Har du nogensinde spekuleret på, hvad OCR står for? Optisk tegngenkendelse er en kraftfuld teknologi, der konverterer billeder af tekst til maskinlæsbart data. Selvom OCR tilbyder enorme fordele ved digitalisering af dokumenter og udtræk af information, er det ikke uden sine ulemper. Når du udforsker denne teknologi, er det vigtigt at forstå både dens kapaciteter og begrænsninger. I denne artikel vil du opdage betydningen bag OCR og dykke ned i dens potentielle ulemper. Ved at få en omfattende forståelse af optisk tegngenkendelse vil du være bedre rustet til at afgøre, om og hvordan du skal implementere denne teknologi i dine egne arbejdsgange og projekter.
Hvad betyder OCR, og hvad er en OCR?
Hvad betyder OCR?
OCR står for optisk tegngenkendelse, en teknologi der gør det muligt for computere at genkende og konvertere forskellige typer dokumenter. I sin kerne er OCR processen med at scanne trykt eller håndskrevet tekst og konvertere det til maskinkodet tekst. Dette gør teksten søgbar, redigerbar og overførbar med lethed. At forstå, hvad OCR betyder, er essentielt for alle, der arbejder med dokument scanning og tekstgenkendelsesteknologier.
Hvad er en OCR?
For dem, der ikke er bekendt med termen, er "hvad er en OCR" et almindeligt spørgsmål, der refererer til optisk tegngenkendelse, en teknologi der tillader computere at læse tekst fra billeder eller scannede dokumenter.
OCR konverterer trykt eller håndskrevet tekst til maskinlæsbart data, hvilket brobygger kløften mellem papir- og digitale formater. Denne teknologi anvender sofistikerede algoritmer til at opdage bogstavformer, ordstrukturer og endda hele sætninger. Ved at gøre dette forvandler den statiske billeder til redigerbare og søgbare tekstfiler.
OCR-teknologi er fundamentalt baseret på computer vision og mønstergenkendelsesteknologier. OCR står for at scanne dokumenter eller billeder, der indeholder tekst, og bruge avancerede algoritmer til at identificere og konvertere teksten til et digitalt, redigerbart format. Et af de nøgleøjeblikke i historien om OCR-teknologi var i 1974, da Ray Kurzweil udviklede et omni-font OCR-system, der kunne genkende tekst i næsten enhver skrifttype. Gennem årene er OCR udviklet fra simpel skabelonmatchning til mere sofistikerede systemer.
På trods af sine kapaciteter står OCR-teknologien i øjeblikket over for visse begrænsninger. Disse inkluderer udfordringer ved at genkende tekst i billeder af dårlig kvalitet, vanskeligheder med at håndtere komplekse layout eller baggrunde, og varierende nøjagtighed, når der arbejdes med forskellige skrifttyper, sprog eller håndskrift. Derudover kan OCR-systemer have problemer med dokumenter, der har farvede baggrunde, er slørede eller skæve, samt med kursiv håndskrift.
Forståelse af optisk tegngenkendelsessoftware
Optisk tegngenkendelsessoftware er en transformerende teknologi, der konverterer forskellige typer dokumenter til redigerbare og søgbare data. Den spiller en afgørende rolle i digitaliseringen af vores verden, hvilket gør information mere tilgængelig og håndterbar. OCR-software anvender en sofistikeret proces til at konvertere billeder af tekst til maskinlæsbart data.
Hvordan fungerer OCR-software?
1. Billedeindfangning
Rejsen for OCR begynder med at fange et billede af dokumentet. Dette kan gøres gennem en scanner eller et digitalkamera. Billedet oversættes derefter til et digitalt format, som en computer kan bearbejde.
2. Forbehandling og billedforbedring
Det andet trin involverer at forbedre billedkvaliteten. Når billedet er indfanget, gennemgår det forbehandling for at forbedre kvaliteten til bedre genkendelse. Dette trin kan involvere justering af kontrast, lysstyrke og skarphed af billedet samt fjernelse af støj eller irrelevante elementer. Denne forbehandlingsfase er afgørende for at opnå nøjagtige resultater, især når man arbejder med lavkvalitets scanninger eller fotografier.
3. Tekstdetektion
OCR-software analyserer det forbehandlede billede for at opdage områder, der indeholder tekst. Det gør dette ved at lede efter mønstre og former, der er karakteristiske for tekst, såsom linjer af forskellige tykkelser og højder.
4. Tegnsegmentering
Når tekstområderne er opdaget, opdeler softwaren teksten i mindre enheder, såsom blokke, linjer, ord eller endda individuelle tegn. OCR-software analyserer billedet pixel for pixel for at identificere mønstre, der danner tegn. Det opdeler billedet i mindre segmenter og isolerer hvert tegn.
5. Tekstgenkendelse og udtræk
Softwaren sammenligner derefter disse isolerede former med en omfattende database af kendte tegnmønstre for at bestemme, hvad hvert tegn er. Softwaren udtrækker funktioner fra tegnene, såsom antallet af linjer, kurver eller vinkler. Disse funktioner hjælper OCR med at genkende og skelne mellem forskellige tegn.
6. Efterbehandling
Efter at tegnene er identificeret, gennemgår OCR-systemet en efterbehandlingsfase, hvor det retter eventuelle potentielle fejl og formaterer teksten til output. Den korrigerede tekst eksporteres derefter til det ønskede format, såsom et Word-dokument eller en søgbar PDF.
Anvendelsestilfælde med optisk tegngenkendelsessoftware
OCR er blevet et essentielt værktøj i den digitale transformation af mange industrier, der strømliner processer og forbedrer dataadgang og nøjagtighed. Du kan støde på OCR oftere, end du indser. Fra scanning af visitkort til digitalisering af gamle bøger spiller OCR en afgørende rolle i forskellige industrier. OCR-teknologi har en bred vifte af anvendelser:
-
Dokumentdigitalisering: OCR bruges til at konvertere trykte materialer såsom gamle bøger, aviser og historiske dokumenter til digitale formater, hvilket gør dem søgbare og bevarer dem for fremtidige generationer.
-
Formbehandling: Virksomheder udnytter OCR til automatisk at udtrække data fra formularer, hvilket reducerer manuel dataindtastning og øger effektiviteten i forskellige sektorer som finans og sundhedspleje.
-
Faktura behandling: OCR-teknologi kan læse tekst på fakturaer og automatisk indtaste dataene i finansielle systemer, hvilket strømliner regnskabs- og bogføringsprocesser.
-
Tilgængelighed: OCR muliggør tekst-til-tale-funktionalitet, der skaber lydversioner af tekst for synshandicappede, hvilket gør trykte materialer mere tilgængelige.
-
Mobilapplikationer: OCR er integreret i apps til opgaver som scanning af visitkort, genkendelse af tekst i fotos og facilitering af realtidsoversættelse.
-
Søgbarhed: OCR forbedrer søgbarheden af scannede dokumenter ved at udtrække tekst fra billeder eller PDF-filer, hvilket muliggør nem opslag og hentning af information.
-
Nummerpladegenkendelse: Bruges til parkering og trafikstyring kan OCR genkende nummerplader, hvilket muliggør effektiv overvågning og håndhævelse.
-
Forretningsdrift: OCR strømliner forretningsprocesser ved at automatisere dataindtastning fra dokumenter som fakturaer, kvitteringer og indkøbsordrer samt fremskynde rekruttering ved at scanne og behandle jobansøgninger og CV'er.
-
Juridiske og sundhedssektorer: Advokatfirmaer bruger OCR til at digitalisere sagsakter og juridiske dokumenter for lettere informationshentning, mens sundhedsudbydere bruger det til at konvertere patientjournaler og medicinske formularer til elektroniske sundhedsoptegnelser (EHR'er), hvilket forbedrer datastyring og patientpleje.
-
Uddannelse: I uddannelsesmiljøer bruges OCR til at skabe digitale lærebøger og læringsmaterialer, hvilket forbedrer tilgængeligheden for studerende med forskellige behov og understøtter et inkluderende læringsmiljø.
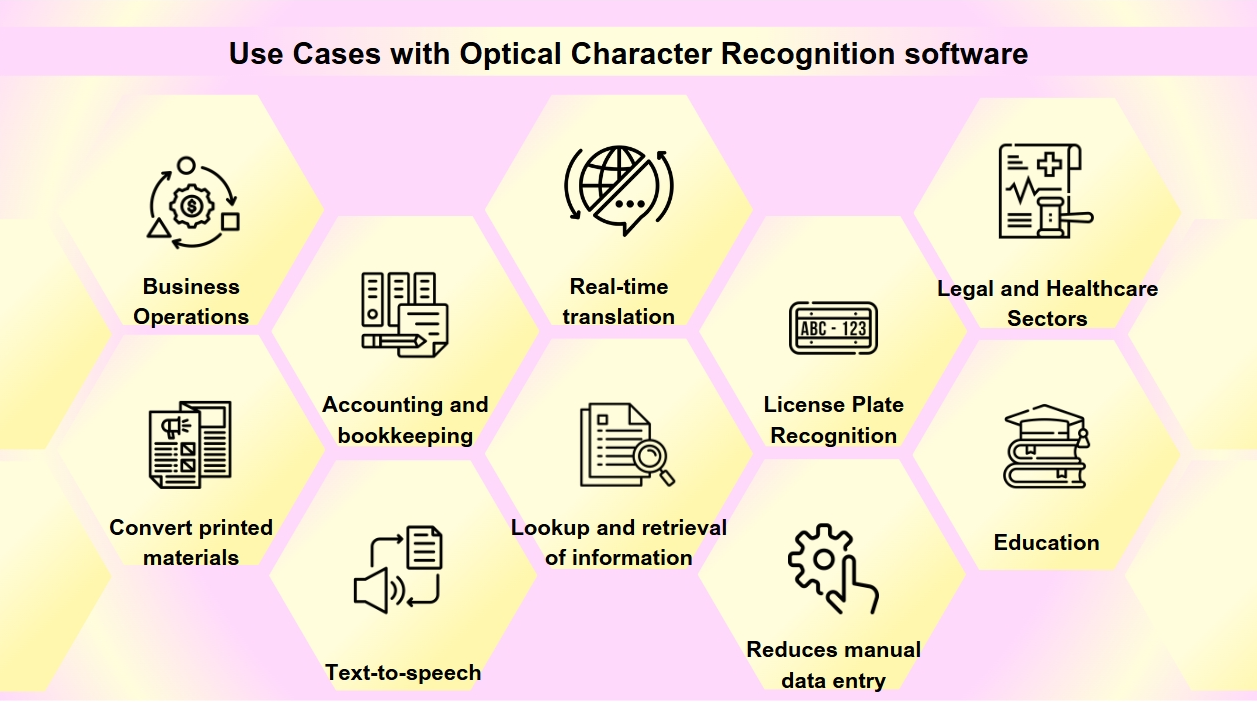
Som OCR-teknologien udvikler sig, fortsætter den med at spille en vital rolle i at gøre information mere tilgængelig og effektiv at håndtere i den digitale tidsalder.
Ulemperne ved OCR: Begrænsninger og udfordringer
Nøjagtighedsudfordringer
Selvom optisk tegngenkendelse (OCR) teknologi er kommet langt, står den stadig over for betydelige forhindringer i at opnå perfekt nøjagtighed. Håndskrevet tekst, usædvanlige skrifttyper eller billeder af dårlig kvalitet kan føre til misfortolkninger og fejl. Selv små variationer i tegnformer eller størrelser kan forvirre OCR-systemer, hvilket resulterer i utydelig output, der kræver manuel korrektion.
Sprog- og formatbegrænsninger
De fleste OCR-løsninger excellerer med standard sprog og formater, men kæmper med specialiseret indhold. Tekniske dokumenter, matematiske ligninger eller tekster med flere sprog kan udgøre betydelige udfordringer. Derudover kan OCR fejle, når den konfronteres med komplekse layout, tabeller eller dokumenter med indviklet formatering, hvilket potentielt kan miste afgørende strukturel information.
Ressourceintensitet
Implementering og vedligeholdelse af et effektivt OCR-system kan være ressourcekrævende. Højkvalitets OCR-software kommer ofte med en høj pris, og det hardware, der kræves for at behandle store mængder dokumenter, kan være kostbart. Desuden kan den tid og indsats, der kræves for at træne personale, finjustere systemet og manuelt gennemgå og korrigere OCR-output, belaste organisatoriske ressourcer.
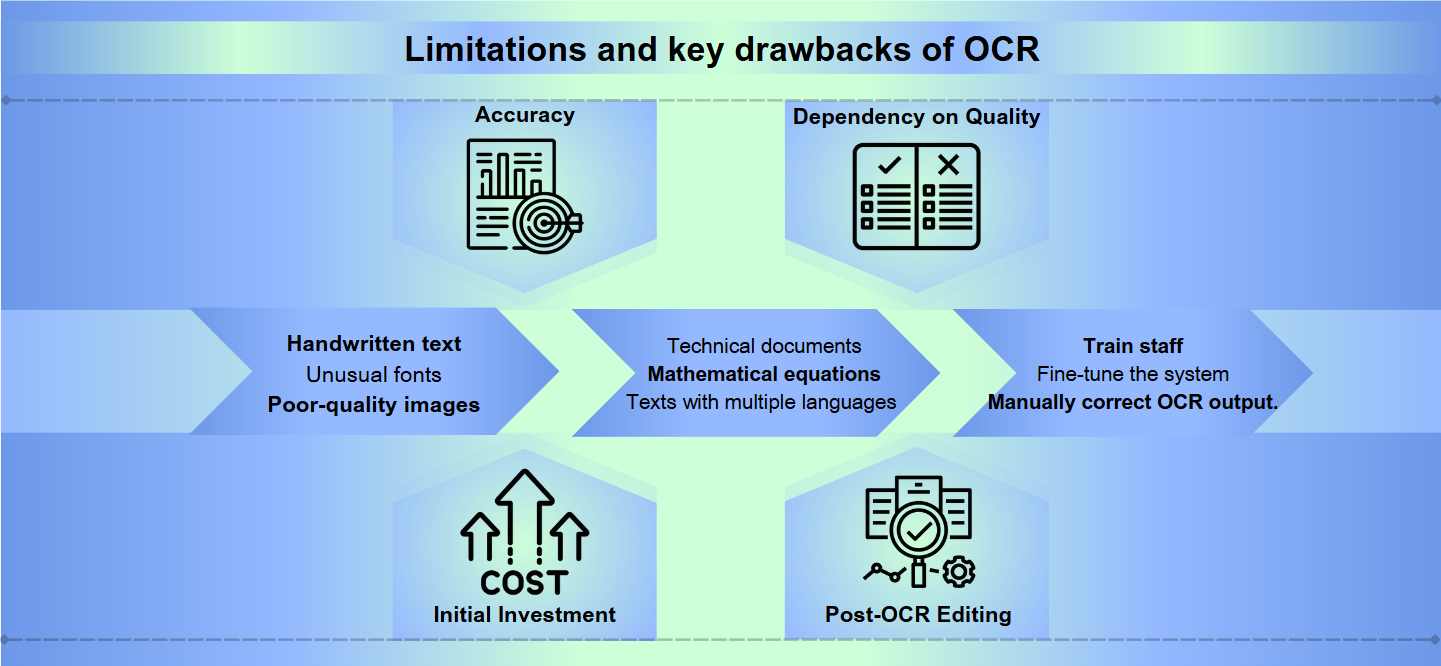
Nøgleulemper ved OCR
-
Nøjagtighed: OCR-software kan have problemer med nøjagtigheden, især når den arbejder med billeder af dårlig kvalitet, komplekse layout eller håndskrevet tekst. Fejl kan variere fra mislæsning af tegn til at springe hele sektioner af tekst over.
-
Afhængighed af kvalitet: Effektiviteten af OCR er stærkt afhængig af kvaliteten af det originale dokument. Fadede blæk, smudser eller krøllet papir kan føre til unøjagtige oversættelser.
-
Initial investering: Opsætning af et OCR-system kan kræve en betydelig upfront-omkostning, der inkluderer ikke kun softwaren, men også kompatibel hardware som scannere.
-
Efter-OCR redigering: Ofte kræver output fra OCR-processer manuel gennemgang og korrektion, hvilket kan være tidskrævende.
Vision Language Model overvinder OCR's begrænsninger
Som teknologien udvikler sig, dukker innovative løsninger op for at imødekomme manglerne ved traditionel optisk tegngenkendelse (OCR). Et sådant gennembrud er Vision Language Model (VLM), som kombinerer computer vision og naturlig sprogbehandling for at revolutionere tekstudtræk og forståelse.
Forbedret kontekstuel forståelse
VLM'er excellerer i at forstå konteksten omkring tekst, i modsætning til OCR's isolerede tegngenkendelse. Ved at analysere visuelle elementer sammen med tekst kan disse modeller fortolke komplekse layout, håndskrevne noter og endda delvist skjult tekst med bemærkelsesværdig nøjagtighed.
Flersproget og multimodal kapabiliteter
Mens OCR ofte kæmper med forskellige sprog og skrifter, viser VLM'er imponerende alsidighed. De kan problemfrit behandle flere sprog og endda fortolke visuelt indhold som diagrammer eller grafer, hvilket giver en mere omfattende forståelse af dokumenter.
Adaptiv læring og kontinuerlig forbedring
I modsætning til statiske OCR-systemer udnytter VLM'er maskinlæring til at tilpasse sig og forbedre sig over tid. Efterhånden som de møder nye data og scenarier, forfiner disse modeller deres præstation, hvilket gør dem stadig mere dygtige til at håndtere forskellige dokumenttyper og formater.
Ved at overvinde OCR's begrænsninger baner Vision Language Models vejen for mere nøjagtig, effektiv og intelligent dokumentbehandling på tværs af industrier.
Vælg Vision Language Model: Prøv AnyParser
Bygget på fremskridtene af Vision Language Models (VLM), fremstår AnyParser som en sofistikeret løsning, der transcenderer begrænsningerne ved traditionel OCR-teknologi. Udviklet af CambioML-teamet, er AnyParser et kraftfuldt dokumentparseringsværktøj, der udnytter en præcis og konfigurerbar API til at udtrække information fra forskellige ustrukturerede datakilder såsom PDF'er, billeder og diagrammer og konvertere dem til strukturerede formater.
Teknisk grundlag og kapabiliteter
AnyParser er forankret i det robuste fundament af store sprogmodeller (LLMs), der sikrer høj nøjagtighed i tekst-, tabel-, diagram- og layoutudtræk fra dokumenter. Det skiller sig ud med sin evne til at bevare det originale layout og format, en funktion der er særligt gavnlig for dokumenter med komplekse layout eller dem, der kræver bevarelse af den oprindelige æstetik.
Privatliv og sikkerhed
Med fokus på brugerens privatliv behandler AnyParser data lokalt, hvilket beskytter følsomme oplysninger. Denne funktion er en betydelig fordel for virksomheder og enkeltpersoner, der håndterer fortrolige data.
Tilpasningsevne og fleksibilitet
Med en høj grad af konfigurerbarhed giver AnyParser brugerne mulighed for at sætte tilpassede udtrækningsregler og definere outputformater, der passer til deres specifikke behov. Denne tilpasningsevne gør det til et ideelt værktøj til en bred vifte af anvendelser, fra AI-ingeniørarbejde til finansiel analyse.
Konklusion
Som du har lært, tilbyder OCR-teknologi kraftfulde kapaciteter til digitalisering af tekst, men den er ikke uden begrænsninger. Selvom optisk tegngenkendelse kan dramatisk forbedre effektiviteten, skal du nøje overveje de potentielle ulemper. Overvej nøjagtighedsproblemer, formateringsudfordringer og ressourcekrav, før du implementerer en OCR-løsning. I sidste ende afhænger beslutningen om at anvende OCR af dine specifikke behov og omstændigheder. Ved at forstå både fordelene og ulemperne kan du træffe en informeret beslutning om, hvorvidt OCR er det rigtige for din organisation. Efterhånden som OCR fortsætter med at udvikle sig, skal du holde dig ajour med nye udviklinger, der kan adressere nuværende mangler og låse op for endnu større potentiale for denne transformerende teknologi.
Call to Action
Omfavn kraften i Vision Language Models ved at prøve AnyParser gratis for at konvertere dine PDF'er til Google Sheets på https://www.cambioml.com/sandbox. Få en gratis konsultation om, hvordan VLM'er kan forbedre din dataudtrækningsarbejdsgang.