Les modèles de langage visuel (VLM) révolutionnent le domaine de l'analyse de documents, en s'attaquant à de nombreuses limitations inhérentes aux systèmes traditionnels de reconnaissance optique de caractères (OCR). Bien que l'OCR ait été une technologie clé pour la numérisation de textes à partir d'images, elle fait face à des défis significatifs dans des scénarios complexes. Ceux-ci incluent des problèmes de précision avec des images de mauvaise qualité, une compréhension contextuelle limitée, des difficultés avec des langues mélangées et l'incapacité d'interpréter des éléments visuels. Les VLM offrent une solution prometteuse en combinant une vision par ordinateur avancée avec des capacités de traitement du langage naturel. Cet article explore comment les VLM surmontent les lacunes de l'OCR, fournissant des solutions plus robustes et polyvalentes pour le traitement de documents à l'ère numérique.
Qu'est-ce que l'OCR ? Quels sont les processus de l'OCR dans l'analyse de documents ?
La reconnaissance optique de caractères (OCR) est une technologie qui permet la conversion de différents types de documents, tels que des documents papier numérisés, des fichiers PDF ou des images capturées par un appareil photo numérique, en données modifiables et consultables. Ce processus est crucial dans le traitement de documents et l'extraction de données PDF, permettant aux machines de reconnaître des caractères de texte imprimé ou manuscrit à l'intérieur d'images numériques.
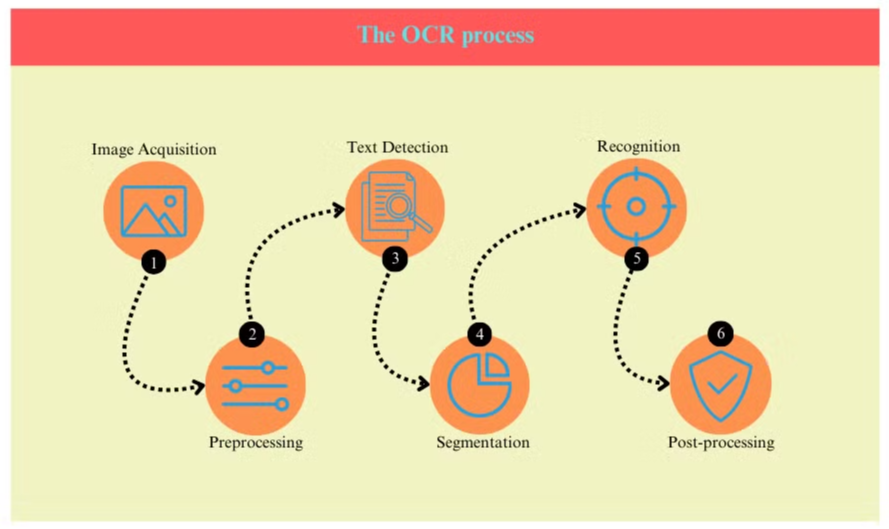
Le Processus OCR
Le processus OCR implique généralement plusieurs étapes :
- Acquisition d'image : Le document est scanné ou photographié pour créer une image numérique.
- Prétraitement : L'image est nettoyée, en supprimant le bruit et en ajustant la luminosité et le contraste.
- Détection de texte : Le système identifie les zones contenant du texte dans l'image.
- Segmentation des caractères : Les caractères individuels sont isolés dans les zones de texte.
- Reconnaissance des caractères : Chaque caractère est analysé et comparé à une base de données de caractères connus.
- Post-traitement : Le texte reconnu est vérifié pour des erreurs en utilisant des informations linguistiques et contextuelles.
Bien que l'OCR ait considérablement amélioré les capacités d'analyse de documents, elle fait encore face à des limitations dans la gestion de mises en page complexes, d'images de mauvaise qualité et de polices variées. C'est là que des technologies avancées comme les modèles de langage visuel interviennent pour améliorer la précision et la compréhension dans l'extraction de données à partir d'images et de documents.
Les Limitations de la Technologie OCR Traditionnelle
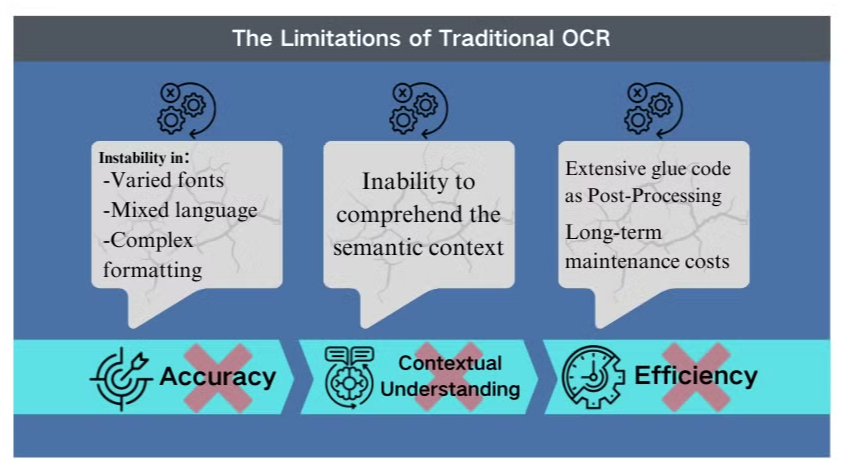
Défis de Précision dans des Scénarios Complexes
La technologie de reconnaissance optique de caractères (OCR) traditionnelle, bien que bénéfique pour l'extraction de texte de base, fait face à des obstacles significatifs lorsqu'elle est confrontée à des mises en page de documents complexes ou à des images de mauvaise qualité. Ces systèmes ont souvent du mal à maintenir la précision lors du traitement de documents avec des polices variées, des langues mélangées ou un formatage complexe. Par exemple, l'OCR peut échouer lorsqu'il s'agit d'extraire des données de présentations riches en images ou de PDF au formatage dense.
Manque de Compréhension Contextuelle
Une des limitations les plus évidentes de l'OCR conventionnelle est son incapacité à comprendre le contexte sémantique du texte qu'elle traite. Ce défaut devient particulièrement évident dans des scénarios nécessitant une interprétation nuancée, tels que des contrats juridiques ou des rapports médicaux. L'accent mis par l'OCR sur la reconnaissance des caractères sans conscience contextuelle peut conduire à des interprétations critiques erronées, surtout lorsqu'il s'agit de caractères ambigus ou de terminologie spécifique à un secteur.
Inefficacités dans le Post-Traitement
Les limitations de l'OCR nécessitent souvent des efforts de post-traitement étendus. Cette étape supplémentaire peut considérablement augmenter le temps et les ressources nécessaires au traitement des documents. De plus, les systèmes OCR traditionnels sont généralement insuffisants lorsqu'il s'agit d'extraire des informations de graphiques, de tableaux ou d'autres éléments non textuels, compliquant encore le processus d'extraction de documents. Ces inefficacités soulignent la nécessité de solutions plus avancées, telles que les modèles de langage visuel, qui offrent une approche plus complète de l'analyse de documents et de l'extraction de données.
Qu'est-ce que les Modèles de Langage Visuel et comment améliorent-ils l'OCR
Les modèles de langage visuel représentent un bond en avant significatif dans la technologie de traitement de documents, s'attaquant à de nombreuses limitations inhérentes aux systèmes traditionnels de reconnaissance optique de caractères (OCR). Ces modèles avancés combinent la vision par ordinateur avec le traitement du langage naturel pour comprendre simultanément les éléments visuels et textuels des documents.
Précision Améliorée et Compréhension Contextuelle
Contrairement à l'OCR, qui a du mal avec des images de mauvaise qualité et des mises en page complexes, les modèles de langage visuel excellent dans l'interprétation de divers formats de documents. Ils peuvent extraire avec précision des données à partir d'images, de PDF et d'autres contenus visuels, même lorsqu'ils sont confrontés à des scénarios difficiles. Cette précision améliorée découle de leur capacité à considérer l'ensemble du contexte d'un document, plutôt que de se concentrer uniquement sur des caractères ou des mots individuels.
Extraction de Données Complète
Les modèles de langage visuel vont au-delà de la simple reconnaissance de texte, offrant des capacités complètes d'extraction de données PDF. Ils peuvent identifier et interpréter des tableaux, des graphiques et des figures au sein des documents, préservant l'intégrité des mises en page complexes. Cette approche holistique de l'analyse de documents permet une récupération d'informations plus nuancée et complète, améliorant considérablement l'utilité des données extraites pour les applications en aval.
Compétence Multilingue et Multi-format
Un des principaux avantages des modèles de langage visuel est leur flexibilité à gérer plusieurs langues et formats de documents. Contrairement aux systèmes OCR qui peuvent avoir du mal avec des scripts non latins ou des documents en langues mélangées, ces modèles peuvent traiter sans effort du contenu dans diverses langues et scripts, les rendant inestimables pour les besoins de traitement de documents à l'échelle mondiale.
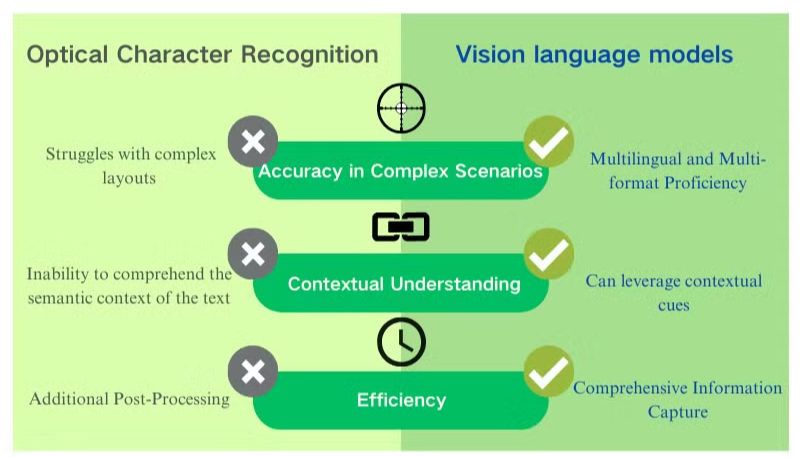
Principaux Avantages des Modèles de Langage Visuel pour la Compréhension des Documents
Les modèles de langage visuel offrent des avantages significatifs par rapport à l'OCR traditionnelle pour le traitement de documents et l'extraction de données. Ces systèmes alimentés par l'IA combinent compréhension visuelle et textuelle pour fournir des résultats supérieurs à travers divers types de documents.
Précision Améliorée et Compréhension Contextuelle
Les modèles de langage visuel excellent dans la gestion de mises en page complexes, d'images de mauvaise qualité et de polices diverses. Contrairement à l'OCR, qui a du mal avec des caractères ambigus, ces modèles exploitent des indices contextuels pour interpréter avec précision le texte. Cette capacité améliore considérablement la précision de l'extraction de données PDF, en particulier pour les documents avec des structures complexes ou une qualité d'image médiocre.
Capture d'Informations Complètes
Alors que l'OCR se concentre uniquement sur la reconnaissance de texte, les modèles de langage visuel peuvent extraire des données d'images, de tableaux et de graphiques. Cette approche holistique garantit que des informations critiques ne sont pas négligées lors de la phase de traitement des documents. En capturant à la fois des éléments textuels et visuels, ces modèles offrent une compréhension plus complète des contenus des documents.
Compétence Multilingue et Multi-format
Les modèles de langage visuel démontrent une flexibilité remarquable dans le traitement de documents à travers diverses langues et formats. Ils peuvent gérer sans effort des documents en langues mélangées et des scripts non latins, surmontant une limitation significative des systèmes OCR traditionnels. Cette polyvalence les rend inestimables pour les entreprises mondiales traitant divers types de documents et langues.
Applications Réelles Permises par les VLM que l'OCR a échouées à traiter
Les modèles de langage visuel révolutionnent le traitement de documents dans les secteurs de la finance, des ressources humaines et d'autres secteurs en s'attaquant aux limitations critiques des systèmes OCR traditionnels. Ces modèles d'IA avancés transforment les efforts de transformation numérique à travers les industries en offrant une précision et une compréhension contextuelle supérieures.
Révolutionner le Traitement de Documents Financiers
Les modèles de langage visuel transforment le traitement de documents dans le secteur financier, surmontant les limitations de l'OCR traditionnelle. Ces modèles avancés excellent dans l'extraction de données à partir d'états financiers complexes, de factures et de reçus avec des mises en page intriquées. Contrairement à l'OCR, ils peuvent comprendre le contexte, interprétant avec précision des caractères ambigus (par exemple, différencier un zéro de la lettre O) et des langues mélangées souvent présentes dans les documents financiers mondiaux.
Améliorer les Opérations RH grâce à une Analyse Documentaire Intelligente
Dans le secteur des ressources humaines, les modèles de langage visuel s'avèrent inestimables pour l'extraction de données PDF à partir de CV, de dossiers d'employés et d'évaluations de performance. Ces modèles peuvent comprendre la structure sémantique des documents, permettant une récupération et une analyse d'informations plus précises. Cette capacité rationalise considérablement les processus de recrutement et la gestion des données des employés, des tâches où l'OCR a souvent du mal avec des formats variés et des notes manuscrites.
Améliorer la Conformité et la Gestion des Risques
Les modèles de langage visuel sont particulièrement efficaces dans la conformité et la gestion des risques tant dans la finance que dans les ressources humaines. Ils peuvent extraire et interpréter des informations critiques à partir de documents réglementaires, de contrats et de politiques avec une plus grande précision que l'OCR. Cette capacité améliorée de traitement des documents garantit un meilleur respect des exigences légales et des procédures d'évaluation des risques plus efficaces.
Conclusion
En conclusion, les modèles de langage visuel représentent un bond en avant significatif dans la technologie de traitement de documents, s'attaquant à de nombreuses limitations inhérentes aux systèmes OCR traditionnels. En combinant compréhension visuelle et textuelle, ces modèles avancés offrent des performances supérieures dans une large gamme de scénarios difficiles, allant des mises en page complexes aux langues mélangées et aux images de mauvaise qualité. Alors que les organisations continuent de numériser leurs opérations et cherchent des moyens plus efficaces d'extraire de la valeur de leurs dépôts de documents, les modèles de langage visuel émergent comme un outil puissant pour les développeurs et les leaders techniques. Leur capacité à comprendre le contexte, à gérer des formats divers et à fournir des résultats plus précis les positionne comme un catalyseur clé pour des pipelines RAG sophistiqués et des capacités de recherche à l'échelle de l'entreprise, propulsant finalement les initiatives de transformation numérique vers de nouveaux sommets.