L'industrie bancaire opère dans un vaste et complexe paysage de données, où l'information est le sang vital des opérations. Les banques traitent un volume énorme de données chaque jour, allant des transactions des clients aux documents de conformité réglementaire. Ces données sont souvent complexes et non structurées, posant des défis significatifs pour les méthodes de traitement des données traditionnelles. La variété et le volume des sources de données, y compris les demandes de prêt, les formulaires d'intégration des clients et les enregistrements de transactions, nécessitent une approche plus sophistiquée de la gestion des données.
L'intégration de l'automatisation pilotée par l'IA est une partie significative de la transformation numérique dans le secteur bancaire, révolutionnant la manière dont les données sont traitées et analysées. L'importance de l'automatisation pilotée par l'IA dans la transformation des processus bancaires traditionnels ne saurait être sous-estimée. Les technologies d'IA, en particulier le parsing intelligent de documents (IDP), révolutionnent la manière dont les banques gèrent les données. L'IDP joue un rôle crucial dans les processus ETL (Extraire, Transformer, Charger). En automatisant l'extraction et le traitement des données à partir de divers documents, l'IDP améliore l'efficacité, la précision et l'évolutivité des processus ETL, soutenant ainsi une meilleure prise de décision et la conformité aux exigences réglementaires.

Comprendre l'ETL dans le secteur bancaire
Une définition complète d'un relevé bancaire inclut toutes les transactions, les détails du compte et les mises à jour de solde, servant de document critique pour le rapprochement et l'analyse. L'ETL (Extraire, Transformer, Charger) est un processus essentiel dans la gestion des données bancaires, responsable de la préparation des données pour l'analyse et la prise de décision. Chaque étape joue un rôle crucial :
-
Extraire : Les données sont collectées à partir de diverses sources, telles que les demandes des clients, les relevés bancaires et les rapports réglementaires. Une définition claire du relevé bancaire aide à rationaliser ce processus d'extraction. Ces sources incluent souvent des formats structurés comme des bases de données et des données semi-structurées ou non structurées, y compris des documents numérisés, des PDF et des e-mails.
-
Transformer : Les données extraites subissent un nettoyage et un formatage pour s'aligner sur un schéma unifié, garantissant cohérence et utilisabilité. Par exemple, les données provenant des demandes de prêt peuvent être transformées pour inclure des formats standard pour les dates ou les chiffres de revenus.
-
Charger : Enfin, les données traitées sont stockées dans un système cible, tel qu'un entrepôt de données, où elles sont prêtes pour des requêtes, des rapports et une analyse plus approfondie.
Les flux de travail bancaires, tels que la création d'un relevé de rapprochement bancaire, dépendent fortement de processus ETL précis. Un relevé de rapprochement compare les enregistrements de transactions des systèmes internes avec les relevés bancaires pour garantir la cohérence, mais des erreurs dans l'extraction des données peuvent perturber ce processus.
Malgré son importance, les processus ETL traditionnels dans le secteur bancaire font face à plusieurs défis :
-
Volume de données : Avec des millions de transactions et d'interactions clients chaque jour, gérer ce volume est décourageant.
-
Formats divers : Les banques traitent des données provenant de divers formats, y compris des documents papier, des e-mails et des relevés bancaires, compliquant le processus d'extraction.
-
Erreurs manuelles : La dépendance à l'intervention humaine augmente le risque d'erreurs dans la transformation et l'intégration.
-
Pressions réglementaires : Assurer la conformité avec des réglementations strictes nécessite une précision dans le traitement et le reporting des données.
Des technologies émergentes comme les modèles de langage visuel (VLM) ouvrent la voie à l'automatisation de la compréhension des documents dans les flux de travail ETL. En permettant une compréhension nuancée de documents comme les relevés bancaires, ces modèles améliorent la précision des données et réduisent le temps de traitement.
Comment fonctionne le parsing intelligent de documents
Le parsing intelligent de documents (IDP) exploite des technologies d'IA avancées pour extraire et comprendre des informations à partir de documents avec rapidité et précision. Voici comment cela fonctionne :
-
Ingestion de documents : Les outils IDP acceptent des documents dans divers formats, tels que des PDF numérisés (comme un relevé bancaire PDF), des images, des e-mails et des formulaires numériques, y compris des relevés bancaires et des documents de rapprochement.
-
Reconnaissance optique de caractères (OCR) : Pour les documents numérisés ou basés sur des images, la technologie OCR identifie et convertit le texte en données lisibles par machine. Les solutions OCR avancées peuvent gérer des numérisations de mauvaise qualité, des notes manuscrites et des mises en page complexes trouvées dans les relevés bancaires.
-
Traitement du langage naturel (NLP) : Le NLP est utilisé pour interpréter le texte dans son contexte, reconnaissant les entités (par exemple, numéros de compte, montants des transactions) et les relations entre elles. Cela est particulièrement utile pour créer un relevé de rapprochement bancaire, où les correspondances de transactions doivent être identifiées avec précision.
-
Modèles de langage visuel (VLM) : Ces systèmes d'IA avancés intègrent des données visuelles et textuelles, permettant une compréhension contextuelle plus profonde des documents. Par exemple, ils peuvent distinguer les en-têtes, les tableaux et les notes de bas de page dans un relevé bancaire pour garantir une extraction complète des données.
-
Structuration des données : Les informations extraites sont structurées dans un format compatible avec les systèmes de données de la banque, garantissant une intégration fluide dans les processus ETL en aval.
-
Validation et vérification : Des contrôles automatisés garantissent l'exactitude des données, signalant les incohérences pour examen.
En incorporant des technologies comme les VLM, l'IDP transforme le traitement traditionnel des documents, le rendant plus efficace et fiable pour les tâches bancaires, y compris les processus ETL et de rapprochement.
Avantages du parsing intelligent de documents dans l'ETL pour la banque
L'adoption de l'IDP dans les processus ETL apporte plusieurs avantages au secteur bancaire :
-
Efficacité : L'IDP automatise l'extraction et la transformation des données, réduisant considérablement le temps nécessaire pour ces processus. Cette automatisation permet aux banques de gérer de grands volumes de données plus rapidement et efficacement.
-
Précision : En minimisant l'intervention humaine, l'IDP réduit la probabilité d'erreurs dans le traitement des données. Cette précision est cruciale pour les vérifications de conformité et garantit que les données utilisées pour la prise de décision sont fiables.
-
Scalabilité : Les systèmes IDP peuvent gérer de grands volumes de données sans effort, les rendant idéaux pour l'environnement intensif en données de la banque. Par exemple, les solutions IDP permettent aux banques de convertir efficacement un relevé bancaire en Excel, rendant la transformation et l'analyse des données plus accessibles. À mesure que les volumes de données augmentent, les systèmes IDP peuvent évoluer en conséquence sans augmentation proportionnelle des ressources ou des coûts.
-
Réduction des coûts : L'automatisation via l'IDP réduit les coûts opérationnels en diminuant le besoin d'entrée et de traitement manuels des données. Cette réduction des coûts est particulièrement significative dans le contexte du traitement de données à grande échelle.
-
Conformité réglementaire : L'IDP garantit l'exactitude des données, ce qui est essentiel pour les audits et la conformité aux exigences réglementaires. En automatisant les vérifications de conformité, les banques peuvent atténuer les risques associés à la non-conformité.
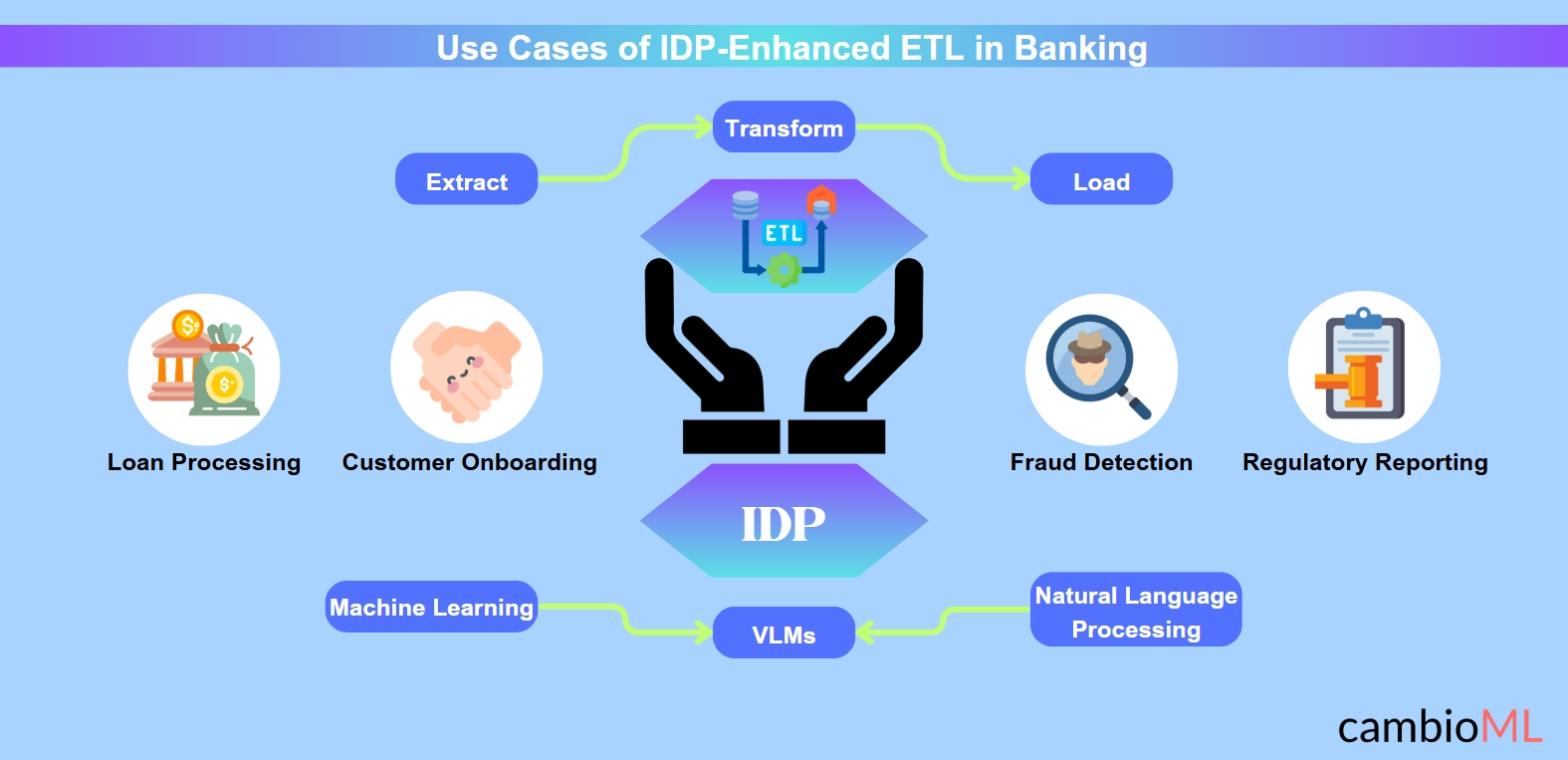
Cas d'utilisation de l'ETL amélioré par l'IDP dans le secteur bancaire
-
Traitement des prêts : Le processus d'approbation des prêts implique souvent le parsing de plusieurs documents, y compris des bulletins de salaire, des déclarations fiscales et des relevés bancaires. L'IDP automatise l'extraction des détails clés comme les revenus, les scores de crédit et l'historique d'emploi, réduisant considérablement les temps de traitement.
-
Intégration des clients : L'IDP simplifie les processus KYC en extrayant et en validant les informations à partir de documents d'identité, de factures de services publics et de relevés bancaires PDF. Cela accélère l'intégration des clients tout en maintenant la conformité avec les réglementations anti-blanchiment (AML).
-
Création de relevés de rapprochement bancaire : Les processus de rapprochement comparent les enregistrements de transactions internes avec des relevés bancaires externes. L'IDP garantit l'extraction précise et la comparaison des données de transaction, automatisant la préparation des relevés de rapprochement bancaire. Cela élimine les erreurs manuelles et réduit le temps nécessaire pour les audits financiers.
-
Détection de fraude : En analysant les données provenant de factures, de contrats et d'enregistrements de transactions, y compris les relevés bancaires, l'IDP aide les banques à identifier des anomalies indiquant une fraude potentielle. Par exemple, des détails de transaction discordants peuvent être signalés pour une enquête plus approfondie.
-
Reporting réglementaire : La conformité avec des cadres réglementaires comme Bâle III et le RGPD nécessite un reporting précis. L'IDP, alimenté par des modèles de langage visuel, extrait et consolide les données provenant de divers rapports et relevés, garantissant des soumissions en temps voulu et sans erreur. Cela soutient la transformation numérique plus large dans le secteur bancaire.
Technologies propulsant le parsing intelligent de documents dans la banque
Plusieurs technologies de pointe alimentent le parsing intelligent de documents, garantissant son efficacité dans le secteur bancaire :
-
Apprentissage automatique (ML) : Les modèles ML s'améliorent continuellement en apprenant à partir de vastes quantités de données bancaires. Ces modèles s'adaptent pour reconnaître de nouveaux formats de documents, y compris les variations dans les relevés bancaires, et extraire des données avec une grande précision au fil du temps.
-
Traitement du langage naturel (NLP) : Les capacités NLP permettent aux systèmes IDP de comprendre le contexte, la syntaxe et la sémantique dans le texte non structuré. Cela est critique pour interpréter des documents bancaires complexes comme des enregistrements de rapprochement ou des déclarations liées à la conformité.
-
Modèles de langage visuel (VLM) : Les VLM représentent le prochain saut dans l'IA en combinant compréhension visuelle et textuelle. Ces modèles excellent dans le parsing de documents semi-structurés et non structurés comme les relevés bancaires, garantissant la précision dans l'extraction de tableaux de données, de graphiques et d'annotations textuelles.
-
Reconnaissance optique de caractères (OCR) : Des moteurs OCR avancés peuvent lire des notes manuscrites, des numérisations de faible résolution et des mises en page multi-colonnes, permettant une extraction précise des données même à partir de formats de documents difficiles comme des relevés bancaires PDF complexes et des relevés de rapprochement détaillés.
-
Informatique en nuage : Les solutions IDP basées sur le cloud offrent évolutivité et capacités de traitement en temps réel. Les banques peuvent gérer des volumes de données fluctuants, y compris des téléchargements en masse de relevés bancaires, sans investir dans une infrastructure sur site extensive.
-
Intégration API : Les plateformes IDP modernes s'intègrent parfaitement aux systèmes bancaires tels que les CRM, les entrepôts de données et les outils d'analyse, permettant un flux de données fluide à travers le pipeline ETL. Elles peuvent traiter des entrées comme des relevés bancaires numérisés et des enregistrements de rapprochement directement dans les flux de travail existants.
En tirant parti de ces technologies, y compris les VLM, les solutions IDP garantissent que les banques peuvent traiter les données efficacement, maintenir la conformité et améliorer la précision des résultats critiques comme les relevés de rapprochement bancaire. Les outils IDP avancés intègrent la définition du relevé bancaire pour améliorer la compréhension contextuelle de l'extraction et du parsing des données.
Défis de la mise en œuvre de l'IDP pour l'ETL
Bien que l'IDP offre des avantages significatifs, sa mise en œuvre dans le secteur bancaire présente des défis :
-
Confidentialité et sécurité des données : La gestion d'informations sensibles sur les clients nécessite des mesures de sécurité robustes pour protéger la confidentialité des données. Les banques doivent garantir la conformité avec les réglementations sur la protection des données et mettre en œuvre de solides mécanismes de cryptage et de contrôle d'accès.
-
Documents multilingues et multi-formats : Les banques traitent souvent des documents dans plusieurs langues et formats. Les systèmes IDP doivent être capables de parser et de comprendre ces variations avec précision pour garantir l'intégrité des données.
-
Résistance à l'adoption de l'IA : Il peut y avoir une résistance à l'adoption de solutions pilotées par l'IA au sein des systèmes hérités. Les banques peuvent faire face à des défis pour intégrer de nouvelles technologies avec des processus existants et peuvent devoir surmonter le scepticisme des parties prenantes.
Comment AnyParser améliore les processus ETL
AnyParser, développé par CambioML, est un puissant outil de parsing de documents qui exploite une technologie avancée de modèles de langage pour extraire du contenu de divers formats de fichiers, y compris les fichiers PDF et DOCX. Il se distingue par sa capacité à améliorer les processus ETL (Extraire, Transformer, Charger) avec son ensemble unique d'avantages :
Précision et exactitude
AnyParser est conçu pour une haute précision, copiant avec exactitude les données des tableaux à partir de PDF vers Excel tout en maintenant la mise en page et le format d'origine. Cela garantit un minimum d'erreurs de conversion, ce qui est critique dans les analyses financières et la prise de décisions basées sur les données dans le secteur bancaire.
Confidentialité et sécurité
AnyParser traite les données localement, protégeant la vie privée des utilisateurs et les informations sensibles. Cela est particulièrement important dans le secteur bancaire, où la gestion des données sensibles des clients et des transactions est une priorité.
Configurabilité
Les utilisateurs peuvent définir des règles d'extraction personnalisées et des formats de sortie, offrant une flexibilité pour extraire des tableaux à partir de PDF selon des exigences spécifiques. Cette configurabilité permet aux banques d'adapter le processus ETL à leurs besoins uniques.
Support multi-sources
AnyParser est capable d'extraire des informations à partir de diverses sources de données non structurées, y compris des PDF, des images et des graphiques. Ce support multi-sources est bénéfique pour les banques qui traitent divers types de documents.
Sortie structurée
AnyParser convertit les informations extraites en formats structurés comme Excel, permettant aux utilisateurs de convertir facilement un relevé bancaire en Excel, facilitant ainsi l'analyse et le traitement. Cette sortie structurée est essentielle pour la phase de transformation des processus ETL dans le secteur bancaire.
Rationalisation des flux de données
AnyParser peut automatiser l'extraction de données, le traitement en temps réel, la génération de rapports personnalisables et la gestion proactive des risques avec des alertes intelligentes. Ces capacités rationalisent les flux de données, améliorant l'efficacité opérationnelle et permettant des décisions plus rapides et éclairées par les données.
Points techniques
AnyParser utilise des modèles de langage visuel (VLM) pour une extraction avancée de tableaux PDF, garantissant une copie précise des tableaux PDF vers Excel et fournissant une compréhension contextuelle au sein des documents. Cette sophistication technique permet une extraction de données précise même à partir de documents complexes et multilingues.
Intégration et automatisation
AnyParser offre une interface fluide pour des flux de travail d'extraction de données PDF automatisés via son API, qui peut être intégrée dans diverses applications, simplifiant des flux de travail tels que la conversion de relevés bancaires en Excel pour une analyse plus rapide. Cette capacité d'intégration est cruciale pour automatiser les processus ETL dans le secteur bancaire, réduisant l'intervention manuelle et les erreurs associées.
En tirant parti des fonctionnalités avancées d'AnyParser, les banques peuvent améliorer leurs processus ETL, conduisant à une meilleure précision des données, une efficacité opérationnelle accrue et une conformité avec les exigences réglementaires. La capacité d'AnyParser à gérer des structures de documents complexes, à maintenir la confidentialité des données et à fournir des sorties structurées en fait un atout précieux dans les stratégies de gestion des données de l'industrie bancaire.
Tendances et opportunités futures
La transformation numérique continue dans le secteur bancaire verra une adoption accrue du traitement des données en temps réel et des outils d'IA avancés. L'avenir de l'IDP dans le secteur bancaire est prometteur, avec plusieurs tendances et opportunités à l'horizon :
-
Augmentation de l'adoption de l'IA : Le secteur bancaire devrait connaître une augmentation continue de l'adoption d'outils pilotés par l'IA. À mesure que ces outils deviennent plus sophistiqués, ils joueront un rôle encore plus important dans le traitement des données et la prise de décision.
-
IA générative et grands modèles de langage : Le rôle de l'IA générative et des grands modèles de langage dans l'amélioration des capacités de l'IDP est appelé à croître. Ces avancées amélioreront la précision et l'efficacité du parsing de documents, en particulier pour les données complexes et non structurées.
-
Prise de décision en temps réel : L'expansion des solutions IDP dans les processus de prise de décision en temps réel permettra aux banques de réagir plus rapidement aux changements du marché et aux besoins des clients. Cela sera particulièrement précieux dans des domaines tels que la détection de fraude et la gestion des risques.
Appel à l'action
Si vous êtes prêt à révolutionner vos processus ETL avec la puissance de l'IA et à porter vos opérations bancaires à un niveau supérieur, nous vous invitons à explorer les capacités d'AnyParser. Rejoignez-nous dans notre mission de simplifier les flux de données et d'améliorer l'efficacité opérationnelle. Essayez notre sandbox pour en savoir plus et commencer dès aujourd'hui : AnyParser