Oletko koskaan miettinyt, mitä OCR tarkoittaa? Optinen merkkitunnistus on tehokas teknologia, joka muuntaa tekstikuvat koneellisesti luettavaksi dataksi. Vaikka OCR tarjoaa valtavia etuja asiakirjojen digitalisoimisessa ja tiedon poimimisessa, se ei ole ilman haittojaan. Tutkiessasi tätä teknologiaa on tärkeää ymmärtää sekä sen kyvyt että rajoitukset. Tässä artikkelissa opit, mitä OCR tarkoittaa, ja syvennyt sen mahdollisiin haittoihin. Saamalla kattavan käsityksen optisesta merkkitunnistuksesta olet paremmin varustautunut arvioimaan, onko ja miten tätä teknologiaa kannattaa toteuttaa omissa työprosesseissasi ja projekteissasi.
Mitä OCR tarkoittaa ja mitä on OCR?
Mitä OCR tarkoittaa?
OCR tarkoittaa optista merkkitunnistusta, teknologiaa, joka mahdollistaa tietokoneiden tunnistaa ja muuntaa erilaisia asiakirjoja. Perusperiaatteeltaan OCR on prosessi, jossa skannataan painettua tai käsinkirjoitettua tekstiä ja muunnetaan se konekoodatuksi tekstiksi. Tämä mahdollistaa tekstin hakemisen, muokkaamisen ja siirtämisen helposti. Ymmärtäminen, mitä OCR tarkoittaa, on olennaista kaikille, jotka työskentelevät asiakirjojen skannaus- ja tekstintunnistusteknologioiden parissa.
Mitä on OCR?
Niille, jotka eivät tunne termiä, "mitä on OCR" on yleinen kysymys, joka viittaa optiseen merkkitunnistukseen, teknologiaan, joka mahdollistaa tietokoneiden lukea tekstiä kuvista tai skannatuista asiakirjoista.
OCR muuntaa painetun tai käsinkirjoitetun tekstin koneellisesti luettavaksi dataksi, yhdistäen paperin ja digitaalisten muotojen välisen kuilun. Tämä teknologia käyttää kehittyneitä algoritmeja kirjainten muotojen, sanarakenteiden ja jopa kokonaisen lauseen tunnistamiseen. Tällä tavoin se muuntaa staattiset kuvat muokattaviksi ja haettaviksi tekstidokumenteiksi.
OCR-teknologia perustuu periaatteessa tietokonenäköön ja kuvioiden tunnistusteknologioihin. OCR tarkoittaa asiakirjojen tai tekstin sisältävien kuvien skannaamista ja kehittyneiden algoritmien käyttöä tekstin tunnistamiseksi ja muuntamiseksi digitaaliseen, muokattavaan muotoon. Yksi keskeisistä hetkistä OCR-teknologian historiassa oli vuonna 1974, jolloin Ray Kurzweil kehitti omni-font OCR -järjestelmän, joka pystyi tunnistamaan tekstiä käytännössä missä tahansa fontissa. Vuosien varrella OCR on kehittynyt yksinkertaisista mallin tunnistamisesta monimutkaisemmiksi järjestelmiksi.
Huolimatta kyvyistään, OCR-teknologia kohtaa tällä hetkellä tiettyjä rajoituksia. Näitä ovat haasteet tekstin tunnistamisessa huonolaatuisissa kuvissa, vaikeudet monimutkaisten asettelujen tai taustojen käsittelyssä ja vaihteleva tarkkuus eri fonttien, kielten tai käsinkirjoituksen kanssa. Lisäksi OCR-järjestelmät voivat kamppailla asiakirjojen kanssa, joilla on värilliset taustat, jotka ovat sumeita tai vinossa, sekä kaunokirjoituksen kanssa.
Ymmärrys optisen merkkitunnistuksen ohjelmistosta
Optisen merkkitunnistuksen ohjelmisto on mullistava teknologia, joka muuntaa erilaiset asiakirjat muokattavaksi ja haettavaksi dataksi. Se näyttelee keskeistä roolia maailmamme digitalisoimisessa, tehden tiedosta helpommin saatavilla ja hallittavissa. OCR-ohjelmisto käyttää monimutkaista prosessia muuntaakseen tekstikuvia koneellisesti luettavaksi dataksi.
Kuinka OCR-ohjelmisto toimii
1. Kuvan hankinta
OCR:n matka alkaa asiakirjan kuvan tallentamisesta. Tämä voidaan tehdä skannerin tai digitaalisen kameran avulla. Kuva muunnetaan sitten digitaaliseen muotoon, jota tietokone voi käsitellä.
2. Esikäsittely ja kuvan parantaminen
Toinen vaihe sisältää kuvan laadun parantamisen. Kun kuva on hankittu, se käy läpi esikäsittelyn, joka parantaa sen laatua paremman tunnistuksen saavuttamiseksi. Tämä vaihe voi sisältää kontrastin, kirkkauden ja terävyyden säätämistä sekä kaiken melun tai merkityksettömien elementtien poistamista. Tämä esikäsittelyvaihe on ratkaiseva tarkkojen tulosten saavuttamiseksi, erityisesti huonolaatuisten skannausten tai valokuvien käsittelyssä.
3. Tekstin tunnistus
OCR-ohjelmisto analysoi esikäsitellyn kuvan tunnistaakseen alueet, jotka sisältävät tekstiä. Se tekee tämän etsimällä kuvioita ja muotoja, jotka ovat tyypillisiä tekstille, kuten eripaksuisia ja -korkuisia viivoja.
4. Merkkisegmentointi
Kun tekstialueet on tunnistettu, ohjelmisto jakaa tekstin pienempiin yksiköihin, kuten lohkoihin, viivoihin, sanoihin tai jopa yksittäisiin merkkeihin. OCR-ohjelmisto analysoi kuvaa pikseli pikseliltä tunnistaakseen kuvioita, jotka muodostavat merkkejä. Se jakaa kuvan pienempiin osiin, eristäen jokaisen merkin.
5. Tekstin tunnistus ja poiminta
Ohjelmisto vertaa sitten näitä eristettyjä muotoja laajaan tunnetuista merkkikuvioista koostuvaan tietokantaan määrittääkseen, mitä kukin merkki on. Ohjelmisto poimii ominaisuuksia merkeistä, kuten viivojen, kaarien tai kulmien määrän. Nämä ominaisuudet auttavat OCR:ää tunnistamaan ja erottamaan eri merkit.
6. Jälkikäsittely
Kun merkit on tunnistettu, OCR-järjestelmä käy läpi jälkikäsittelyvaiheen, jossa se korjaa mahdolliset virheet ja muotoilee tekstin ulostuloa varten. Korjattu teksti viedään sitten haluttuun muotoon, kuten Word-dokumenttiin tai haettavaksi PDF:ksi.
Käyttötapaukset optisen merkkitunnistuksen ohjelmistolla
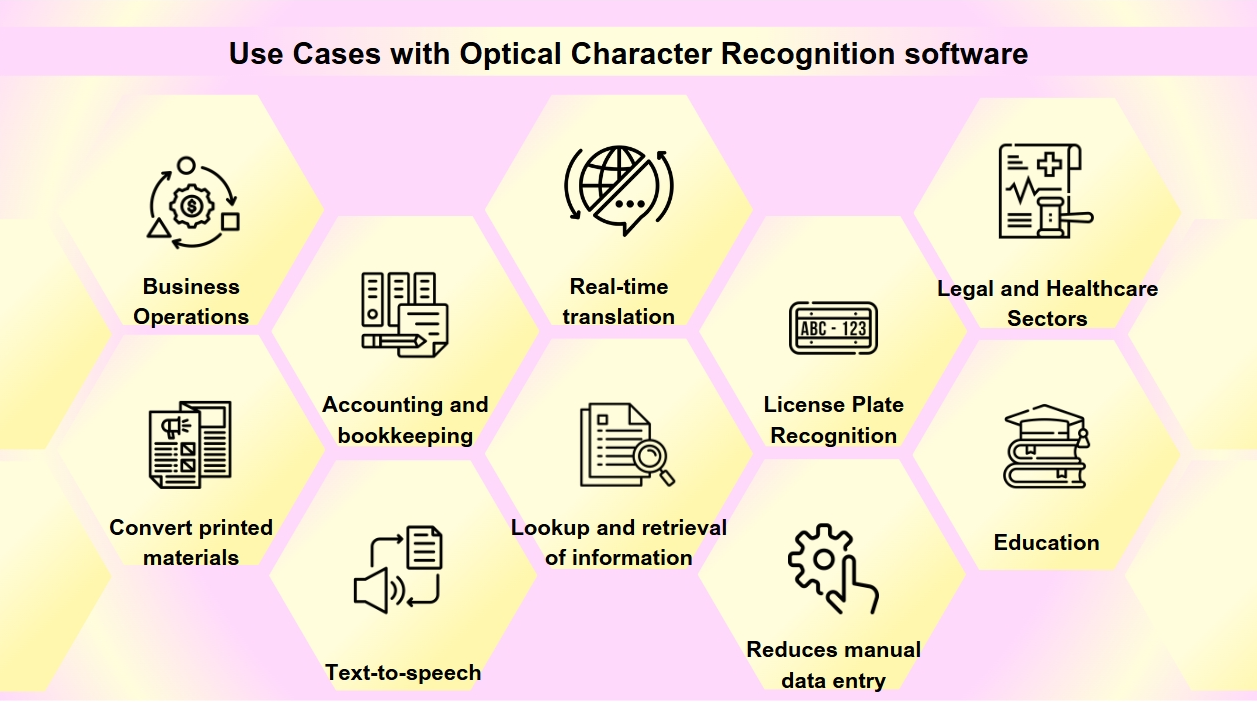
OCR:stä on tullut olennainen työkalu monien teollisuudenalojen digitaaliseen transformaatioon, tehostaen prosesseja ja parantaen datan saatavuutta ja tarkkuutta. Saatat kohdata OCR:ää useammin kuin ymmärrät. Liiketoimintakorttien skannaamisesta vanhojen kirjojen digitalisoimiseen, OCR näyttelee keskeistä roolia eri teollisuudenaloilla. OCR-teknologialla on laaja valikoima sovelluksia:
-
Asiakirjojen digitalisointi: OCR:ää käytetään painettujen materiaalien, kuten vanhojen kirjojen, sanomalehtien ja historiallisten asiakirjojen, muuntamiseen digitaalisiin muotoihin, mikä tekee niistä haettavia ja säilyttää ne tuleville sukupolville.
-
Lomakkeiden käsittely: Yritykset hyödyntävät OCR:ää automaattisesti poimiakseen tietoja lomakkeista, mikä vähentää manuaalista tietojen syöttämistä ja lisää tehokkuutta eri sektoreilla, kuten rahoituksessa ja terveydenhuollossa.
-
Laskujen käsittely: OCR-teknologia voi lukea tekstiä laskuista ja syöttää tiedot automaattisesti talousjärjestelmiin, tehostaen kirjanpito- ja tilitoimintaprosesseja.
-
Saavutettavuus: OCR mahdollistaa tekstistä puheeksi -toiminnallisuuden, luoden ääniversioita tekstistä näkövammaisille, tehden painetuista materiaaleista helpommin saavutettavia.
-
Mobiilisovellukset: OCR on integroitu sovelluksiin, jotka suorittavat tehtäviä, kuten liiketoimintakorttien skannaaminen, tekstin tunnistaminen valokuvista ja reaaliaikaisen käännöksen mahdollistaminen.
-
Haettavuus: OCR parantaa skannattujen asiakirjojen haettavuutta poimimalla tekstiä kuvista tai PDF-tiedostoista, jolloin tietojen hakeminen ja palauttaminen on helppoa.
-
Rekisterikilpien tunnistus: Käytetään pysäköinti- ja liikenteenhallinnassa, OCR voi tunnistaa rekisterikilpiä, mahdollistaen tehokkaan valvonnan ja valvonnan.
-
Liiketoimintatoiminnot: OCR tehostaa liiketoimintaprosesseja automatisoimalla tietojen syöttämistä asiakirjoista, kuten laskuista, kuitista ja ostotilauksista, sekä nopeuttamalla rekrytointia skannaamalla ja käsittelemällä työhakemuksia ja ansioluetteloita.
-
Oikeus- ja terveydenhuoltoala: Asianajotoimistot käyttävät OCR:ää digitointiin tapauksista ja oikeudellisista asiakirjoista tiedon helpottamiseksi, kun taas terveydenhuollon tarjoajat hyödyntävät sitä potilastietojen ja lääkärin lomakkeiden muuntamiseen sähköisiksi terveystiedoiksi (EHR), parantaen tietojen hallintaa ja potilashoidon laatua.
-
Koulutus: Koulutusympäristöissä OCR:ää käytetään digitaalisten oppikirjojen ja oppimateriaalien luomiseen, parantaen saavutettavuutta opiskelijoille, joilla on erilaisia tarpeita, ja tukien inklusiivista oppimisympäristöä.
Kun OCR-teknologia kehittyy, se jatkaa tärkeää rooliaan tiedon tekemisessä helpommin saavutettavaksi ja tehokkaasti käsiteltäväksi digitaalissa aikakaudessa.
OCR:n haitat: Rajoitukset ja ongelmat
Tarkkuushaasteet
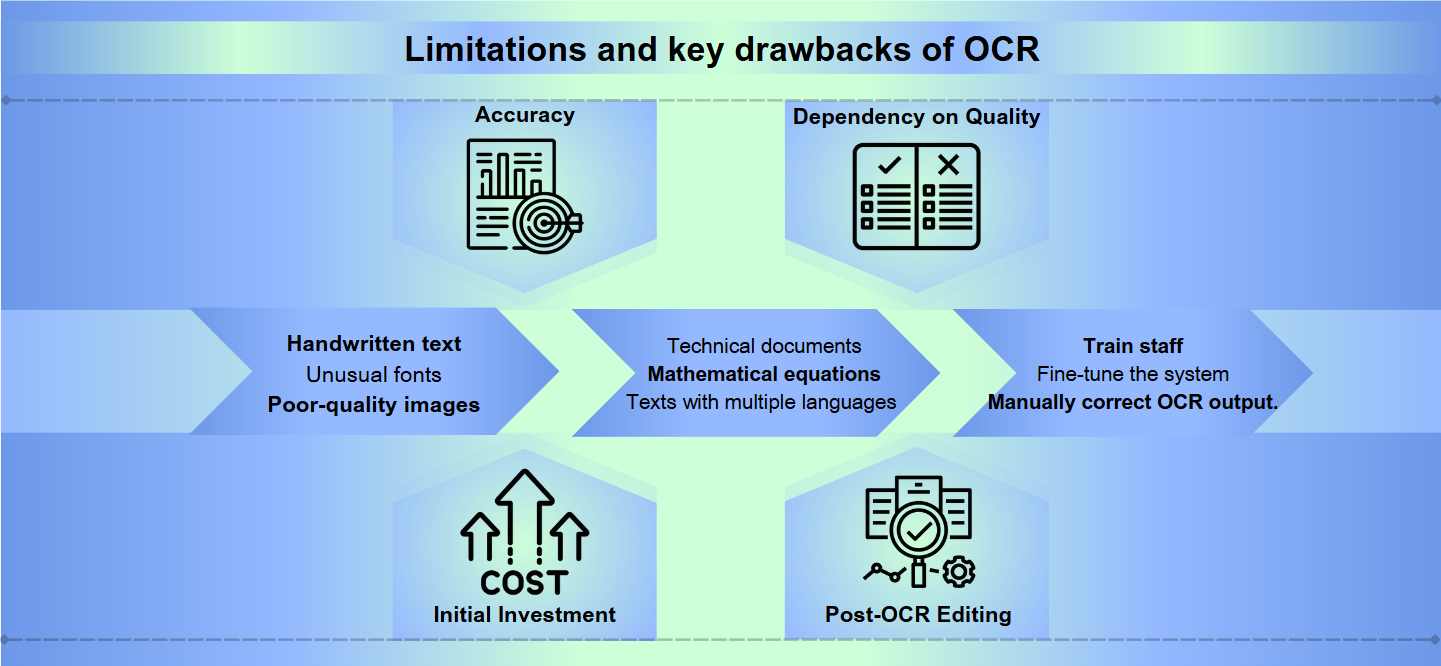
Vaikka optinen merkkitunnistus (OCR) -teknologia on edistynyt pitkälle, se kohtaa edelleen merkittäviä esteitä täydellisen tarkkuuden saavuttamisessa. Käsinkirjoitettu teksti, epätavalliset fontit tai huonolaatuiset kuvat voivat johtaa väärinymmärryksiin ja virheisiin. Jopa pienet vaihtelut merkkien muodoissa tai kooissa voivat hämmentää OCR-järjestelmiä, mikä johtaa sekavaan tulokseen, joka vaatii manuaalista korjausta.
Kieli- ja formaattirajoitukset
Useimmat OCR-ratkaisut menestyvät standardikielillä ja -muodoilla, mutta kamppailevat erikoissisällön kanssa. Teknilliset asiakirjat, matemaattiset kaavat tai tekstit, joissa on useita kieliä, voivat aiheuttaa merkittäviä haasteita. Lisäksi OCR voi epäonnistua monimutkaisissa asetteluissa, taulukoissa tai asiakirjoissa, joissa on monimutkaista muotoilua, mikä voi johtaa tärkeän rakenteellisen tiedon menettämiseen.
Resurssien intensiivisyys
Tehokkaan OCR-järjestelmän toteuttaminen ja ylläpitäminen voi olla resurssi-intensiivistä. Korkealaatuinen OCR-ohjelmisto maksaa usein paljon, ja laitteisto, jota tarvitaan suurten asiakirjamäärien käsittelyyn, voi olla kallista. Lisäksi henkilöstön kouluttamiseen, järjestelmän hienosäätöön ja OCR-tulosten manuaaliseen tarkistamiseen ja korjaamiseen tarvittava aika ja vaivannäkö voivat rasittaa organisaation resursseja.
OCR:n keskeiset haitat
-
Tarkkuus: OCR-ohjelmisto voi kamppailla tarkkuuden kanssa, erityisesti huonolaatuisten kuvien, monimutkaisten asettelujen tai käsinkirjoitetun tekstin käsittelyssä. Virheet voivat vaihdella merkkien väärinlukemisesta koko tekstin osien ohittamiseen.
-
Laatu riippuvuus: OCR:n tehokkuus riippuu voimakkaasti alkuperäisen asiakirjan laadusta. Haalistunut muste, tahraantuminen tai ryppyinen paperi voivat johtaa epätarkkoihin käännöksiin.
-
Alkuinvestointi: OCR-järjestelmän perustaminen voi vaatia merkittäviä alkuinvestointeja, mukaan lukien ei vain ohjelmisto, vaan myös yhteensopiva laitteisto, kuten skannerit.
-
Jälkeen OCR-editointi: Usein OCR-prosessien tuottama tulos vaatii manuaalista tarkistusta ja korjausta, mikä voi olla aikaa vievää.
Vision Language Model ylittämässä OCR:n rajoituksia
Teknologian kehittyessä innovatiivisia ratkaisuja nousee esiin perinteisten optisten merkkitunnistus (OCR) -menetelmien puutteiden ratkaisemiseksi. Yksi tällainen läpimurto on Vision Language Model (VLM), joka yhdistää tietokonenäön ja luonnollisen kielen käsittelyn mullistaakseen tekstin poiminnan ja ymmärtämisen.
Parannettu kontekstuaalinen ymmärrys
VLM:t erottuvat kyvyssään ymmärtää tekstin ympärillä olevaa kontekstia, toisin kuin OCR:n eristetty merkkitunnistus. Analysoimalla visuaalisia elementtejä tekstin ohella nämä mallit voivat tulkita monimutkaisia asetteluja, käsinkirjoitettuja muistiinpanoja ja jopa osittain peitettyä tekstiä huomattavalla tarkkuudella.
Monikieliset ja multimodaaliset kyvyt
Vaikka OCR usein kamppailee erilaisten kielten ja kirjoitusten kanssa, VLM:t osoittavat vaikuttavaa monipuolisuutta. Ne voivat saumattomasti käsitellä useita kieliä ja jopa tulkita visuaalista sisältöä, kuten kaavioita tai taulukoita, tarjoten kattavamman ymmärryksen asiakirjoista.
Mukautuva oppiminen ja jatkuva parantaminen
Toisin kuin staattiset OCR-järjestelmät, VLM:t hyödyntävät koneoppimista sopeutuakseen ja parantuakseen ajan myötä. Kun ne kohtaavat uusia tietoja ja tilanteita, nämä mallit hienosäätävät suorituskykyään, tullessaan yhä taitavammiksi erilaisten asiakirjatyyppien ja -muotojen käsittelyssä.
Ylittämällä OCR:n rajoituksia Vision Language Modelit avustavat tarkemman, tehokkaamman ja älykkäämmän asiakirjakäsittelyn kehittämisessä eri teollisuudenaloilla.
Valitse Vision Language Model: Kokeile AnyParseria
Rakentuen Vision Language Modelien (VLM) edistysaskeliin, AnyParser nousee hienostuneena ratkaisuna, joka ylittää perinteisen OCR-teknologian rajoitukset. CambioML-tiimin kehittämä AnyParser on tehokas asiakirjojen purkuväline, joka hyödyntää tarkkaa ja konfiguroitavaa API:a tietojen poimimiseksi erilaisista jäsentämättömistä tietolähteistä, kuten PDF-tiedostoista, kuvista ja kaavioista, muuttaen ne jäsennellyiksi muodoiksi.
Tekninen perusta ja kyvyt
AnyParser perustuu suurten kielimallien (LLM) vankalle perustalle, mikä takaa korkean tarkkuuden tekstin, taulukon, kaavion ja asettelun poiminnassa asiakirjoista. Se erottuu kyvyllään säilyttää alkuperäinen asettelu ja muoto, mikä on erityisen hyödyllistä monimutkaisissa asiakirjoissa tai asiakirjoissa, joissa alkuperäisen esteettisyyden säilyttäminen on tärkeää.
Yksityisyys ja turvallisuus
Käyttäjien yksityisyyden korostamiseksi AnyParser käsittelee tietoja paikallisesti, suojaten siten arkaluontoista tietoa. Tämä ominaisuus on merkittävä etu yrityksille ja yksilöille, jotka käsittelevät luottamuksellisia tietoja.
Mukautettavuus ja joustavuus
Tarjoamalla korkean tason konfiguroitavuutta AnyParser antaa käyttäjille mahdollisuuden asettaa mukautettuja poimintasääntöjä ja määrittää ulostulomuotoja, jotka vastaavat heidän erityistarpeitaan. Tämä mukautettavuus tekee siitä ihanteellisen työkalun laajalle sovellusalueelle, aina tekoälyn kehittämisestä taloudelliseen analyysiin.
Yhteenveto
Kuten olet oppinut, OCR-teknologia tarjoaa voimakkaita kykyjä tekstin digitalisoimiseen, mutta se ei ole ilman rajoituksia. Vaikka optinen merkkitunnistus voi dramaattisesti parantaa tehokkuutta, sinun on punnittava mahdollisia haittoja huolellisesti. Ota huomioon tarkkuusongelmat, muotoilun haasteet ja resurssivaatimukset ennen OCR-ratkaisun toteuttamista. Lopulta päätös OCR:n käyttämisestä riippuu erityistarpeistasi ja olosuhteistasi. Ymmärtämällä sekä hyödyt että haitat voit tehdä tietoon perustuvan päätöksen siitä, onko OCR oikea valinta organisaatiollesi. Kun OCR jatkaa kehittymistään, pysy ajan tasalla uusista kehityksistä, jotka saattavat ratkaista nykyiset puutteet ja avata vielä suurempia mahdollisuuksia tälle mullistavalle teknologialle.
Toimintakehotus
Hyödynnä Vision Language Modelien voimaa kokeilemalla AnyParseria ilmaiseksi muuttaaksesi PDF-tiedostosi Google Sheetsiksi osoitteessa https://www.cambioml.com/sandbox. Saat ilmaisen konsultoinnin siitä, kuinka VLM:t voivat parantaa tietojen poimintaprosessiasi.