dokumenter som pakkelister, handelsfakturaer og fragtdokumenter.
Betydningen af Parsing
Parsing spiller en vital rolle i forskellige felter, fra webudvikling til datafangst. Det gør det muligt for virksomheder at udtrække værdifulde indsigter fra ustrukturerede datakilder, såsom PDF-dokumenter, HTML-filer og XML-data. Parsing letter:
-
Forbedret beslutningstagning gennem datadrevne indsigter.
-
Forbedret data nøjagtighed og konsistens.
-
Strømlinet data behandling og analyse.
-
Effektiv informationstilgang og opbevaring.
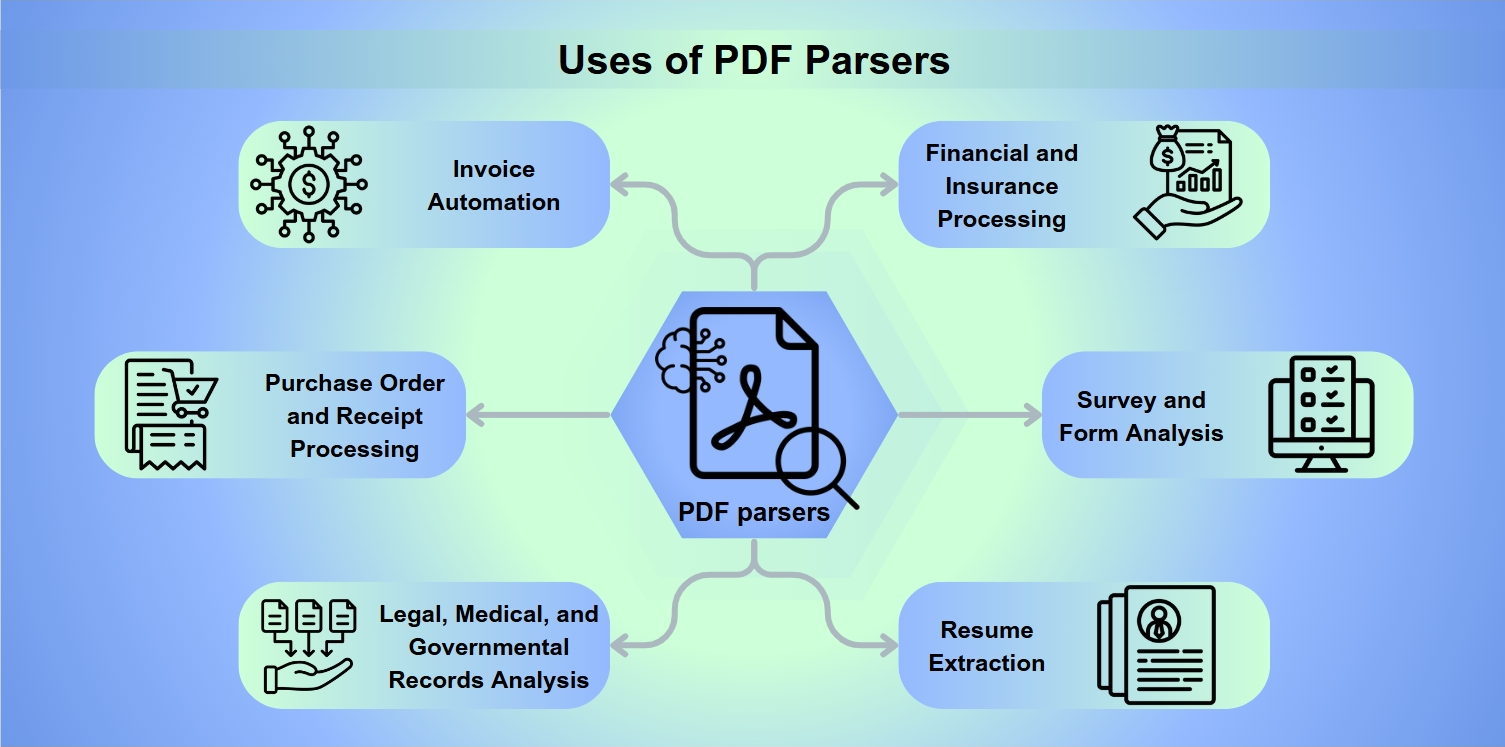
Anvendelser af PDF Parsers
PDF parsers er uundgåelige værktøjer i et spektrum af anvendelser, herunder:
-
Fakturaautomatisering: Strømlining af behandling og betaling af fakturaer.
-
Behandling af indkøbsordrer og kvitteringer: Facilitering af refusioner og tilbagebetalinger.
-
Analyse af juridiske, medicinske og offentlige optegnelser: Muliggør dybdegående dataudtræk til analyse.
-
Finansiel og forsikringsbehandling: Vurdering af risiko og analyse af balanceark.
-
Analyse af undersøgelser og formularer: Indsamling og fortolkning af formularbesvarelser.
-
CV-udtræk: Hjælper rekrutterere med at kortlægge kandidater.
Sammenligning af Forskellige Parsingmetoder
Data parsingmetoder har udviklet sig betydeligt over tid. Traditionelle tilgange til datafangst er ofte afhængige af regulære udtryk (regex) til at udtrække specifikke mønstre fra tekst. Selvom de er kraftfulde, kan regex blive komplekse og svære at vedligeholde for indviklede parsingopgaver. En anden almindelig teknik er strengmanipulation, som involverer opdeling og behandling af tekst baseret på afgrænsere eller specifikke tegn. Disse metoder, selvom de stadig er nyttige i visse scenarier, kan have problemer med ustrukturerede eller inkonsistente dataformater.
Landskabet af PDF parsing betjenes af en række metoder, hver med sine unikke fordele og ulemper:
-
Online PDF-konvertere/parsere: Som Zamzar og Smallpdf, tilbyder bekvemmelighed og hastighed, men er begrænsede i funktionalitet og potentielt usikre.
-
Adobe Acrobat: Bevarer struktur og formatering, men kan kræve manuelle justeringer efter konvertering.
-
Kopiering og indsætning: Giver fuld kontrol, men er besværligt og fejlbehæftet.
-
Automatiserede platforme: Moderne parsingteknologier som AnyParser udnytter maskinlæring og naturlig sprogbehandling (NLP) til at håndtere mere komplekse datastrukturer.
Disse AI-drevne tilgange kan forstå kontekst og semantik, hvilket gør dem særligt effektive til parsing af ustruktureret tekst eller dokumenter med varierende formater. Nogle avancerede parsere anvender dyb læringsmodeller til at identificere og udtrække relevant information med høj nøjagtighed, selv fra tidligere usete dokumentlayouts.
Sådan udføres PDF Parsing: Den Bedste Gratis PDF Parser til Udtrækning af PDF Metadata
Forståelse af PDF Metadata
PDF metadata indeholder afgørende information om et dokument, herunder dets titel, forfatter, oprettelsesdato og nøgleord. Effektiv udtrækning af denne metadata er essentiel for organisering, søgning og håndtering af store samlinger af PDF-filer. En robust PDF parser kan strømline denne proces, spare tid og forbedre arbejdsflowproduktiviteten.
Nøglefunktioner i Top PDF Parsers
De bedste gratis PDF parsere tilbyder en kombination af nøjagtighed, hastighed og alsidighed. De bør være i stand til at håndtere forskellige PDF-formater, herunder scannede dokumenter og dem med komplekse layouts. Se efter parsere, der kan udtrække ikke kun grundlæggende metadata, men også tilpassede felter og skjult information. Derudover tilbyder top-tier parsere ofte muligheder for pdf dataudtrækker til batchbehandling og integration med andre softwaresystemer.
Funktioner i AnyParser
AnyParser, udviklet af CambioML, er særligt bemærkelsesværdig på grund af sin nøjagtighed, privatliv og konfigurerbarhed. AnyParser's evne til at håndtere flere filformater, dens brugervenlige grænseflade og dens skalerbarhed gør det til et fremragende valg for virksomheder af alle størrelser. Desuden muliggør dens API problemfri integration i eksisterende arbejdsprocesser, hvilket forbedrer den samlede dokumenthåndteringseffektivitet. Her er nogle af de vigtigste funktioner, der gør AnyParser til et fremragende valg for PDF parsing:
-
Præcision: AnyParser er designet til nøjagtigt at udtrække tekst, tal og symboler, mens den bevarer den oprindelige layout og format. Den udnytter avancerede sprogmodeller til at forbedre dokumentforståelse og informationudtræk, og kan prale af op til 2x højere nøjagtighed sammenlignet med traditionelle OCR-modeller.
-
Privatliv: Den understøtter både on-prem og cloud data parsing, hvilket sikrer, at følsomme oplysninger forbliver private og sikre.
-
Konfigurerbarhed: Brugere kan tilpasse udtrækningsregler og outputformater til at passe til specifikke behov.
-
Multi-kilde Support: AnyParser understøtter en række dokumenttyper, herunder PDFs, billeder og diagrammer.
-
Struktureret Output: Udtrukket information kan konverteres til strukturerede formater som Markdown, Excel eller JSON, hvilket letter yderligere behandling og analyse.
-
Cloud-baserede Udrulningsmuligheder: AnyParser SDK kan udrulles i skyen, datacentre eller privat, hvilket tilbyder fleksibilitet og skalerbarhed.
-
Brugervenlig Grænseflade: Værktøjet tilbyder en simpel API, der gør det muligt at udføre komplekse dokument parsingopgaver med blot et par linjer kode.
-
Høj Ydeevne: Optimerede algoritmer sikrer hurtig behandling af et stort antal dokumenter, 5X hurtigere end generaliserede LLM'er som GPT4o.
-
Fællesskabsstøtte: Som et open-source projekt drager AnyParser fordel af et aktivt fællesskab og byder velkommen til bidrag.
-
Gratis Brugsgrænse: AnyParser tilbyder en gratis brugsgrænse med hver konto, hvilket giver brugerne mulighed for at teste værktøjets kapaciteter, før de forpligter sig til en betalt plan.
-
Kunde Feedback: Brugere har rost AnyParser for sin høje nøjagtighed, bevarelse af privatliv og effektivitet i dataudtræk, med casestudier, der viser betydelige tidsbesparelser og forbedret datakvalitet.
Disse fordele gør AnyParser til en værdifuld pdf dataudtrækker til dokument parsing og informationudtræk, især for erhvervsbrugere, der kræver høj præcision og sikkerhed. Med løbende teknologiske fremskridt og aktivt fællesskabsengagement er AnyParser klar til at spille en stadig vigtigere rolle inden for dokument parsing og informationudtræk.
Teknisk Forklaring af PDF Parsers
PDF parsing deler konceptuel grund med web scraping, men mangler den strukturerede hierarki af HTML. Mens webdokumenter parses gennem tilgængelige HTML-tags, præsenterer PDF'er en flad række af tegn og pixels, hvilket kræver mere sofistikerede algoritmer og biblioteker til dataudtræk.
PDF Parser vs Python PDF Parser: Nøgleforskelle
En PDF parser er ofte et selvstændigt værktøj som en pdf dataudtrækker eller bibliotek designet specifikt til at udtrække data fra PDF-filer. Disse parsere tilbyder typisk brugervenlige grænseflader og kræver minimal kodningsviden. På den anden side er Python PDF parsere moduler eller biblioteker, der integreres i Python-scripts, hvilket giver mere fleksibilitet, men kræver programmeringsekspertise.
Udviklere kan finjustere parsingprocessen, implementere avanceret tekstanalyse og problemfrit integrere PDF dataudtræk i bredere Python-applikationer. PDF parsere, mens de er mere begrænsede i tilpasning end Python PDF parser, tilbyder ofte forudbyggede funktioner til almindelige anvendelsestilfælde, hvilket gør dem ideelle til brugere, der har brug for hurtige resultater uden omfattende programmering.
Fordele ved AnyParser med VLM til Data Parsing
-
Høj Præcision: AnyParser's VLM'er sikrer, at dataudtræk opretholder høj troværdighed, selv med komplekse dokumentlayouts.
-
Hastighed: Den fører i konverteringshastighed, hvilket forbedrer produktiviteten ved at reducere den tid, der er nødvendig for at behandle dokumenter.
-
Brugervenlig: AnyParser tilbyder en ligetil grænseflade, der gør det tilgængeligt for brugere på alle niveauer.
-
Alsidighed: Udover PDF'er fungerer AnyParser som en kraftfuld billed-til-Excel konverter, der understøtter forskellige dokumenttyper.
Konklusion
PDF parsing er mere end blot en teknisk proces; det er en gateway til at transformere, hvordan virksomheder håndterer data. På trods af udfordringerne har udviklingen af softwareløsninger gjort det mere tilgængeligt end nogensinde. Uanset om du beskæftiger dig med fakturabehandling eller kompleks dataanalyse, er det essentielt at vælge den rigtige PDF parser. Det handler om at finde det værktøj, der tilbyder den perfekte balance mellem nøjagtighed, sikkerhed og effektivitet for at styrke dine datadrevne initiativer.
Start din gratis prøveperiode i dag
Klar til at revolutionere din dokumentbehandling? Prøv AnyParser GRATIS uden kreditkortkrav på https://www.cambioml.com/sandbox. Den gratis prøveperiode giver dig mulighed for at behandle op til 10 sider pr. dokument, med en maksimal filstørrelse på 10MB. Oplev førstehånds, hvordan AnyParser's pdf parser kan transformere din tilgang til ustrukturerede data og dokumentudtræk. Gå ikke glip af denne mulighed for at forbedre dine dataanalysekapaciteter og strømline dit arbejdsflow med state-of-the-art AI-teknologi.