Introduction
Les tableaux sont une pierre angulaire de la représentation des données structurées, largement utilisés dans des secteurs comme la finance, la santé et la recherche. Cependant, l'extraction d'informations tabulaires à partir de formats tels que les PDF, les documents scannés ou les images reste un défi en raison des mises en page variées et des complexités.
L'intelligence artificielle (IA) a révolutionné le parsing de documents, permettant des solutions précises et efficaces aux problèmes tels que l'extraction d'un tableau d'un PDF ou la conversion d'un tableau PNG en données structurées. En s'appuyant sur des techniques avancées d'IA, les entreprises peuvent désormais transformer facilement des visuels non structurés en informations exploitables, y compris la conversion d'une image en tableau pour une intégration fluide dans les flux de travail.
Ce blog explore comment l'extraction de tableaux par IA permet aux industries de progresser, met en lumière les technologies sous-jacentes et montre son potentiel à simplifier des tâches complexes de traitement de documents.

Défis de l'extraction de tableaux traditionnelle
L'extraction manuelle de données tabulaires à partir de documents comme les PDF ou les images est fastidieuse, sujette aux erreurs et inefficace. Voici quelques-uns des défis courants rencontrés avec les méthodes traditionnelles :
-
Structures de tableaux complexes : Les tableaux ont souvent des mises en page irrégulières, telles que des cellules imbriquées, des en-têtes multi-lignes ou des lignes fusionnées, qui sont difficiles à interpréter. Les outils traditionnels échouent à extraire avec précision un tableau d'un PDF dans de tels scénarios.
-
Formats divers : Les tableaux apparaissent dans une large gamme de formats, y compris des documents scannés, des fichiers PNG de tableaux et des PDF. L'extraction de données à partir de ceux-ci nécessite des techniques de reconnaissance avancées qui vont au-delà de l'OCR simple.
-
Contexte et signification : Les systèmes traditionnels ont du mal à préserver les relations entre les lignes et les colonnes, ce qui est crucial lors de la conversion d'une image en tableau ou du traitement de grands ensembles de données.
Ces défis soulignent la nécessité de solutions intelligentes comme l'extraction de tableaux par IA, qui peuvent gérer des mises en page complexes et des formats divers tout en garantissant une grande précision.
Qu'est-ce que l'extraction de tableaux par IA ?
L'extraction de tableaux par IA est l'application de techniques de parsing intelligent de documents conçues pour identifier, extraire et organiser des données structurées à partir de tableaux dans divers formats de documents. Contrairement aux méthodes traditionnelles basées sur des règles, les approches pilotées par l'IA utilisent des technologies avancées pour relever des défis complexes, tels que des mises en page non standard, des cellules fusionnées et des en-têtes multi-lignes.
Une avancée clé dans ce domaine est l'utilisation des Modèles Vision-Langage (VLM). Les VLM combinent les forces de la vision par ordinateur et de la compréhension du langage naturel, leur permettant d'interpréter à la fois les éléments visuels et textuels au sein d'un document. Cette double capacité permet aux VLM de :
- Identifier visuellement les structures de tableaux, même lorsqu'elles manquent de formatage explicite.
- Comprendre contextuellement le contenu, comme distinguer les en-têtes, les données et les notes.
- S'adapter à divers types de documents, y compris les images scannées, les PDF et les notes manuscrites.
En s'appuyant sur les VLM, l'extraction de tableaux par IA est devenue plus précise et polyvalente, capable de traiter des documents multilingues et d'extraire des relations entre les points de données que les méthodes traditionnelles manquent souvent.
Technologies clés derrière l'extraction de tableaux par IA
L'extraction de tableaux par IA repose sur un ensemble de technologies avancées qui travaillent en harmonie pour surmonter les défis traditionnels. Parmi celles-ci, les Modèles Vision-Langage (VLM) se distinguent comme une innovation transformative. Voici un aperçu des technologies clés et du rôle central des VLM :
-
Reconnaissance Optique de Caractères (OCR) : Extrait du texte à partir d'images ou de documents scannés. Lorsqu'elle est associée aux VLM, les résultats de l'OCR sont améliorés car les modèles comprennent à la fois la structure visuelle et la signification textuelle.
-
Modèles Vision-Langage (VLM) : Les VLM révolutionnent l'extraction de tableaux en intégrant le traitement des données visuelles et linguistiques. Ils excellent dans :
- La reconnaissance de mises en page de tableaux complexes et de frontières irrégulières.
- L'interprétation des relations entre les lignes, les colonnes et les en-têtes.
- La gestion de tableaux dans divers formats, y compris les images et les PDF, avec un support multilingue. Les VLM permettent une compréhension contextuelle plus profonde, garantissant que les données extraites conservent leur signification et leur structure d'origine.
-
Traitement du Langage Naturel (NLP) : Analyse et organise les données extraites, garantissant la cohérence sémantique. Les VLM améliorent encore le NLP en fournissant des indices contextuels à partir de motifs visuels.
-
Algorithmes d'Apprentissage Profond : Entraînent des modèles pour détecter les frontières de tableaux, les hiérarchies de cellules et les motifs dans des documents non structurés. Enrichis par les VLM, ces algorithmes atteignent une plus grande précision et adaptabilité.
En mettant l'accent sur les VLM, l'extraction de tableaux par IA est passée d'une tâche de simple récupération de données à une compréhension contextualisée, la rendant inestimable pour les industries où la précision et la nuance sont primordiales.
Cas d'utilisation de l'extraction de tableaux par IA
L'extraction de tableaux alimentée par l'IA transforme les industries en automatisant le processus d'extraction et d'organisation des données tabulaires à partir de divers formats de documents. Voici quelques cas d'utilisation notables où l'extraction intelligente de tableaux s'est révélée inestimable :
-
Finance : L'extraction de données structurées à partir d'états financiers, de factures et de rapports est souvent une tâche laborieuse. L'IA facilite la copie de tableaux PDF vers Excel, permettant une réconciliation, une analyse et un reporting plus rapides.
-
Santé : L'organisation des résultats d'essais cliniques, des dossiers patients ou des données de recherche médicale est simplifiée. Par exemple, les prestataires de soins de santé peuvent facilement copier un tableau d'un PDF vers Excel, garantissant que les données sont prêtes pour une intégration dans les systèmes de dossiers de santé électroniques (DSE).
-
Juridique : L'analyse des contrats et l'extraction de clauses structurées à partir de tableaux imbriqués aident les équipes juridiques à travailler plus efficacement. Les modèles d'IA rendent facile la copie d'un tableau PDF vers Excel, économisant du temps lors des vérifications de conformité et des recherches en litige.
-
Recherche et Académie : Les chercheurs peuvent rapidement extraire des données d'articles académiques, simplifiant la tâche de transfert de métriques clés en utilisant des outils pour copier un tableau d'un PDF vers Excel, rendant les ensembles de données prêts pour une analyse statistique.
La capacité de l'extraction de tableaux par IA à traiter avec précision divers formats de documents révolutionne les flux de travail, facilitant la copie, l'organisation et l'analyse des données tabulaires dans des feuilles Excel.
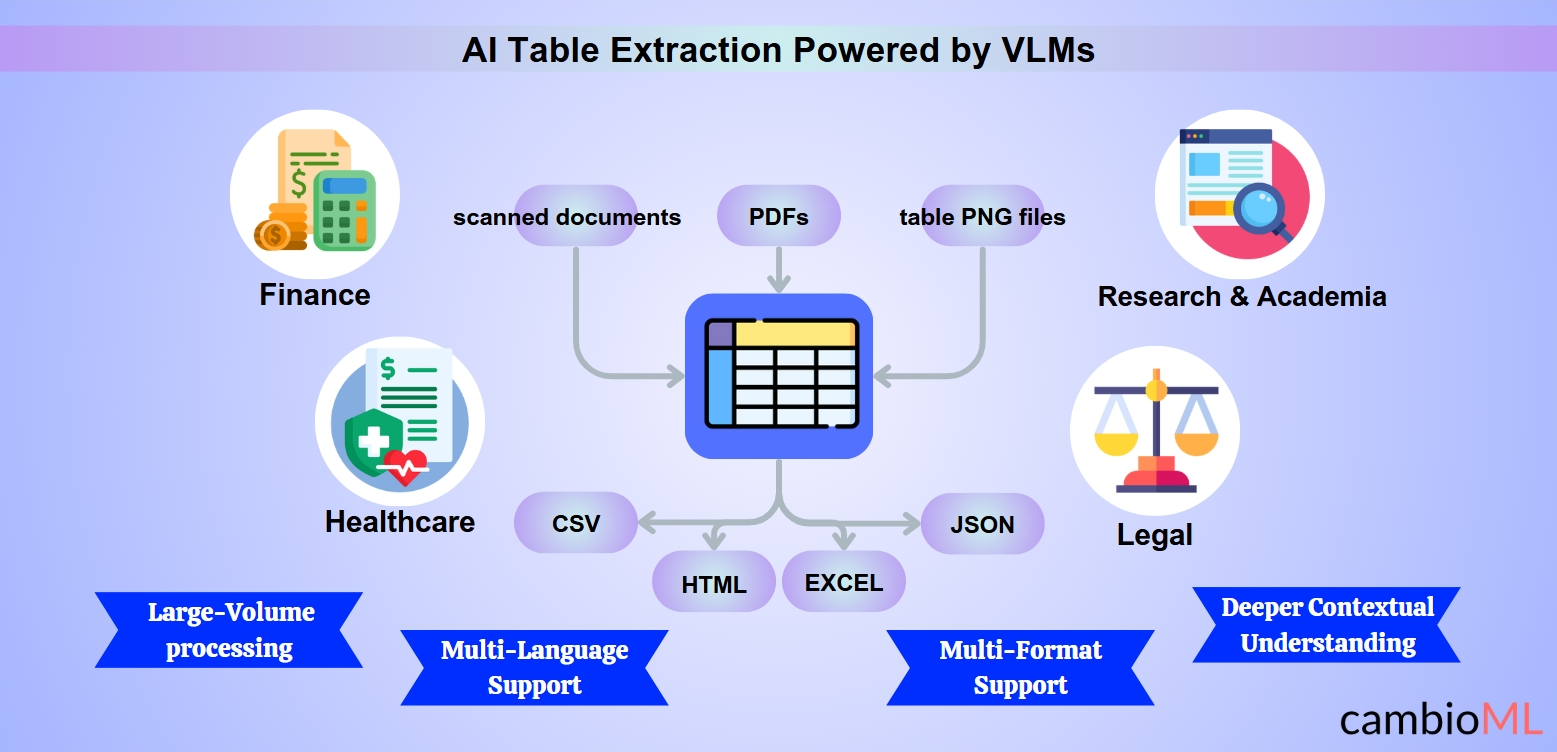
Avantages de l'extraction intelligente de tableaux
L'extraction de tableaux par IA offre une multitude d'avantages, notamment en améliorant l'efficacité, la précision et l'évolutivité. En s'appuyant sur des technologies avancées, y compris les Modèles Vision-Langage (VLM), les entreprises peuvent surmonter les défis traditionnels de l'extraction de tableaux :
-
Automatisation et économies de temps : Les tâches répétitives comme la copie manuelle de tableaux d'un PDF vers Excel sont éliminées, permettant aux employés de se concentrer sur des activités à plus forte valeur ajoutée.
-
Précision améliorée : Les modèles d'IA réduisent considérablement les erreurs courantes lorsque les utilisateurs copient manuellement un tableau PDF vers Excel ou s'appuient sur des outils basiques. Ces modèles garantissent que les données conservent leur structure et leur signification.
-
Évolutivité pour le traitement en grande quantité : Les outils d'IA sont conçus pour gérer l'extraction de données en masse. Qu'il s'agisse de dossiers financiers, de documents de recherche ou de fichiers de conformité, ils simplifient le processus d'extraction et d'organisation des données dans Excel.
-
Support multi-format et multi-langue : Les systèmes intelligents peuvent traiter des documents dans divers formats et langues, permettant une extraction fluide et la copie de tableaux d'un PDF vers Excel même dans des contextes multilingues complexes.
L'extraction de tableaux par IA non seulement rationalise les flux de travail, mais garantit également l'intégrité contextuelle des données, transformant la manière dont les industries gèrent les informations tabulaires. Cette efficacité est cruciale dans le monde axé sur les données d'aujourd'hui, où un traitement rapide et précis des données tabulaires constitue un avantage concurrentiel.
Répondre aux défis multi-format et multi-langue
Les solutions d'IA modernes excellent à relever la variabilité des formats et des langues, garantissant une précision et une efficacité constantes à travers des ensembles de données divers :
-
Capacités multi-format : Les outils alimentés par l'IA peuvent traiter sans effort des PDF, des documents scannés et des fichiers image comme les tableaux PNG. Cette polyvalence est particulièrement critique lorsque les utilisateurs ont besoin d'extraire un tableau d'un PDF ou de convertir une image en tableau pour l'analyse et le reporting.
-
Support multi-langue : Les modèles d'IA sont entraînés sur des ensembles de données multilingues, leur permettant de traiter des documents dans diverses langues. Cette fonctionnalité est inestimable pour les industries mondiales traitant de la documentation internationale.
-
Préservation des relations de données : Que ce soit pour traiter une image en tableau ou extraire une structure complexe d'un PDF, les systèmes d'IA garantissent que les en-têtes, les lignes et les colonnes sont préservés, maintenant l'intégrité des données.
En répondant à ces défis, les solutions d'IA se sont établies comme des outils indispensables pour les organisations gérant une documentation à grande échelle, multilingue et multi-format.
L'avenir de l'IA dans l'extraction de tableaux
L'avenir de l'extraction de tableaux par IA est prometteur, avec des avancées qui devraient encore améliorer ses capacités :
-
Modèles Vision-Langage (VLM) améliorés : Les technologies VLM émergentes fourniront des moyens encore plus sophistiqués d'extraire un tableau d'un PDF et de convertir des formats de tableaux PNG complexes en données structurées. Ces modèles combleront le fossé entre les éléments visuels et la compréhension textuelle.
-
Intégration avec l'IA générative : En intégrant l'IA générative, les solutions futures pourraient non seulement extraire des tableaux d'un PDF ou d'images, mais aussi analyser les données extraites pour des informations, des résumés et des recommandations.
-
Automatisation de bout en bout : Les outils pilotés par l'IA rationaliseront les flux de travail en convertissant automatiquement des fichiers, comme la transformation d'une image en tableau, en catégorisant les données et en les alimentant directement dans des pipelines d'analyse.
-
Accessibilité élargie : Les systèmes d'IA deviendront plus conviviaux et accessibles, permettant même aux utilisateurs non techniques de traiter des fichiers PNG de tableaux ou d'extraire des données sans effort.
L'extraction de tableaux par IA est prête à redéfinir le traitement de documents, rendant l'extraction de données plus rapide, plus intelligente et plus adaptable aux besoins évolutifs des industries. Les entreprises qui adoptent ces solutions obtiendront un avantage concurrentiel dans la gestion et l'utilisation efficace de leurs données.
AnyParser : Un changeur de jeu dans le parsing de documents et l'extraction de tableaux
AnyParser est à la pointe du parsing intelligent de documents, offrant aux entreprises un moyen efficace et fiable d'extraire des données même des documents les plus complexes. Ses capacités avancées sont particulièrement évidentes en matière d'extraction de tableaux, garantissant une capture de données précise et évolutive pour divers secteurs.
Avantages clés d'AnyParser pour l'extraction de tableaux
-
Support complet des formats : Que ce soit pour des PDF, des images ou d'autres types de fichiers, AnyParser simplifie la capture de données en extrayant avec précision des informations tabulaires, quel que soit le format.
-
Haute précision et compréhension contextuelle : Contrairement aux outils traditionnels, AnyParser préserve la structure, les relations et le contexte des données tabulaires, fournissant des résultats prêts pour l'analyse et l'intégration.
-
Efficacité pilotée par l'IA : Alimenté par des Modèles Vision-Langage (VLM), AnyParser excelle dans des environnements multilingues et multi-format, garantissant une capture de données fluide à grande échelle.
-
Flux de travail personnalisables : La plateforme s'adapte à vos besoins uniques, que vous extrayez des tableaux financiers, des dossiers de santé ou des données de recherche.
Avec AnyParser, les entreprises peuvent optimiser leurs processus, minimiser les erreurs et gagner du temps en automatisant la tâche complexe d'extraction de tableaux pour la capture de données structurées.
Conclusion
L'extraction de tableaux alimentée par l'IA a redéfini la manière dont les entreprises traitent et utilisent les données structurées. Que la tâche consiste à extraire des tableaux de PDF, à traiter des images ou à réaliser une capture de données précise, des outils comme AnyParser facilitent plus que jamais la transformation de documents non structurés en informations exploitables. AnyParser est votre solution de confiance pour simplifier le parsing de documents, offrant une précision et une efficacité inégalées. Avec sa capacité à gérer des formats et des contextes divers, AnyParser permet aux organisations d'automatiser leurs flux de travail et de libérer tout le potentiel de leurs données.
Appel à l'action
Pourquoi attendre pour découvrir le prochain niveau de parsing de documents ? Débloquez tout le potentiel d'AnyParser en essayant ses fonctionnalités dans un environnement pratique !
Cliquez sur le lien ci-dessous pour entrer dans le Sandbox, où vous pouvez explorer comment il simplifie :
- La capture de données précises à partir de PDF et d'images.
- L'extraction fluide de tableaux pour l'intégration dans des outils d'analyse.
- Des performances fiables à travers des ensembles de données complexes et volumineux.
Découvrez AnyParser dans le Sandbox maintenant
Ne manquez pas l'occasion de voir comment AnyParser peut révolutionner vos flux de travail. Testez-le aujourd'hui et découvrez à quel point le parsing de documents et l'extraction de tableaux peuvent être simples !