At konvertere komplekse PDF-filer til Markdown kan være en udfordring. Der findes mange open-source biblioteker til at udtrække tekst fra PDF, men når det kommer til PDF-filer, der indeholder komplekse elementer som tabeller og diagrammer, falder resultaterne ofte kort. Populære store sprogmodeller som GPT eller Claude kan håndtere disse opgaver, men de har tendens til at være langsomme og nogle gange producere unøjagtige resultater. Traditionelle OCR-værktøjer, mens de er effektive til enklere dokumenter, kæmper ofte med at opretholde den nøjagtige struktur og semantiske betydning af det originale indhold. På den anden side hallucinerer visionssprogmodeller nogle gange, hvilket fører til fejlagtige parsingresultater. Denne blog vil forklare, hvad parsing betyder, og detaljeret beskrive resultaterne af en sammenlignende analyse af flere modeller ved hjælp af flere metrikker.
Hvad betyder parsing?
I forbindelse med PDF-parsing refererer "parsing" til processen med at udtrække specifikke data fra en PDF-fil ved hjælp af specialiseret software kendt som en PDF-parser. En PDF-parser analyserer indholdet af et PDF-dokument og identificerer elementer som tekst, billeder, skrifttyper, layouts og endda metadata. De udtrukne data kan derefter organiseres og eksporteres til forskellige formater som XML, JSON eller Excel/CSV, som kan bruges til forskellige formål som dataanalyse, registrering eller automatisering af arbejdsgange.
At forstå, hvad parsing betyder, er essentielt for at evaluere effektiviteten af en parsingløsning, især når man sammenligner forskellige PDF til Markdown konverteringsværktøjer, da PDF-parser involverer mere end blot simpel tekstudtrækning—det kræver genkendelse og opretholdelse af dokumentets semantiske struktur.
Hvordan måler vi kvaliteten af disse parsingløsninger?
Vi har defineret en række ord-niveau metrikker til at vurdere ydeevnen af forskellige modeller med fokus på nøglefaktorer som:
-
Præcision, Recall og F-Mål: Evaluering af kvaliteten og fuldstændigheden af parsing.
-
BLEU Score og ANLS: Nyttige til evaluering af sprog og layoutstruktur.
-
Edit Distance, Jensen-Shannon Divergence og Jaccard Distance: Metrikker specifikke for OCR-domenet, der er særligt nyttige til at forstå nøjagtigheden af indholdsreproduktion.
Vores visionssprogmodel, AnyParser, demonstrerer enestående ydeevne, der kombinerer hastighed og nøjagtighed, især på komplekse layouts med tabeller og semantiske elementer. AnyParser overgår andre løsninger, hvilket tilbyder en 20x hastighedsforbedring i forhold til modeller som GPT/Claude, samtidig med at den opnår højere nøjagtighed.
En omfattende sammenligning af førende parsingmodeller
Statistisk objekt
For virkelig at vise kapabiliteterne af AnyParser, gennemførte vi en omfattende sammenligning mod førende parsingmodeller i branchen og velkendte store sprogmodeller (LLMs). Vores evaluering omfattede:
1. Store Sprogmodeller
- AnyParser
- OpenAI's GPT-4o
- Googles Gemini 1.5 Pro
- Anthropic's Claude 3.5 Sonnet
2. OCR-baserede Tjenester
- LlamaParse
- Amazon Textract
- Google Cloud Document AI
- Azure Document Intelligence
Resultatpræsentation og analyse
Eksperiment 1
Først gennemfører vi en række strenge sammenligninger af ydeevnen af forskellige dokument AI-modeller på over 5 metrikker nedenfor: BLEU, Præcision og recall, F-Mål og ANLS. Du kan finde den matematiske definition af disse definitioner i appendikset.
De sammenlignede modeller er: AnyParser-base, AnyParser-pro, Textract, Llama-Parse, GPT4o, Gemini-1.5-pro, GCP-DocAl og Azure-DocAl.
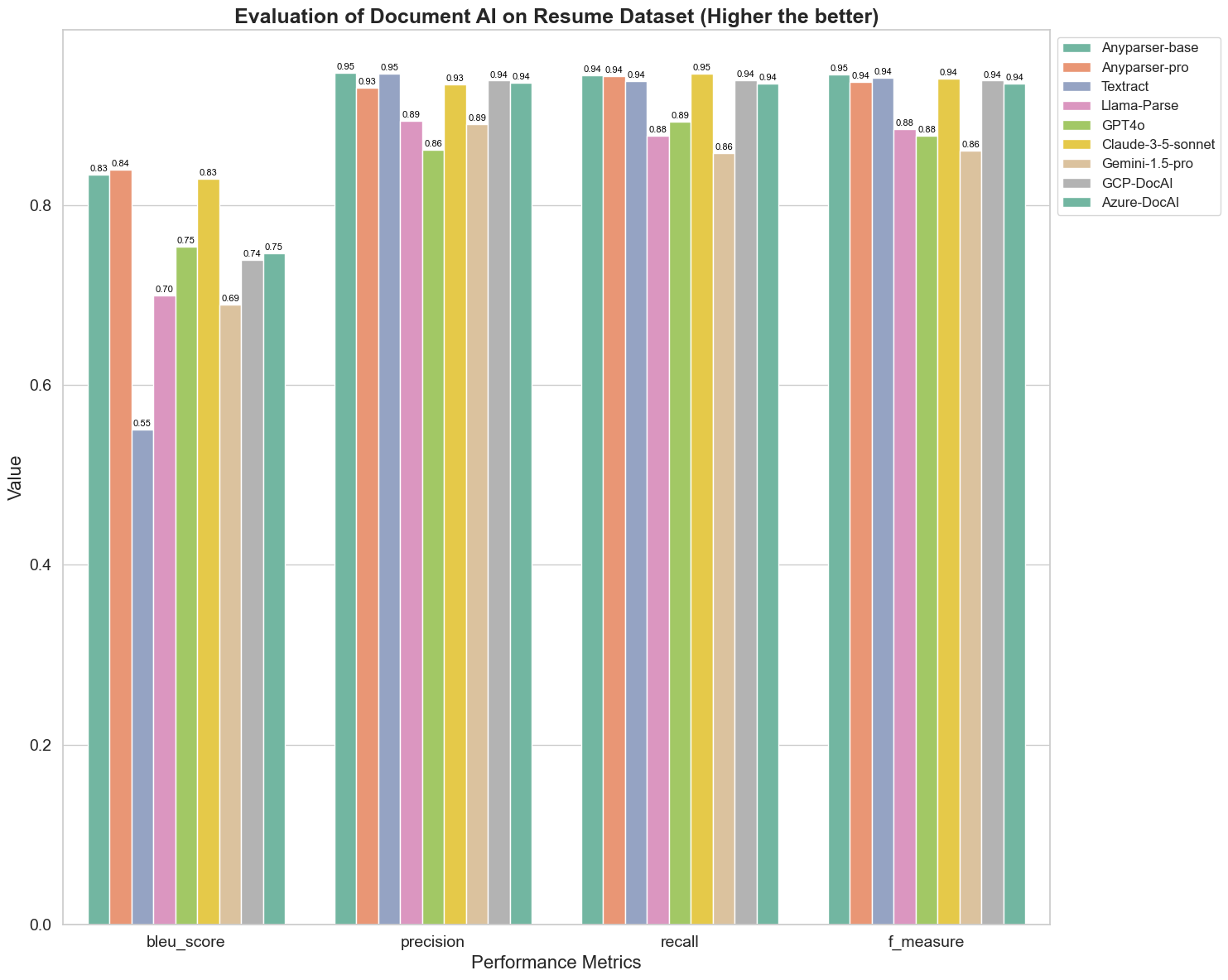
BLEU bruges som en vurdering af kvaliteten af to-sproget fortolkning for at teste kvaliteten af modellerne i behandlingen af ytringer. Ved at sammenligne resultaterne af disse parsingmodeller under BLEU-vurderingsmetoden finder vi, at: scores for AnyParser-base og AnyParser-pro er betydeligt højere end scores for de andre modeller, Amazon Textract scorer lavest, og resultaterne af scores for de andre modeller ligger på et relativt gennemsnitligt niveau.
Genkendelsesnøjagtighed repræsenteres normalt af præcision og recall, hvor præcision repræsenterer procentdelen af virkelig korrekte resultater blandt de resultater, der vurderes som korrekte af modellen, og recall repræsenterer procentdelen af virkelig korrekt vurderede resultater af modellen blandt alle faktisk korrekte resultater. Ved at sammenligne præcision og recall af disse parsingmodeller finder vi, at: bortset fra Llama-Parse, GPT4o og Gemini-1.5-pro, ligger alle andre modeller på et højt niveau. Blandt dem er AnyParser og Amazon Textract mere fremtrædende i præcision, og AnyParser-base og AnyParser-pro er mere fremtrædende i recall. Den højere score for modellen på Præcision indikerer, at modellen udskriver mere korrekt information i produktionsresultaterne, og den højere score på recall indikerer, at modellen er mere i stand til at opnå korrekt information fra prøven. Resultaterne af scores viser, at AnyParser har en klar fordel med hensyn til genkendelsesnøjagtighed til at udtrække tekst fra PDF.
F-Mål er en omfattende evalueringsindeks for præcision og recall på disse to indikatorer. Ved at sammenligne scores for disse parsingmodeller under F-Mål kan vi se mere intuitivt, at de fem modeller, AnyParser-base, AnyParser-pro, Amazon Textract, GCP-DocAI og Azure-DocAI, har en bedre styrke med hensyn til genkendelsesnøjagtighed sammenlignet med andre modeller. Vi kan se mere intuitivt, at de fem modeller har mere styrke i genkendelsesnøjagtighed end de andre modeller, og AnyParser har den højeste score under F-Mål, hvilket yderligere illustrerer den åbenlyse fordel ved AnyParser i genkendelsesnøjagtighed til at udtrække tekst fra PDF.
ANLS, som er en almindeligt anvendt evalueringsindeks, når det kommer til at måle nøjagtigheden og ligheden mellem den originale tekst og målteksten på tegnniveau, er også meget informativ til at måle parsingniveauet for modellerne. De højere scores for AnyParser-base, AnyParser-pro og Azure-DocAI afspejler det højere parsingniveau for disse modeller sammenlignet med de andre modeller.
Overordnet set overgår AnyParser-base og AnyParser-pro de andre modeller.
Eksperiment 2
Vi sammenligner også ydeevnen af forskellige dokument AI-modeller på tre forskellige metrikker: Edit Distance, Jensen-Shannon Divergence og Jaccard Distance. Metrikkerne bruges til at måle ligheden mellem output fra modellerne og et reference-dokument. Lavere værdier indikerer bedre ydeevne.
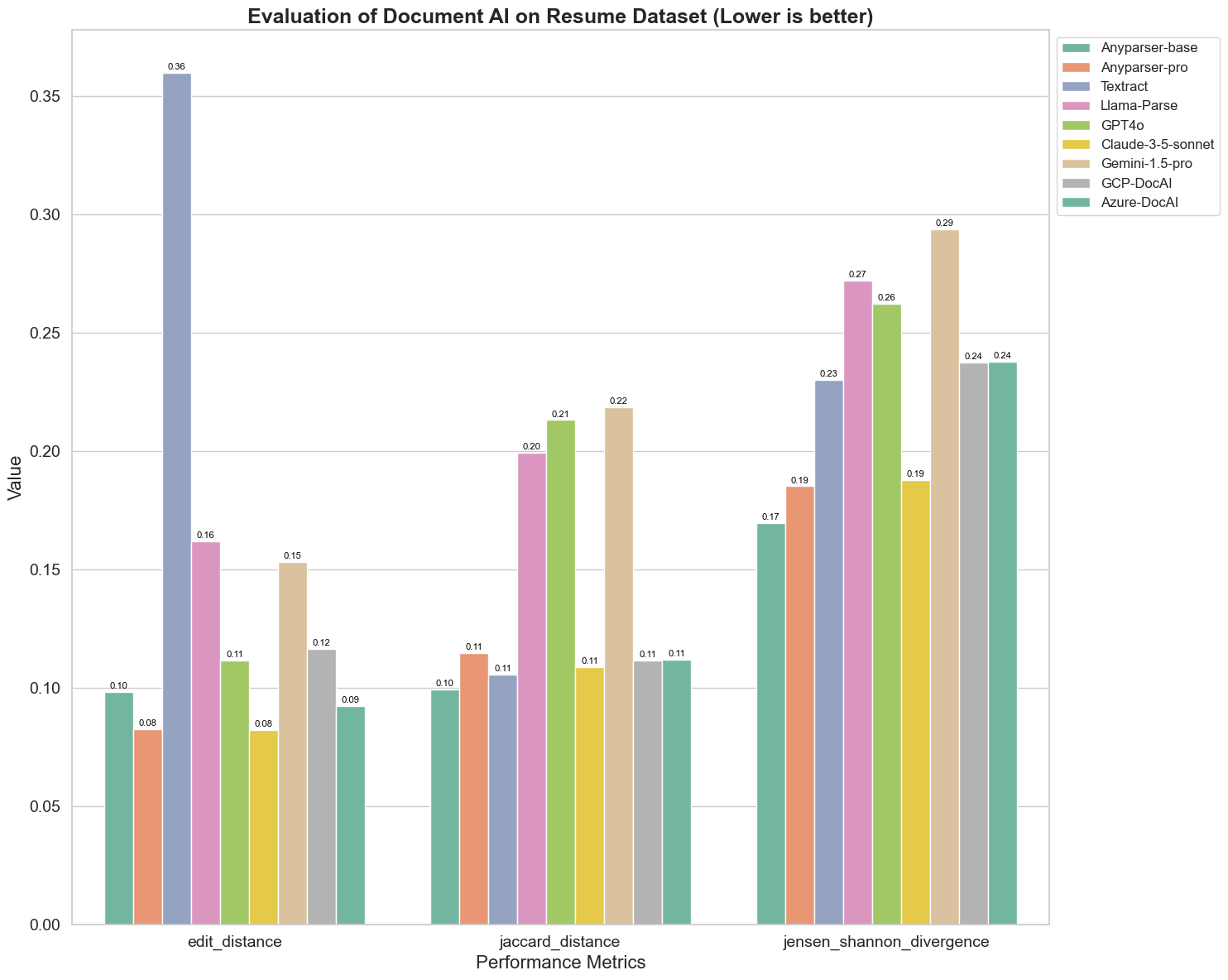
Her er nogle nøgleobservationer fra diagrammet:
-
Edit Distance: Modellerne AnyParser-base og AnyParser-pro klarer sig bedst med den laveste edit distance, hvilket tyder på, at deres output var tættest på reference-dokumentet.
-
Jensen-Shannon Divergence: Modellerne AnyParser-base og AnyParser-pro har den laveste divergence, hvilket antyder, at deres output er mest lig reference-dokumentet med hensyn til ordfordeling.
-
Jaccard Distance: Udover Llama-parse, GPT4O, Gemini-1.5, præsterer alle de andre modeller anstændigt med den laveste Jaccard distance, hvilket indikerer, at deres output har den højeste overlapning med reference-dokumentet med hensyn til de anvendte ordsæt.
Konklusion
Overordnet set tyder vores strenge test på, at AnyParser-base og AnyParser-pro generelt klarer sig godt på tværs af forskellige metrikker, hvilket indikerer dets potentiale for nøjagtig dokumentbehandling. Fra diagrammerne kan vi se, at traditionelle OCR-modeller som den berømte Amazon Textract scorer meget lavere end visionssprogmodeller. Dog varierer ydeevnen af forskellige modeller afhængigt af den anvendte metrik, hvilket fremhæver vigtigheden af at overveje flere evalueringskriterier, når man sammenligner AI-modeller.
Introduktion af vores open-source evalueringspipeline
For at strømline evalueringer har vi oprettet en evalueringspipeline, der giver en branche-standardmetode til at sammenligne parsingmodeller. I vores eksempel demonstrerer vi dens anvendelse i HR-domenet, hvor CV-parsing er almindeligt. Vi har bygget et forskelligt syntetisk datasæt af 128 CV'er, genereret ved hjælp af parrede billede-Markdown-filer. Ved hjælp af GPT-4 genererede vi HTML-indhold, gengav det til billeder og brugte den udtrukne tekst som sandhed for sammenligning.
Og her er den bedste del: vi har open-sourcet denne evalueringsramme på GitHub! Uanset om du er udvikler eller forretningsbruger, giver vores pipeline dig mulighed for at evaluere og sammenligne parsingkvaliteten af forskellige modeller på dit eget datasæt.
Find hurtigstartguiden i Github repo og se, hvordan forskellige parsingmodeller klarer sig mod hinanden. Vi mener, at ved at fremvise vores models styrker åbent, kan vi tiltrække flere brugere, der ønsker pålidelige, hurtige og nøjagtige parsingmuligheder.
Appendix - Metrikker
1. Præcision
Præcision måler nøjagtigheden af det parsede indhold og viser, hvor mange af de hentede elementer der var korrekte. I parsing er det andelen af korrekt udtrukne ord ud af alle udtrukne ord.
Præcision = Sande Positiver (TP) / (Sande Positiver (TP) + Falske Positiver (FP))
- Sande Positiver (TP): Ord korrekt identificeret af parseren.
- Falske Positiver (FP): Ord forkert identificeret af parseren.
2. Recall
Recall angiver fuldstændigheden af parsing, eller hvor mange relevante ord fra det originale dokument der blev hentet.
Recall = Sande Positiver (TP) / (Sande Positiver (TP) + Falske Negativer (FN))
- Falske Negativer (FN): Ord i det originale dokument, der blev overset af parseren.
3. F-Mål (F1 Score)
F1 Score er det harmoniske gennemsnit af Præcision og Recall, der balancerer begge metrikker for at give et samlet mål for parsingkvalitet.
F1 Score = 2 × (Præcision × Recall) / (Præcision + Recall)
4. BLEU Score (Bilingual Evaluation Understudy)
BLEU score måler ligheden mellem det parsede indhold og den originale tekst, med særlig vægt på rækkefølgen af ord. Det er særligt nyttigt til evaluering af sprog og strukturens konsistens i parsede dokumenter, da det straffer output, der adskiller sig i rækkefølge fra det originale.
5. ANLS (Gennemsnitlig Normaliseret Levenshtein Lighed)
ANLS kvantificerer ligheden mellem det parsede indhold og det originale ved hjælp af normaliseret edit distance. Det beregnes ved at tage gennemsnittet af den Normaliserede Levenshtein Lighed (NLS) for hvert ordpar i de parsede og reference-tekster. NLS beregnes som følger:
NLS = 1 - (Levenshtein Distance (LD)(parset ord, originalt ord)) / max(Længde af parset ord, Længde af originalt ord)
Derefter er ANLS gennemsnittet af NLS på tværs af alle ordpar:
ANLS = (1/N) × Σ(NLS_i) for i=1 til N
6. Edit Distance
Edit Distance beregner antallet af ord-niveau operationer (indsættelser, sletninger, substitutioner), der kræves for at konvertere den parsede tekst til den originale.
7. Jensen-Shannon Divergence
Jensen-Shannon Divergence måler ligheden mellem diskrete sandsynlighedsfordelinger af parsede og originale ordtællinger, hvilket fremhæver forskelle i ordhyppighed.
JSD(P || Q) = (1/2) × KL(P || M) + (1/2) × KL(Q || M)
hvor M = (1/2)(P + Q), og KL(P || Q) er Kullback-Leibler divergence
8. Jaccard Distance
Jaccard Distance måler uligheden mellem ordsæt i parsede og originale indhold, nyttigt til at vurdere ordoverlap.
Jaccard Distance = 1 - |A ∩ B| / |A ∪ B|
hvor |A ∩ B| er antallet af fælles elementer mellem A og B,
og |A ∪ B| er det samlede antal unikke elementer i begge sæt.