Monimutkaisten PDF-tiedostojen muuntaminen Markdowniksi voi olla haastavaa. Saatavilla on runsaasti avoimen lähdekoodin kirjastoja tekstin erottamiseen PDF:stä, mutta kun kyseessä ovat PDF:t, jotka sisältävät monimutkaisia elementtejä, kuten taulukoita ja kaavioita, tulokset jäävät usein puutteellisiksi. Suositut suuret kielimallit, kuten GPT tai Claude, pystyvät käsittelemään näitä tehtäviä, mutta niiden suorituskyky on usein hidas ja tulokset voivat olla epätarkkoja. Perinteiset OCR-työkalut, vaikka ne ovatkin tehokkaita yksinkertaisemmissa asiakirjoissa, kamppailevat usein alkuperäisen sisällön tarkan rakenteen ja semanttisen merkityksen säilyttämisessä. Toisaalta näkökielimallit saattavat joskus "hallusinoida", mikä johtaa virheellisiin parsintatuloksiin. Tässä blogissa selitetään, mitä parsinta tarkoittaa, ja yksityiskohtaisesti tarkastellaan useiden mallien vertailuanalyysin tuloksia eri mittareilla.
Mitä parsinta tarkoittaa?
PDF-parsinnan yhteydessä "parsinta" viittaa prosessiin, jossa erityisohjelmiston, jota kutsutaan PDF-parsijaksi, avulla eristetään tiettyjä tietoja PDF-tiedostosta. PDF-parsija analysoi PDF-dokumentin sisältöä ja tunnistaa elementtejä, kuten tekstiä, kuvia, fontteja, asetteluja ja jopa metatietoja. Eristetty data voidaan sitten järjestää ja viedä eri muotoihin, kuten XML, JSON tai Excel/CSV, joita voidaan käyttää erilaisiin tarkoituksiin, kuten tietoanalyysiin, asiakirjojen ylläpitoon tai työnkulkujen automatisointiin.
Ymmärtäminen, mitä parsinta tarkoittaa, on olennaista arvioitaessa parsintaratkaisun tehokkuutta, erityisesti vertaillessa erilaisia PDF:stä Markdowniin muuntamistyökaluja, sillä PDF-parsinta sisältää enemmän kuin vain yksinkertaisen tekstin erottamisen—se vaatii asiakirjan semanttisen rakenteen tunnistamista ja säilyttämistä.
Miten mittaamme näiden parsintaratkaisujen laatua?
Olemme määrittäneet joukon sanatasoisia mittareita arvioidaksemme eri mallien suorituskykyä, keskittyen keskeisiin tekijöihin, kuten:
-
Tarkkuus, Kattavuus ja F-Mittari: Parsinnan laadun ja täydellisyyden arviointi.
-
BLEU-pisteet ja ANLS: Hyödyllisiä kielen ja asettelurakenteen arvioimiseksi.
-
Muokkausetäisyys, Jensen-Shannon Divergenssi ja Jaccard-etäisyys: OCR-alueelle spesifisiä mittareita, erityisesti hyödyllisiä sisällön toistamisen tarkkuuden ymmärtämisessä.
Meidän näkökielimallimme, AnyParser, osoittaa poikkeuksellista suorituskykyä, yhdistäen nopeuden ja tarkkuuden, erityisesti monimutkaisissa asetteluissa, joissa on taulukoita ja semanttisia elementtejä. AnyParser ylittää muut ratkaisut, tarjoten 20-kertaisen nopeuden parannuksen malleihin kuten GPT/Claude verrattuna, samalla saavuttaen korkeamman tarkkuuden.
Laaja vertailutulos johtavia parsintamalleja vastaan
Tilastollinen objekti
Jotta voisimme todella osoittaa AnyParserin kyvyt, suoritimme laajan vertailun johtavia parsintamalleja ja tunnettuja suuria kielimalleja (LLM) vastaan. Arviointimme sisälsi:
1. Suuret kielimallit
- AnyParser
- OpenAI:n GPT-4o
- Googlen Gemini 1.5 Pro
- Anthropicin Claude 3.5 Sonnet
2. OCR-pohjaiset palvelut
- LlamaParse
- Amazon Textract
- Google Cloud Document AI
- Azure Document Intelligence
Tulosten esittely ja analyysi
Kokeilu 1
Ensinnäkin, suoritimme sarjan perusteellisia vertailuja eri dokumentti-AI-mallien suorituskyvystä yli 5 mittarilla: BLEU, tarkkuus ja kattavuus, F-mittari ja ANLS. Voit löytää näiden määritelmien matemaattiset määritelmät liitteestä.
Vertailtavat mallit ovat: AnyParser-base, AnyParser-pro, Textract, Llama-Parse, GPT4o, Gemini-1.5-pro, GCP-DocAl ja Azure-DocAl.
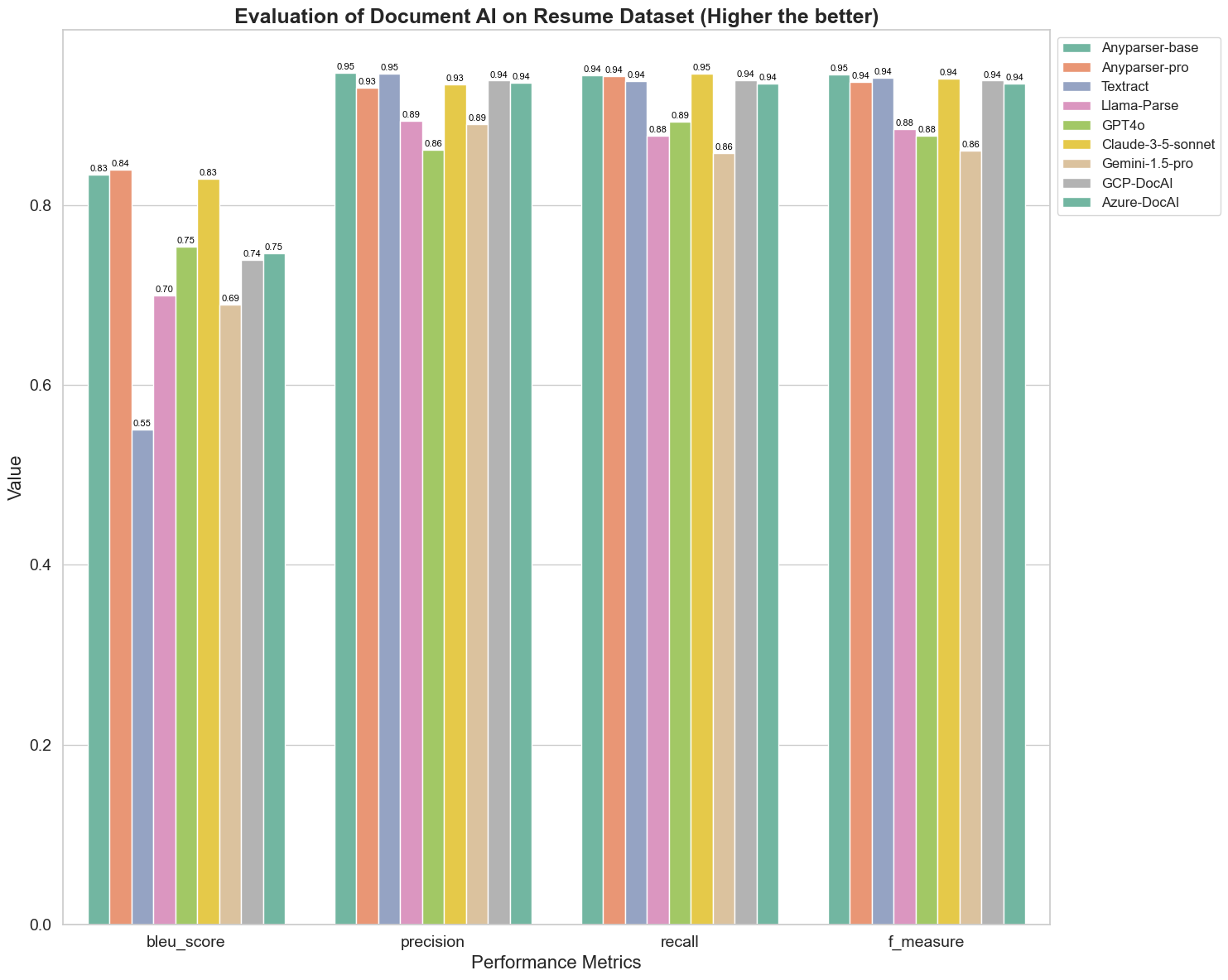
BLEU:ta käytetään kaksikielisen tulkkauksen laadun arvioimiseen testatessa mallien laatua käsitellessään lausuntoja. Vertailtaessa näiden parsintamallien tuloksia BLEU-arviointimenetelmän mukaan, huomaamme, että: AnyParser-base ja AnyParser-pro saavat merkittävästi korkeammat pisteet kuin muut mallit, Amazon Textract saa alhaisimmat pisteet, ja muiden mallien tulokset ovat keskimääräisellä tasolla.
Tunnistus tarkkuus esitetään yleensä tarkkuuden ja kattavuuden avulla, jossa tarkkuus edustaa oikeiden tulosten prosenttiosuutta mallin arvioimista oikeista tuloksista, ja kattavuus edustaa oikeiden tulosten prosenttiosuutta mallin arvioimista kaikista todellisesti oikeista tuloksista. Vertailtaessa näiden parsintamallien tarkkuutta ja kattavuutta, huomaamme, että: lukuun ottamatta Llama-Parsea, GPT4o:ta ja Gemini-1.5-prota, kaikki muut mallit ovat korkealla tasolla. Näistä AnyParser ja Amazon Textract erottuvat tarkkuudessa, ja AnyParser-base ja AnyParser-pro erottuvat kattavuudessa. Mallin korkeampi tarkkuuspiste osoittaa, että malli tuottaa enemmän oikeaa tietoa tuotoksissaan, ja korkeampi kattavuuspiste osoittaa, että malli pystyy paremmin saamaan oikeaa tietoa näytteestä. Tulosten perusteella AnyParserilla on selkeä etu tunnistustarkkuudessa PDF:stä tekstin erottamisessa.
F-mittari on kattava arviointimittari tarkkuudelle ja kattavuudelle näiden kahden indikaattorin osalta. Vertailtaessa näiden parsintamallien pisteitä F-mittarissa, voimme nähdä selkeämmin, että viisi mallia, AnyParser-base, AnyParser-pro, Amazon Textract, GCP-DocAI ja Azure-DocAI, ovat vahvempia tunnistustarkkuudessa verrattuna muihin malleihin. Voimme nähdä selkeämmin, että viidellä mallilla on enemmän voimaa tunnistustarkkuudessa kuin muilla malleilla, ja AnyParserilla on korkein piste F-mittarissa, mikä edelleen osoittaa AnyParserin ilmeisen edun tunnistustarkkuudessa PDF:stä tekstin erottamisessa.
ANLS, yleisesti käytetty arviointimittari, kun mitataan alkuperäisen tekstin ja kohdetekstin tarkkuutta ja samankaltaisuutta merkkitasolla, on myös erittäin informatiivinen mallien parsintatason mittaamiseksi. AnyParser-base, AnyParser-pro ja Azure-DocAI korkeammat pisteet heijastavat näiden mallien korkeampaa parsintatasoa verrattuna muihin malleihin.
Kaiken kaikkiaan AnyParser-base ja AnyParser-pro ylittävät muut mallit.
Kokeilu 2
Vertailimme myös eri dokumentti-AI-mallien suorituskykyä kolmella eri mittarilla: Muokkausetäisyys, Jensen-Shannon Divergenssi ja Jaccard-etäisyys. Mittareita käytetään mallien tuotosten ja viitetiedoston samankaltaisuuden mittaamiseen. Alhaisemmat arvot viittaavat parempaan suorituskykyyn.
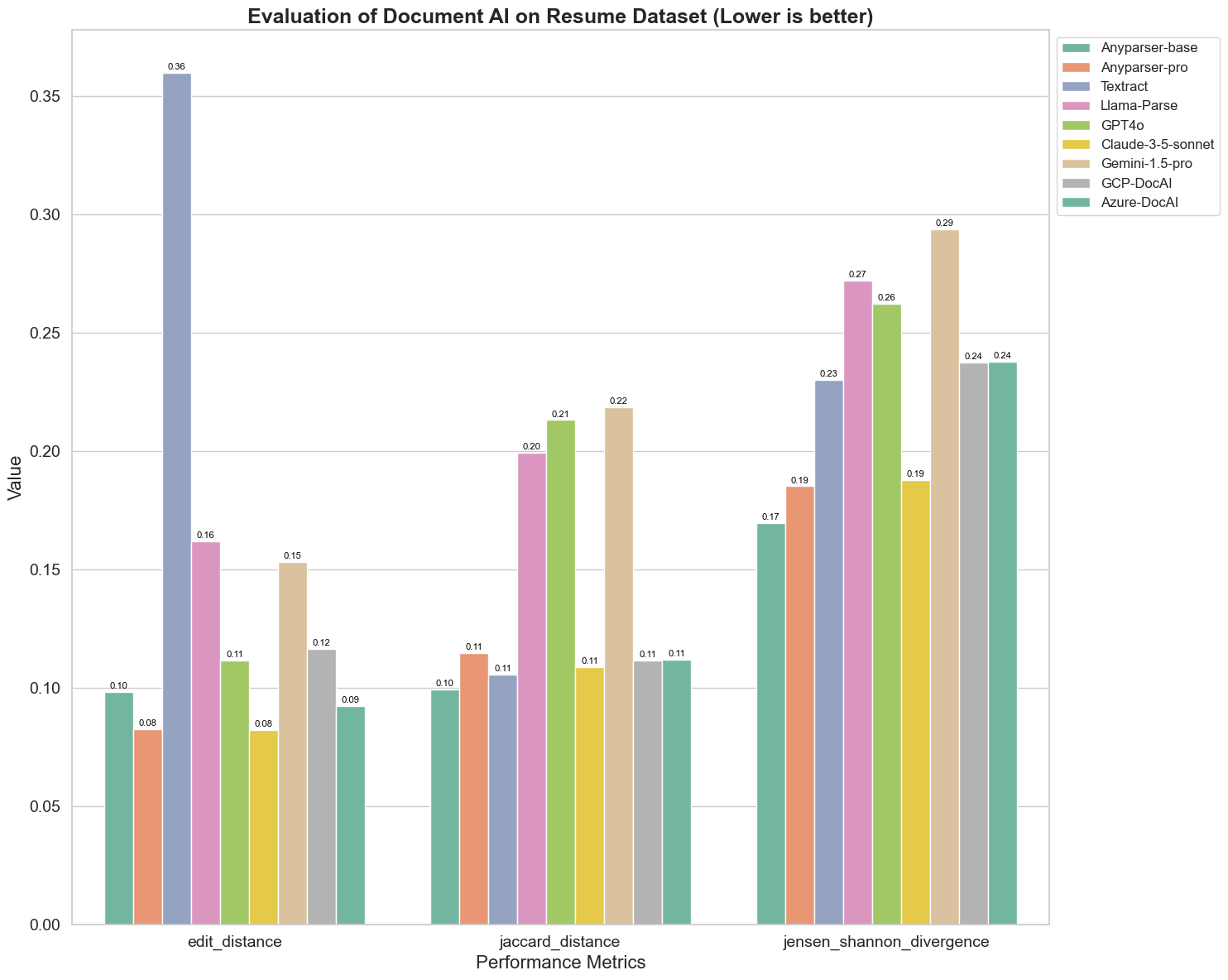
Tässä on joitakin keskeisiä havaintoja kaaviosta:
-
Muokkausetäisyys: Mallit AnyParser-base ja AnyParser-pro suoriutuvat parhaiten alhaisimmalla muokkausetäisyydellä, mikä viittaa siihen, että niiden tuotokset olivat lähimpänä viitetiedostoa.
-
Jensen-Shannon Divergenssi: Mallit AnyParser-base ja AnyParser-pro omaavat alhaisimman divergenssin, mikä tarkoittaa, että niiden tuotokset ovat eniten samankaltaisia viitetiedoston kanssa sanajakauman osalta.
-
Jaccard-etäisyys: Llama-parsea, GPT4O:ta ja Gemini-1.5:ttä lukuun ottamatta kaikki muut mallit suoriutuvat kohtuullisesti alhaisimmalla Jaccard-etäisyydellä, mikä osoittaa, että niiden tuotoksilla on suurin päällekkäisyys viitetiedoston kanssa käytettyjen sanojen osalta.
Johtopäätös
Kaiken kaikkiaan perusteellinen testauksemme viittaa siihen, että AnyParser-base ja AnyParser-pro suoriutuvat yleensä hyvin eri mittareilla, mikä osoittaa niiden potentiaalin tarkassa asiakirjakäsittelyssä. Kaavioista voimme nähdä, että perinteiset OCR-mallit, kuten tunnettu Amazon Textract, saavat paljon alhaisempia pisteitä kuin näkökielimallit. Kuitenkin eri mallien suorituskyky vaihtelee käytetystä mittarista riippuen, mikä korostaa useiden arviointikriteerien huomioimisen tärkeyttä AI-malleja vertaillessa.
Esittelemme avoimen lähdekoodin arviointiputkiston
Arviointien sujuvoittamiseksi olemme luoneet arviointiputkiston, joka tarjoaa alan standardin mukaisen menetelmän parsintamallien vertaamiseen. Esimerkissämme demonstroimme sen käyttöä HR-alueella, jossa ansioluetteloiden parsinta on yleistä. Rakensimme monipuolisen synteettisen tietojoukon, joka koostuu 128 ansioluettelosta, jotka on luotu paritettuja kuva-Markdown-tiedostoja käyttäen. Käyttäen GPT-4:ää, generoimme HTML-sisältöä, renderöimme sen kuviksi ja käytimme eristettyä tekstiä vertailun perustana.
Ja tässä on paras osa: olemme avanneet tämän arviointikehyksen GitHubissa! Olitpa kehittäjä tai liiketoimintakäyttäjä, putkistomme mahdollistaa sinun arvioida ja vertailla eri mallien parsintalaatua omassa tietojoukossasi.
Löydä pikaopas Github-reposta ja katso, miten eri parsintamallit vertautuvat toisiinsa. Uskomme, että esittelemällä mallimme vahvuudet avoimesti voimme houkutella lisää käyttäjiä, jotka haluavat luotettavia, nopeita ja tarkkoja parsintakykyjä.
Liite - Mittarit
1. Tarkkuus
Tarkkuus mittaa parsitun sisällön tarkkuutta, näyttäen kuinka monta haettua elementtiä oli oikein. Parsinnassa se on oikeiden eristettyjen sanojen osuus kaikista eristetyistä sanoista.
Tarkkuus = Oikeat positiiviset (TP) / (Oikeat positiiviset (TP) + Väärät positiiviset (FP))
- Oikeat positiiviset (TP): Parserin oikein tunnistamat sanat.
- Väärät positiiviset (FP): Parserin väärin tunnistamat sanat.
2. Kattavuus
Kattavuus osoittaa parsinnan täydellisyyden tai kuinka monta olennaista sanaa alkuperäisestä asiakirjasta saatiin.
Kattavuus = Oikeat positiiviset (TP) / (Oikeat positiiviset (TP) + Väärät negatiiviset (FN))
- Väärät negatiiviset (FN): Alkuperäisessä asiakirjassa olevat sanat, jotka parseri jätti huomiotta.
3. F-Mittari (F1-piste)
F1-piste on tarkkuuden ja kattavuuden harmoninen keskiarvo, joka tasapainottaa molemmat mittarit antaen yleisen mittarin parsinnan laadulle.
F1-piste = 2 × (Tarkkuus × Kattavuus) / (Tarkkuus + Kattavuus)
4. BLEU-piste (Kaksikielinen arviointimenetelmä)
BLEU-piste mittaa parsitun sisällön ja alkuperäisen tekstin samankaltaisuutta, painottaen erityisesti sanojen järjestystä. Se on erityisen hyödyllinen arvioitaessa kielen ja rakenteen johdonmukaisuutta parsituissa asiakirjoissa, koska se rankaisee tuotoksia, jotka poikkeavat alkuperäisestä järjestyksestä.
5. ANLS (Keskimääräinen normalisoitu Levenshtein-samankaltaisuus)
ANLS kvantifioi parsitun sisällön ja alkuperäisen samankaltaisuuden käyttäen normalisoitua muokkausetäisyyttä. Se lasketaan keskiarvona normalisoidun Levenshtein-samankaltaisuuden (NLS) osalta jokaiselle sanaparille parsitussa ja viitetekstissä. NLS lasketaan seuraavasti:
NLS = 1 - (Levenshtein-etäisyys (LD)(parsittu sana, alkuperäinen sana)) / max(Parsittavan sanan pituus, Alkuperäisen sanan pituus)
Sitten ANLS on NLS:n keskiarvo kaikkien sanaparien osalta:
ANLS = (1/N) × Σ(NLS_i) for i=1 to N
6. Muokkausetäisyys
Muokkausetäisyys laskee sanatason operaatioiden (lisäykset, poistot, korvaukset) määrän, joka tarvitaan parsitun tekstin muuttamiseksi alkuperäiseksi.
7. Jensen-Shannon Divergenssi
Jensen-Shannon Divergenssi mittaa samankaltaisuutta parsittujen ja alkuperäisten sanamäärien diskreettisten todennäköisyysjakaumien välillä, korostaen sanojen taajuuden eroja.
JSD(P || Q) = (1/2) × KL(P || M) + (1/2) × KL(Q || M)
missä M = (1/2)(P + Q), ja KL(P || Q) on Kullback-Leiblerin divergenssi
8. Jaccard-etäisyys
Jaccard-etäisyys mittaa eroa parsittujen ja alkuperäisten sisältöjen sanajoukoissa, mikä on hyödyllistä sanojen päällekkäisyyden arvioimiseksi.
Jaccard-etäisyys = 1 - |A ∩ B| / |A ∪ B|
missä |A ∩ B| on yhteisten elementtien määrä A:n ja B:n välillä,
ja |A ∪ B| on molempien joukkojen ainutlaatuisten elementtien kokonaismäärä.