 Métriques d'évaluation de Ragas
Métriques d'évaluation de Ragas
Dans le paysage axé sur les données d'aujourd'hui, des secteurs comme les services financiers dépendent fortement d'une extraction d'informations précise et efficace à partir de documents, en particulier ceux contenant à la fois du texte non structuré et des données structurées comme des tableaux et des graphiques. Les modèles de reconnaissance optique de caractères (OCR) traditionnels, malgré leur utilisation répandue, peinent souvent à gérer des formats de documents complexes, entraînant des performances sous-optimales dans les applications d'IA avancées. Reconnaissant cette lacune, CambioML et Epsilla ont introduit un système de récupération de connaissances de pointe qui promet d'améliorer considérablement la précision et le rappel dans les tâches d'extraction de données.
Introduction : Surmonter les limitations de l'OCR
Les modèles basés sur l'OCR, bien qu'efficaces pour détecter du texte, ont du mal à extraire des informations de mise en page et à extraire avec précision des données à partir de tableaux et de graphiques. Ces limitations deviennent particulièrement évidentes dans les secteurs où la précision est primordiale, comme la finance et la santé. Pour relever ces défis, CambioML et Epsilla ont développé une approche novatrice qui intègre des modèles d'extraction de tableaux à la pointe de la technologie avec des techniques de génération augmentée par récupération (RAG). Ce nouveau système atteint jusqu'à 2x de précision et 2,5x de rappel par rapport aux systèmes RAG conventionnels, établissant une nouvelle norme pour le questionnement de documents.
AnyParser : Révolutionner l'extraction de tableaux
Au cœur de cette avancée se trouve AnyParser, un modèle alimenté par des modèles de langage visuel avancés (VLM) qui excelle dans l'extraction d'informations à partir de diverses sources de données. Contrairement aux modèles traditionnels qui s'appuient fortement sur l'OCR, AnyParser utilise une combinaison d'encodeurs visuels et textuels pour capturer même les plus petits détails des documents, garantissant qu'aucune donnée critique ne soit manquée. Cette approche est particulièrement bénéfique pour l'extraction de données haute résolution à partir de documents financiers et médicaux, où la précision est essentielle.
Epsilla : Une plateforme RAG flexible
Complétant AnyParser, Epsilla est une plateforme RAG-as-a-Service sans code conçue pour optimiser divers pipelines RAG. Epsilla améliore le processus de récupération de connaissances grâce à des techniques avancées de découpage, d'indexation et de raffinement des requêtes. En intégrant des méthodes de recherche basées sur des mots-clés et sémantiques, Epsilla fournit des résultats hautement précis et contextuellement pertinents, en faisant une solution idéale pour les applications de modèles de langage de grande taille (LLM).
Expérience et évaluation : Impact dans le monde réel
Métriques d'évaluation de Ragas
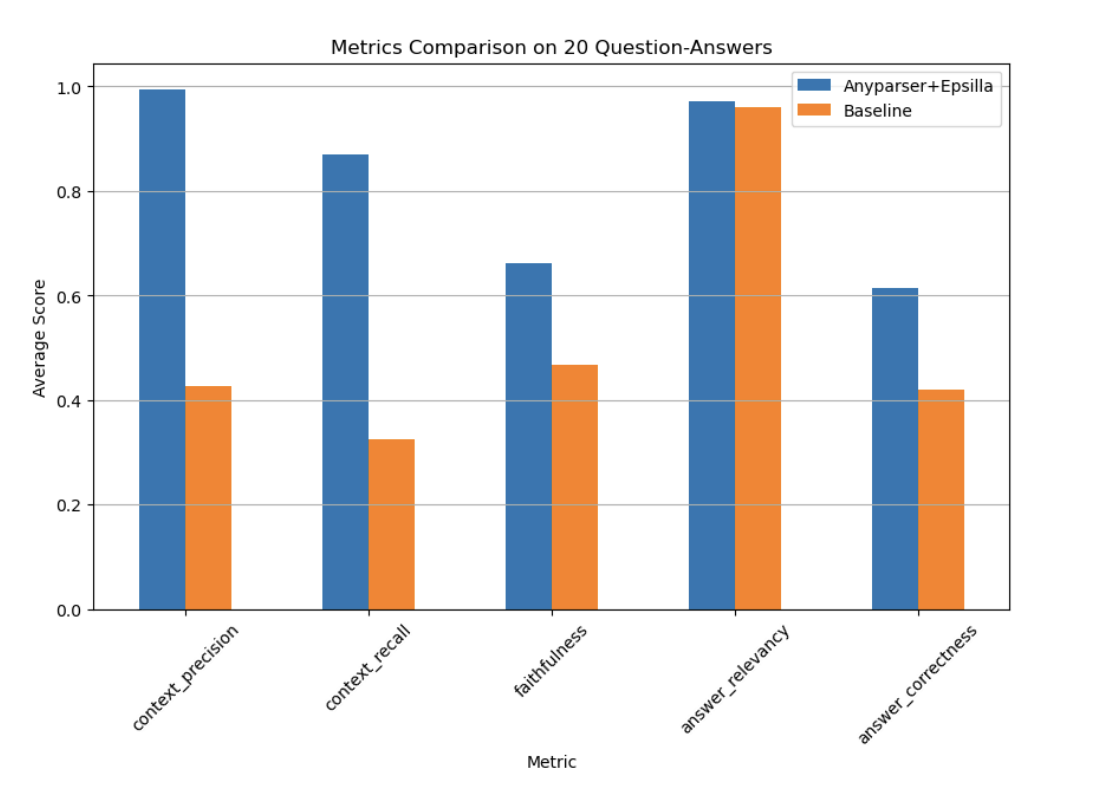
Pour valider l'efficacité d'AnyParser et d'Epsilla, le système a été testé sur des documents financiers 10-K d'entreprises comme Apple et Meta. Les résultats étaient impressionnants, le système démontrant des performances significativement plus élevées sur tous les indicateurs d'évaluation clés, y compris la précision contextuelle, le rappel, la fidélité et la justesse des réponses. Dans certains cas, le système a surpassé les systèmes RAG traditionnels de jusqu'à 2,7x, soulignant sa supériorité dans la gestion des tâches complexes d'extraction de données.
Cas d'utilisation courants et avantages clés
-
Précision : Haute précision dans la conversion des données structurées et non structurées en formats exploitables.
-
Confidentialité : La possibilité de déployer le système au sein du centre de données d'un client garantit la sécurité totale des données.
-
Scalabilité : Traitement rapide de grands volumes de documents, permettant une prise de décision plus rapide.
Conclusion : Une nouvelle ère dans la récupération de connaissances
L'introduction d'AnyParser et d'Epsilla marque une avancée significative dans la technologie de récupération de connaissances. En combinant des modèles d'extraction avancés avec une infrastructure RAG robuste, cette solution intégrée améliore non seulement la précision et l'efficacité, mais offre également la flexibilité et la confidentialité que les entreprises modernes exigent. À mesure que la technologie continue d'évoluer, les applications et les avantages de ce système sont vastes et prometteurs, en faisant un véritable changement de donne pour les secteurs qui dépendent d'une extraction de données précise.
Pour le document complet, veuillez consulter ce lien.