Hvad Er Strukturerede Data og Ustrukturerede Data
I den digitale informationstid genereres data hele tiden, og virksomheder skaber værdi gennem analyse og behandling af data. Derfor er indsamling og registrering af data samt behandling og analyse af data blevet to vigtige opgaver i forretningsdrift. I processen med dataindsamling støder man oftere på ustrukturerede data, hvis kilder og former er mangfoldige, og som er svære at klassificere eller søge i. Effektiv dataindtagelse er afgørende for organisationer for effektivt at transformere rådata til handlingsorienterede indsigter. I data behandlingsprocessen møder man oftere strukturerede data, som har en klar struktur, veldefineret information og kan nemt organiseres, søges og analyseres. Derfor er det en vigtig skridt for virksomheder at transformere ustrukturerede data til strukturerede data for at udnytte dataværdien.
Strukturerede Data
Strukturerede data er data, der passer ind i en foruddefineret datamodel eller skema. Det er særligt nyttigt til håndtering af diskrete, numeriske data såsom finansielle operationer, salgs- og marketingtal samt videnskabelig modellering.
Strukturerede data er typisk kvantitative og organiseret på en måde, der gør dem let søgbare. Det inkluderer almindelige typer som navne, adresser, kreditkortnumre, telefonnumre, stjernerangeringer, bankoplysninger og andre data, der nemt kan forespørges ved hjælp af SQL i relationelle databaser.
Eksempler på strukturerede data i virkelige applikationer inkluderer fly- og reservationsdata ved booking af en flyrejse samt kundeadfærd og præferencer i CRM-systemer som Salesforce. Det er bedst til tilknyttede samlinger af diskrete, korte, ikke-kontinuerlige numeriske og tekstværdier og anvendes til lagerkontrol, CRM-systemer og ERP-systemer.
Strukturerede data opbevares i relationelle databaser, grafdatabaser, rumlige databaser, OLAP-kuber og mere. Dens største fordel er, at den er lettere at organisere, rense, søge og analysere, men den største udfordring er, at alle data skal passe ind i den foreskrevne datamodel.
Ustrukturerede Data
Ustrukturerede data er data uden en underliggende model til at skelne attributter. Det anvendes, når data ikke passer ind i et struktureret dataformat, såsom videoovervågning, virksomheds dokumenter og indlæg på sociale medier.
Eksempler på ustrukturerede data inkluderer en række formater som e-mails, billeder, videofiler, lydfiler, indlæg på sociale medier, PDF-filer og mere. Cirka 80-90% af data er ustrukturerede, hvilket betyder, at der er et stort potentiale for konkurrencefordel, hvis virksomheder kan udnytte det.
Eksempler på ustrukturerede data i virkelige applikationer inkluderer chatbots, der udfører tekstanalyse for at besvare kundespørgsmål og give information, samt data, der bruges til at forudsige ændringer på aktiemarkedet til investeringsbeslutninger. Ustrukturerede data er bedst til tilknyttede samlinger af data, objekter eller filer, hvor attributterne ændrer sig eller er ukendte, og det anvendes med præsentations- eller tekstbehandlingssoftware og værktøjer til visning eller redigering af medier. Ustrukturerede supplerende tjenestedata, såsom indlæg på sociale medier og kundefeedback, kan give værdifulde indsigter, når de konverteres til strukturerede formater.
Det opbevares typisk i datalagre, NoSQL-databaser, datalagre og applikationer. Den største fordel ved ustrukturerede data er dens evne til at analysere data, der ikke let kan formes til strukturerede data, men den største udfordring er, at det kan være svært at analysere. Den primære analyseteknik for ustrukturerede data varierer afhængigt af konteksten og de anvendte værktøjer.
Forskellen mellem strukturerede og ustrukturerede data
Fordele ved Strukturerede Data og Ulemper ved Ustrukturerede Data
Strukturerede data tilbyder fordelen ved at være let søgbare og anvendelige til maskinlæringsalgoritmer, hvilket gør dem tilgængelige for virksomheder og organisationer til at fortolke data. Der er også flere værktøjer tilgængelige til at analysere strukturerede data end ustrukturerede data. På den anden side kræver ustrukturerede data, at dataforskere har ekspertise i at forberede og analysere dataene, hvilket kan begrænse andre medarbejdere i organisationen fra at få adgang til det. Derudover er der brug for særlige værktøjer til at håndtere ustrukturerede data, hvilket yderligere bidrager til dens manglende tilgængelighed.
Struktureret Dataanalyse vs. Ustruktureret Dataanalyse
Struktureret dataanalyse er typisk mere ligetil, fordi dataene er strengt formateret, hvilket muliggør brug af programmeringslogik til at søge efter og finde specifikke dataindtastninger samt at oprette, slette eller redigere indtastninger. Dette gør automatisering af datastyring og analyse af strukturerede data mere effektivt. I kontrast hertil har ustruktureret dataanalyse ikke foruddefinerede attributter, hvilket gør det sværere at søge og organisere. Ustruktureret dataanalyse kræver ofte komplekse algoritmer til at forbehandle, manipulere og analysere, hvilket udgør en større udfordring i analyseprocessen. Analysen af ustrukturerede supplerende tjenestedata kræver ofte avancerede parsingteknikker for at udtrække meningsfuld information.
Struktureret Datastyring vs. Ustruktureret Datastyring
Styringen af strukturerede data er generelt mere effektiv på grund af dens organiserede og forudsigelige natur. Computere, datastrukturer og programmeringssprog kan lettere forstå strukturerede data, hvilket fører til minimale udfordringer i dens anvendelse. Omvendt præsenterer ustruktureret datastyring to betydelige udfordringer: opbevaring, da ustruktureret datastyring typisk står over for større behandling end struktureret datastyring, og analyse, da ustruktureret datastyring ikke er så ligetil som analysen af struktureret datastyring. For at forstå og styre ustrukturerede data skal computersystemer først nedbryde det i forståelige komponenter, hvilket er en mere kompleks proces.
Sammenfatning af Forskellen mellem Strukturerede og Ustrukturerede Data
Strukturerede data er definerede og søgbare, herunder data som datoer, telefonnumre og produkt-SKU'er. Dette gør det lettere at organisere, rense, søge og analysere sammenlignet med ustrukturerede data, som omfatter alt andet, der er sværere at kategorisere eller søge i, såsom fotos, videoer, podcasts, indlæg på sociale medier og e-mails. Én sætning til at forklare forskellen mellem strukturerede og ustrukturerede data: Det meste af dataene i verden er ustrukturerede, men strukturerede datas lethed i håndtering og analyse giver det en betydelig fordel i applikationer, hvor data kan organiseres pænt og hurtigt tilgås.
Eksempler på Strukturerede og Ustrukturerede Data
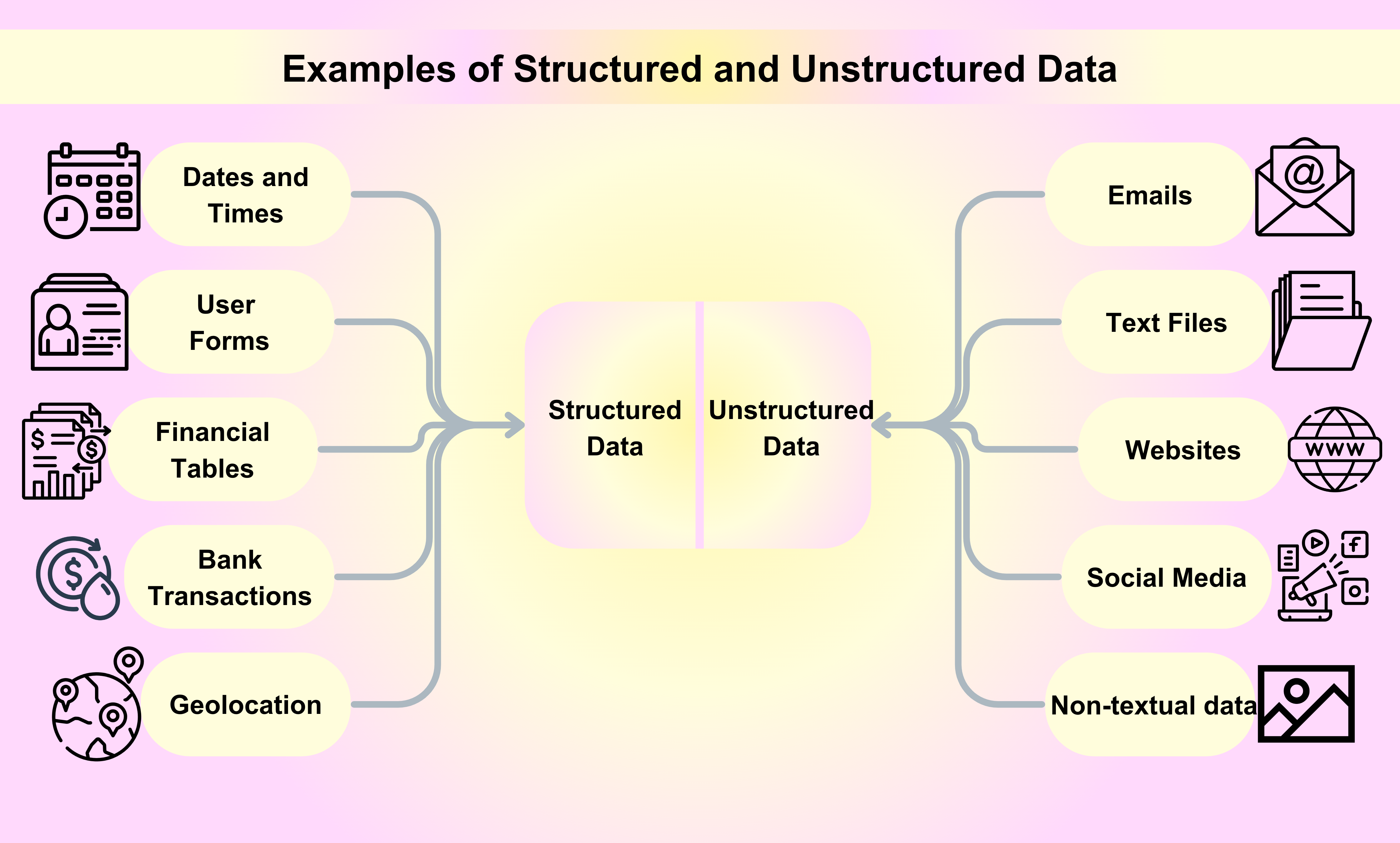
Eksempler på Strukturerede Data
-
Datoer og Tider: Datoer og tider følger et specifikt format, hvilket gør det nemt for maskiner at læse og analysere dem. For eksempel kan en dato struktureres som YYYY-MM-DD, mens en tid kan struktureres som HH:MM:SS.
-
Kundenavne og Kontaktinformation: Når du tilmelder dig en tjeneste eller køber et produkt online, indsamles og opbevares dit navn, e-mailadresse, telefonnummer og andre kontaktoplysninger på en struktureret måde.
-
Finansielle Transaktioner: Finansielle transaktioner såsom kreditkorttransaktioner, bankindskud og bankoverførsler er alle eksempler på strukturerede data. Hver transaktion kommer med specifik information i form af et serienummer, en transaktionsdato, beløbet og de involverede parter.
-
Aktieinformation: Aktieinformation såsom aktiekurser, handelsvolumener og markedsværdi er et andet eksempel på strukturerede data. Disse oplysninger er systematisk organiseret og opdateret i realtid.
-
Geolocation: Geolocation-data, herunder GPS-koordinater og IP-adresser, anvendes ofte i forskellige applikationer, fra navigationssystemer til placering-baserede marketingkampagner.
Eksempler på Ustrukturerede Data
-
E-mails: E-mails er blandt de mest populære eksempler på ustrukturerede data, vi bruger hver dag til forretnings- eller personlige formål.
-
Tekstfiler: Eksempler på ustrukturerede data inkluderer tekstbehandlingsfiler, regneark, PDF-filer, rapporter og præsentationer.
-
Websteder: Indhold fra websteder som YouTube, Instagram og Flickr betragtes som eksempler på ustrukturerede data.
-
Sociale Medier: Data genereret fra sociale medieplatforme som Facebook, Twitter og LinkedIn er eksempler på ustrukturerede data.
-
Medier: Digitale billeder, lydoptagelser og videoer repræsenterer en stor mængde ikke-tekstuelle data på en ustruktureret måde, der kan betragtes som eksempler på ustrukturerede data.
Teknikker til Analyse af Strukturerede Data
-
SQL Forespørgsler: Strukturerede data kan effektivt forespørges ved hjælp af SQL (Structured Query Language), som muliggør hurtig hentning og manipulation af data opbevaret i relationelle databaser.
-
Data Warehousing: Strukturerede data kan opbevares i datalagre, som integrerer data fra flere kilder og understøtter komplekse forespørgsler og analyser.
-
Maskinlæringsalgoritmer: Algoritmer kan let behandle strukturerede data for at identificere mønstre og lave forudsigelser.
Strukturerede data er lette at forstå og manipulere, hvilket gør dem tilgængelige for en bred vifte af brugere. Strukturerede data muliggør effektiv opbevaring, hentning og analyse, hvilket fremskynder beslutningsprocesser. Systemer til strukturerede data kan skalere til at håndtere store datamængder, hvilket sikrer, at ydeevnen forbliver høj, efterhånden som data vokser.
Teknikker til Analyse af Ustrukturerede Data
-
Natural Language Processing (NLP): NLP-teknikker bruges til at analysere tekstdata og udtrække meningsfuld information og indsigter fra store mængder ustruktureret tekst.
-
Maskinlæring: Maskinlæringsalgoritmer kan trænes til at genkende mønstre i ustrukturerede data, såsom billeder eller lydfiler.
-
Datalagre: Ustrukturerede data kan opbevares i datalagre, som tillader opbevaring af rådata i deres oprindelige format, indtil de er nødvendige til analyse.
Fra eksemplet med teknikker til analyse af ustrukturerede data er det mere komplekst at analysere ustrukturerede data og kræver specialiserede værktøjer og teknikker. Behandling af ustrukturerede data kræver ofte betydelige computerressourcer og lagerkapacitet. Ustrukturerede data kan indeholde inkonsistenser, fejl eller irrelevant information, hvilket gør det udfordrende at sikre datakvalitet. Strømlining af dataindtagelse kan betydeligt forbedre en organisations evne til at håndtere og analysere store datamængder.
Eksempler på Behovet for at Konvertere Ustrukturerede Data til Strukturerede Data
-
Analyse af Kunde Feedback: At konvertere kundeanmeldelser og feedback fra ustruktureret tekst til strukturerede data gør det muligt for virksomheder at udføre sentimentanalyse og identificere tendenser i kundetilfredshed.
-
Medicinske Journaler: At strukturere ustrukturerede medicinske journaler, såsom lægenotater og billedrapporter, muliggør bedre integration med elektroniske patientjournal (EHR) systemer og forbedrer patientpleje.
-
Overholdelse og Rapportering: Dataindtagelsesprocessen involverer udtrækning, indlæsning og transformation af data fra forskellige kilder til et format, der er egnet til analyse. Organisationer kan have brug for at konvertere ustrukturerede data til strukturerede formater for at overholde lovgivningsmæssige krav og lette nøjagtig rapportering.
-
Markedsundersøgelse: At konvertere ustrukturerede data fra undersøgelser og fokusgrupper til strukturerede data hjælper med at analysere markedstendenser og forbrugeradfærd.
Hvordan AnyParser Kan Parse Ustrukturerede Data til Strukturerede Data
AnyParser, udviklet af CambioML, er et kraftfuldt dokument parsing værktøj designet til at udtrække information fra forskellige ustrukturerede datakilder såsom PDF'er, billeder og diagrammer og konvertere dem til strukturerede formater. Det udnytter avancerede Vision Language Models (VLM'er) for at opnå høj nøjagtighed og effektivitet i dataudtrækning.
Nøglefunktioner
-
Præcision: Præcist udtrækker tekst, tal og symboler, mens den opretholder det oprindelige layout og format.
-
Privatliv: Behandler data lokalt for at sikre beskyttelse af brugerens privatliv og følsomme oplysninger.
-
Konfigurerbarhed: Giver brugerne mulighed for at definere brugerdefinerede udtrækningsregler og outputformater.
-
Multi-kilde Support: Understøtter udtrækning fra forskellige ustrukturerede datakilder, herunder PDF'er, billeder og diagrammer.
-
Struktureret Output: Konverterer udtrukket information til strukturerede formater såsom Markdown, CSV eller JSON.
Trin til at Parse Ustrukturerede Data ved Brug af AnyParser
-
Upload Dit Dokument: Begynd med at uploade din ustrukturerede datafil (f.eks. PDF, billede) til AnyParser's webgrænseflade. Du kan trække og slippe din fil eller indsætte et screenshot for hurtig behandling.
-
Vælg Udtrækningsmuligheder: Vælg den type data, du ønsker at udtrække. For eksempel, hvis du har brug for at udtrække tabeller fra en PDF, skal du vælge 'Kun Tabel' muligheden.
-
Behandl Dokumentet: AnyParser's API-motor vil behandle dokumentet, nøjagtigt detektere og udtrække de nødvendige oplysninger. Værktøjet bruger avancerede VLM-teknikker til at identificere relevante datapunkter og konvertere dem til et struktureret format.
-
Forhåndsvis og Bekræft: Gennemgå de udtrukne data ved hjælp af AnyParser's forhåndsvisningsfunktion. Sammenlign den indledende udtrækning med det oprindelige dokument for at sikre nøjagtighed.
-
Download eller Eksporter: Når du er tilfreds med udtrækningen, kan du downloade den strukturerede datafil (f.eks. CSV, Excel) eller eksportere den direkte til platforme som Google Sheets for yderligere analyse.
Fordele ved at Bruge AnyParser
-
Effektivitet og Nøjagtighed: Automatiserer dataudtrækningsopgaver, reducerer manuel indsats og minimerer fejl.
-
Datasikkerhed: Sikrer, at følsomme oplysninger behandles lokalt, i overensstemmelse med databeskyttelsesstandarder.
-
Fleksibel Tilpasning: Brugere kan tilpasse udtrækningsparametre og outputformater til specifikke behov.
-
Forbedret Analytisk Fokus: Forenkler dataudtrækning, så fagfolk kan fokusere på højere værdi-analyse.
Anvendelser
-
AI Ingeniører: Udtræk tekst og layoutinformation fra PDF'er for at udvikle og træne AI-modeller.
-
Finansanalytikere: Udtræk numeriske data fra PDF-tabeller for nøjagtig finansanalyse.
-
Dataforskere: Behandl store mængder ustrukturerede dokumenter for at afdække indsigter og tendenser.
-
Virksomheder: Automatiser behandlingen og analysen af forskellige dokumenter, såsom kontrakter og rapporter, for at forbedre driftsmæssig effektivitet.
Ved at udnytte AnyParser kan brugerne transformere komplekse ustrukturerede data til strukturerede, redigerbare filer, der sømløst integreres i deres arbejdsgange for forbedret dataanalyse og -styring.
Konklusion
I den digitale tidsalder er det afgørende for virksomheder at konvertere ustrukturerede data til strukturerede formater ved hjælp af værktøjer som AnyParser for at låse op for indsigter og opnå en konkurrencefordel. AnyParser kan anvendes til at parse ustrukturerede supplerende tjenestedata, hvilket gør det lettere at integrere i business intelligence-systemer. Ved at strømline denne proces kan organisationer effektivt udnytte det fulde potentiale af deres data, hvilket driver bedre beslutningstagning og strategisk planlægning.