Convertir PDFs complejos en Markdown puede ser un desafío. Hay muchas bibliotecas de código abierto disponibles para extraer texto de PDF, pero cuando se trata de PDFs que contienen elementos complejos como tablas y gráficos, los resultados a menudo son insatisfactorios. Modelos de lenguaje grandes populares como GPT o Claude pueden manejar estas tareas, pero tienden a ser lentos y, a veces, producen salidas inexactas. Las herramientas OCR tradicionales, aunque efectivas para documentos más simples, a menudo luchan por mantener la estructura exacta y el significado semántico del contenido original. Por otro lado, los modelos de lenguaje visual a veces alucinan, lo que lleva a resultados de análisis erróneos. Este blog explicará qué significa analizar y detallará los resultados de un análisis comparativo de múltiples modelos utilizando múltiples métricas.
¿Qué significa analizar?
En el contexto del análisis de PDF, "analizar" se refiere al proceso de extraer datos específicos de un archivo PDF utilizando software especializado conocido como analizador de PDF. Un analizador de PDF analiza el contenido de un documento PDF e identifica elementos como texto, imágenes, fuentes, diseños e incluso metadatos. Los datos extraídos pueden organizarse y exportarse a diferentes formatos como XML, JSON o Excel/CSV, que se pueden utilizar para diversos propósitos como análisis de datos, mantenimiento de registros o automatización de flujos de trabajo.
Entender qué significa analizar es esencial para evaluar la efectividad de una solución de análisis, especialmente al comparar diferentes herramientas de conversión de PDF a Markdown, ya que el analizador de PDF implica más que solo una simple extracción de texto; requiere reconocer y mantener la estructura semántica del documento.
¿Cómo medimos la calidad de estas soluciones de análisis?
Hemos definido una serie de métricas a nivel de palabra para evaluar el rendimiento de diferentes modelos, centrándonos en factores clave como:
-
Precisión, Recuperación y F-Medida: Evaluando la calidad y la completitud del análisis.
-
Puntuación BLEU y ANLS: Útiles para evaluar la estructura del lenguaje y el diseño.
-
Distancia de Edición, Divergencia de Jensen-Shannon y Distancia de Jaccard: Métricas específicas del dominio OCR, particularmente útiles para entender la exactitud de la reproducción del contenido.
Nuestro modelo de lenguaje visual, AnyParser, demuestra un rendimiento excepcional, combinando velocidad y precisión, especialmente en diseños complejos con tablas y elementos semánticos. AnyParser supera a otras soluciones, ofreciendo una mejora de velocidad de 20 veces en comparación con modelos como GPT/Claude, mientras logra una mayor precisión.
Un extenso resultado de comparación contra modelos de análisis líderes
Objeto estadístico
Para mostrar verdaderamente las capacidades de AnyParser, realizamos una comparación exhaustiva contra modelos de análisis líderes en la industria y modelos de lenguaje grande (LLMs) bien conocidos. Nuestra evaluación incluyó:
1. Modelos de Lenguaje Grande
- AnyParser
- GPT-4o de OpenAI
- Gemini 1.5 Pro de Google
- Claude 3.5 Sonnet de Anthropic
2. Servicios Basados en OCR
- LlamaParse
- Amazon Textract
- Google Cloud Document AI
- Azure Document Intelligence
Presentación y análisis de resultados
Experimento 1
Primero, realizamos una serie de comparaciones rigurosas del rendimiento de diferentes modelos de IA de documentos en más de 5 métricas a continuación: BLEU, Precisión y recuperación, F-Medida y ANLS. Puede encontrar la definición matemática de estas métricas en el apéndice.
Los modelos comparados son: AnyParser-base, AnyParser-pro, Textract, Llama-Parse, GPT4o, Gemini-1.5-pro, GCP-DocAl y Azure-DocAl.
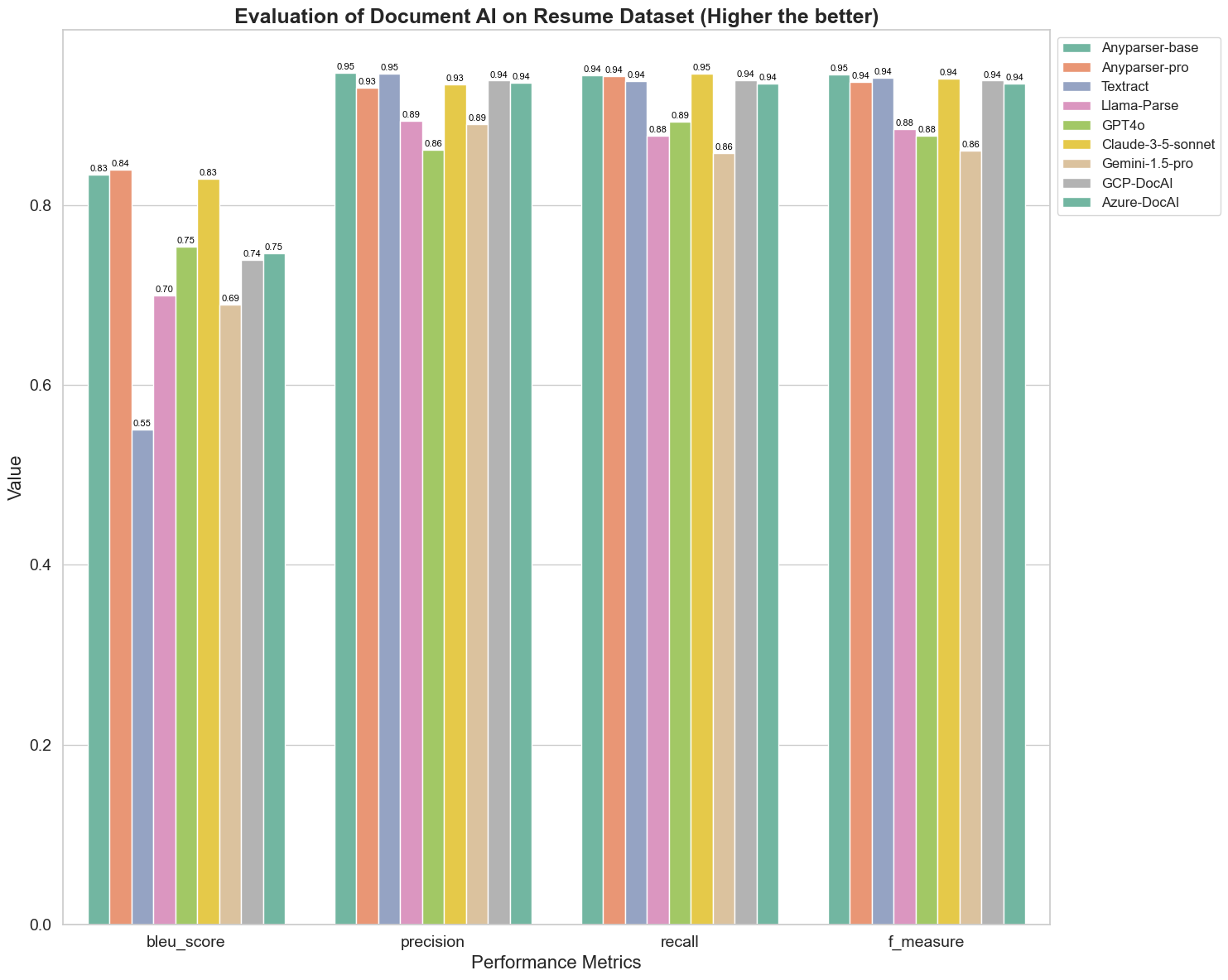
BLEU se utiliza como una evaluación de la calidad de la interpretación bilingüe para probar la calidad de los modelos en el procesamiento de enunciados. Al comparar los resultados de estos modelos de análisis bajo el método de evaluación BLEU, encontramos que: las puntuaciones de AnyParser-base y AnyParser-pro son significativamente más altas que las puntuaciones de los otros modelos, Amazon Textract tiene la puntuación más baja, y los resultados de las puntuaciones de los otros modelos están en un nivel relativamente promedio.
La precisión de reconocimiento generalmente se representa mediante precisión y recuperación, donde la precisión representa el porcentaje de resultados verdaderamente correctos entre los resultados juzgados como correctos por el modelo, y la recuperación representa el porcentaje de resultados verdaderamente correctos juzgados por el modelo entre todos los resultados realmente correctos. Al comparar la precisión y la recuperación de estos modelos de análisis, encontramos que: excepto por Llama-Parse, GPT4o y Gemini-1.5-pro, todos los demás modelos están en un nivel alto. Entre ellos, AnyParser y Amazon Textract son más destacados en precisión, y AnyParser-base y AnyParser-pro son más destacados en recuperación. La puntuación más alta del modelo en Precisión indica que el modelo produce más información correcta en los resultados de producción, y la puntuación más alta en recuperación indica que el modelo es más capaz de obtener información correcta de la muestra. Los resultados de las puntuaciones muestran que AnyParser tiene una clara ventaja en términos de precisión de reconocimiento para extraer texto de PDF.
La F-Medida es un índice de evaluación integral de precisión y recuperación en estos dos indicadores. Al comparar las puntuaciones de estos modelos de análisis bajo la F-Medida, podemos ver más intuitivamente que los cinco modelos, AnyParser-base, AnyParser-pro, Amazon Textract, GCP-DocAI y Azure-DocAI, tienen una mejor fortaleza en términos de precisión de reconocimiento en comparación con otros modelos. Podemos ver más intuitivamente que los cinco modelos tienen más fortaleza en precisión de reconocimiento que los otros modelos, y AnyParser tiene la puntuación más alta bajo la F-Medida, lo que ilustra aún más la clara ventaja de AnyParser en precisión de reconocimiento para extraer texto de PDF.
ANLS, como un índice de evaluación comúnmente utilizado cuando se trata de medir la precisión y la similitud entre el texto original y el texto objetivo a nivel de caracteres, también es muy informativo para medir el nivel de análisis de los modelos. Las puntuaciones más altas de AnyParser-base, AnyParser-pro y Azure-DocAI reflejan el nivel de análisis más alto de estos modelos en comparación con los otros modelos.
En general, AnyParser-base y AnyParser-pro superan a los otros modelos.
Experimento 2
También comparamos el rendimiento de diferentes modelos de IA de documentos en tres métricas diferentes: Distancia de Edición, Divergencia de Jensen-Shannon y Distancia de Jaccard. Las métricas se utilizan para medir la similitud entre la salida de los modelos y un documento de referencia. Valores más bajos indican un mejor rendimiento.
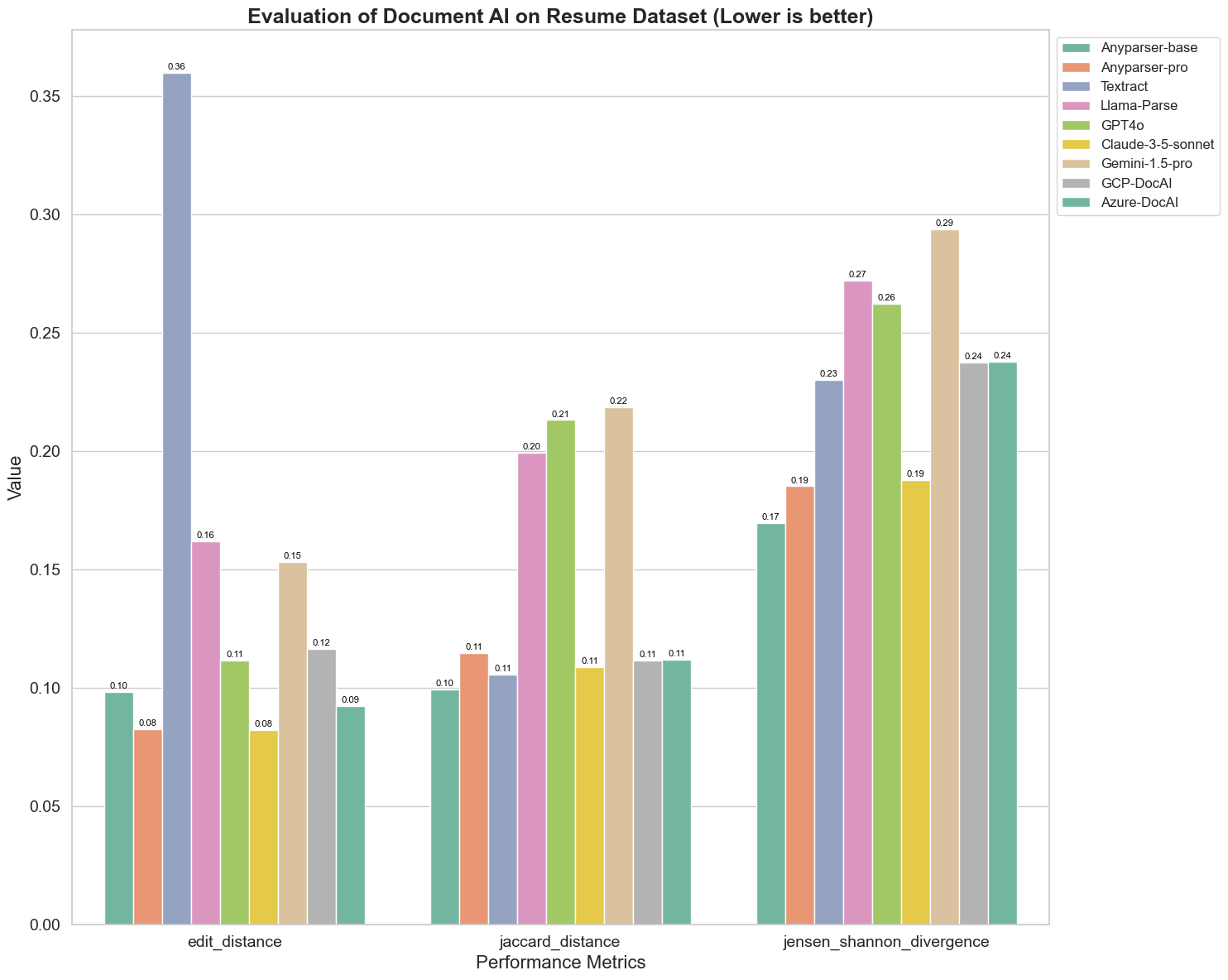
Aquí hay algunas observaciones clave del gráfico:
-
Distancia de Edición: Los modelos AnyParser-base y AnyParser-pro tienen el mejor rendimiento con la menor distancia de edición, lo que sugiere que su salida fue la más cercana al documento de referencia.
-
Divergencia de Jensen-Shannon: Los modelos AnyParser-base y AnyParser-pro tienen la menor divergencia, lo que implica que sus salidas son las más similares al documento de referencia en términos de distribución de palabras.
-
Distancia de Jaccard: Más allá de Llama-parse, GPT4O, Gemini-1.5, todos los demás modelos tienen un rendimiento decente con la menor distancia de Jaccard, lo que indica que su salida tiene la mayor superposición con el documento de referencia en términos del conjunto de palabras utilizadas.
Conclusión
En general, nuestras pruebas rigurosas sugieren que AnyParser-base y AnyParser-pro generalmente tienen un buen rendimiento en varias métricas, lo que indica su potencial para un procesamiento preciso de documentos. A partir de los gráficos, podemos ver que los modelos OCR tradicionales, como el famoso Amazon Textract, obtienen puntuaciones mucho más bajas que los modelos de lenguaje visual. Sin embargo, el rendimiento de los diferentes modelos varía según la métrica utilizada, lo que resalta la importancia de considerar múltiples criterios de evaluación al comparar modelos de IA.
Presentando Nuestro Pipeline de Evaluación de Código Abierto
Para agilizar las evaluaciones, hemos creado un pipeline de evaluación que proporciona un método estándar de la industria para comparar modelos de análisis. En nuestro ejemplo, demostramos su uso en el dominio de RRHH, donde el análisis de currículos es común. Construimos un conjunto de datos sintético diverso de 128 currículos, generados utilizando archivos de imagen-Markdown emparejados. Usando GPT-4, generamos contenido HTML, lo renderizamos en imágenes y utilizamos el texto extraído como verdad fundamental para la comparación.
Y aquí está la mejor parte: ¡hemos liberado este marco de evaluación como código abierto en GitHub! Ya sea que sea un desarrollador o un usuario empresarial, nuestro pipeline le permite evaluar y comparar la calidad de análisis de diferentes modelos en su propio conjunto de datos.
Encuentre la guía de inicio rápido en el repositorio de Github y vea cómo se comparan los diferentes modelos de análisis entre sí. Creemos que al mostrar la fortaleza de nuestro modelo de manera abierta, podemos atraer a más usuarios que buscan capacidades de análisis confiables, rápidas y precisas.
Apéndice - Métricas
1. Precisión
La precisión mide la exactitud del contenido analizado, mostrando cuántos de los elementos recuperados eran correctos. En el análisis, es la proporción de palabras extraídas correctamente de todas las palabras extraídas.
Precisión = Verdaderos Positivos (TP) / (Verdaderos Positivos (TP) + Falsos Positivos (FP))
- Verdaderos Positivos (TP): Palabras identificadas correctamente por el analizador.
- Falsos Positivos (FP): Palabras identificadas incorrectamente por el analizador.
2. Recuperación
La recuperación indica la completitud del análisis, o cuántas palabras relevantes del documento original fueron recuperadas.
Recuperación = Verdaderos Positivos (TP) / (Verdaderos Positivos (TP) + Falsos Negativos (FN))
- Falsos Negativos (FN): Palabras en el documento original que fueron omitidas por el analizador.
3. F-Medida (Puntuación F1)
La Puntuación F1 es la media armónica de la Precisión y la Recuperación, equilibrando ambas métricas para dar una medida general de la calidad del análisis.
Puntuación F1 = 2 × (Precisión × Recuperación) / (Precisión + Recuperación)
4. Puntuación BLEU (Evaluación Bilingüe)
La puntuación BLEU mide la similitud entre el contenido analizado y el texto original, poniendo especial énfasis en el orden de las palabras. Es particularmente útil para evaluar la consistencia del lenguaje y la estructura en documentos analizados, ya que penaliza las salidas que difieren en secuencia del original.
5. ANLS (Similitud de Levenshtein Normalizada Promedio)
ANLS cuantifica la similitud entre el contenido analizado y el original, utilizando la distancia de edición normalizada. Se calcula promediando la Similitud de Levenshtein Normalizada (NLS) para cada par de palabras en los textos analizados y de referencia. La NLS se calcula de la siguiente manera:
NLS = 1 - (Distancia de Levenshtein (LD)(palabra analizada, palabra original)) / max(Longitud de la palabra analizada, Longitud de la palabra original)
Luego, el ANLS es el promedio de NLS a través de todos los pares de palabras:
ANLS = (1/N) × Σ(NLS_i) para i=1 hasta N
6. Distancia de Edición
La Distancia de Edición calcula el número de operaciones a nivel de palabra (inserciones, eliminaciones, sustituciones) requeridas para convertir el texto analizado al original.
7. Divergencia de Jensen-Shannon
La Divergencia de Jensen-Shannon mide la similitud entre distribuciones de probabilidad discretas de conteos de palabras analizadas y originales, destacando diferencias en la frecuencia de palabras.
JSD(P || Q) = (1/2) × KL(P || M) + (1/2) × KL(Q || M)
donde M = (1/2)(P + Q), y KL(P || Q) es la divergencia de Kullback-Leibler
8. Distancia de Jaccard
La Distancia de Jaccard mide la disimilitud entre conjuntos de palabras en el contenido analizado y original, útil para evaluar la superposición de palabras.
Distancia de Jaccard = 1 - |A ∩ B| / |A ∪ B|
donde |A ∩ B| es el número de elementos comunes entre A y B,
y |A ∪ B| es el número total de elementos únicos en ambos conjuntos.