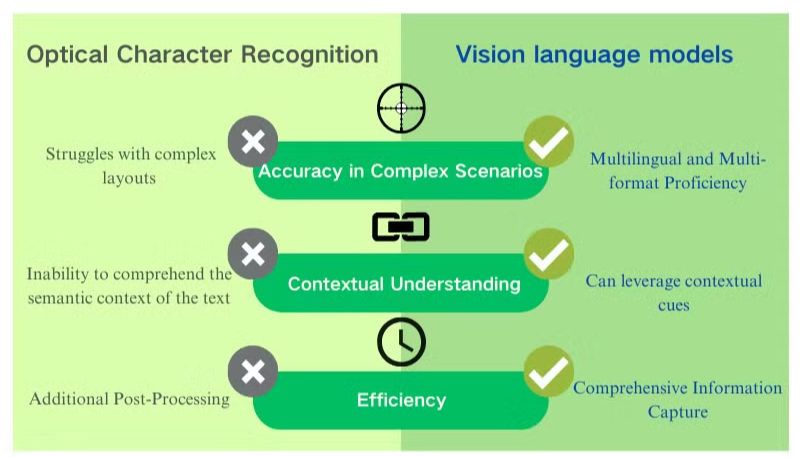
Vision Sprogmodeller (VLM'er) revolutionerer feltet for dokumentanalyse ved at adressere mange af de begrænsninger, der er iboende i traditionelle systemer til optisk tegngenkendelse (OCR). Mens OCR har været en hjørnesten teknologi til digitalisering af tekst fra billeder, står det over for betydelige udfordringer i komplekse scenarier. Disse inkluderer nøjagtighedsproblemer med lavkvalitetsbilleder, begrænset kontekstuel forståelse, vanskeligheder med blandede sprog og manglende evne til at fortolke visuelle elementer. VLM'er tilbyder en lovende løsning ved at kombinere avanceret computer vision med naturlig sprogbehandlingskapaciteter. Denne artikel udforsker, hvordan VLM'er overvinder OCR's mangler og giver mere robuste og alsidige løsninger til dokumentbehandling i den digitale tidsalder.
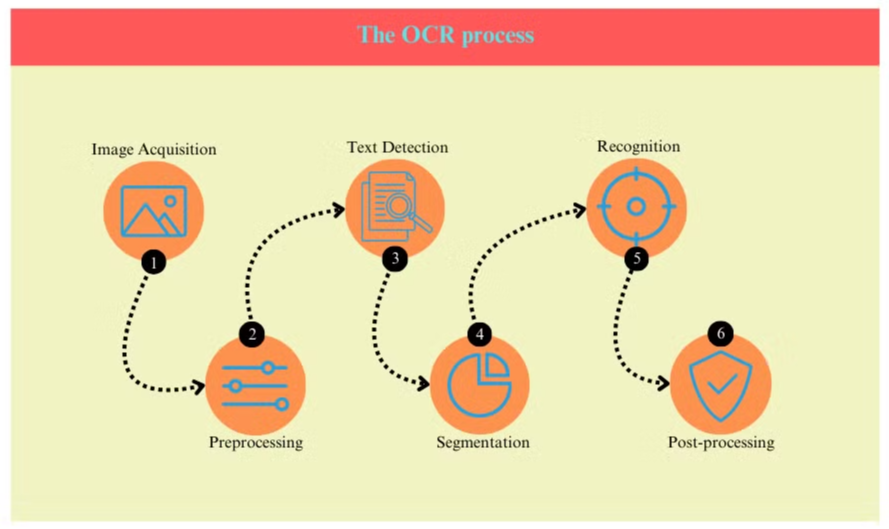
Hvad er OCR? Hvad er processerne for OCR i dokumentanalyse?
Optisk tegngenkendelse (OCR) er en teknologi, der muliggør konvertering af forskellige typer dokumenter, såsom scannede papirdokumenter, PDF-filer eller billeder taget med et digitalkamera, til redigerbare og søgbare data. Denne proces er afgørende i dokumentbehandling og PDF dataudtræk, da den gør det muligt for maskiner at genkende trykte eller håndskrevne teksttegn i digitale billeder.
OCR-processen
OCR-processen involverer typisk flere trin:
- Billedoptagelse: Dokumentet scannes eller fotograferes for at skabe et digitalt billede.
- Forbehandling: Billedet renses, støj fjernes, og lysstyrke og kontrast justeres.
- Tekstdetektion: Systemet identificerer områder, der indeholder tekst i billedet.
- Tegngenkendelse: Individuelle tegn isoleres inden for tekstområderne.
- Tegngenkendelse: Hvert tegn analyseres og sammenlignes med en database af kendte tegn.
- Efterbehandling: Den genkendte tekst kontrolleres for fejl ved hjælp af sproglige og kontekstuelle oplysninger.
Selvom OCR har forbedret dokumentanalysekapaciteterne betydeligt, står det stadig over for begrænsninger i håndteringen af komplekse layouts, lavkvalitetsbilleder og varierede skrifttyper. Det er her, avancerede teknologier som vision sprogmodeller træder ind for at forbedre nøjagtighed og forståelse i udtræk af data fra billeder og dokumenter.
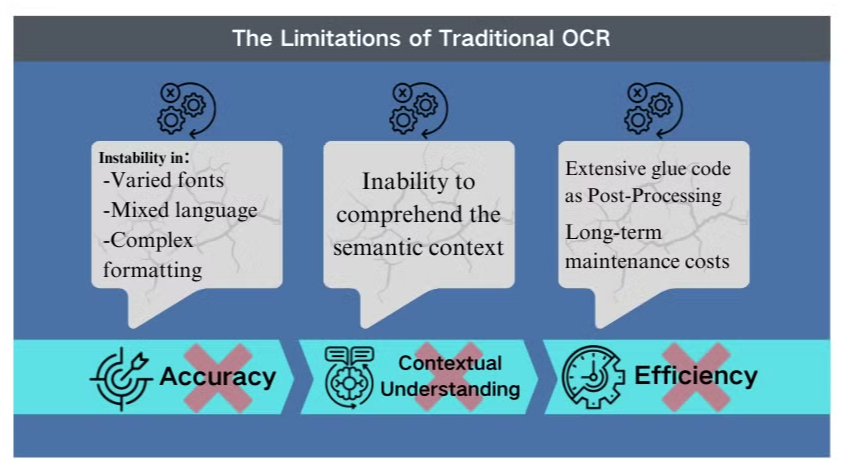
Begrænsningerne ved Traditionel OCR Teknologi
Nøjagtighedsudfordringer i Komplekse Scenarier
Traditionel optisk tegngenkendelse (OCR) teknologi, selvom den er gavnlig til grundlæggende tekstudtræk, står over for betydelige forhindringer, når den konfronteres med indviklede dokumentlayouts eller lavkvalitetsbilleder. Disse systemer har ofte svært ved at opretholde nøjagtigheden, når de behandler dokumenter med varierede skrifttyper, blandede sprog eller komplekse formateringer. For eksempel kan OCR fejle, når den forsøger at udtrække data fra billedtunge præsentationer eller tæt formaterede PDF'er.
Manglende Kontekstuel Forståelse
En af de mest iøjnefaldende begrænsninger ved konventionel OCR er dens manglende evne til at forstå den semantiske kontekst af den tekst, den behandler. Denne mangel bliver særligt tydelig i scenarier, der kræver nuanceret fortolkning, såsom juridiske kontrakter eller medicinske rapporter. OCR's fokus på tegngenkendelse uden kontekstuel bevidsthed kan føre til kritiske misfortolkninger, især når der arbejdes med tvetydige tegn eller branchespecifik terminologi.
Ineffektivitet i Efterbehandling
Begrænsningerne ved OCR kræver ofte omfattende efterbehandlingsindsats. Dette ekstra trin kan betydeligt øge den tid og de ressourcer, der kræves til dokumentbehandling. Desuden falder traditionelle OCR-systemer typisk kort, når de skal udtrække information fra diagrammer, tabeller eller andre ikke-tekstuelle elementer, hvilket yderligere komplicerer dokumentudtrækningsprocessen. Disse ineffektiviteter understreger behovet for mere avancerede løsninger, såsom vision sprogmodeller, som tilbyder en mere omfattende tilgang til dokumentanalyse og dataudtræk.
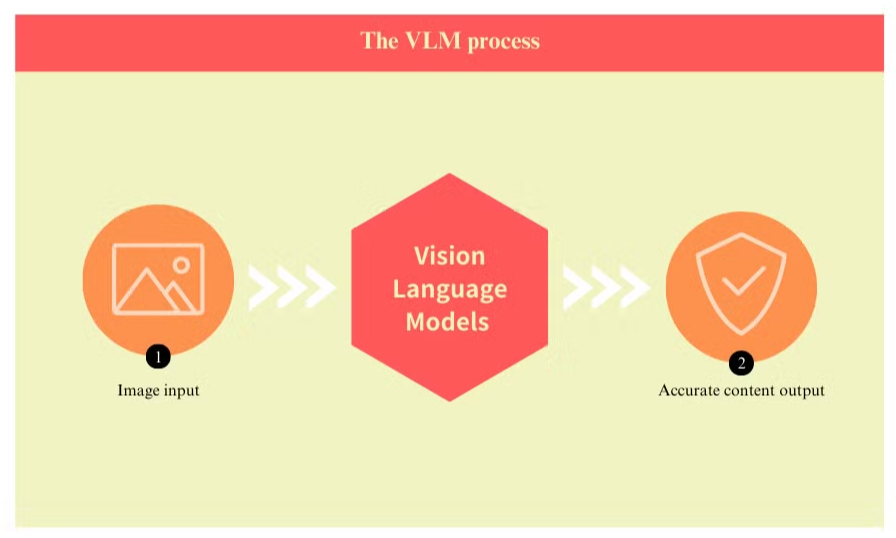
Hvad er Vision-Sprogmodeller, og hvordan forbedrer de OCR
Vision sprogmodeller repræsenterer et betydeligt fremskridt inden for dokumentbehandlingsteknologi, idet de adresserer mange af de begrænsninger, der er iboende i traditionelle systemer til optisk tegngenkendelse (OCR). Disse avancerede modeller kombinerer computer vision med naturlig sprogbehandling for at forstå både de visuelle og tekstlige elementer i dokumenter samtidig.
Forbedret Nøjagtighed og Kontekstuel Forståelse
I modsætning til OCR, der kæmper med lavkvalitetsbilleder og komplekse layouts, excellerer vision sprogmodeller i at fortolke forskellige dokumentformater. De kan nøjagtigt udtrække data fra billeder, PDF'er og andet visuelt indhold, selv når de står over for udfordrende scenarier. Denne forbedrede nøjagtighed stammer fra deres evne til at overveje hele konteksten af et dokument i stedet for kun at fokusere på individuelle tegn eller ord.
Omfattende Dataudtræk
Vision sprogmodeller går ud over simpel tekstgenkendelse og tilbyder omfattende PDF dataudtrækningskapaciteter. De kan identificere og fortolke tabeller, diagrammer og figurer inden for dokumenter, hvilket bevarer integriteten af komplekse layouts. Denne holistiske tilgang til dokumentanalyse muliggør mere nuanceret og komplet informationshentning, hvilket betydeligt forbedrer nytten af de udtrukne data til downstream-applikationer.
Flersproget og Multi-format Kompetence
En af de vigtigste fordele ved vision sprogmodeller er deres fleksibilitet i håndteringen af flere sprog og dokumentformater. I modsætning til OCR-systemer, der kan have svært ved ikke-latinske skrifter eller blandede sprog, kan disse modeller problemfrit behandle indhold på tværs af forskellige sprog og skrifter, hvilket gør dem uvurderlige for globale dokumentbehandlingsbehov.
Nøglefordele ved Vision-Sprogmodeller til Dokumentforståelse
Vision sprogmodeller tilbyder betydelige fordele i forhold til traditionel OCR til dokumentbehandling og dataudtræk. Disse AI-drevne systemer kombinerer visuel og tekstuel forståelse for at levere overlegen præstation på tværs af forskellige dokumenttyper.
Forbedret Nøjagtighed og Kontekstuel Forståelse
Vision sprogmodeller excellerer i at håndtere komplekse layouts, lavkvalitetsbilleder og forskellige skrifttyper. I modsætning til OCR, der kæmper med tvetydige tegn, udnytter disse modeller kontekstuelle ledetråde til nøjagtigt at fortolke tekst. Denne evne forbedrer dramatisk nøjagtigheden af PDF dataudtræk, især for dokumenter med indviklede strukturer eller dårlig billedkvalitet.
Omfattende Informationsindhentning
Mens OCR udelukkende fokuserer på tekstgenkendelse, kan vision sprogmodeller udtrække data fra billeder, tabeller og diagrammer. Denne holistiske tilgang sikrer, at kritisk information ikke overses under dokumentbehandlingsfasen. Ved at indfange både tekstlige og visuelle elementer giver disse modeller en mere komplet forståelse af dokumentindholdet.
Flersproget og Multi-format Kompetence
Vision sprogmodeller viser bemærkelsesværdig fleksibilitet i behandlingen af dokumenter på tværs af forskellige sprog og formater. De kan problemfrit håndtere blandede sprog og ikke-latinske skrifter, hvilket overvinder en betydelig begrænsning ved traditionelle OCR-systemer. Denne alsidighed gør dem uvurderlige for globale virksomheder, der beskæftiger sig med forskellige dokumenttyper og sprog.
Virkelige Anvendelser Muliggjort af VLM, som OCR Fejlede
Vision sprogmodeller revolutionerer dokumentbehandling inden for finans, menneskelige ressourcer og andre sektorer ved at adressere kritiske begrænsninger ved traditionelle OCR-systemer. Disse avancerede AI-modeller transformerer digitale transformationsindsatser på tværs af industrier ved at tilbyde overlegen nøjagtighed og kontekstuel forståelse.
Revolutionering af Finansiel Dokumentbehandling
Vision sprogmodeller transformerer dokumentbehandling i finanssektoren ved at overvinde begrænsningerne ved traditionel OCR. Disse avancerede modeller excellerer i at udtrække data fra komplekse finansielle erklæringer, fakturaer og kvitteringer med indviklede layouts. I modsætning til OCR kan de forstå konteksten, nøjagtigt fortolke tvetydige tegn (f.eks. skelne mellem et nul og bogstavet O) og blandede sprog, der ofte findes i globale finansielle dokumenter.
Forbedring af HR-operationer gennem Intelligent Dokumentanalyse
I HR-sektoren viser vision sprogmodeller sig uvurderlige til PDF dataudtræk fra CV'er, medarbejderoptegnelser og præstationsvurderinger. Disse modeller kan forstå den semantiske struktur af dokumenter, hvilket muliggør mere nøjagtig informationshentning og analyse. Denne evne strømline ansættelsesprocesser og medarbejderdatahåndtering betydeligt, opgaver hvor OCR ofte kæmper med varierede formater og håndskrevne noter.
Forbedring af Overholdelse og Risikostyring
Vision-sprogmodeller er særligt effektive i overholdelse og risikostyring inden for både finans og HR. De kan udtrække og fortolke kritisk information fra reguleringsdokumenter, kontrakter og politikker med større nøjagtighed end OCR. Denne forbedrede dokumentbehandlingskapacitet sikrer bedre overholdelse af lovkrav og mere effektive risikovurderingsprocedurer.
Konklusion
Afslutningsvis repræsenterer vision sprogmodeller et betydeligt fremskridt inden for dokumentbehandlingsteknologi, idet de adresserer mange af de iboende begrænsninger ved traditionelle OCR-systemer. Ved at kombinere visuel og tekstuel forståelse tilbyder disse avancerede modeller overlegen præstation på tværs af en bred vifte af udfordrende scenarier, fra komplekse layouts til blandede sprog og lavkvalitetsbilleder. Efterhånden som organisationer fortsætter med at digitalisere deres operationer og søge mere effektive måder at udtrække værdi fra deres dokumentarkiver, fremstår vision sprogmodeller som et kraftfuldt værktøj for udviklere og ingeniørledere. Deres evne til at forstå kontekst, håndtere forskellige formater og levere mere nøjagtige resultater placerer dem som en nøglemuliggører for sofistikerede RAG-pipelines og virksomhedsomspændende søgefunktioner, hvilket i sidste ende driver digitale transformationsinitiativer til nye højder.