Qu'est-ce que les données structurées et non structurées
À l'ère de l'information numérique, les données sont générées à tout moment, et les entreprises créent de la valeur grâce à l'analyse et au traitement des données. Par conséquent, la collecte et l'enregistrement des données ainsi que le traitement et l'analyse des données sont devenus deux tâches importantes dans le fonctionnement des entreprises. Dans le processus de collecte de données, les données non structurées sont rencontrées plus souvent, leur source et leur forme étant diverses, et il est difficile de les classer ou de les rechercher simplement. Une ingestion de données efficace est essentielle pour que les organisations transforment efficacement les données brutes en informations exploitables. Dans le processus de traitement des données, les données structurées sont plus souvent rencontrées, car elles ont une structure claire, des informations bien définies et peuvent être facilement organisées, recherchées et analysées. Par conséquent, transformer les données non structurées en données structurées est une étape importante pour les entreprises afin d'exploiter la valeur des données.
Données structurées
Les données structurées sont des données qui s'intègrent dans un modèle ou un schéma de données prédéfini. Elles sont particulièrement utiles pour traiter des données discrètes et numériques telles que les opérations financières, les chiffres de ventes et de marketing, et la modélisation scientifique.
Les données structurées sont généralement quantitatives et organisées de manière à être facilement recherchables. Elles incluent des types courants comme les noms, adresses, numéros de carte de crédit, numéros de téléphone, évaluations par étoiles, informations bancaires et d'autres données qui peuvent être facilement interrogées à l'aide de SQL dans des bases de données relationnelles.
Des exemples de données structurées dans des applications réelles incluent les données de vol et de réservation lors de la réservation d'un vol, et le comportement et les préférences des clients dans des systèmes CRM comme Salesforce. Elles conviennent le mieux aux collections associées de valeurs numériques et textuelles discrètes, courtes et non continues, et sont utilisées pour le contrôle des stocks, les systèmes CRM et les systèmes ERP.
Les données structurées sont stockées dans des bases de données relationnelles, des bases de données graphiques, des bases de données spatiales, des cubes OLAP, et plus encore. Son principal avantage est qu'il est plus facile de les organiser, de les nettoyer, de les rechercher et de les analyser, mais le principal défi est que toutes les données doivent s'inscrire dans le modèle de données prescrit.
Données non structurées
Les données non structurées sont des données sans un modèle sous-jacent pour discerner les attributs. Elles sont utilisées lorsque les données ne peuvent pas s'intégrer dans un format de données structuré, comme la surveillance vidéo, les documents d'entreprise et les publications sur les réseaux sociaux.
Des exemples de données non structurées incluent une variété de formats tels que les e-mails, les images, les fichiers vidéo, les fichiers audio, les publications sur les réseaux sociaux, les PDF, et plus encore. Environ 80 à 90 % des données sont non structurées, ce qui signifie qu'elles ont un énorme potentiel pour un avantage concurrentiel si les entreprises peuvent les exploiter.
Des exemples de données non structurées dans des applications réelles incluent des chatbots effectuant une analyse de texte pour répondre aux questions des clients et fournir des informations, et des données utilisées pour prédire les changements sur le marché boursier pour des décisions d'investissement. Les données non structurées conviennent le mieux aux collections associées de données, d'objets ou de fichiers dont les attributs changent ou sont inconnus, et elles sont utilisées avec des logiciels de présentation ou de traitement de texte et des outils de visualisation ou d'édition de médias. Les données de service supplémentaire non structurées, telles que les publications sur les réseaux sociaux et les retours clients, peuvent fournir des informations précieuses lorsqu'elles sont converties en formats structurés.
Elles sont généralement stockées dans des lacs de données, des bases de données NoSQL, des entrepôts de données et des applications. Le principal avantage des données non structurées est sa capacité à analyser des données qui ne peuvent pas être facilement façonnées en données structurées, mais le principal défi est qu'il peut être difficile de les analyser. La principale technique d'analyse pour les données non structurées varie en fonction du contexte et des outils utilisés.
Différence entre données structurées et non structurées
Avantages des données structurées et inconvénients des données non structurées
Les données structurées offrent l'avantage d'être facilement recherchables et utilisables pour les algorithmes d'apprentissage automatique, les rendant accessibles aux entreprises et aux organisations pour interpréter les données. Il existe également plus d'outils disponibles pour analyser les données structurées que pour les données non structurées. D'autre part, les données non structurées nécessitent que les scientifiques des données aient une expertise dans la préparation et l'analyse des données, ce qui pourrait restreindre d'autres employés de l'organisation dans leur accès. De plus, des outils spéciaux sont nécessaires pour traiter les données non structurées, ce qui contribue davantage à leur manque d'accessibilité.
Analyse des données structurées vs. Analyse des données non structurées
L'analyse des données structurées est généralement plus simple car les données sont strictement formatées, permettant l'utilisation de la logique de programmation pour rechercher et localiser des entrées de données spécifiques, ainsi que pour créer, supprimer ou modifier des entrées. Cela rend l'automatisation de la gestion des données et l'analyse des données structurées plus efficaces. En revanche, l'analyse des données non structurées n'a pas d'attributs prédéfinis, ce qui rend plus difficile la recherche et l'organisation. L'analyse des données non structurées nécessite souvent des algorithmes complexes pour prétraiter, manipuler et analyser, posant un plus grand défi dans le processus d'analyse. L'analyse des données de service supplémentaire non structurées nécessite souvent des techniques de parsing avancées pour extraire des informations significatives.
Gestion des données structurées vs. Gestion des données non structurées
La gestion des données structurées est généralement plus efficace en raison de sa nature organisée et prévisible. Les ordinateurs, les structures de données et les langages de programmation peuvent plus facilement comprendre les données structurées, ce qui entraîne des défis minimes dans leur utilisation. En revanche, la gestion des données non structurées présente deux défis majeurs : le stockage, car la gestion des données non structurées fait généralement face à un traitement plus important que la gestion des données structurées, et l'analyse, car la gestion des données non structurées n'est pas aussi simple que l'analyse des données structurées. Pour comprendre et gérer les données non structurées, les systèmes informatiques doivent d'abord les décomposer en composants compréhensibles, ce qui est un processus plus complexe.
Résumé de la différence entre données structurées et non structurées
Les données structurées sont définies et recherchables, incluant des données comme des dates, des numéros de téléphone et des SKU de produits. Cela les rend plus faciles à organiser, à nettoyer, à rechercher et à analyser par rapport aux données non structurées, qui englobent tout le reste qui est plus difficile à catégoriser ou à rechercher, comme des photos, des vidéos, des podcasts, des publications sur les réseaux sociaux et des e-mails. Une phrase pour expliquer la différence entre les données structurées et non structurées : La plupart des données dans le monde sont non structurées, mais la facilité de gestion et d'analyse des données structurées leur donne un avantage significatif dans les applications où les données peuvent être soigneusement organisées et rapidement accessibles.
Exemples de données structurées et non structurées
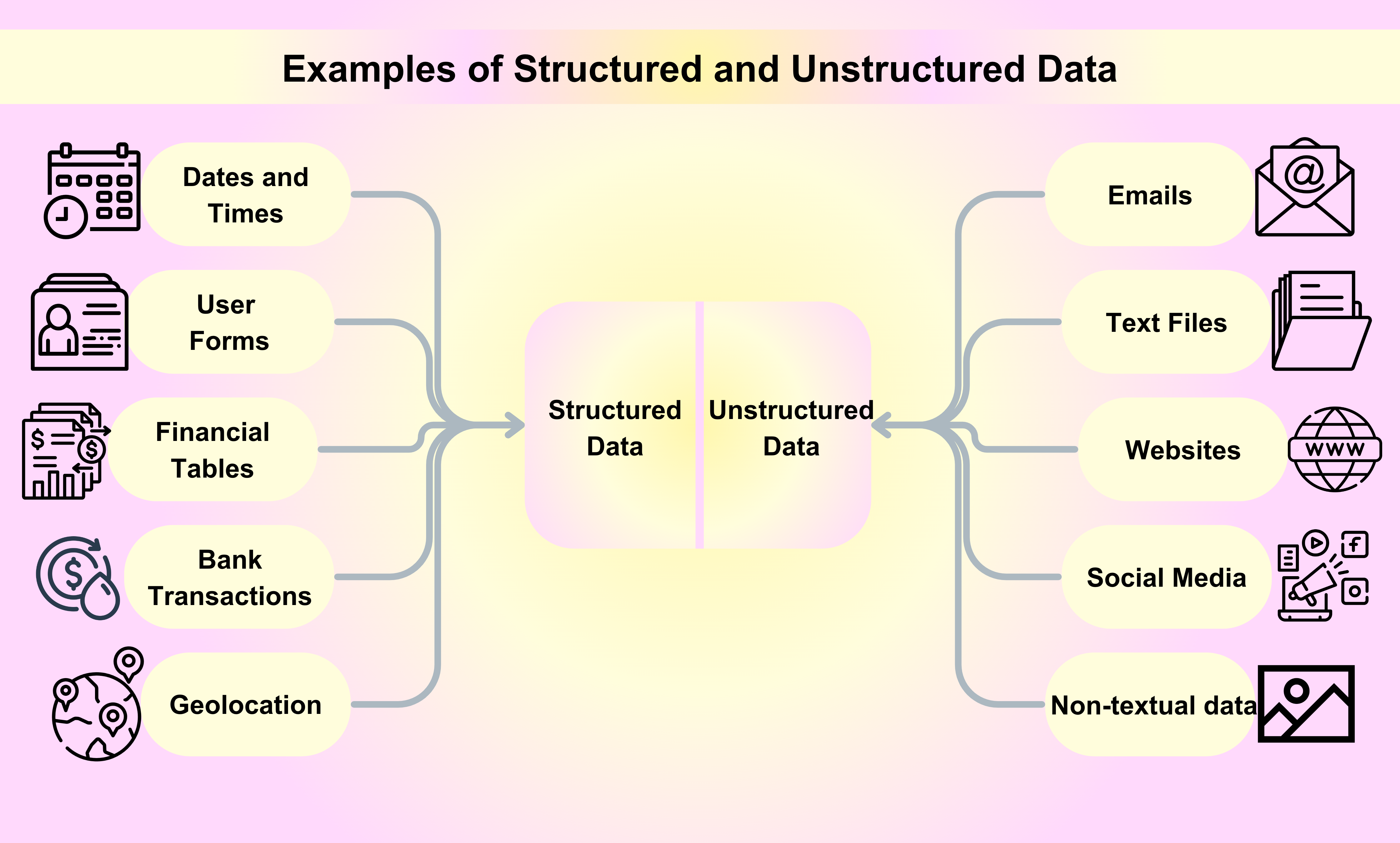
Exemples de données structurées
-
Dates et heures : Les dates et heures suivent un format spécifique, ce qui les rend faciles à lire et à analyser par les machines. Par exemple, une date peut être structurée sous la forme AAAA-MM-JJ, tandis qu'une heure peut être structurée sous la forme HH:MM:SS.
-
Noms et informations de contact des clients : Lorsque vous vous inscrivez à un service ou achetez un produit en ligne, votre nom, adresse e-mail, numéro de téléphone et autres informations de contact sont collectés et stockés de manière structurée.
-
Transactions financières : Les transactions financières telles que les transactions par carte de crédit, les dépôts bancaires et les virements sont tous des exemples de données structurées. Chaque transaction est accompagnée d'informations spécifiques sous la forme d'un numéro de série, d'une date de transaction, du montant et des parties impliquées.
-
Informations boursières : Les informations boursières telles que les prix des actions, les volumes de négociation et la capitalisation boursière sont un autre exemple de données structurées. Ces informations sont systématiquement organisées et mises à jour en temps réel.
-
Géolocalisation : Les données de géolocalisation, y compris les coordonnées GPS et les adresses IP, sont souvent utilisées dans diverses applications, des systèmes de navigation aux campagnes de marketing basées sur la localisation.
Exemples de données non structurées
-
E-mails : Les e-mails sont parmi les exemples de données non structurées les plus populaires que nous utilisons chaque jour à des fins professionnelles ou personnelles.
-
Fichiers texte : Des exemples de données non structurées incluent des fichiers de traitement de texte, des tableurs, des fichiers PDF, des rapports et des présentations.
-
Sites Web : Le contenu des sites Web comme YouTube, Instagram et Flickr est considéré comme un exemple de données non structurées.
-
Réseaux sociaux : Les données générées par des plateformes de réseaux sociaux telles que Facebook, Twitter et LinkedIn sont un exemple de données non structurées.
-
Médias : Les images numériques, les enregistrements audio et les vidéos représentent une énorme quantité de données non textuelles de manière non structurée qui peuvent être considérées comme des exemples de données non structurées.
Techniques pour l'analyse des données structurées
-
Requêtes SQL : Les données structurées peuvent être efficacement interrogées à l'aide de SQL (Structured Query Language), ce qui permet une récupération rapide et une manipulation des données stockées dans des bases de données relationnelles.
-
Entrepôt de données : Les données structurées peuvent être stockées dans des entrepôts de données, qui intègrent des données provenant de plusieurs sources et prennent en charge des requêtes et analyses complexes.
-
Algorithmes d'apprentissage automatique : Les algorithmes peuvent facilement traiter les données structurées pour identifier des modèles et faire des prédictions.
Les données structurées sont faciles à comprendre et à manipuler, ce qui les rend accessibles à un large éventail d'utilisateurs. Les données structurées permettent un stockage, une récupération et une analyse efficaces, ce qui accélère les processus de prise de décision. Les systèmes de données structurées peuvent évoluer pour gérer de grands volumes de données, garantissant que les performances restent élevées à mesure que les données augmentent.
Techniques pour l'analyse des données non structurées
-
Traitement du langage naturel (NLP) : Les techniques NLP sont utilisées pour analyser les données textuelles, extrayant des informations significatives et des insights à partir de grands volumes de texte non structuré.
-
Apprentissage automatique : Les algorithmes d'apprentissage automatique peuvent être entraînés à reconnaître des modèles dans des données non structurées, telles que des images ou des fichiers audio.
-
Lacs de données : Les données non structurées peuvent être stockées dans des lacs de données, qui permettent le stockage de données brutes dans leur format natif jusqu'à ce qu'elles soient nécessaires pour l'analyse.
À partir de l'exemple des techniques d'analyse des données non structurées, l'analyse des données non structurées est plus complexe et nécessite des outils et techniques spécialisés. Le traitement des données non structurées nécessite souvent des ressources informatiques et une capacité de stockage significatives. Les données non structurées peuvent contenir des incohérences, des erreurs ou des informations non pertinentes, rendant difficile l'assurance de la qualité des données. Rationaliser l'ingestion de données peut considérablement améliorer la capacité d'une organisation à gérer et analyser de grands volumes de données.
Exemples du besoin de convertir des données non structurées en données structurées
-
Analyse des retours clients : Convertir les avis et retours clients de texte non structuré en données structurées permet aux entreprises d'effectuer une analyse de sentiment et d'identifier des tendances en matière de satisfaction client.
-
Dossiers médicaux : Structurer des dossiers médicaux non structurés, tels que des notes de médecins et des rapports d'imagerie, permet une meilleure intégration avec les systèmes de dossiers de santé électroniques (DSE) et améliore les soins aux patients.
-
Conformité et reporting : Le processus d'ingestion de données implique l'extraction, le chargement et la transformation des données provenant de diverses sources dans un format adapté à l'analyse. Les organisations peuvent avoir besoin de convertir des données non structurées en formats structurés pour se conformer aux exigences réglementaires et faciliter un reporting précis.
-
Recherche de marché : Convertir des données non structurées provenant d'enquêtes et de groupes de discussion en données structurées aide à analyser les tendances du marché et le comportement des consommateurs.
Comment AnyParser peut parser des données non structurées en données structurées
AnyParser, développé par CambioML, est un puissant outil de parsing de documents conçu pour extraire des informations de diverses sources de données non structurées telles que des PDF, des images et des graphiques, et les convertir en formats structurés. Il exploite des modèles de langage visuel avancés (VLM) pour atteindre une grande précision et efficacité dans l'extraction de données.
Caractéristiques clés
-
Précision : Extrait avec précision du texte, des chiffres et des symboles tout en maintenant la mise en page et le format d'origine.
-
Confidentialité : Traite les données localement pour garantir la protection de la vie privée des utilisateurs et des informations sensibles.
-
Configurabilité : Permet aux utilisateurs de définir des règles d'extraction personnalisées et des formats de sortie.
-
Support multi-sources : Prend en charge l'extraction de diverses sources de données non structurées, y compris des PDF, des images et des graphiques.
-
Sortie structurée : Convertit les informations extraites en formats structurés tels que Markdown, CSV ou JSON.
Étapes pour parser des données non structurées à l'aide d'AnyParser
-
Téléchargez votre document : Commencez par télécharger votre fichier de données non structurées (par exemple, PDF, image) sur l'interface web d'AnyParser. Vous pouvez faire glisser et déposer votre fichier ou coller une capture d'écran pour un traitement rapide.
-
Sélectionnez les options d'extraction : Choisissez le type de données que vous souhaitez extraire. Par exemple, si vous devez extraire des tableaux d'un PDF, sélectionnez l'option "Tableau uniquement".
-
Traitez le document : Le moteur API d'AnyParser traitera le document, détectant et extrayant avec précision les informations requises. L'outil utilise des techniques VLM avancées pour identifier les points de données pertinents et les convertir en un format structuré.
-
Aperçu et vérification : Examinez les données extraites à l'aide de la fonction d'aperçu d'AnyParser. Comparez l'extraction initiale avec le document d'origine pour garantir l'exactitude.
-
Téléchargez ou exportez : Une fois satisfait de l'extraction, téléchargez le fichier de données structurées (par exemple, CSV, Excel) ou exportez-le directement vers des plateformes comme Google Sheets pour une analyse plus approfondie.
Avantages d'utiliser AnyParser
-
Efficacité et précision : Automatise les tâches d'extraction de données, réduisant l'effort manuel et minimisant les erreurs.
-
Sécurité des données : Garantit que les informations sensibles sont traitées localement, en conformité avec les normes de confidentialité des données.
-
Personnalisation flexible : Les utilisateurs peuvent adapter les paramètres d'extraction et les formats de sortie pour répondre à des besoins spécifiques.
-
Concentration analytique améliorée : Simplifie l'extraction de données, permettant aux professionnels de se concentrer sur des analyses de plus grande valeur.
Applications
-
Ingénieurs en IA : Extraire des informations textuelles et de mise en page à partir de PDF pour développer et entraîner des modèles d'IA.
-
Analystes financiers : Extraire des données numériques à partir de tableaux PDF pour une analyse financière précise.
-
Scientifiques des données : Traiter de grands volumes de documents non structurés pour découvrir des insights et des tendances.
-
Entreprises : Automatiser le traitement et l'analyse de divers documents, tels que des contrats et des rapports, pour améliorer l'efficacité opérationnelle.
En tirant parti d'AnyParser, les utilisateurs peuvent transformer des données non structurées complexes en fichiers structurés et modifiables, les intégrant facilement dans leurs flux de travail pour une analyse et une gestion des données améliorées.
Conclusion
À l'ère numérique, convertir des données non structurées en formats structurés à l'aide d'outils comme AnyParser est crucial pour les entreprises afin de débloquer des insights et d'obtenir un avantage concurrentiel. AnyParser peut être utilisé pour parser des données de service supplémentaire non structurées, facilitant leur intégration dans des systèmes d'intelligence d'affaires. En rationalisant ce processus, les organisations peuvent exploiter efficacement tout le potentiel de leurs données, favorisant une meilleure prise de décision et une planification stratégique.