Nykyisessä datavetoisessa maailmassa monimutkaisten asiakirjojen muuntaminen PDF-muodosta CSV-muotoon on monille ammattilaisille tärkeä tehtävä. Jos kamppailet pankkitilien, lääkärin raporttien tai lähetysasiakirjojen kanssa PDF-muodossa, etsit todennäköisesti tehokasta ratkaisua.
Vision Language -mallit (VLM) tulevat apuun, sillä ne ovat huipputeknologiaa, joka ylittää perinteiset OCR-menetelmät. Hyödyntämällä sekä visuaalista että kontekstuaalista ymmärrystä, VLM:t tarjoavat tehokkaan työkalun monimutkaisten, rakenteellisten asiakirjojen muuntamiseen koneellisesti luettaviin muotoihin.
Tämä opas vie sinut läpi prosessin, jossa hyödynnät VLM:iä muuttaaksesi PDF-tiedostosi CSV- tai Excel-tiedostoiksi AnyParserin avulla, tehostaen työskentelyprosessejasi ja avaten arvokkaita tietonäkymiä. AnyParserin avulla voit helposti muuttaa PDF:n CSV:ksi, PDF:n Exceliksi tai jopa muuttaa Word-tiedoston CSV:ksi vain muutamalla klikkauksella Playgroundissamme.
PDF:n muuntamisen tarpeet ja perinteisten OCR-mallien rajoitukset
PDF:n muuntamisen kasvava kysyntä
Nykyisessä datavetoisessa maailmassa PDF:n muuntamisen tarve CSV-muotoon on tullut yhä tärkeämmäksi. Sekä yritykset että yksityishenkilöt etsivät tehokkaita tapoja muuttaa staattisia PDF-asiakirjoja dynaamisiksi, analysoitaviksi taulukoiksi. Tämä muuntamisprosessi on välttämätön arvokkaan tiedon erottamiseksi erilaisista asiakirjoista, kuten pankkitileistä, lääkärin raporteista ja lähetysasiakirjoista. Mahdollisuus muuttaa Word Exceliksi tai käyttää PDF CSV -muunninta voi merkittävästi tehostaa tiedonhallintaa ja analyysiprosesseja.
Perinteisen OCR-teknologian puutteet
Vaikka perinteisiä optisia merkintunnistus (OCR) -malleja on pitkään käytetty tekstin erottamiseen, ne jäävät usein jälkeen monimutkaisten asiakirjojen käsittelyssä. Nämä rajoitukset tulevat ilmi, kun yritetään muuttaa monimutkaisia PDF-tiedostoja Google Sheets -muotoon tai muihin taulukkomuotoihin. OCR-järjestelmät kamppailevat:
- Alhaisen laadun skannattujen tai kuvien tarkalla tulkinnalla
- Monisarakkeisten asettelujen ja taulukoiden käsittelyllä
- Erilaisten fonttien ja kielten tunnistamisella
- Alkuperäisen asiakirjarakenteen säilyttämisellä
Nämä haasteet korostavat tarvetta kehittyneemmille ratkaisuille, jotka voivat saumattomasti käsitellä PDF:n muuntamisprosessia CSV-muotoon säilyttäen sekä alkuperäisten asiakirjojen sisällön että kontekstin.
Vaiheittainen opas PDF-asiakirjojen muuntamiseen AnyParserilla
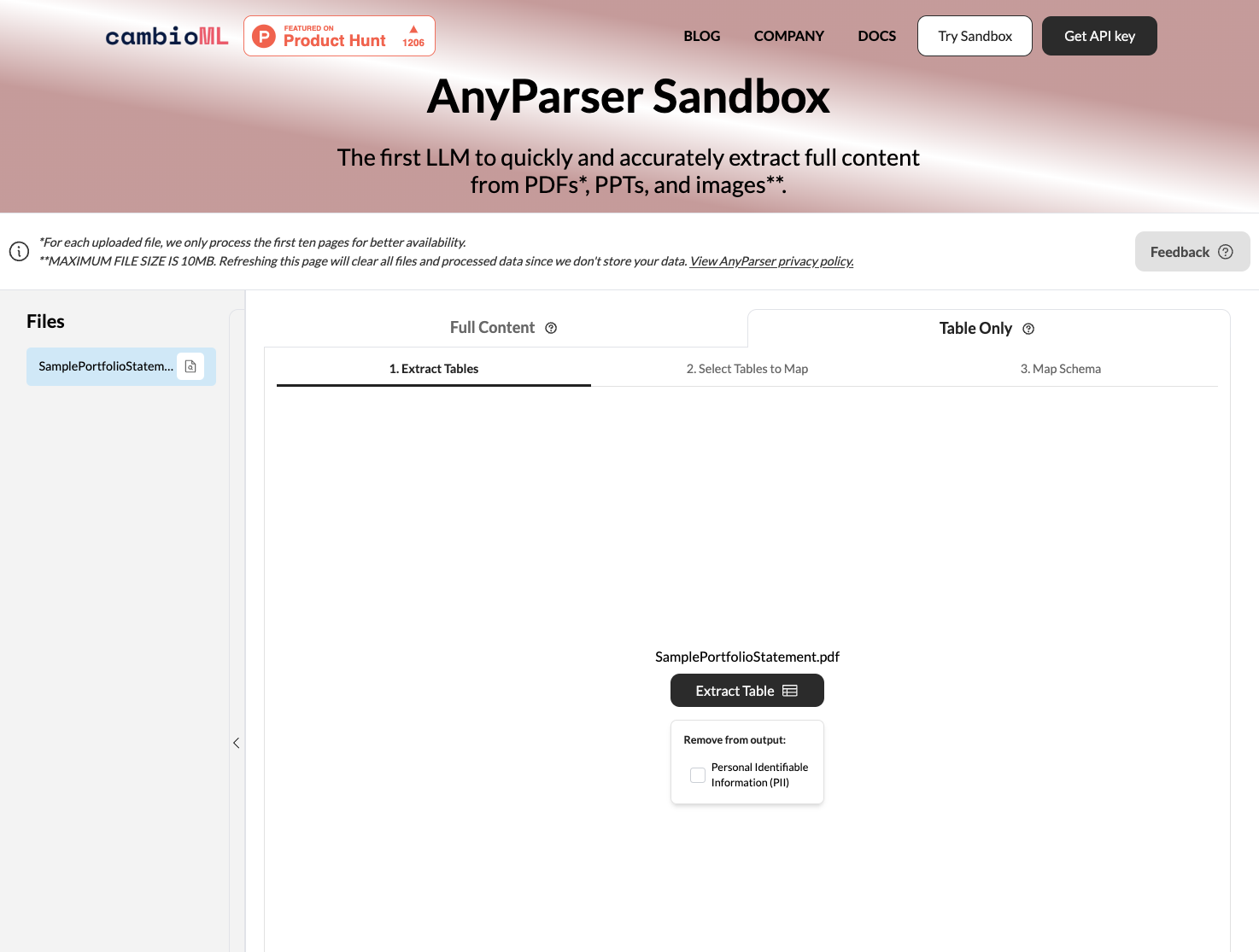
AnyParser on tehokas PDF:n muuntamistyökalu, joka hyödyntää edistyneitä Vision Language -malleja tarkasti tietojen erottamiseksi monimutkaisista PDF-asiakirjoista. Tässä ovat perusvaiheet AnyParserin käyttämiseksi PDF-tiedostojesi muuntamiseen:
-
Lataa PDF tai Word. Vedä ja pudota PDF-asiakirjasi AnyParserin verkkoliittymään tai voit liittää PDF-näytteen AnyParserin käyttöliittymään.
-
Valitse "Vain taulukko" ja napsauta "Erota". AnyParserin API-moottori tunnistaa automaattisesti PDF:n taulukot ja erottaa ne korkealla tarkkuudella. Erottamatut tiedot tallennetaan .csv-tiedostoon, jonka voit ladata tai viedä Google Sheetsiin yhdellä klikkauksella.
-
Esikatsele ja vertaa. Tarkista erotetut tiedot esikatselussa varmistaaksesi, että ne vastaavat odotuksiasi. Esikatsele AnyParserin alkuperäistä erottamista ja vertaa vierekkäin käyttöliittymässä.
-
Vie CSV- tai Excel-muotoon. Kun olet tyytyväinen erottamiseen, lataa .csv-tiedosto käyttääksesi tietoja omissa sovelluksissasi ja järjestelmissäsi. Erottamatut tiedot voidaan helposti tuoda taulukoihin ja tietokantoihin lisäanalyysiä varten.
Noudattamalla näitä yksinkertaisia vaiheita ja hyödyntämällä Vision Language -mallien voimaa, AnyParser mahdollistaa jopa monimutkaisimpien PDF-asiakirjojen tehokkaan muuntamisen rakenteellisiksi, muokattaviksi CSV-tiedostoiksi, joita voit analysoida ja integroida työprosesseihisi.
Katso tämä video nähdäksesi vaiheittaisen videodemon!
VLM:n käytännön sovellukset PDF:n muuntamisessa CSV/Excel-muotoon
Vision Language -mallit (VLM) mullistavat tavan, jolla muunnamme PDF:n CSV- ja Excel-muotoon, tarjoten tehokkaita ratkaisuja eri teollisuudenaloille. Hyödyntämällä näitä edistyneitä malleja voit tehokkaasti muuttaa monimutkaisia asiakirjoja rakenteelliseksi, koneellisesti luettavaksi dataksi.
Rahoitusasiakirjojen käsittely
Pankkisektorilla VLM:t ovat erinomaisia PDF:n muuntamisessa CSV-muotoon pankkitileille. Nämä mallit voivat tarkasti erottaa tapahtumatiedot, tilinumerot ja saldo tiedot, jopa asiakirjoista, joissa on monimutkaisia asetteluja tai useita valuuttoja. Tämä kyky tehostaa taloudellista analyysiä ja sovitusta.
Lääkärin tietojen hallinta
Terveydenhuollon ammattilaisille VLM:t tarjoavat arvokkaan työkalun Wordin muuntamiseen Exceliksi lääkärin raporteissa. Tarkasti tulkitsemalla monimutkaista lääketieteellistä terminologiaa ja säilyttämällä laboratoriotulosten rakenne, VLM:t helpottavat kattavien potilastietokantojen luomista. Tämä muutos mahdollistaa helpomman trendianalyysin ja parannetun potilashoidon.
Logistiikan ja toimitusketjun optimointi
Logistiikka-alalla VLM:t loistavat muuttaessaan lähetysasiakirjoja PDF:stä Google Sheets -muotoon. Nämä mallit voivat erottaa olennaista tietoa, kuten toimitusosoitteita, tuotekuvauksia ja seurantanumeroita, säilyttäen taulukkotietojen eheyden. Tämä muuntaminen mahdollistaa tehokkaan varastonhallinnan ja reittien optimoinnin.
Hyödyntämällä VLM:ien tehoa PDF:n muuntamisessa CSV-muotoon, voit merkittävästi parantaa tiedon käsittelyn tehokkuutta eri sektoreilla. Nämä edistyneet mallit tarjoavat vertaansa vailla olevaa tarkkuutta monikielisten asiakirjojen, monimutkaisten asettelujen ja jopa alhaisen laadun skannattujen asiakirjojen käsittelyssä, tehden niistä välttämättömän työkalun nykyaikaisille yrityksille.
Kuinka Vision Language -mallit toimivat OCR-haasteiden voittamiseksi
Vision Language -mallit (VLM) mullistavat tavan, jolla muunnamme PDF:n CSV-muotoon ja muutamme monimutkaisia asiakirjoja koneellisesti luettaviin muotoihin. Toisin kuin perinteinen OCR, VLM:t hyödyntävät sekä visuaalista että kielellistä ymmärrystä käsitelläkseen asiakirjojen muuntamisen vaikeimpia osa-alueita.
Monimutkaisten asettelujen tulkinta
VLM:t ovat erinomaisia monimutkaisten asiakirjarakenteiden tulkinnassa, mikä tekee niistä ihanteellisia Wordin muuntamiseen Exceliksi tai pankkitilien käsittelyyn, joissa on erilaisia muotoja. Analysoimalla tekstielementtien välisiä tilasuhteita VLM:t voivat tarkasti rekonstruoida taulukot ja säilyttää asettelun eheyden. Esimerkiksi VLM:t voivat oikein tulkita PDF:n, jossa on lasku, joka sisältää useita taulukoita eri sarakkeiden ja rivien määrillä, kun taas perinteinen OCR sekoittaa rivit ja sarakkeet.
Kontekstuaalinen ymmärrys
Yksi VLM:ien keskeisistä eduista on niiden kyky ymmärtää asiakirjan sisällön semanttista merkitystä. Tämä kontekstuaalinen tietoisuus mahdollistaa tarkemman erottamisen PDF:n muuntamisessa CSV-muotoon, erityisesti asiantuntijadokumenteissa, kuten lääketieteellisissä CBC-raporteissa tai logistiikan lähetysasiakirjoissa. Esimerkiksi VLM:t voivat oikein luokitella lääkärin raportit erikoisalan mukaan niiden sisällön perusteella, jopa ymmärtää, että "leukosyyttiluku" tarkoittaa "valkosolujen (WBC) lukua"!
Monikielinen kyvykkyys
VLM:t purkavat kielimuureja käsittelemällä saumattomasti useita kirjoitusjärjestelmiä ja kieliä yhdessä asiakirjassa. Tämä tekee niistä erityisen hyödyllisiä kansainvälisille yrityksille, jotka käsittelevät monenlaisia asiakirjoja. Esimerkiksi VLM:t voivat erottaa tietoja PDF:stä, joka sisältää tekstiä sekä englanniksi että ranskaksi.
Melun vähentäminen
Alhaisen laadun skannatut tai kuvat aiheuttavat usein haasteita perinteisille OCR-järjestelmille. VLM:t voivat kuitenkin tehokkaasti suodattaa melua ja keskittyä olennaiseen tietoon, varmistaen korkealaatuisen tuloksen asiakirjojen muuntamisessa Google Sheets -muotoon tai muihin muotoihin. Esimerkiksi VLM:t voivat tarkasti erottaa tietoja sumeasta tai haalistuneesta PDF-asiakirjasta.
UKK PDF:n muuntamisesta CSV-muotoon Vision Language -mallien avulla
Miten VLM-pohjainen muuntaminen eroaa perinteisestä OCR:stä?
Vision Language -mallit (VLM) tarjoavat merkittäviä etuja perinteiseen OCR:ään verrattuna PDF:n muuntamisessa CSV- tai Excel-muotoon. Toisin kuin OCR, VLM:t voivat tarkasti tulkita monimutkaisia asetteluja, ymmärtää kontekstia ja käsitellä useita kieliä saumattomasti. Tämä tekee niistä ihanteellisia pankkitilien, lääketieteellisten CBC-raporttien ja logistiikan lähetysasiakirjojen muuntamiseen koneellisesti luettaviin muotoihin.
Mitkä asiakirjat toimivat parhaiten VLM-muunnoksessa?
VLM:t ovat erinomaisia rakenteellisten asiakirjojen muuntamisessa, joissa on taulukoita, kaavioita ja sekoitettua sisältöä. Ne ovat erityisen tehokkaita taloudellisissa lausunnoissa, lääkärin raporteissa ja lähetysmanifestissa. VLM:ien avulla toimiva PDF CSV -muunnin voi säilyttää taulukon eheyden ja erottaa tietoja jopa alhaisen laadun skannatuista tai monimutkaisista monikielisistä asiakirjoista.
Kuinka tarkka VLM-pohjainen muuntaminen on verrattuna manuaaliseen tietojen syöttöön?
VLM-pohjaiset ratkaisut, kuten AnyParser, voivat merkittävästi parantaa tarkkuutta verrattuna manuaaliseen tietojen syöttöön tai perinteiseen OCR:ään. Hyödyntämällä sekä visuaalista että kontekstuaalista ymmärrystä nämä työkalut voivat vähentää virheitä Wordin muuntamisessa Exceliksi tai PDF:n muuntamisessa Google Sheetsiksi jopa 50 %. Tämä tarkkuus on ratkaisevan tärkeää tietojen eheyden ylläpitämiseksi taloudellisissa, lääketieteellisissä ja logistisissa sovelluksissa.
Voivatko VLM:t käsitellä erilaisia tiedostomuotoja PDF:iden lisäksi?
Kyllä, edistyneet VLM-pohjaiset työkalut voivat käsitellä erilaisia tiedostomuotoja. Vaikka PDF:n muuntaminen CSV-muotoon on yleistä, nämä mallit voivat myös erottaa tietoja kuvista, Word-asiakirjoista, PowerPoint-esityksistä ja skannatuista asiakirjoista. Tämä monipuolisuus tekee VLM:istä tehokkaan ratkaisun kattaviin asiakirjakäsittelytarpeisiin eri teollisuudenaloilla.
Yhteenveto
Kun aloitat Vision Language -mallien hyödyntämisen PDF:n muuntamisessa CSV-muotoon, muista, että menestys perustuu hyvin rakenteelliseen lähestymistapaan. Toteuttamalla vahvaa esikäsittelyä, tarkkaa asiakirjojen luokittelua ja perusteellista jälkikäsittelyä voit hyödyntää VLM:ien koko potentiaalia tietojen erottamistarpeissasi. Olitpa sitten tekemisissä monimutkaisten pankkitilien, yksityiskohtaisten lääkärin raporttien tai tarkkojen lähetysasiakirjojen kanssa, VLM:t tarjoavat tehokkaan ratkaisun muuttaa jäsentämätöntä tietoa toiminnallisiksi näkemyksiksi. Hyödynnä tätä huipputeknologiaa tehostaaksesi työprosessejasi, parantaaksesi tietojen tarkkuutta ja avaat uusia mahdollisuuksia asiakirjakäsittelyssä. VLM:ien avulla olet hyvin varustautunut käsittelemään jopa haastavimmat PDF-muunnostehtävät tehokkaasti ja vaikuttavasti.
Toimintakehotus
Siirrytään eteenpäin toteuttamalla nämä oivallukset. Harkitse asiantuntijoiden, kuten AnyParserin tiimin, kanssa yhteydenottoa Vision Language -malleissa:
- Kokeile AnyParseria ilmaiseksi muuttaaksesi PDF:si CSV-muotoon osoitteessa https://www.cambioml.com/sandbox
- Jos haluat käyttää koodittomia ratkaisuja suurten PDF-tiedostomäärien muuntamiseen Excel-muotoon, käy osoitteessa https://www.energent.ai
- Hanki ilmainen konsultaatio siitä, kuinka VLM:t voivat parantaa tietojen erottamisprosessiasi
Vision Language -mallien täyden potentiaalin hyödyntäminen vaatii muunnosspecialistien kokemuksen ja parhaat käytännöt. Ota seuraava askel yhdistämällä voimasi alan johtajien kanssa nopeuttaaksesi siirtymistäsi automaattiseen, tarkkaan ja oivaltavaan tietojen erottamisprosessiin.