Dans le domaine de la gestion des données, le parsing implique la conversion du contenu—tel que le texte, les images, les tableaux et les métadonnées—dans un format utilisable (par exemple, texte brut, données structurées ou images) qui peut être traité ou analysé ultérieurement. Cela est particulièrement évident dans le domaine du parsing PDF, un processus crucial qui transforme des informations brutes en données structurées et exploitables. Ce guide complet explore les subtilités du parsing PDF, en éclaircissant sa définition, le spectre des données qu'il peut extraire, les obstacles qu'il rencontre, ses applications multiples et la multitude de méthodes disponibles pour exploiter tout son potentiel. Vous découvrirez diverses méthodes de parsing, avec un accent particulier sur le parsing PDF et sur la façon dont des outils comme AnyParser se démarquent de la foule.
Comprendre le Parseur PDF : Qu'est-ce que le Parsing ?
Qu'est-ce que le parsing : un processus de capture de données méticuleux
Au cœur du sujet, le parsing PDF fait référence au processus d'extraction et d'interprétation des données à partir de fichiers PDF (Portable Document Format). Étant donné que les PDF sont principalement conçus pour l'affichage plutôt que pour le stockage de données structurées, le parsing implique la conversion du contenu—tel que le texte, les images, les tableaux et les métadonnées—dans un format utilisable (par exemple, texte brut, données structurées ou images) qui peut être traité ou analysé ultérieurement. Le parsing nécessite une analyse de haut niveau pour identifier et récupérer des éléments spécifiques au sein d'un PDF, s'étendant au-delà du simple texte et des images pour englober les polices, les mises en page, les tableaux et les métadonnées. Ce processus n'est pas seulement une question de technique, mais une nécessité dans des secteurs aussi divers que la finance, le droit, la logistique et la santé, où la réutilisation de l'information est primordiale.
Données pouvant être extraites des PDF
Les données extractibles des PDF sont variées et étendues, incluant :
-
Paragraphes de texte : Séquences de mots et de caractères.
-
Champs de données uniques : Éléments individuels tels que des dates, des numéros de suivi et des noms.
-
Données tabulaires : Informations organisées en tableaux et en listes.
-
Images : Contenu graphique intégré dans le PDF.
-
Éléments avancés : En-têtes, objets, tables de références croisées, bandes-annonces et métadonnées, qui nécessitent des outils de parsing plus sophistiqués.
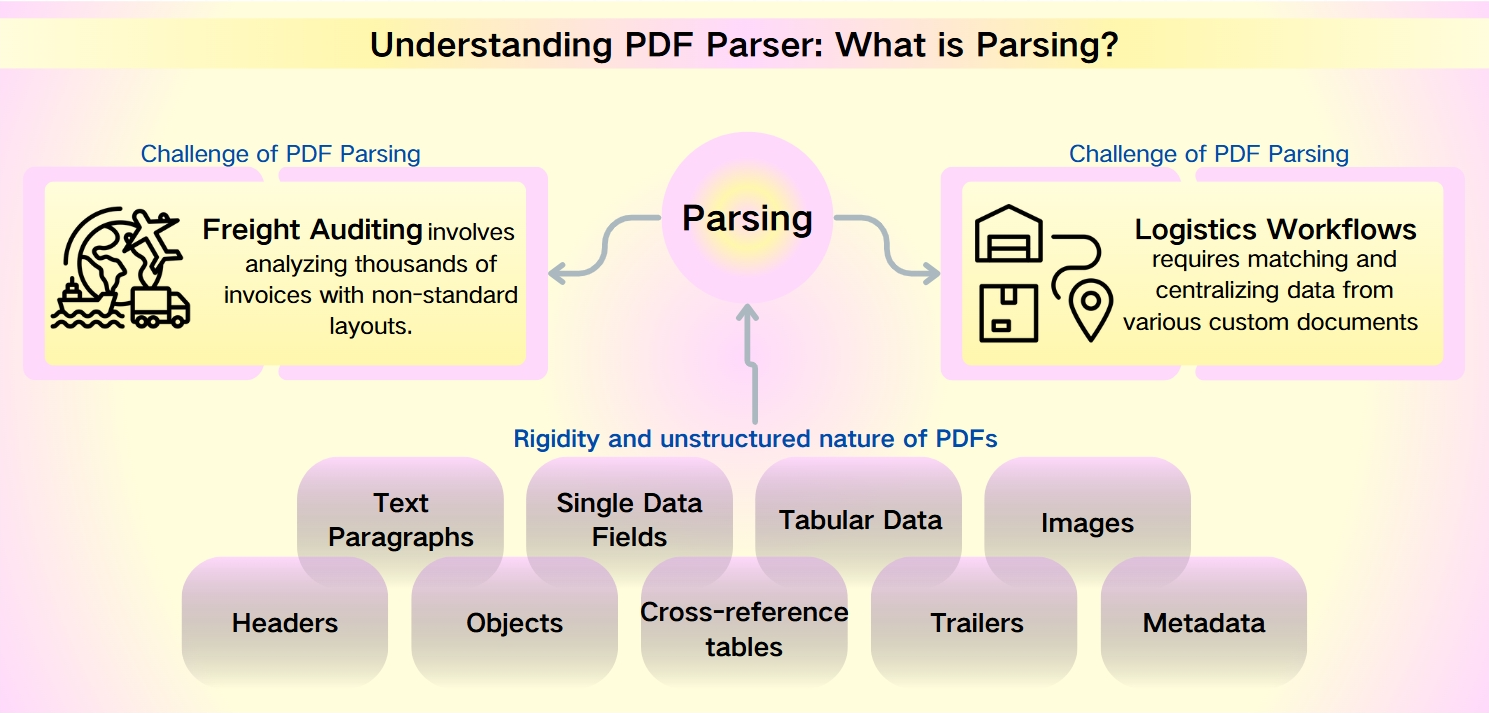
Défis du Parsing PDF : la nature non structurée des métadonnées PDF
Malgré la robustesse des PDF—caractérisés par leur sécurité, leur compatibilité avec les appareils et leur taille de fichier compacte—l'extraction de données à partir de ceux-ci pose un défi redoutable. La rigidité et la nature non structurée des PDF entravent l'analyse rapide et la récupération d'informations. Cela est particulièrement prononcé dans des scénarios tels que l'audit de fret et les flux de travail logistiques, où des mises en page non standard et des ensembles de données volumineux compliquent la complexité.
L'audit de fret implique l'analyse de milliers de factures avec des mises en page non standard. Les flux de travail logistiques nécessitent la correspondance et la centralisation des données provenant de divers documents personnalisés tels que des listes de colisage, des factures commerciales et des connaissements.
L'Importance du Parsing
Le parsing joue un rôle vital dans divers domaines, du développement web à la capture de données. Il permet aux entreprises d'extraire des informations précieuses à partir de sources de données non structurées, telles que des documents PDF, des fichiers HTML et des données XML. Le parsing facilite :
-
Une prise de décision améliorée grâce à des informations basées sur les données.
-
Une précision et une cohérence des données accrues.
-
Un traitement et une analyse des données rationalisés.
-
Une récupération et un stockage d'informations efficaces.
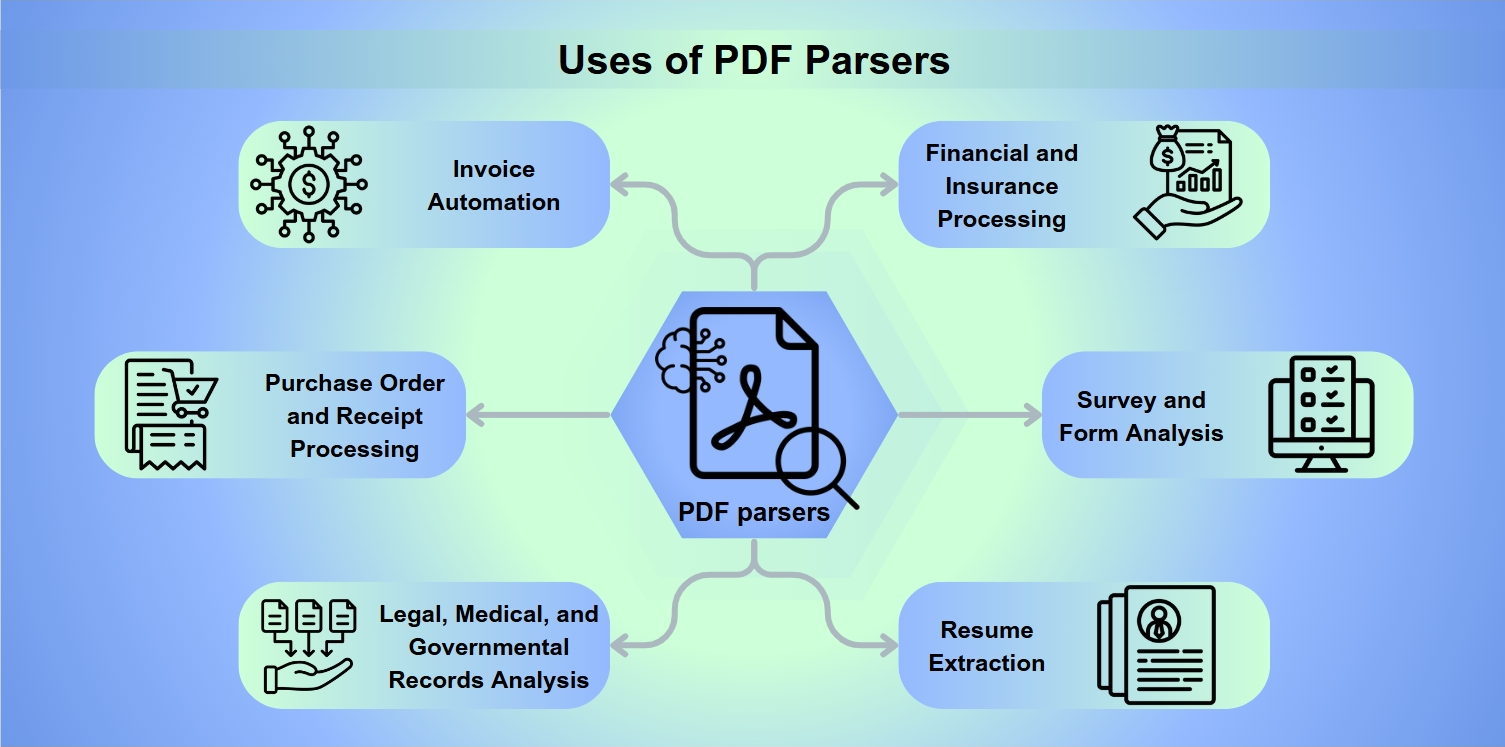
Utilisations des Parseurs PDF
Les parseurs PDF sont des outils indispensables dans un éventail d'applications, y compris :
-
Automatisation des factures : Rationalisation du traitement et du paiement des factures.
-
Traitement des commandes d'achat et des reçus : Facilitation des remboursements et des remboursements.
-
Analyse des dossiers juridiques, médicaux et gouvernementaux : Permettre une extraction de données approfondie pour l'analyse.
-
Traitement financier et d'assurance : Évaluation des risques et analyse des bilans.
-
Analyse des enquêtes et des formulaires : Collecte et interprétation des réponses aux formulaires.
-
Extraction de CV : Aider les recruteurs à présélectionner les candidats.
Comparaison des Différentes Méthodes de Parsing
Les méthodes de parsing de données ont évolué de manière significative au fil du temps. Les approches traditionnelles de capture de données reposent souvent sur des expressions régulières (regex) pour extraire des motifs spécifiques à partir de texte. Bien que puissantes, les regex peuvent devenir complexes et difficiles à maintenir pour des tâches de parsing délicates. Une autre technique courante est la manipulation de chaînes, qui consiste à diviser et à traiter le texte en fonction de délimiteurs ou de caractères spécifiques. Ces méthodes, bien qu'encore utiles dans certains scénarios, peuvent rencontrer des difficultés avec des formats de données non structurés ou incohérents.
Le paysage du parsing PDF est desservi par une variété de méthodes, chacune avec ses propres mérites et inconvénients :
-
Convertisseurs/Parseurs PDF en ligne : Tels que Zamzar et Smallpdf, offrent commodité et rapidité mais sont limités en fonctionnalités et potentiellement peu sécurisés.
-
Adobe Acrobat : Préserve la structure et le format mais peut nécessiter des ajustements manuels après la conversion.
-
Copier et Coller : Offre un contrôle total mais est laborieux et sujet aux erreurs.
-
Plateformes automatisées : Les technologies de parsing modernes telles qu'AnyParser tirent parti de l'apprentissage automatique et du traitement du langage naturel (NLP) pour gérer des structures de données plus complexes.
Ces approches pilotées par l'IA peuvent comprendre le contexte et la sémantique, les rendant particulièrement efficaces pour le parsing de texte non structuré ou de documents avec des formats variés. Certains parseurs avancés utilisent des modèles d'apprentissage profond pour identifier et extraire des informations pertinentes avec une grande précision, même à partir de mises en page de documents jamais vues auparavant.
Comment Effectuer le Parsing PDF : Le Meilleur Parseur PDF Gratuit pour Extraire les Métadonnées PDF
Comprendre les Métadonnées PDF
Les métadonnées PDF contiennent des informations cruciales sur un document, y compris son titre, son auteur, sa date de création et ses mots-clés. L'extraction efficace de ces métadonnées est essentielle pour organiser, rechercher et gérer de grandes collections de fichiers PDF. Un parseur PDF robuste peut rationaliser ce processus, économisant du temps et améliorant la productivité du flux de travail.
Caractéristiques Clés des Meilleurs Parseurs PDF
Les meilleurs parseurs PDF gratuits offrent une combinaison de précision, de rapidité et de polyvalence. Ils doivent être capables de gérer divers formats PDF, y compris les documents numérisés et ceux avec des mises en page complexes. Recherchez des parseurs capables d'extraire non seulement des métadonnées de base, mais aussi des champs personnalisés et des informations cachées. De plus, les parseurs de premier ordre offrent souvent des options pour l'extraction de données PDF pour le traitement par lots et l'intégration avec d'autres systèmes logiciels.
Caractéristiques d'AnyParser
AnyParser, développé par CambioML, est particulièrement remarquable en raison de sa précision, de sa confidentialité et de sa configurabilité. La capacité d'AnyParser à gérer plusieurs formats de fichiers, son interface conviviale et sa scalabilité en font un excellent choix pour les entreprises de toutes tailles. De plus, son API permet une intégration transparente dans les flux de travail existants, améliorant l'efficacité globale de la gestion des documents. Voici quelques-unes des caractéristiques clés qui font d'AnyParser un excellent choix pour le parsing PDF :
-
Précision : AnyParser est conçu pour extraire avec précision le texte, les chiffres et les symboles tout en maintenant la mise en page et le format d'origine. Il utilise des modèles linguistiques avancés pour améliorer la compréhension des documents et l'extraction d'informations, affichant jusqu'à 2 fois un taux de précision supérieur par rapport aux modèles OCR traditionnels.
-
Confidentialité : Il prend en charge le parsing de données à la fois sur site et dans le cloud, garantissant que les informations sensibles restent privées et sécurisées.
-
Configurabilité : Les utilisateurs peuvent personnaliser les règles d'extraction et les formats de sortie pour répondre à des besoins spécifiques.
-
Support multi-sources : AnyParser prend en charge une variété de types de documents, y compris les PDF, les images et les graphiques.
-
Sortie structurée : Les informations extraites peuvent être converties en formats structurés tels que Markdown, Excel ou JSON, facilitant un traitement et une analyse ultérieurs.
-
Options de déploiement basées sur le cloud : Le SDK d'AnyParser peut être déployé dans le cloud, dans des centres de données ou de manière privée, offrant flexibilité et scalabilité.
-
Interface conviviale : L'outil propose une API simple qui permet d'accomplir des tâches de parsing de documents complexes en quelques lignes de code.
-
Haute performance : Des algorithmes optimisés garantissent un traitement rapide d'un grand nombre de documents, 5 fois plus rapide que les LLM généralisés comme GPT-4.
-
Soutien communautaire : En tant que projet open-source, AnyParser bénéficie d'une communauté active et accueille les contributions.
-
Quota d'utilisation gratuit : AnyParser propose un quota d'utilisation gratuit avec chaque compte, permettant aux utilisateurs de tester les capacités de l'outil avant de s'engager dans un plan payant.
-
Retour d'expérience des clients : Les utilisateurs ont loué AnyParser pour sa haute précision, la préservation de la confidentialité et son efficacité dans l'extraction de données, avec des études de cas montrant des économies de temps significatives et une amélioration de la qualité des données.
Ces avantages font d'AnyParser un précieux extracteur de données PDF pour le parsing de documents et l'extraction d'informations, en particulier pour les utilisateurs d'entreprise qui nécessitent une haute précision et sécurité. Avec les avancées technologiques continues et l'engagement actif de la communauté, AnyParser est bien positionné pour jouer un rôle de plus en plus vital dans le domaine du parsing de documents et de l'extraction d'informations.
Explication Technique des Parseurs PDF
Le parsing PDF partage un terrain conceptuel avec le web scraping, mais il manque de la hiérarchie structurée de l'HTML. Alors que les documents web sont analysés à travers des balises HTML accessibles, les PDF présentent un tableau plat de caractères et de pixels, nécessitant des algorithmes et des bibliothèques plus sophistiqués pour l'extraction de données.
Parseur PDF vs Parseur PDF Python : Différences Clés
Un parseur PDF est souvent un outil autonome en tant qu'extracteur de données PDF ou bibliothèque conçu spécifiquement pour extraire des données à partir de fichiers PDF. Ces parseurs offrent généralement des interfaces conviviales et nécessitent peu de connaissances en programmation. En revanche, les parseurs PDF Python sont des modules ou des bibliothèques qui s'intègrent dans des scripts Python, offrant plus de flexibilité mais nécessitant une expertise en programmation.
Les développeurs peuvent affiner le processus de parsing, mettre en œuvre une analyse de texte avancée et intégrer sans effort l'extraction de données PDF dans des applications Python plus larges. Les parseurs PDF, bien que plus limités en personnalisation que les parseurs PDF Python, offrent souvent des fonctionnalités préconstruites pour des cas d'utilisation courants, les rendant idéaux pour les utilisateurs qui ont besoin de résultats rapides sans programmation extensive.
Avantages d'AnyParser avec VLM pour le Parsing de Données
-
Haute Précision : Les VLM d'AnyParser garantissent que l'extraction de données maintient une haute fidélité, même avec des mises en page de documents complexes.
-
Vitesse : Il est leader en termes de vitesse de conversion, améliorant la productivité en réduisant le temps nécessaire pour traiter les documents.
-
Convivialité : AnyParser propose une interface simple, la rendant accessible aux utilisateurs de tous niveaux.
-
Polyvalence : Au-delà des PDF, AnyParser sert de puissant convertisseur d'images en Excel, prenant en charge divers types de documents.
Conclusion
Le parsing PDF est plus qu'un simple processus technique ; c'est une porte d'entrée pour transformer la manière dont les entreprises gèrent les données. Malgré les défis, l'évolution des solutions logicielles a rendu cela plus accessible que jamais. Que vous traitiez des factures ou une analyse de données complexe, choisir le bon parseur PDF est essentiel. Il s'agit de trouver l'outil qui offre le parfait équilibre entre précision, sécurité et efficacité pour renforcer vos initiatives basées sur les données.
Commencez Votre Essai Gratuit Aujourd'hui
Prêt à révolutionner votre traitement de documents ? Essayez AnyParser GRATUITEMENT sans carte de crédit requise à https://www.cambioml.com/sandbox. L'essai gratuit vous permet de traiter jusqu'à 10 pages par document, avec une taille de fichier maximale de 10 Mo. Découvrez par vous-même comment le parseur PDF d'AnyParser peut transformer votre approche des données non structurées et de l'extraction de documents. Ne manquez pas cette opportunité d'améliorer vos capacités d'analyse de données et de rationaliser votre flux de travail avec une technologie IA de pointe.