Die Umwandlung komplexer PDFs in Markdown kann herausfordernd sein. Es gibt zahlreiche Open-Source-Bibliotheken, die Text aus PDFs extrahieren, aber wenn es um PDFs mit komplexen Elementen wie Tabellen und Diagrammen geht, sind die Ergebnisse oft unzureichend. Beliebte große Sprachmodelle wie GPT oder Claude können diese Aufgaben bewältigen, sind jedoch oft langsam und produzieren manchmal ungenaue Ausgaben. Traditionelle OCR-Tools sind zwar für einfachere Dokumente effektiv, haben jedoch oft Schwierigkeiten, die genaue Struktur und die semantische Bedeutung des ursprünglichen Inhalts beizubehalten. Auf der anderen Seite neigen Vision-Language-Modelle manchmal dazu, falsche Ergebnisse zu erzeugen, was zu fehlerhaften Parsing-Ergebnissen führt. Dieser Blog erklärt, was "parsen" bedeutet, und beschreibt die Ergebnisse einer vergleichenden Analyse mehrerer Modelle anhand verschiedener Metriken.
Was bedeutet "parsen"?
Im Kontext des PDF-Parsings bezieht sich "parsen" auf den Prozess der Extraktion spezifischer Daten aus einer PDF-Datei mithilfe spezialisierter Software, die als PDF-Parser bekannt ist. Ein PDF-Parser analysiert den Inhalt eines PDF-Dokuments und identifiziert Elemente wie Text, Bilder, Schriftarten, Layouts und sogar Metadaten. Die extrahierten Daten können dann organisiert und in verschiedene Formate wie XML, JSON oder Excel/CSV exportiert werden, die für verschiedene Zwecke wie Datenanalyse, Dokumentation oder Automatisierung von Arbeitsabläufen verwendet werden können.
Zu verstehen, was "parsen" bedeutet, ist entscheidend für die Bewertung der Effektivität einer Parsing-Lösung, insbesondere beim Vergleich verschiedener PDF-zu-Markdown-Konvertierungswerkzeuge, da das PDF-Parsen mehr als nur einfache Textextraktion umfasst – es erfordert das Erkennen und Beibehalten der semantischen Struktur des Dokuments.
Wie messen wir die Qualität dieser Parsing-Lösungen?
Wir haben eine Reihe von Wort-zu-Wort-Metriken definiert, um die Leistung verschiedener Modelle zu bewerten, wobei wir uns auf wichtige Faktoren wie konzentrieren:
-
Präzision, Recall und F-Maß: Bewertung der Qualität und Vollständigkeit des Parsings.
-
BLEU-Score und ANLS: Nützlich zur Bewertung von Sprache und Layoutstruktur.
-
Edit Distance, Jensen-Shannon-Divergenz und Jaccard-Distanz: Metriken, die spezifisch für den OCR-Bereich sind und besonders hilfreich sind, um die Genauigkeit der Inhaltserstellung zu verstehen.
Unser Vision-Language-Modell, AnyParser, zeigt eine außergewöhnliche Leistung, kombiniert Geschwindigkeit und Genauigkeit, insbesondere bei komplexen Layouts mit Tabellen und semantischen Elementen. AnyParser übertrifft andere Lösungen und bietet eine 20-fache Geschwindigkeitsverbesserung im Vergleich zu Modellen wie GPT/Claude, während es eine höhere Genauigkeit erreicht.
Eine umfassende Vergleichsanalyse gegen führende Parsing-Modelle
Statistisches Objekt
Um die Fähigkeiten von AnyParser wirklich zu demonstrieren, haben wir einen umfassenden Vergleich mit führenden Parsing-Modellen in der Branche und bekannten großen Sprachmodellen (LLMs) durchgeführt. Unsere Bewertung umfasste:
1. Große Sprachmodelle
- AnyParser
- OpenAI's GPT-4o
- Googles Gemini 1.5 Pro
- Anthropics Claude 3.5 Sonnet
2. OCR-basierte Dienste
- LlamaParse
- Amazon Textract
- Google Cloud Document AI
- Azure Document Intelligence
Ergebnispräsentation und Analyse
Experiment 1
Zunächst führen wir eine Reihe strenger Vergleiche der Leistung verschiedener Dokumenten-AI-Modelle anhand der folgenden über 5 Metriken durch: BLEU, Präzision und Recall, F-Maß und ANLS. Die mathematische Definition dieser Metriken finden Sie im Anhang.
Die verglichenen Modelle sind: AnyParser-base, AnyParser-pro, Textract, Llama-Parse, GPT4o, Gemini-1.5-pro, GCP-DocAl und Azure-DocAl.
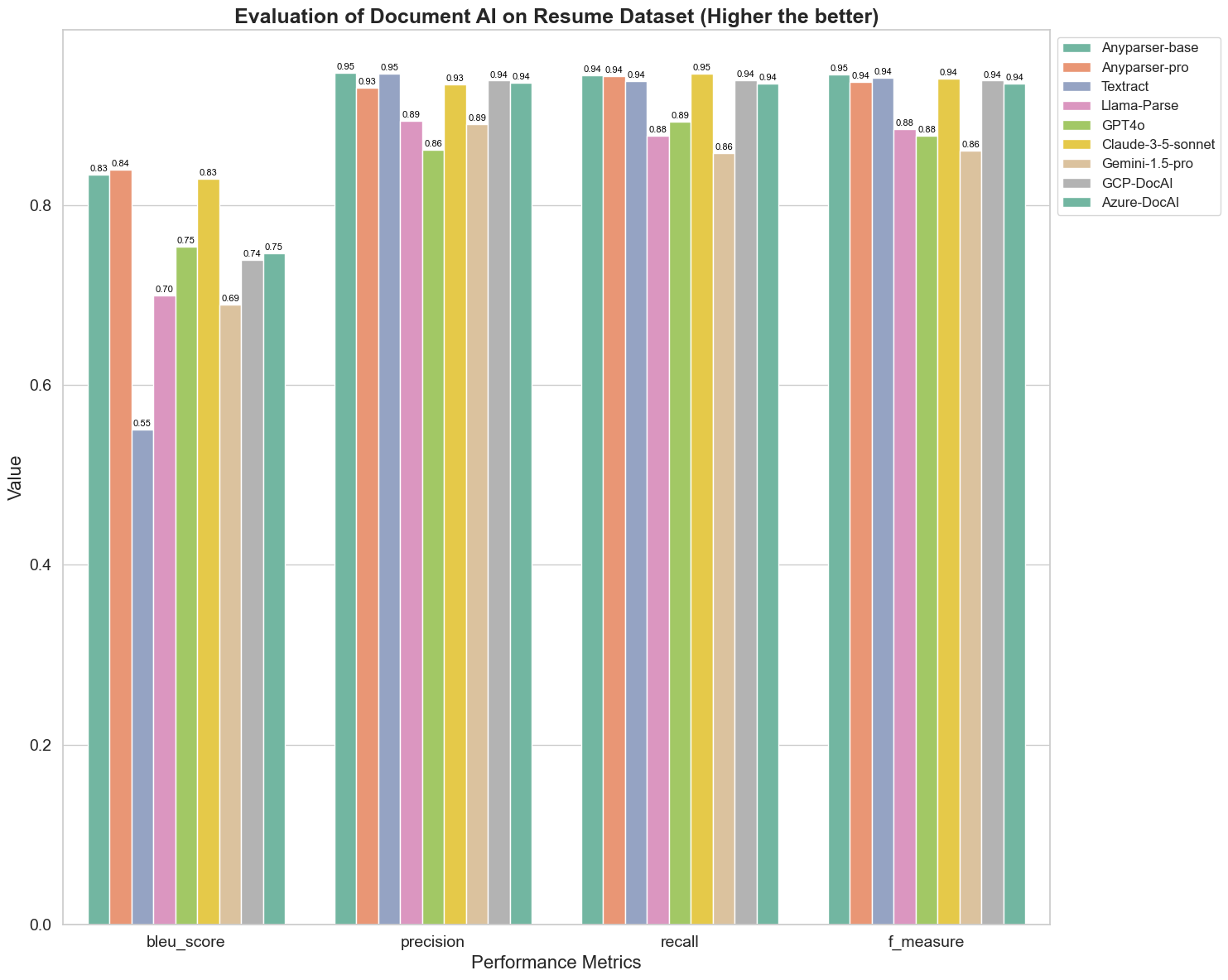
BLEU wird als Bewertungsmaß für die Qualität der zweisprachigen Interpretation verwendet, um die Qualität der Modelle bei der Verarbeitung von Äußerungen zu testen. Durch den Vergleich der Ergebnisse dieser Parsing-Modelle unter der BLEU-Bewertungsmethode stellen wir fest, dass die Scores von AnyParser-base und AnyParser-pro deutlich höher sind als die Scores der anderen Modelle, während Amazon Textract die niedrigsten Werte erzielt und die Ergebnisse der anderen Modelle im mittleren Bereich eines relativ durchschnittlichen Niveaus liegen.
Die Erkennungsgenauigkeit wird normalerweise durch Präzision und Recall dargestellt, wobei die Präzision den Prozentsatz der tatsächlich korrekten Ergebnisse unter den als korrekt bewerteten Ergebnissen des Modells darstellt und der Recall den Prozentsatz der tatsächlich korrekt bewerteten Ergebnisse des Modells unter allen tatsächlich korrekten Ergebnissen darstellt. Durch den Vergleich der Präzision und des Recalls dieser Parsing-Modelle stellen wir fest, dass: mit Ausnahme von Llama-Parse, GPT4o und Gemini-1.5-pro alle anderen Modelle auf einem hohen Niveau sind. Darunter sind AnyParser und Amazon Textract in der Präzision ausgeprägter, während AnyParser-base und AnyParser-pro im Recall herausstechen. Der höhere Score des Modells bei der Präzision zeigt an, dass das Modell mehr korrekte Informationen in den Produktionsergebnissen ausgibt, und der höhere Score beim Recall zeigt an, dass das Modell besser in der Lage ist, korrekte Informationen aus der Probe zu gewinnen. Die Ergebnisse zeigen, dass AnyParser einen klaren Vorteil in Bezug auf die Erkennungsgenauigkeit beim Extrahieren von Text aus PDFs hat.
Das F-Maß ist ein umfassender Bewertungsindex für Präzision und Recall bei diesen beiden Indikatoren. Durch den Vergleich der Scores dieser Parsing-Modelle unter dem F-Maß können wir intuitiver erkennen, dass die fünf Modelle, AnyParser-base, AnyParser-pro, Amazon Textract, GCP-DocAI und Azure-DocAI, in Bezug auf die Erkennungsgenauigkeit besser abschneiden als andere Modelle. Wir können intuitiver sehen, dass die fünf Modelle in der Erkennungsgenauigkeit stärker sind als die anderen Modelle, und AnyParser hat den höchsten Score unter dem F-Maß, was den offensichtlichen Vorteil von AnyParser in der Erkennungsgenauigkeit beim Extrahieren von Text aus PDFs weiter verdeutlicht.
ANLS, als gängiger Bewertungsindex zur Messung der Genauigkeit und Ähnlichkeit zwischen dem Originaltext und dem Zieltext auf Zeichenebene, ist ebenfalls sehr informativ zur Messung des Parsing-Niveaus der Modelle. Die höheren Scores von AnyParser-base, AnyParser-pro und Azure-DocAI spiegeln das höhere Parsing-Niveau dieser Modelle im Vergleich zu den anderen Modellen wider.
Insgesamt übertreffen AnyParser-base und AnyParser-pro die anderen Modelle.
Experiment 2
Wir vergleichen auch die Leistung verschiedener Dokumenten-AI-Modelle anhand von drei verschiedenen Metriken: Edit Distance, Jensen-Shannon-Divergenz und Jaccard-Distanz. Die Metriken werden verwendet, um die Ähnlichkeit zwischen den Ausgaben der Modelle und einem Referenzdokument zu messen. Niedrigere Werte deuten auf eine bessere Leistung hin.
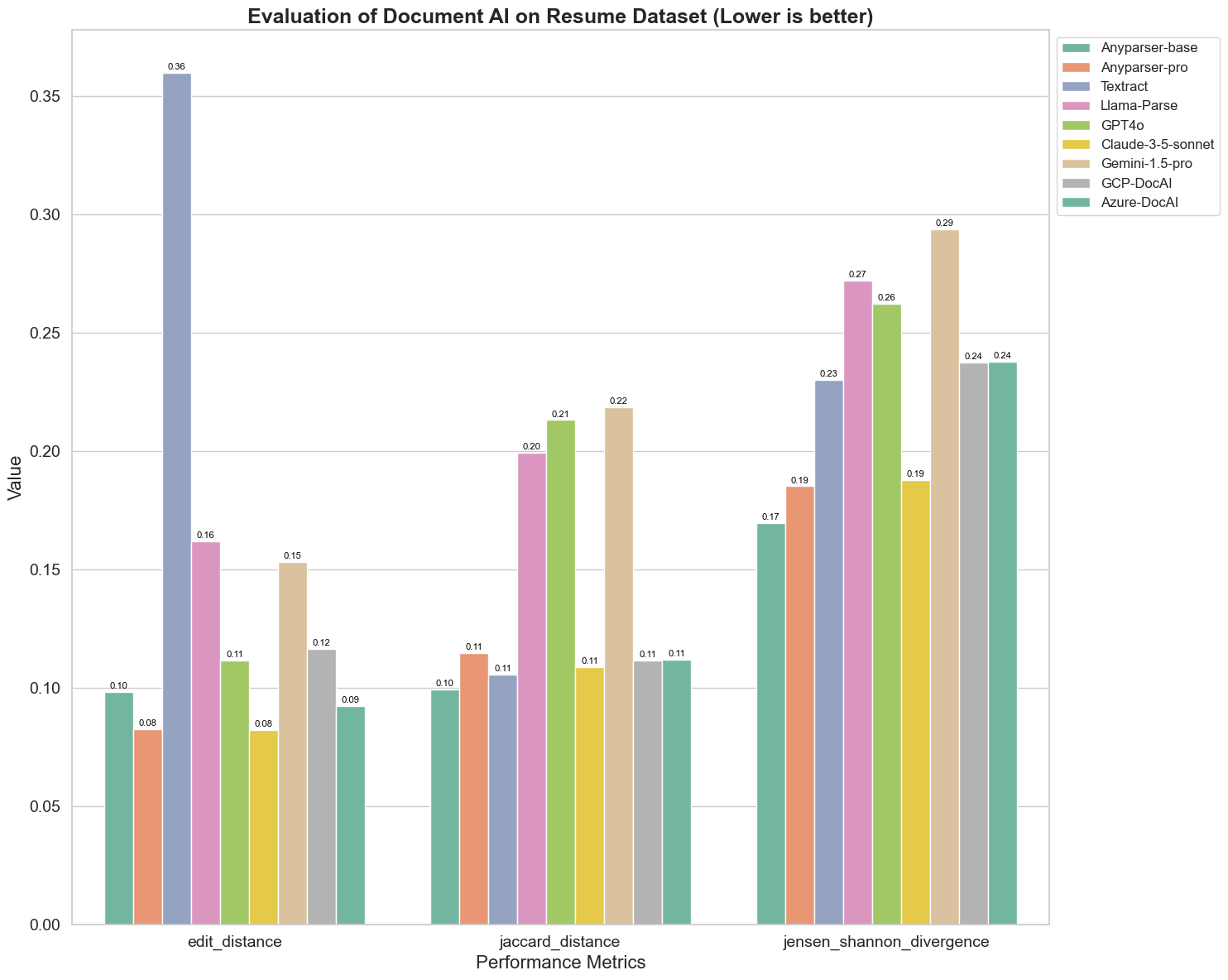
Hier sind einige wichtige Beobachtungen aus dem Diagramm:
-
Edit Distance: Die Modelle AnyParser-base und AnyParser-pro schneiden am besten ab mit der niedrigsten Edit Distance, was darauf hindeutet, dass ihre Ausgaben den Referenzdokumenten am nächsten kommen.
-
Jensen-Shannon-Divergenz: Die Modelle AnyParser-base und AnyParser-pro haben die niedrigste Divergenz, was impliziert, dass ihre Ausgaben in Bezug auf die Wortverteilung am ähnlichsten zum Referenzdokument sind.
-
Jaccard-Distanz: Abgesehen von Llama-Parse, GPT4O und Gemini-1.5 schneiden alle anderen Modelle anständig ab mit der niedrigsten Jaccard-Distanz, was darauf hinweist, dass ihre Ausgaben die höchste Überlappung mit dem Referenzdokument in Bezug auf die verwendeten Wörter haben.
Fazit
Insgesamt deutet unser rigoroser Test darauf hin, dass AnyParser-base und AnyParser-pro im Allgemeinen gut über verschiedene Metriken hinweg abschneiden, was auf ihr Potenzial für eine genaue Dokumentenverarbeitung hinweist. Aus den Diagrammen geht hervor, dass traditionelle OCR-Modelle wie das bekannte Amazon Textract deutlich schlechter abschneiden als Vision-Language-Modelle. Die Leistung verschiedener Modelle variiert jedoch je nach verwendeter Metrik, was die Bedeutung der Berücksichtigung mehrerer Bewertungskriterien beim Vergleich von KI-Modellen hervorhebt.
Einführung unserer Open-Source-Bewertungspipeline
Um die Bewertungen zu optimieren, haben wir eine Bewertungspipeline erstellt, die eine branchenübliche Methode zum Vergleich von Parsing-Modellen bietet. In unserem Beispiel demonstrieren wir ihre Verwendung im HR-Bereich, wo das Parsing von Lebensläufen üblich ist. Wir haben einen vielfältigen synthetischen Datensatz von 128 Lebensläufen erstellt, der mit gepaarten Bild-Markdown-Dateien generiert wurde. Mithilfe von GPT-4 haben wir HTML-Inhalte generiert, diese in Bilder gerendert und den extrahierten Text als Grundlage für den Vergleich verwendet.
Und das Beste daran: Wir haben dieses Bewertungsframework auf GitHub als Open Source veröffentlicht! Egal, ob Sie Entwickler oder Geschäftsanwender sind, unsere Pipeline ermöglicht es Ihnen, die Parsing-Qualität verschiedener Modelle mit Ihrem eigenen Datensatz zu bewerten und zu vergleichen.
Finden Sie die Schnellstartanleitung im Github-Repo und sehen Sie, wie verschiedene Parsing-Modelle im Vergleich zueinander abschneiden. Wir glauben, dass wir durch die Präsentation der Stärken unseres Modells im offenen Raum mehr Benutzer anziehen können, die zuverlässige, schnelle und genaue Parsing-Funktionen wünschen.
Anhang - Metriken
1. Präzision
Die Präzision misst die Genauigkeit des geparsten Inhalts und zeigt, wie viele der abgerufenen Elemente korrekt waren. Beim Parsen ist es der Anteil der korrekt extrahierten Wörter an allen extrahierten Wörtern.
Präzision = Wahre Positive (TP) / (Wahre Positive (TP) + Falsche Positive (FP))
- Wahre Positive (TP): Wörter, die korrekt vom Parser identifiziert wurden.
- Falsche Positive (FP): Wörter, die fälschlicherweise vom Parser identifiziert wurden.
2. Recall
Der Recall gibt die Vollständigkeit des Parsings an oder wie viele relevante Wörter aus dem ursprünglichen Dokument abgerufen wurden.
Recall = Wahre Positive (TP) / (Wahre Positive (TP) + Falsche Negative (FN))
- Falsche Negative (FN): Wörter im ursprünglichen Dokument, die vom Parser übersehen wurden.
3. F-Maß (F1-Score)
Der F1-Score ist das harmonische Mittel von Präzision und Recall und balanciert beide Metriken, um eine Gesamteinschätzung der Parsing-Qualität zu geben.
F1-Score = 2 × (Präzision × Recall) / (Präzision + Recall)
4. BLEU-Score (Bilingual Evaluation Understudy)
Der BLEU-Score misst die Ähnlichkeit zwischen dem geparsten Inhalt und dem Originaltext und legt besonderen Wert auf die Reihenfolge der Wörter. Er ist besonders nützlich zur Bewertung der Sprach- und Strukturkonsistenz in geparsten Dokumenten, da er Ausgaben bestraft, die in der Reihenfolge vom Original abweichen.
5. ANLS (Durchschnittliche Normalisierte Levenshtein-Ähnlichkeit)
ANLS quantifiziert die Ähnlichkeit zwischen dem geparsten Inhalt und dem Original unter Verwendung der normalisierten Edit-Distanz. Er wird berechnet, indem die Normalisierte Levenshtein-Ähnlichkeit (NLS) für jedes Wortpaar in den geparsten und Referenztexten gemittelt wird. Die NLS wird wie folgt berechnet:
NLS = 1 - (Levenshtein-Distanz (LD)(geparstes Wort, ursprüngliches Wort)) / max(Länge des geparsten Wortes, Länge des ursprünglichen Wortes)
Dann ist der ANLS der Durchschnitt der NLS über alle Wortpaare:
ANLS = (1/N) × Σ(NLS_i) für i=1 bis N
6. Edit Distance
Die Edit-Distanz berechnet die Anzahl der Operationen auf Wortebene (Einfügungen, Löschungen, Ersetzungen), die erforderlich sind, um den geparsten Text in das Original zu konvertieren.
7. Jensen-Shannon-Divergenz
Die Jensen-Shannon-Divergenz misst die Ähnlichkeit zwischen diskreten Wahrscheinlichkeitsverteilungen der geparsten und ursprünglichen Wortzählungen und hebt Unterschiede in der Wortfrequenz hervor.
JSD(P || Q) = (1/2) × KL(P || M) + (1/2) × KL(Q || M)
wobei M = (1/2)(P + Q) und KL(P || Q) die Kullback-Leibler-Divergenz ist
8. Jaccard-Distanz
Die Jaccard-Distanz misst die Unähnlichkeit zwischen Wortgruppen im geparsten und ursprünglichen Inhalt und ist nützlich zur Bewertung der Wortüberlappung.
Jaccard-Distanz = 1 - |A ∩ B| / |A ∪ B|
wobei |A ∩ B| die Anzahl der gemeinsamen Elemente zwischen A und B ist,
und |A ∪ B| die Gesamtzahl der einzigartigen Elemente in beiden Mengen.