Vision Language Models (VLM:t) mullistavat dokumenttianalyysin kenttää, ratkaisten monia perinteisten optisten merkkien tunnistus (OCR) järjestelmien sisäisiä rajoituksia. Vaikka OCR on ollut keskeinen teknologia tekstin digitalisoimisessa kuvista, se kohtaa merkittäviä haasteita monimutkaisissa tilanteissa. Näitä ovat tarkkuusongelmat huonolaatuisten kuvien kanssa, rajoitettu kontekstuaalinen ymmärrys, vaikeudet sekoitetuissa kielissä ja kyvyttömyys tulkita visuaalisia elementtejä. VLM:t tarjoavat lupaavan ratkaisun yhdistämällä edistyneen tietokonenäön ja luonnollisen kielen käsittelyn kyvyt. Tässä artikkelissa tarkastellaan, kuinka VLM:t voittavat OCR:n puutteet, tarjoten kestävämpiä ja monipuolisempia ratkaisuja dokumenttien käsittelyyn digitaalisessa aikakaudessa.
Mikä on OCR? Mitkä ovat OCR:n prosessit dokumenttien analysoinnissa?
Optinen merkkien tunnistus (OCR) on teknologia, joka mahdollistaa erilaisten asiakirjojen, kuten skannattujen paperiasiakirjojen, PDF-tiedostojen tai digitaalisen kameran tallentamien kuvien, muuntamisen muokattavaksi ja haettavaksi dataksi. Tämä prosessi on ratkaisevan tärkeä dokumenttien käsittelyssä ja PDF-tietojen poiminnassa, jolloin koneet voivat tunnistaa painettua tai käsinkirjoitettua tekstisisältöä digitaalisissa kuvissa.
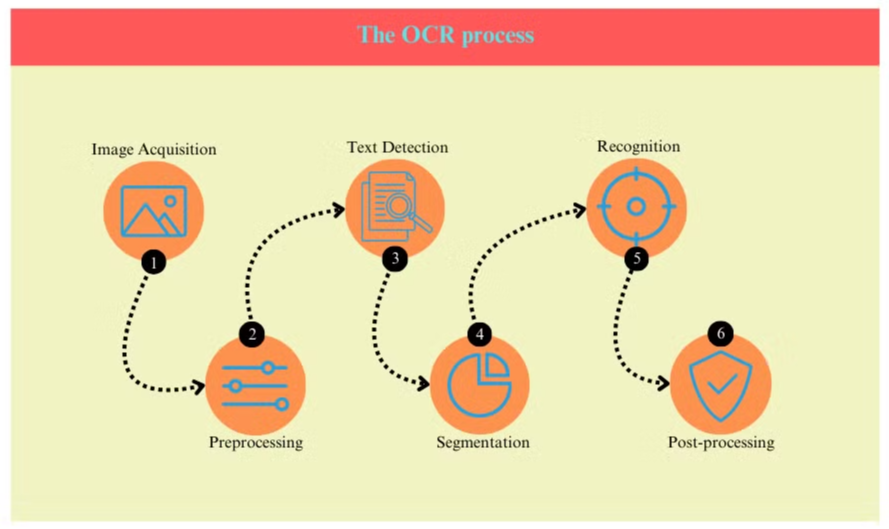
OCR-prosessi
OCR-prosessi sisältää tyypillisesti useita vaiheita:
- Kuvan hankinta: Asiakirja skannataan tai valokuvataan digitaalisen kuvan luomiseksi.
- Esikäsittely: Kuva puhdistetaan, poistamalla häiriöitä ja säätämällä kirkkautta ja kontrastia.
- Tekstin tunnistus: Järjestelmä tunnistaa tekstialueet kuvassa.
- Merkkien segmentointi: Yksittäiset merkit eristetään tekstialueilta.
- Merkkien tunnistus: Jokainen merkki analysoidaan ja verrataan tunnettujen merkkien tietokantaan.
- Jälkikäsittely: Tunnistettu teksti tarkistetaan virheiden varalta kielellisen ja kontekstuaalisen tiedon avulla.
Vaikka OCR on huomattavasti parantanut dokumenttien analysointikykyjä, se kohtaa edelleen rajoituksia monimutkaisten asettelujen, huonolaatuisten kuvien ja vaihtelevien fonttien käsittelyssä. Tässä edistyneet teknologiat, kuten vision language models, astuvat kuvaan parantaakseen tarkkuutta ja ymmärrystä tietojen poiminnassa kuvista ja asiakirjoista.
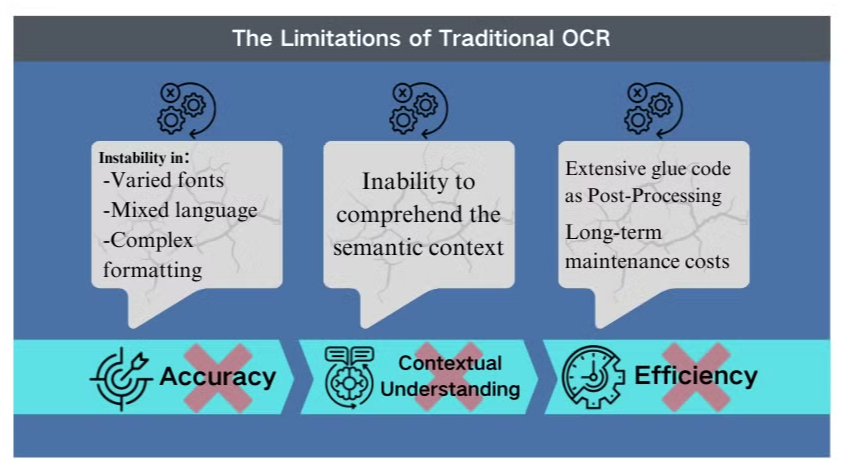
Perinteisen OCR-teknologian Rajoitukset
Tarkkuusongelmat Monimutkaisissa Tilanteissa
Perinteinen optinen merkkien tunnistus (OCR) -teknologia, vaikka se on hyödyllinen perus tekstin poiminnassa, kohtaa merkittäviä esteitä monimutkaisten asiakirja-asettelujen tai huonolaatuisten kuvien kanssa. Nämä järjestelmät kamppailevat usein tarkkuuden ylläpitämisessä käsitellessään asiakirjoja, joissa on vaihtelevia fontteja, sekoitettuja kieliä tai monimutkaista muotoilua. Esimerkiksi OCR voi epäonnistua yrittäessään poimia tietoja kuvapainotteisista esityksistä tai tiheästi muotoilluista PDF-tiedostoista.
Kontekstuaalisen Ymmärryksen Puute
Yksi perinteisen OCR:n ilmeisimmistä rajoituksista on sen kyvyttömyys ymmärtää käsiteltävän tekstin semanttista kontekstia. Tämä puute tulee erityisesti esiin tilanteissa, joissa tarvitaan hienovaraista tulkintaa, kuten oikeudellisissa sopimuksissa tai lääkärin raporteissa. OCR:n keskittyminen merkkien tunnistamiseen ilman kontekstuaalista tietoisuutta voi johtaa kriittisiin väärinymmärryksiin, erityisesti käsiteltäessä epäselviä merkkejä tai alakohtaisia termejä.
Tehottomuus Jälkikäsittelyssä
OCR:n rajoitukset vaativat usein laajoja jälkikäsittelytoimia. Tämä lisävaihe voi merkittävästi lisätä asiakirjojen käsittelyyn tarvittavaa aikaa ja resursseja. Lisäksi perinteiset OCR-järjestelmät jäävät usein jälkeen, kun niiden on tarkoitus poimia tietoja kaavioista, taulukoista tai muista ei-tekstuaalisista elementeistä, mikä vaikeuttaa asiakirjojen poimintaprosessia entisestään. Nämä tehottomuudet korostavat tarpeen edistyneemmille ratkaisuille, kuten vision language models, jotka tarjoavat kattavamman lähestymistavan asiakirjojen analysointiin ja tietojen poimintaan.
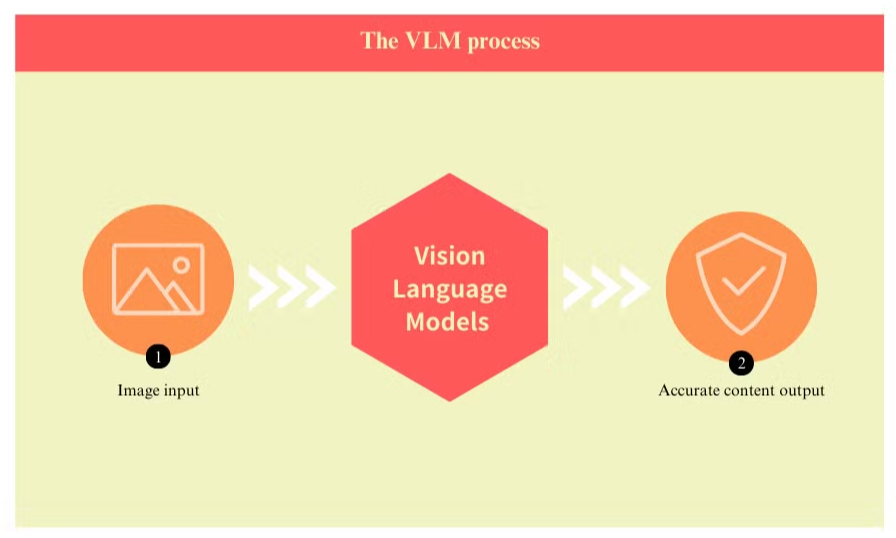
Mitä ovat Vision-Language Mallit ja Kuinka Ne Parantavat OCR:ää
Vision language models edustavat merkittävää edistystä asiakirjojen käsittelyteknologiassa, ratkaisten monia perinteisten optisten merkkien tunnistus (OCR) järjestelmien sisäisiä rajoituksia. Nämä edistyneet mallit yhdistävät tietokonenäön ja luonnollisen kielen käsittelyn ymmärtääkseen sekä asiakirjojen visuaalisia että tekstuaalisia elementtejä samanaikaisesti.
Parannettu Tarkkuus ja Kontekstin Ymmärrys
Toisin kuin OCR, joka kamppailee huonolaatuisten kuvien ja monimutkaisten asettelujen kanssa, vision language models erottuvat kyvyssään tulkita erilaisia asiakirjamuotoja. Ne voivat tarkasti poimia tietoja kuvista, PDF-tiedostoista ja muusta visuaalisesta sisällöstä, jopa haastavissa tilanteissa. Tämä parannettu tarkkuus johtuu niiden kyvystä ottaa huomioon koko asiakirjan konteksti sen sijaan, että keskityttäisiin pelkästään yksittäisiin merkkeihin tai sanoihin.
Kattava Tietojen Poiminta
Vision language models menevät pidemmälle kuin pelkkä tekstin tunnistus, tarjoten kattavat PDF-tietojen poimintakyvyt. Ne voivat tunnistaa ja tulkita taulukoita, kaavioita ja kuvastoja asiakirjoissa, säilyttäen monimutkaisten asettelujen eheyden. Tämä kokonaisvaltainen lähestymistapa asiakirjojen analysointiin mahdollistaa hienovaraisemman ja täydellisemmän tiedon haun, mikä merkittävästi parantaa poimittujen tietojen hyödyllisyyttä alihankintatehtävissä.
Monikielinen ja Monimuotoinen Osaaminen
Yksi vision language modelsin keskeisistä eduista on niiden joustavuus käsitellä useita kieliä ja asiakirjamuotoja. Toisin kuin OCR-järjestelmät, jotka saattavat kamppailla ei-latinankielisten kirjoitusten tai sekoitettujen kieliasiakirjojen kanssa, nämä mallit voivat saumattomasti käsitellä sisältöä eri kielillä ja kirjoituksilla, mikä tekee niistä korvaamattomia globaalissa asiakirjakäsittelyssä.
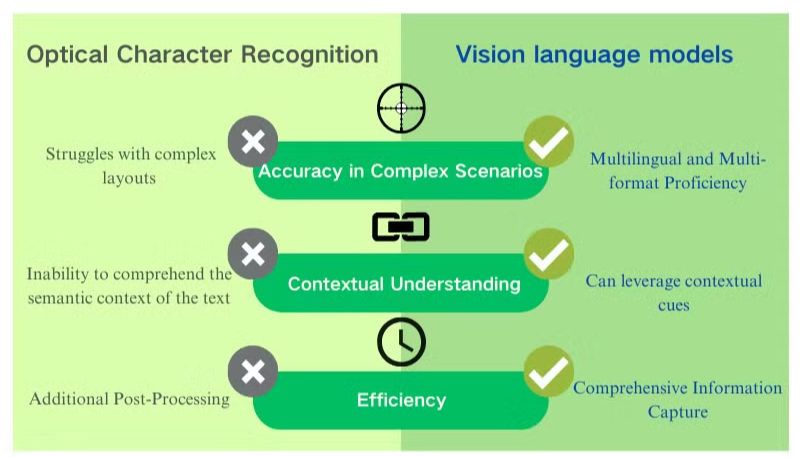
Vision-Language Mallien Avainedut Dokumenttien Ymmärtämisessä
Vision language models tarjoavat merkittäviä etuja perinteiseen OCR:ään verrattuna asiakirjojen käsittelyssä ja tietojen poiminnassa. Nämä tekoälypohjaiset järjestelmät yhdistävät visuaalisen ja tekstuaalisen ymmärryksen tarjotakseen erinomaisia tuloksia eri asiakirjatyyppien keskuudessa.
Parannettu Tarkkuus ja Kontekstuaalinen Ymmärrys
Vision language models erottuvat monimutkaisten asettelujen, huonolaatuisten kuvien ja vaihtelevien fonttien käsittelyssä. Toisin kuin OCR, joka kamppailee epäselvien merkkien kanssa, nämä mallit hyödyntävät kontekstuaalisia vihjeitä tekstin tarkassa tulkinnassa. Tämä kyky parantaa merkittävästi PDF-tietojen poiminnan tarkkuutta, erityisesti asiakirjoissa, joissa on monimutkaisia rakenteita tai huonoa kuvakvaliteettia.
Kattava Tietojen Keruu
Vaikka OCR keskittyy pelkästään tekstin tunnistamiseen, vision language models voivat poimia tietoja kuvista, taulukoista ja kaavioista. Tämä kokonaisvaltainen lähestymistapa varmistaa, että kriittistä tietoa ei jää huomaamatta asiakirjojen käsittelyvaiheessa. Tunnistamalla sekä tekstuaaliset että visuaaliset elementit, nämä mallit tarjoavat täydellisemmän ymmärryksen asiakirjan sisällöstä.
Monikielinen ja Monimuotoinen Osaaminen
Vision language models osoittavat huomattavaa joustavuutta asiakirjojen käsittelyssä eri kielillä ja muodoissa. Ne voivat saumattomasti käsitellä sekoitettuja kieliasiakirjoja ja ei-latinankielisiä kirjoituksia, ylittäen perinteisten OCR-järjestelmien merkittävän rajoituksen. Tämä monipuolisuus tekee niistä korvaamattomia globaaleille yrityksille, jotka käsittelevät erilaisia asiakirjatyyppisiä ja kieliä.
Todelliset Sovellukset, Joita VLM Mahdollistaa, Joissa OCR Epäonnistui
Vision language models mullistavat asiakirjojen käsittelyä rahoituksessa, henkilöstöhallinnossa ja muilla aloilla, ratkaisten perinteisten OCR-järjestelmien kriittisiä rajoituksia. Nämä edistyneet tekoälymallit muuttavat digitaalisen transformaation ponnistuksia eri toimialoilla tarjoamalla ylivoimaista tarkkuutta ja kontekstuaalista ymmärrystä.
Rahoitusasiakirjojen Käsittelyn Mullistaminen
Vision language models muuttavat asiakirjojen käsittelyä rahoituksessa, ylittäen perinteisten OCR:n rajoitukset. Nämä edistyneet mallit erottuvat kyvyssään poimia tietoja monimutkaisista rahoituslaskelmista, laskuista ja kuitista, joissa on monimutkaisia asetteluja. Toisin kuin OCR, ne voivat ymmärtää kontekstia, tulkiten tarkasti epäselviä merkkejä (esim. erottamaan nollan ja aakkosen O) ja sekoitettuja kieliä, joita usein esiintyy globaaleissa rahoitusasiakirjoissa.
Henkilöstöhallinnan Tehostaminen Älykkään Asiakirjan Analyysin Avulla
Henkilöstöhallinnan alalla vision language models ovat osoittautuneet korvaamattomiksi PDF-tietojen poiminnassa ansioluetteloista, työntekijätiedoista ja suoritusarvioista. Nämä mallit voivat ymmärtää asiakirjojen semanttista rakennetta, mahdollistaen tarkemman tiedon haun ja analyysin. Tämä kyky virtaviivaistaa rekrytointiprosesseja ja työntekijätietojen hallintaa, tehtäviä, joissa OCR usein kamppailee vaihtelevien muotojen ja käsinkirjoitettujen muistiinpanojen kanssa.
Vaikuttaminen Vaatimustenmukaisuuteen ja Riskienhallintaan
Vision-language mallit ovat erityisen tehokkaita vaatimustenmukaisuudessa ja riskienhallinnassa sekä rahoituksessa että henkilöstöhallinnossa. Ne voivat poimia ja tulkita kriittistä tietoa sääntelyasiakirjoista, sopimuksista ja käytännöistä tarkemmin kuin OCR. Tämä parannettu asiakirjojen käsittelykyky varmistaa paremman lain noudattamisen ja tehokkaammat riskinarviointimenettelyt.
Yhteenveto
Yhteenvetona voidaan todeta, että vision language models edustavat merkittävää edistystä asiakirjojen käsittelyteknologiassa, ratkaisten monia perinteisten OCR-järjestelmien sisäisiä rajoituksia. Yhdistämällä visuaalisen ja tekstuaalisen ymmärryksen, nämä edistyneet mallit tarjoavat ylivoimaista suorituskykyä laajalla valikoimalla haastavia tilanteita, monimutkaisista asetteluista sekoitettuihin kieliin ja huonolaatuisiin kuviin. Kun organisaatiot jatkavat toimintojensa digitalisoimista ja etsivät tehokkaampia tapoja saada arvoa asiakirjakirjastoistaan, vision language models nousevat voimakkaaksi työkaluksi kehittäjille ja insinöörijohtajille. Niiden kyky ymmärtää konteksti, käsitellä erilaisia muotoja ja tuottaa tarkempia tuloksia asettaa ne keskeiseksi mahdollistajaksi monimutkaisille RAG-putkille ja yrityslaajuisille hakukyvykkyyksille, mikä lopulta vie digitaalisen transformaation aloitteet uusiin korkeuksiin.