La conversion de PDF complexes en Markdown peut être un défi. Il existe de nombreuses bibliothèques open-source disponibles pour extraire du texte à partir de PDF, mais lorsqu'il s'agit de PDF contenant des éléments complexes comme des tableaux et des graphiques, les résultats sont souvent décevants. Des modèles de langage de grande taille populaires comme GPT ou Claude peuvent gérer ces tâches, mais tendent à être lents et produisent parfois des résultats inexacts. Les outils OCR traditionnels, bien qu'efficaces pour des documents plus simples, ont souvent du mal à maintenir la structure exacte et le sens sémantique du contenu original. D'autre part, les modèles de langage visuel peuvent parfois halluciner, entraînant des résultats de parsing erronés. Ce blog expliquera ce que signifie le parsing et détaillera les résultats d'une analyse comparative de plusieurs modèles utilisant plusieurs métriques.
Que signifie le parsing ?
Dans le contexte du parsing PDF, "parser" fait référence au processus d'extraction de données spécifiques d'un fichier PDF à l'aide d'un logiciel spécialisé connu sous le nom de parser PDF. Un parser PDF analyse le contenu d'un document PDF et identifie des éléments tels que le texte, les images, les polices, les mises en page et même les métadonnées. Les données extraites peuvent ensuite être organisées et exportées dans différents formats comme XML, JSON ou Excel/CSV, qui peuvent être utilisés à diverses fins telles que l'analyse de données, la tenue de dossiers ou l'automatisation des flux de travail.
Comprendre ce que signifie le parsing est essentiel pour évaluer l'efficacité d'une solution de parsing, surtout lors de la comparaison de différents outils de conversion PDF en Markdown, car le parser PDF implique plus qu'une simple extraction de texte : il nécessite de reconnaître et de maintenir la structure sémantique du document.
Comment mesurons-nous la qualité de ces solutions de parsing ?
Nous avons défini une série de métriques au niveau des mots pour évaluer la performance de différents modèles, en nous concentrant sur des facteurs clés tels que :
-
Précision, Rappel et F-Mesure : Évaluation de la qualité et de l'exhaustivité du parsing.
-
Score BLEU et ANLS : Utiles pour évaluer la langue et la structure de mise en page.
-
Distance d'Édition, Divergence de Jensen-Shannon et Distance de Jaccard : Métriques spécifiques au domaine de l'OCR, particulièrement utiles pour comprendre la précision de la reproduction du contenu.
Notre modèle de langage visuel, AnyParser, démontre une performance exceptionnelle, alliant rapidité et précision, surtout sur des mises en page complexes avec des tableaux et des éléments sémantiques. AnyParser surpasse les autres solutions, offrant une amélioration de vitesse de 20x par rapport à des modèles comme GPT/Claude tout en atteignant une précision supérieure.
Un résultat de comparaison approfondie contre les principaux modèles de parsing
Objet statistique
Pour vraiment mettre en valeur les capacités d'AnyParser, nous avons réalisé une comparaison approfondie contre les principaux modèles de parsing de l'industrie et des modèles de langage de grande taille (LLMs) bien connus. Notre évaluation a inclus :
1. Modèles de Langage de Grande Taille
- AnyParser
- GPT-4o d'OpenAI
- Gemini 1.5 Pro de Google
- Claude 3.5 Sonnet d'Anthropic
2. Services Basés sur l'OCR
- LlamaParse
- Amazon Textract
- Google Cloud Document AI
- Azure Document Intelligence
Présentation et analyse des résultats
Expérience 1
Tout d'abord, nous avons mené une série de comparaisons rigoureuses de la performance de différents modèles d'IA documentaires sur plus de 5 métriques ci-dessous : BLEU, Précision et rappel, F-Mesure et ANLS. Vous pouvez trouver la définition mathématique de ces métriques dans l'annexe.
Les modèles comparés sont : AnyParser-base, AnyParser-pro, Textract, Llama-Parse, GPT4o, Gemini-1.5-pro, GCP-DocAI et Azure-DocAI.
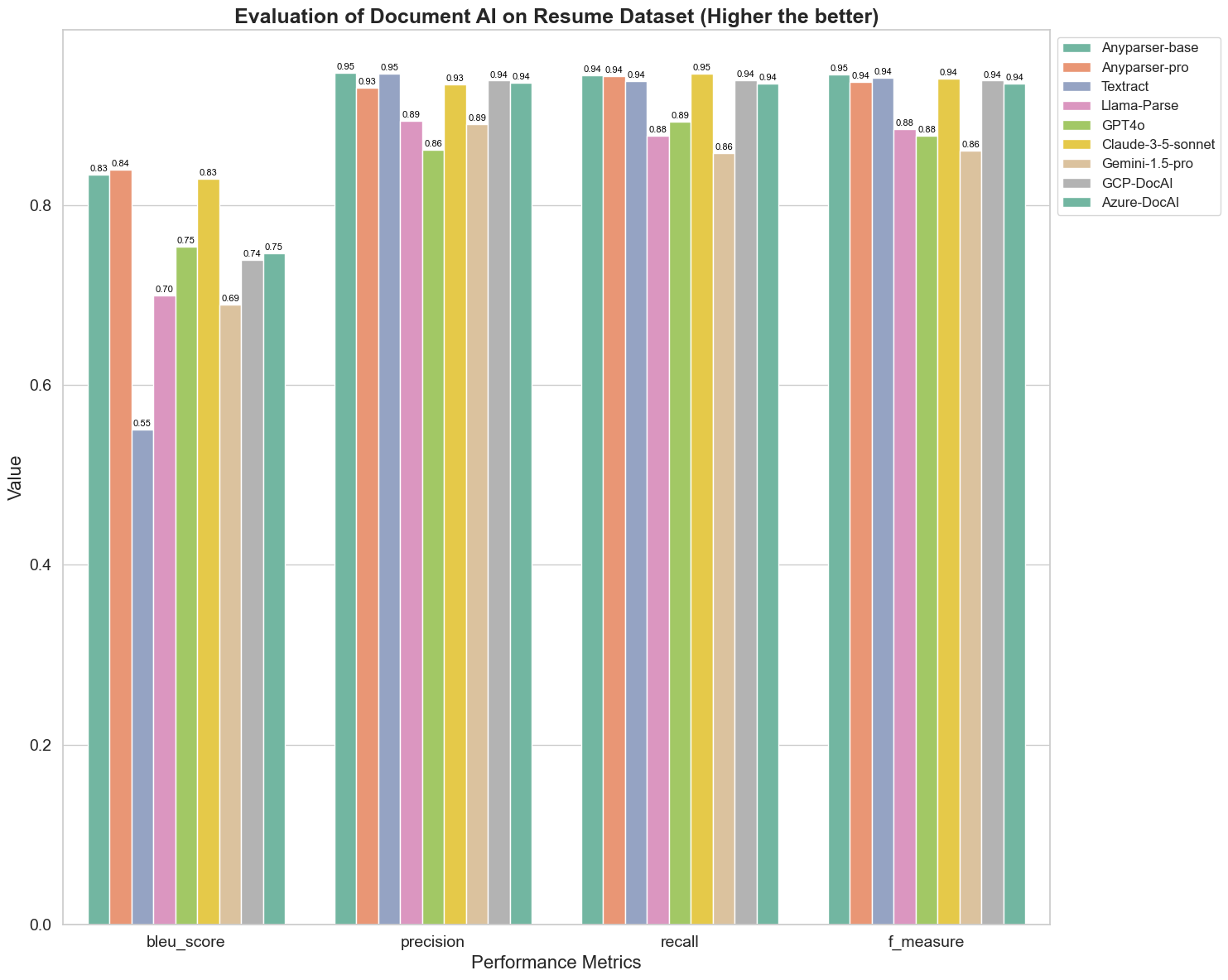
Le score BLEU est utilisé comme évaluation de la qualité de l'interprétation bilingue pour tester la qualité des modèles dans le traitement des énoncés. En comparant les résultats de ces modèles de parsing selon la méthode d'évaluation BLEU, nous constatons que : les scores d'AnyParser-base et d'AnyParser-pro sont significativement plus élevés que ceux des autres modèles, Amazon Textract obtient le score le plus bas, et les résultats des autres modèles se situent à un niveau relativement moyen.
La précision de reconnaissance est généralement représentée par la précision et le rappel, où la précision représente le pourcentage de résultats réellement corrects parmi les résultats jugés corrects par le modèle, et le rappel représente le pourcentage de résultats réellement jugés corrects par le modèle parmi tous les résultats réellement corrects. En comparant la précision et le rappel de ces modèles de parsing, nous constatons que : à l'exception de Llama-Parse, GPT4o et Gemini-1.5-pro, tous les autres modèles sont à un niveau élevé. Parmi eux, AnyParser et Amazon Textract se distinguent davantage en précision, et AnyParser-base et AnyParser-pro se distinguent davantage en rappel. Un score plus élevé du modèle en précision indique que le modèle produit plus d'informations correctes dans les résultats de production, et un score plus élevé en rappel indique que le modèle est plus capable d'obtenir des informations correctes à partir de l'échantillon. Les résultats des scores montrent qu'AnyParser a un avantage clair en termes de précision de reconnaissance pour extraire du texte à partir de PDF.
La F-Mesure est un indice d'évaluation complet de la précision et du rappel sur ces deux indicateurs. En comparant les scores de ces modèles de parsing selon la F-Mesure, nous pouvons voir plus intuitivement que les cinq modèles, AnyParser-base, AnyParser-pro, Amazon Textract, GCP-DocAI et Azure-DocAI, ont une meilleure force en termes de précision de reconnaissance par rapport aux autres modèles. Nous pouvons voir plus intuitivement que les cinq modèles ont plus de force en précision de reconnaissance que les autres modèles, et AnyParser a le score le plus élevé selon la F-Mesure, ce qui illustre davantage l'avantage évident d'AnyParser en précision de reconnaissance pour extraire du texte à partir de PDF.
L'ANLS, en tant qu'indice d'évaluation couramment utilisé pour mesurer la précision et la similarité entre le texte original et le texte cible au niveau des caractères, est également très informatif pour mesurer le niveau de parsing des modèles. Les scores plus élevés d'AnyParser-base, AnyParser-pro et Azure-DocAI reflètent le niveau de parsing plus élevé de ces modèles par rapport aux autres modèles.
Dans l'ensemble, AnyParser-base et AnyParser-pro surpassent les autres modèles.
Expérience 2
Nous comparons également la performance de différents modèles d'IA documentaires sur trois métriques différentes : Distance d'Édition, Divergence de Jensen-Shannon et Distance de Jaccard. Les métriques sont utilisées pour mesurer la similarité entre la sortie des modèles et un document de référence. Des valeurs plus basses indiquent une meilleure performance.
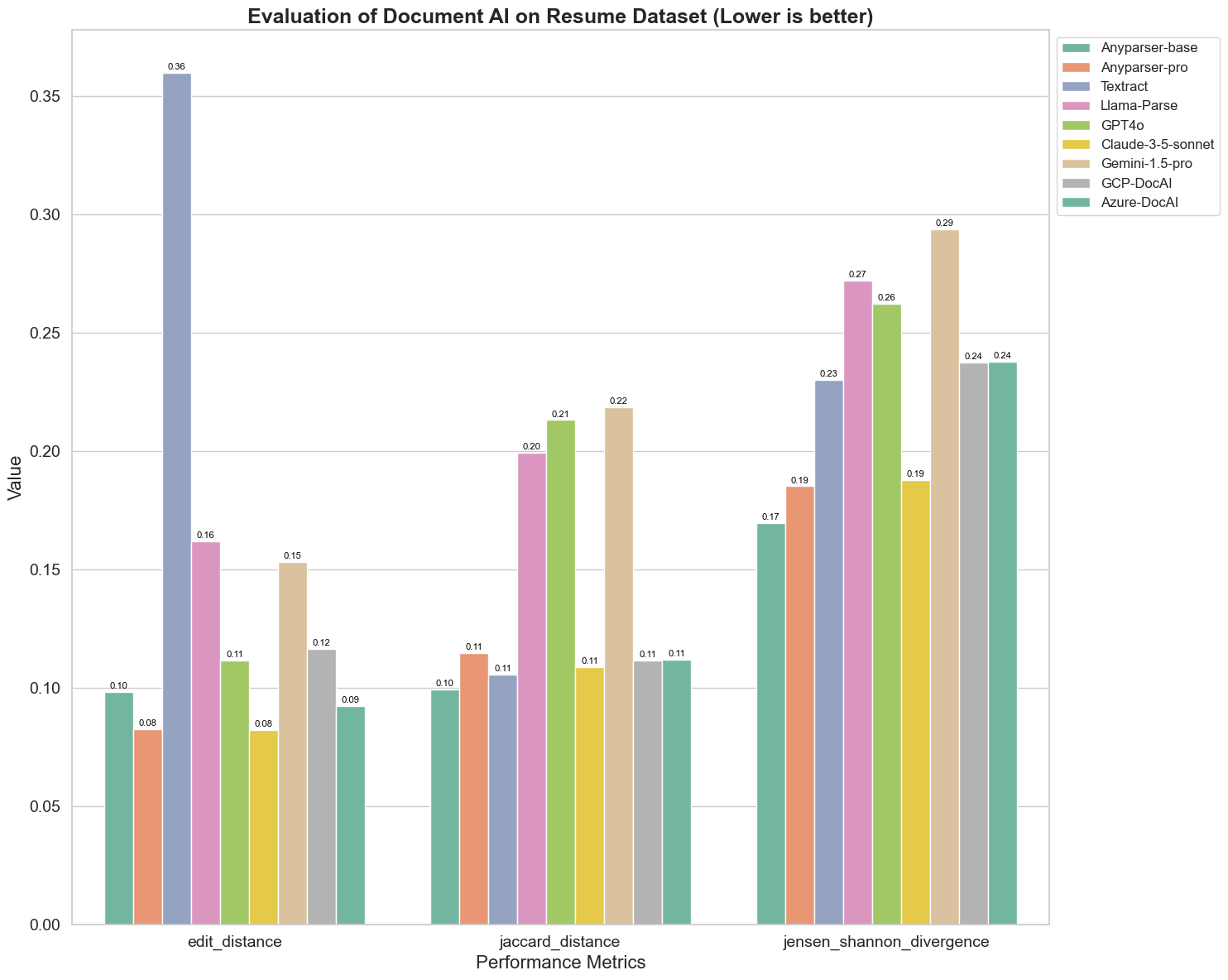
Voici quelques observations clés du graphique :
-
Distance d'Édition : Les modèles AnyParser-base et AnyParser-pro obtiennent les meilleurs résultats avec la distance d'édition la plus basse, suggérant que leur sortie était la plus proche du document de référence.
-
Divergence de Jensen-Shannon : Les modèles AnyParser-base et AnyParser-pro ont la plus faible divergence, impliquant que leurs sorties sont les plus similaires au document de référence en termes de distribution des mots.
-
Distance de Jaccard : Au-delà de Llama-parse, GPT4O, Gemini-1.5, tous les autres modèles obtiennent des résultats décents avec la plus basse distance de Jaccard, indiquant que leur sortie a le plus grand chevauchement avec le document de référence en termes d'ensemble de mots utilisés.
Conclusion
Dans l'ensemble, nos tests rigoureux suggèrent qu'AnyParser-base et AnyParser-pro fonctionnent généralement bien sur diverses métriques, indiquant son potentiel pour un traitement précis des documents. D'après les graphiques, nous pouvons voir que les modèles OCR traditionnels tels que le célèbre Amazon Textract obtiennent des scores beaucoup plus bas que les modèles de langage visuel. Cependant, la performance des différents modèles varie en fonction de la métrique utilisée, soulignant l'importance de considérer plusieurs critères d'évaluation lors de la comparaison des modèles d'IA.
Présentation de notre pipeline d'évaluation open-source
Pour rationaliser les évaluations, nous avons créé un pipeline d'évaluation qui fournit une méthode standard de l'industrie pour comparer les modèles de parsing. Dans notre exemple, nous démontrons son utilisation dans le domaine des ressources humaines, où le parsing de CV est courant. Nous avons construit un ensemble de données synthétiques diversifié de 128 CV, généré à l'aide de fichiers image-Markdown appariés. En utilisant GPT-4, nous avons généré du contenu HTML, l'avons rendu en images et utilisé le texte extrait comme vérité de base pour la comparaison.
Et voici le meilleur : nous avons open-sourcé ce cadre d'évaluation sur GitHub ! Que vous soyez développeur ou utilisateur professionnel, notre pipeline vous permet d'évaluer et de comparer la qualité de parsing de différents modèles sur votre propre ensemble de données.
Trouvez le guide de démarrage rapide dans le repo Github et voyez comment différents modèles de parsing se comparent les uns aux autres. Nous croyons qu'en mettant en avant la force de notre modèle de manière ouverte, nous pouvons attirer plus d'utilisateurs souhaitant des capacités de parsing fiables, rapides et précises.
Annexe - Métriques
1. Précision
La précision mesure l'exactitude du contenu analysé, montrant combien des éléments récupérés étaient corrects. Dans le parsing, c'est la proportion de mots correctement extraits parmi tous les mots extraits.
Précision = Vrais Positifs (TP) / (Vrais Positifs (TP) + Faux Positifs (FP))
- Vrais Positifs (TP) : Mots correctement identifiés par le parser.
- Faux Positifs (FP) : Mots incorrectement identifiés par le parser.
2. Rappel
Le rappel indique l'exhaustivité du parsing, ou combien de mots pertinents du document original ont été récupérés.
Rappel = Vrais Positifs (TP) / (Vrais Positifs (TP) + Faux Négatifs (FN))
- Faux Négatifs (FN) : Mots dans le document original qui ont été manqués par le parser.
3. F-Mesure (Score F1)
Le Score F1 est la moyenne harmonique de la Précision et du Rappel, équilibrant les deux métriques pour donner une mesure globale de la qualité du parsing.
Score F1 = 2 × (Précision × Rappel) / (Précision + Rappel)
4. Score BLEU (Bilingual Evaluation Understudy)
Le score BLEU mesure la similarité entre le contenu analysé et le texte original, en mettant un accent particulier sur l'ordre des mots. Il est particulièrement utile pour évaluer la consistance de la langue et de la structure dans les documents analysés, car il pénalise les sorties qui diffèrent de la séquence originale.
5. ANLS (Similarité de Levenshtein Normalisée Moyenne)
L'ANLS quantifie la similarité entre le contenu analysé et l'original, en utilisant la distance d'édition normalisée. Elle est calculée en moyennant la Similarité de Levenshtein Normalisée (NLS) pour chaque paire de mots dans les textes analysés et de référence. La NLS est calculée comme suit :
NLS = 1 - (Distance de Levenshtein (LD)(mot analysé, mot original)) / max(Longueur du mot analysé, Longueur du mot original)
Ensuite, l'ANLS est la moyenne de la NLS sur toutes les paires de mots :
ANLS = (1/N) × Σ(NLS_i) pour i=1 à N
6. Distance d'Édition
La Distance d'Édition calcule le nombre d'opérations au niveau des mots (insertions, suppressions, substitutions) nécessaires pour convertir le texte analysé en l'original.
7. Divergence de Jensen-Shannon
La Divergence de Jensen-Shannon mesure la similarité entre les distributions de probabilité discrètes des comptes de mots analysés et originaux, mettant en évidence les différences de fréquence des mots.
JSD(P || Q) = (1/2) × KL(P || M) + (1/2) × KL(Q || M)
où M = (1/2)(P + Q), et KL(P || Q) est la divergence de Kullback-Leibler
8. Distance de Jaccard
La Distance de Jaccard mesure la dissimilarité entre les ensembles de mots dans le contenu analysé et original, utile pour évaluer le chevauchement des mots.
Distance de Jaccard = 1 - |A ∩ B| / |A ∪ B|
où |A ∩ B| est le nombre d'éléments communs entre A et B,
et |A ∪ B| est le nombre total d'éléments uniques dans les deux ensembles.