Vous êtes-vous déjà demandé ce que signifie OCR ? La reconnaissance optique de caractères est une technologie puissante qui convertit des images de texte en données lisibles par machine. Bien que l'OCR offre d'énormes avantages pour la numérisation de documents et l'extraction d'informations, elle n'est pas sans inconvénients. En explorant cette technologie, il est crucial de comprendre à la fois ses capacités et ses limitations. Dans cet article, vous découvrirez la signification de l'OCR et examinerez ses inconvénients potentiels. En acquérant une compréhension complète de la reconnaissance optique de caractères, vous serez mieux équipé pour déterminer si et comment mettre en œuvre cette technologie dans vos propres flux de travail et projets.
Que signifie OCR et qu'est-ce qu'un OCR ?
Que signifie OCR ?
OCR signifie reconnaissance optique de caractères, une technologie qui permet aux ordinateurs de reconnaître et de convertir divers types de documents. Au cœur de l'OCR se trouve le processus de numérisation de texte imprimé ou manuscrit et de conversion en texte encodé par machine. Cela permet au texte d'être facilement consultable, modifiable et transférable. Comprendre ce que signifie OCR est essentiel pour quiconque travaille avec des technologies de numérisation de documents et de reconnaissance de texte.
Qu'est-ce qu'un OCR ?
Pour ceux qui ne sont pas familiers avec le terme, "qu'est-ce qu'un OCR" est une question courante, se référant à la reconnaissance optique de caractères, une technologie qui permet aux ordinateurs de lire du texte à partir d'images ou de documents numérisés.
L'OCR convertit le texte imprimé ou manuscrit en données lisibles par machine, comblant le fossé entre les formats papier et numérique. Cette technologie utilise des algorithmes sophistiqués pour détecter les formes des lettres, les structures des mots et même des phrases entières. Ce faisant, elle transforme des images statiques en fichiers texte modifiables et consultables.
La technologie OCR repose fondamentalement sur la vision par ordinateur et les technologies de reconnaissance de motifs. L'OCR consiste à scanner des documents ou des images contenant du texte et à utiliser des algorithmes avancés pour identifier et convertir le texte en un format numérique et modifiable. L'un des moments clés de l'histoire de la technologie OCR a été en 1974, lorsque Ray Kurzweil a développé un système OCR omni-font capable de reconnaître du texte dans pratiquement toutes les polices. Au fil des ans, l'OCR a évolué, passant d'un simple appariement de modèles à des systèmes plus sophistiqués.
Malgré ses capacités, la technologie OCR fait actuellement face à certaines limitations. Celles-ci incluent des défis dans la reconnaissance de texte dans des images de mauvaise qualité, des difficultés à gérer des mises en page ou des arrière-plans complexes, et une précision variable lorsqu'il s'agit de différentes polices, langues ou écritures manuscrites. De plus, les systèmes OCR peuvent avoir du mal avec des documents ayant des arrière-plans colorés, flous ou inclinés, ainsi qu'avec l'écriture cursive.
Comprendre le logiciel de reconnaissance optique de caractères
Le logiciel de reconnaissance optique de caractères est une technologie transformative qui convertit divers types de documents en données modifiables et consultables. Il joue un rôle crucial dans la numérisation de notre monde, rendant l'information plus accessible et gérable. Le logiciel OCR utilise un processus sophistiqué pour convertir des images de texte en données lisibles par machine.
Comment fonctionne le logiciel OCR
1. Acquisition d'image
Le parcours de l'OCR commence par la capture d'une image du document. Cela peut se faire par le biais d'un scanner ou d'un appareil photo numérique. L'image est ensuite traduite en un format numérique que l'ordinateur peut traiter.
2. Prétraitement et amélioration de l'image
La deuxième étape consiste à améliorer la qualité de l'image. Une fois l'image acquise, elle subit un prétraitement pour améliorer sa qualité afin d'optimiser la reconnaissance. Cette étape peut impliquer l'ajustement du contraste, de la luminosité et de la netteté de l'image, ainsi que la suppression de tout bruit ou éléments non pertinents. Cette étape de prétraitement est cruciale pour obtenir des résultats précis, surtout lorsqu'il s'agit de numérisations ou de photographies de mauvaise qualité.
3. Détection de texte
Le logiciel OCR analyse l'image prétraitée pour détecter les zones contenant du texte. Il le fait en recherchant des motifs et des formes caractéristiques du texte, comme des lignes de différentes épaisseurs et hauteurs.
4. Segmentation des caractères
Une fois les zones de texte détectées, le logiciel décompose le texte en unités plus petites, comme des blocs, des lignes, des mots ou même des caractères individuels. Le logiciel OCR analyse l'image pixel par pixel pour identifier les motifs qui forment des caractères. Il décompose l'image en segments plus petits, isolant chaque caractère.
5. Reconnaissance et extraction de texte
Le logiciel compare ensuite ces formes isolées à une vaste base de données de motifs de caractères connus pour déterminer ce que chaque caractère est. Le logiciel extrait des caractéristiques des caractères, telles que le nombre de lignes, de courbes ou d'angles. Ces caractéristiques aident l'OCR à reconnaître et à distinguer différents caractères.
6. Post-traitement
Après l'identification des caractères, le système OCR passe par une étape de post-traitement où il corrige d'éventuelles erreurs et formate le texte pour la sortie. Le texte corrigé est ensuite exporté dans le format souhaité, tel qu'un document Word ou un PDF consultable.
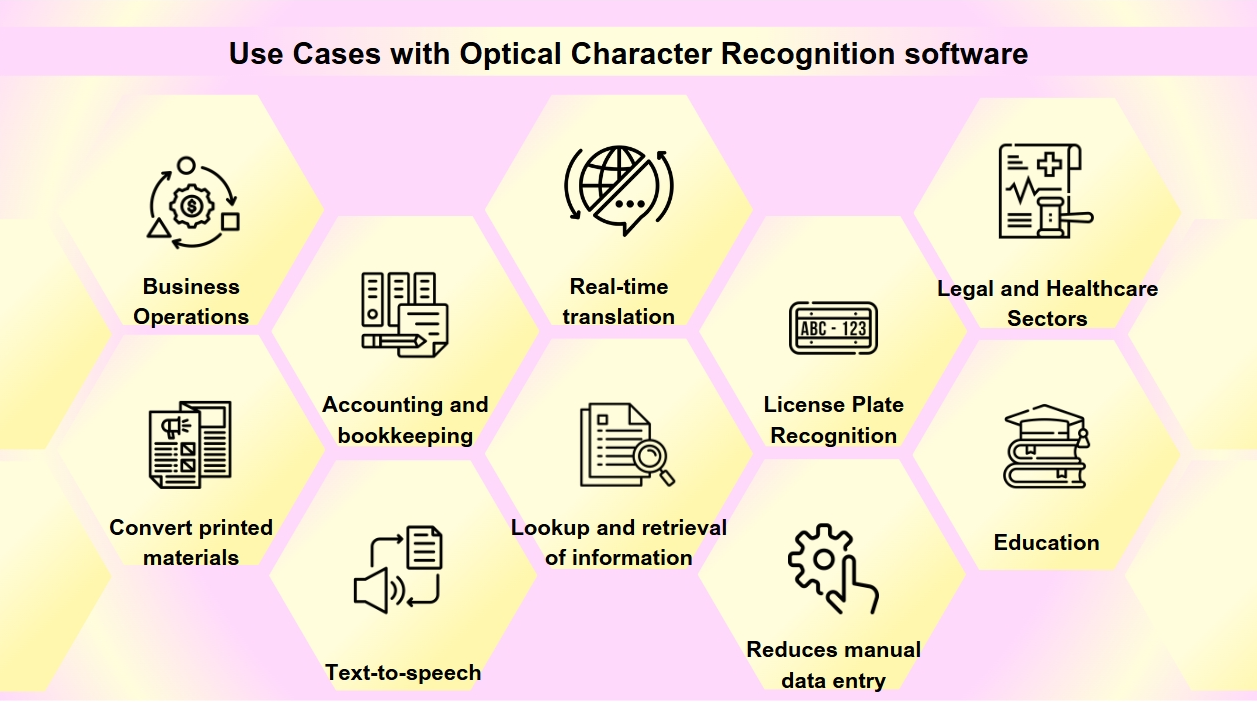
Cas d'utilisation du logiciel de reconnaissance optique de caractères
L'OCR est devenu un outil essentiel dans la transformation numérique de nombreuses industries, rationalisant les processus et améliorant l'accessibilité et la précision des données. Vous pourriez rencontrer l'OCR plus souvent que vous ne le réalisez. De la numérisation de cartes de visite à la numérisation de vieux livres, l'OCR joue un rôle crucial dans diverses industries. La technologie OCR a une large gamme d'applications :
-
Numérisation de documents : L'OCR est utilisé pour convertir des matériaux imprimés tels que des vieux livres, des journaux et des documents historiques en formats numériques, les rendant consultables et les préservant pour les générations futures.
-
Traitement de formulaires : Les entreprises utilisent l'OCR pour extraire automatiquement des données à partir de formulaires, ce qui réduit la saisie manuelle des données et augmente l'efficacité dans divers secteurs comme la finance et la santé.
-
Traitement des factures : La technologie OCR peut lire le texte sur les factures et saisir automatiquement les données dans les systèmes financiers, rationalisant ainsi les processus de comptabilité et de tenue de livres.
-
Accessibilité : L'OCR permet la fonctionnalité de synthèse vocale, créant des versions audio de textes pour les personnes malvoyantes, rendant ainsi les matériaux imprimés plus accessibles.
-
Applications mobiles : L'OCR est intégré dans des applications pour des tâches telles que la numérisation de cartes de visite, la reconnaissance de texte dans des photos et la facilitation de la traduction en temps réel.
-
Consultabilité : L'OCR améliore la consultabilité des documents numérisés en extrayant du texte à partir d'images ou de PDF, permettant ainsi une recherche et une récupération d'informations faciles.
-
Reconnaissance de plaques d'immatriculation : Utilisée pour la gestion des parkings et du trafic, l'OCR peut reconnaître les plaques d'immatriculation, permettant un suivi et une application efficaces.
-
Opérations commerciales : L'OCR rationalise les processus commerciaux en automatisant la saisie de données à partir de documents tels que des factures, des reçus et des bons de commande, ainsi qu'en accélérant le recrutement en numérisant et en traitant les candidatures et les CV.
-
Secteurs juridique et de la santé : Les cabinets d'avocats utilisent l'OCR pour numériser des dossiers de cas et des documents juridiques pour faciliter la récupération d'informations, tandis que les prestataires de soins de santé l'utilisent pour convertir des dossiers de patients et des formulaires médicaux en dossiers de santé électroniques (DSE), améliorant ainsi la gestion des données et les soins aux patients.
-
Éducation : Dans les établissements éducatifs, l'OCR est utilisé pour créer des manuels numériques et des matériaux d'apprentissage, améliorant l'accessibilité pour les étudiants ayant des besoins divers et soutenant un environnement d'apprentissage inclusif.
À mesure que la technologie OCR progresse, elle continue de jouer un rôle vital dans la facilitation de l'accès à l'information et de la gestion efficace dans l'ère numérique.
Les inconvénients de l'OCR : Limitations et inconvénients
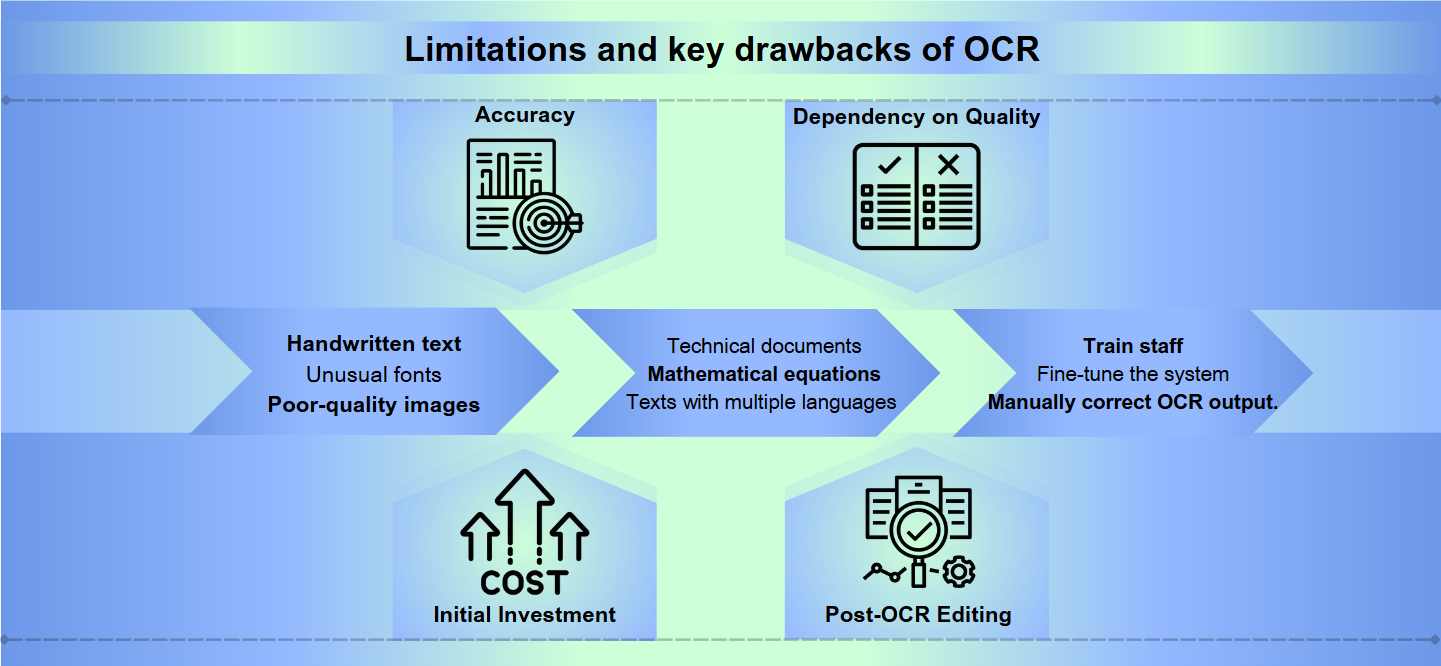
Défis de précision
Bien que la technologie de reconnaissance optique de caractères (OCR) ait fait des progrès considérables, elle fait encore face à des obstacles importants pour atteindre une précision parfaite. Le texte manuscrit, les polices inhabituelles ou les images de mauvaise qualité peuvent entraîner des interprétations erronées et des erreurs. Même de légères variations dans les formes ou les tailles des caractères peuvent confondre les systèmes OCR, entraînant une sortie illisible nécessitant une correction manuelle.
Restrictions linguistiques et de format
La plupart des solutions OCR excellent avec des langues et des formats standards, mais ont du mal avec du contenu spécialisé. Les documents techniques, les équations mathématiques ou les textes comportant plusieurs langues peuvent poser des défis significatifs. De plus, l'OCR peut échouer lorsqu'il est confronté à des mises en page complexes, des tableaux ou des documents avec un formatage complexe, perdant potentiellement des informations structurelles cruciales.
Intensité des ressources
La mise en œuvre et le maintien d'un système OCR efficace peuvent être gourmands en ressources. Les logiciels OCR de haute qualité sont souvent coûteux, et le matériel nécessaire pour traiter de grands volumes de documents peut être onéreux. De plus, le temps et les efforts nécessaires pour former le personnel, peaufiner le système et examiner manuellement et corriger la sortie de l'OCR peuvent mettre à rude épreuve les ressources organisationnelles.
Principaux inconvénients de l'OCR
-
Précision : Les logiciels OCR peuvent avoir des difficultés avec la précision, en particulier lorsqu'il s'agit d'images de mauvaise qualité, de mises en page complexes ou de texte manuscrit. Les erreurs peuvent aller de la mauvaise lecture de caractères à l'omission de sections entières de texte.
-
Dépendance à la qualité : L'efficacité de l'OCR dépend fortement de la qualité du document original. L'encre fanée, les taches ou le papier froissé peuvent entraîner des traductions inexactes.
-
Investissement initial : La mise en place d'un système OCR peut nécessiter un coût initial significatif, comprenant non seulement le logiciel mais aussi le matériel compatible comme les scanners.
-
Édition post-OCR : Souvent, la sortie des processus OCR nécessite une révision et une correction manuelles, ce qui peut prendre du temps.
Modèle de langage visuel surmontant les limitations de l'OCR
À mesure que la technologie progresse, des solutions innovantes émergent pour répondre aux lacunes de la reconnaissance optique de caractères (OCR) traditionnelle. L'une de ces percées est le modèle de langage visuel (VLM), qui combine la vision par ordinateur et le traitement du langage naturel pour révolutionner l'extraction et la compréhension du texte.
Compréhension contextuelle améliorée
Les VLM excellent à comprendre le contexte entourant le texte, contrairement à la reconnaissance isolée des caractères de l'OCR. En analysant les éléments visuels aux côtés du texte, ces modèles peuvent interpréter des mises en page complexes, des notes manuscrites et même du texte partiellement obscurci avec une précision remarquable.
Capacités multilingues et multimodales
Alors que l'OCR a souvent du mal avec des langues et des scripts divers, les VLM démontrent une polyvalence impressionnante. Ils peuvent traiter plusieurs langues sans effort et même interpréter du contenu visuel comme des diagrammes ou des graphiques, fournissant une compréhension plus complète des documents.
Apprentissage adaptatif et amélioration continue
Contrairement aux systèmes OCR statiques, les VLM exploitent l'apprentissage automatique pour s'adapter et s'améliorer au fil du temps. À mesure qu'ils rencontrent de nouvelles données et scénarios, ces modèles affinent leur performance, devenant de plus en plus compétents pour gérer divers types et formats de documents.
En surmontant les limitations de l'OCR, les modèles de langage visuel ouvrent la voie à un traitement de documents plus précis, efficace et intelligent dans divers secteurs.
Choisissez le modèle de langage visuel : Essayez AnyParser
S'appuyant sur les avancées des modèles de langage visuel (VLM), AnyParser émerge comme une solution sophistiquée qui transcende les limitations de la technologie OCR traditionnelle. Développé par l'équipe de CambioML, AnyParser est un puissant outil d'analyse de documents qui utilise une API précise et configurable pour extraire des informations à partir de diverses sources de données non structurées telles que des PDF, des images et des graphiques, les convertissant en formats structurés.
Fondement technique et capacités
AnyParser repose sur la solide fondation de grands modèles de langage (LLM), garantissant une haute précision dans l'extraction de texte, de tableaux, de graphiques et de mises en page à partir de documents. Il se distingue par sa capacité à maintenir la mise en page et le format d'origine, une caractéristique particulièrement bénéfique pour les documents ayant des mises en page complexes ou nécessitant la préservation de l'esthétique originale.
Confidentialité et sécurité
Soulignant la confidentialité des utilisateurs, AnyParser traite les données localement, protégeant ainsi les informations sensibles. Cette fonctionnalité est un avantage significatif pour les entreprises et les particuliers traitant des données confidentielles.
Personnalisabilité et flexibilité
Offrant un haut degré de configurabilité, AnyParser permet aux utilisateurs de définir des règles d'extraction personnalisées et de définir des formats de sortie adaptés à leurs besoins spécifiques. Cette adaptabilité en fait un outil idéal pour une large gamme d'applications, de l'ingénierie AI à l'analyse financière.
Conclusion
Comme vous l'avez appris, la technologie OCR offre des capacités puissantes pour numériser du texte, mais elle n'est pas sans limitations. Bien que la reconnaissance optique de caractères puisse améliorer considérablement l'efficacité, vous devez peser soigneusement les inconvénients potentiels. Considérez les problèmes de précision, les défis de formatage et les exigences en ressources avant de mettre en œuvre une solution OCR. En fin de compte, la décision d'utiliser l'OCR dépend de vos besoins et circonstances spécifiques. En comprenant à la fois les avantages et les inconvénients, vous pouvez faire un choix éclairé sur la pertinence de l'OCR pour votre organisation. À mesure que l'OCR continue d'évoluer, restez informé des nouvelles avancées qui pourraient répondre aux lacunes actuelles et débloquer un potentiel encore plus grand pour cette technologie transformative.
Appel à l'action
Embrassez la puissance des modèles de langage visuel en essayant AnyParser gratuitement pour convertir vos PDF en Google Sheets à https://www.cambioml.com/sandbox. Obtenez une consultation gratuite sur la manière dont les VLM peuvent améliorer votre flux de travail d'extraction de données.