परिचय
तालिकाएँ संरचित डेटा प्रतिनिधित्व का एक आधार हैं, जो वित्त, स्वास्थ्य देखभाल और अनुसंधान जैसे उद्योगों में व्यापक रूप से उपयोग की जाती हैं। हालाँकि, PDFs, स्कैन किए गए दस्तावेज़ों या छवियों जैसे प्रारूपों से तालिका संबंधी जानकारी निकालना विभिन्न लेआउट और जटिलताओं के कारण एक चुनौती बनी हुई है।
कृत्रिम बुद्धिमत्ता (AI) ने दस्तावेज़ पार्सिंग में क्रांति ला दी है, जिससे PDF से तालिका निकालने या तालिका PNG को संरचित डेटा में परिवर्तित करने जैसी समस्याओं के लिए सटीक और कुशल समाधान संभव हो गए हैं। उन्नत AI तकनीकों का उपयोग करके, व्यवसाय अब असंरचित दृश्य सामग्री को क्रियाशील अंतर्दृष्टियों में आसानी से परिवर्तित कर सकते हैं, जिसमें कार्यप्रवाह में सहज एकीकरण के लिए छवि को तालिका में परिवर्तित करना शामिल है।
यह ब्लॉग यह अन्वेषण करता है कि AI तालिका निष्कर्षण उद्योगों को कैसे सशक्त बनाता है, इसके अंतर्निहित तकनीकों को उजागर करता है, और जटिल दस्तावेज़ प्रसंस्करण कार्यों को सरल बनाने की इसकी क्षमता को प्रदर्शित करता है।

पारंपरिक तालिका निष्कर्षण में चुनौतियाँ
PDF या छवियों जैसे दस्तावेज़ों से तालिका संबंधी डेटा मैन्युअल रूप से निकालना थकाऊ, त्रुटि-प्रवण और अप्रभावी है। नीचे कुछ सामान्य चुनौतियाँ दी गई हैं जो पारंपरिक विधियों के साथ सामना की जाती हैं:
-
जटिल तालिका संरचनाएँ: तालिकाएँ अक्सर असामान्य लेआउट में होती हैं, जैसे कि नेस्टेड सेल, मल्टी-लाइन हेडर, या मर्ज किए गए पंक्तियाँ, जिन्हें समझना कठिन होता है। पारंपरिक उपकरण ऐसे परिदृश्यों में PDF से तालिका निकालने में सटीकता से विफल रहते हैं।
-
विविध प्रारूप: तालिकाएँ स्कैन किए गए दस्तावेज़ों, तालिका PNG फ़ाइलों और PDFs सहित विभिन्न प्रारूपों में दिखाई देती हैं। इनसे डेटा निकालने के लिए उन्नत पहचान तकनीकों की आवश्यकता होती है जो साधारण OCR से परे जाती हैं।
-
संदर्भ और अर्थ: पारंपरिक प्रणालियाँ पंक्तियों और कॉलमों के बीच संबंधों को बनाए रखने में संघर्ष करती हैं, जो छवि को तालिका में परिवर्तित करने या बड़े डेटा सेट को संसाधित करने के समय महत्वपूर्ण है।
ये चुनौतियाँ बुद्धिमान समाधानों की आवश्यकता को उजागर करती हैं जैसे AI-संचालित तालिका निष्कर्षण, जो जटिल लेआउट और विविध प्रारूपों को संभालने के साथ-साथ उच्च सटीकता सुनिश्चित कर सकती है।
AI तालिका निष्कर्षण क्या है?
AI तालिका निष्कर्षण बुद्धिमान दस्तावेज़ पार्सिंग तकनीकों का अनुप्रयोग है जिसे विभिन्न दस्तावेज़ प्रारूपों में तालिकाओं से संरचित डेटा की पहचान, निष्कर्षण और संगठन के लिए तैयार किया गया है। पारंपरिक नियम-आधारित विधियों के विपरीत, AI-संचालित दृष्टिकोण जटिल चुनौतियों का सामना करने के लिए उन्नत तकनीकों का उपयोग करते हैं, जैसे गैर-मानक लेआउट, मर्ज किए गए सेल और मल्टी-लाइन हेडर।
इस क्षेत्र में एक प्रमुख उन्नति दृष्टि-भाषा मॉडल (VLMs) का उपयोग है। VLMs कंप्यूटर दृष्टि और प्राकृतिक भाषा समझ के लाभों को संयोजित करते हैं, जिससे वे दस्तावेज़ के भीतर दृश्य और पाठ्य तत्वों दोनों की व्याख्या कर सकते हैं। यह द्वि-क्षमता VLMs को सक्षम बनाती है:
- दृश्य रूप से तालिका संरचनाओं की पहचान करना, भले ही उनमें स्पष्ट प्रारूपण न हो।
- सामग्री को संदर्भ में समझना, जैसे हेडर, डेटा और नोट्स के बीच अंतर करना।
- स्कैन की गई छवियों, PDFs और हस्तलिखित नोट्स सहित विभिन्न दस्तावेज़ प्रकारों के लिए अनुकूलित होना।
VLMs का लाभ उठाकर, AI तालिका निष्कर्षण अधिक सटीक और बहुपरकारी बन गया है, जो बहु-भाषाई दस्तावेज़ों को संभालने और डेटा बिंदुओं के बीच संबंधों को निकालने में सक्षम है, जो पारंपरिक विधियाँ अक्सर चूक जाती हैं।
AI तालिका निष्कर्षण के पीछे की प्रमुख तकनीकें
AI तालिका निष्कर्षण एक उन्नत तकनीकों के समूह पर निर्भर करता है जो पारंपरिक चुनौतियों को पार करने के लिए सामंजस्य में काम करती हैं। इनमें से, दृष्टि-भाषा मॉडल (VLMs) एक परिवर्तनकारी नवाचार के रूप में उभरे हैं। नीचे प्रमुख तकनीकों और VLMs की महत्वपूर्ण भूमिका का विवरण दिया गया है:
-
ऑप्टिकल कैरेक्टर रिकग्निशन (OCR): छवियों या स्कैन किए गए दस्तावेज़ों से पाठ निकालता है। जब VLMs के साथ जोड़ा जाता है, तो OCR परिणामों में सुधार होता है क्योंकि मॉडल दृश्य संरचना और पाठ्य अर्थ दोनों को समझते हैं।
-
दृष्टि-भाषा मॉडल (VLMs): VLMs तालिका निष्कर्षण में दृश्य और भाषाई डेटा प्रसंस्करण को एकीकृत करके क्रांति लाते हैं। वे उत्कृष्टता प्राप्त करते हैं:
- जटिल तालिका लेआउट और असामान्य सीमाओं को पहचानना।
- पंक्तियों, कॉलमों और हेडरों के बीच संबंधों की व्याख्या करना।
- छवियों और PDFs सहित विभिन्न प्रारूपों में तालिकाओं को संभालना, बहुभाषी समर्थन के साथ। VLMs गहरे संदर्भीय समझ को सक्षम बनाते हैं, यह सुनिश्चित करते हुए कि निकाली गई डेटा अपनी मूल संरचना और अर्थ को बनाए रखती है।
-
प्राकृतिक भाषा प्रसंस्करण (NLP): निकाली गई डेटा का विश्लेषण और संगठन करता है, यह सुनिश्चित करता है कि अर्थ संगत हो। VLMs दृश्य पैटर्न से संदर्भीय संकेत प्रदान करके NLP को और बढ़ाते हैं।
-
डीप लर्निंग एल्गोरिदम: मॉडल को तालिका सीमाओं, सेल हायरार्की, और असंरचित दस्तावेज़ों में पैटर्न का पता लगाने के लिए प्रशिक्षित करते हैं। जब VLMs द्वारा समृद्ध किया जाता है, तो ये एल्गोरिदम अधिक सटीकता और अनुकूलनशीलता प्राप्त करते हैं।
VLMs पर जोर देकर, AI तालिका निष्कर्षण सरल डेटा पुनर्प्राप्ति के कार्य से संदर्भित समझ के कार्य में स्थानांतरित हो गया है, जिससे यह उन उद्योगों के लिए अमूल्य बन गया है जहाँ सटीकता और बारीकी महत्वपूर्ण हैं।
AI तालिका निष्कर्षण के उपयोग के मामले
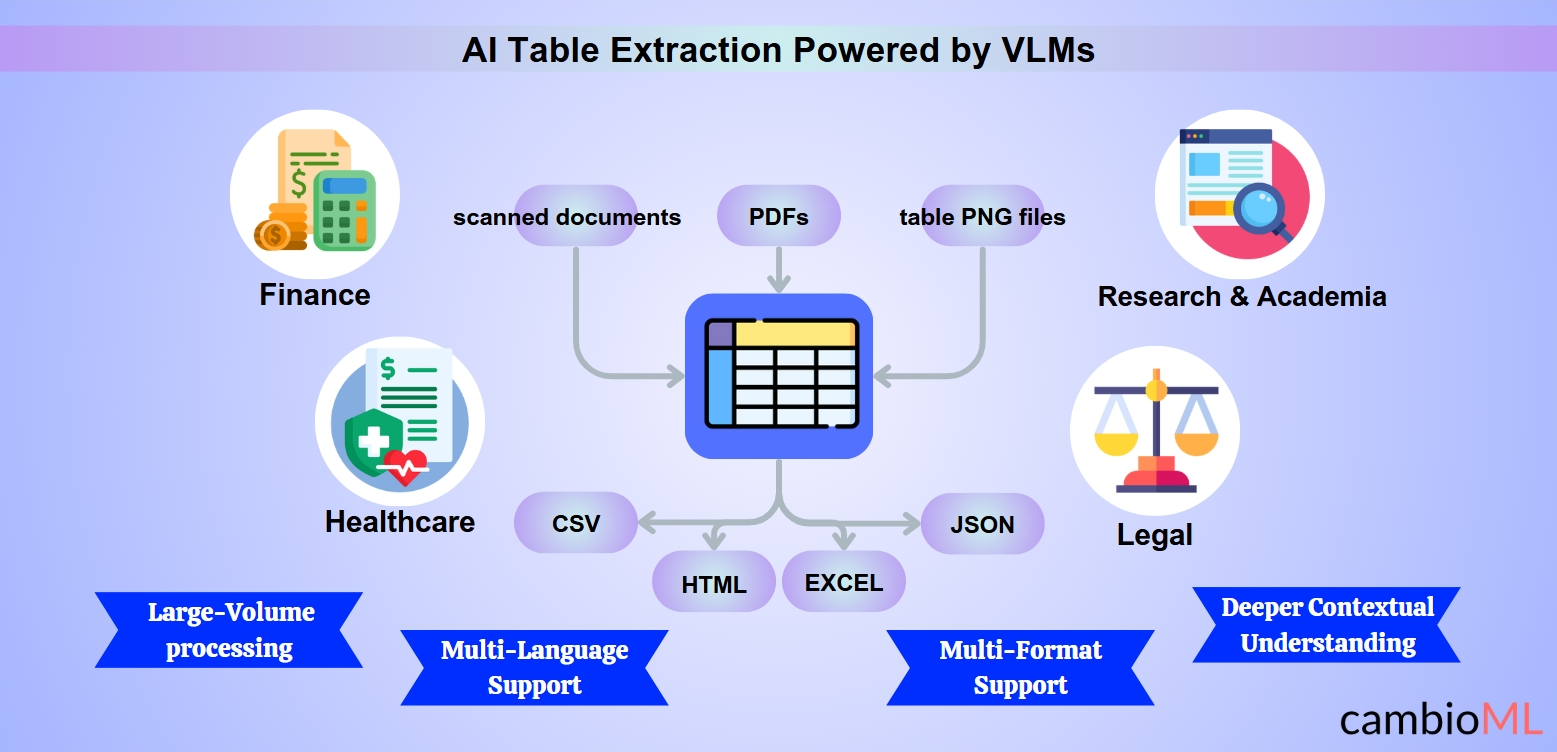
AI-संचालित तालिका निष्कर्षण उद्योगों को विभिन्न दस्तावेज़ प्रारूपों से तालिका संबंधी डेटा निकालने और व्यवस्थित करने की प्रक्रिया को स्वचालित करके बदल रहा है। नीचे कुछ उल्लेखनीय उपयोग के मामले दिए गए हैं जहाँ बुद्धिमान तालिका निष्कर्षण अमूल्य साबित हुआ है:
-
वित्त: वित्तीय विवरण, चालान, और रिपोर्टों से संरचित डेटा निकालना अक्सर श्रम-गहन कार्य होता है। AI इसे PDF तालिका को Excel में कॉपी करने के लिए सहज बनाता है, जिससे सामंजस्य, विश्लेषण, और रिपोर्टिंग में तेजी आती है।
-
स्वास्थ्य देखभाल: नैदानिक परीक्षण परिणामों, रोगी रिकॉर्ड, या चिकित्सा अनुसंधान डेटा का आयोजन सरल हो जाता है। उदाहरण के लिए, स्वास्थ्य सेवा प्रदाता आसानी से PDF से तालिका को Excel में कॉपी कर सकते हैं, यह सुनिश्चित करते हुए कि डेटा इलेक्ट्रॉनिक स्वास्थ्य रिकॉर्ड (EHR) प्रणालियों में एकीकरण के लिए तैयार है।
-
कानूनी: अनुबंधों का विश्लेषण करना और नेस्टेड तालिकाओं से संरचित क्लॉज़ निकालना कानूनी टीमों को अधिक कुशलता से काम करने में मदद करता है। AI मॉडल PDF तालिका को Excel में कॉपी करना सीधा बनाते हैं, अनुपालन जांच और मुकदमे के शोध में समय बचाते हैं।
-
अनुसंधान और अकादमी: शोधकर्ता शैक्षणिक लेखों से डेटा को जल्दी निकाल सकते हैं, प्रमुख मैट्रिक्स को स्थानांतरित करने के कार्य को सरल बनाते हुए PDF से तालिका को Excel में कॉपी करने के लिए उपकरणों का उपयोग करते हैं, जिससे डेटा सेट सांख्यिकीय विश्लेषण के लिए तैयार हो जाते हैं।
AI तालिका निष्कर्षण की क्षमता विभिन्न दस्तावेज़ प्रारूपों को सटीकता से संसाधित करने की है, जो कार्यप्रवाहों को क्रांतिकारी बना रही है, जिससे Excel शीट में तालिका संबंधी डेटा को कॉपी, व्यवस्थित और विश्लेषण करना आसान हो जाता है।
बुद्धिमान तालिका निष्कर्षण के लाभ
AI तालिका निष्कर्षण कई लाभ प्रदान करता है, विशेष रूप से दक्षता, सटीकता, और स्केलेबिलिटी में सुधार करने में। दृष्टि-भाषा मॉडल (VLMs) सहित उन्नत तकनीकों का लाभ उठाकर, व्यवसाय तालिका निष्कर्षण में पारंपरिक चुनौतियों को पार कर सकते हैं:
-
स्वचालन और समय की बचत: PDF से Excel में तालिकाओं को मैन्युअल रूप से कॉपी करने जैसे दोहराए जाने वाले कार्य समाप्त हो जाते हैं, जिससे कर्मचारियों को उच्च-मूल्य गतिविधियों पर ध्यान केंद्रित करने की अनुमति मिलती है।
-
सुधरी हुई सटीकता: AI मॉडल उन त्रुटियों को काफी कम करते हैं जो उपयोगकर्ताओं द्वारा PDF तालिका को Excel में मैन्युअल रूप से कॉपी करने या बुनियादी उपकरणों पर निर्भर रहने पर सामान्य होती हैं। ये मॉडल सुनिश्चित करते हैं कि डेटा अपनी संरचना और अर्थ को बनाए रखता है।
-
बड़े-परिमाण प्रसंस्करण के लिए स्केलेबिलिटी: AI उपकरण बड़े डेटा निष्कर्षण को संभालने के लिए डिज़ाइन किए गए हैं। चाहे वह वित्तीय रिकॉर्ड, अनुसंधान दस्तावेज़, या अनुपालन फ़ाइलें हों, वे Excel में डेटा निकालने और व्यवस्थित करने की प्रक्रिया को सरल बनाते हैं।
-
बहु-फॉर्मेट और बहु-भाषा समर्थन: बुद्धिमान प्रणालियाँ विभिन्न प्रारूपों और भाषाओं में दस्तावेज़ों को संसाधित कर सकती हैं, जिससे जटिल, बहु-भाषाई संदर्भों में भी PDF से तालिका को कॉपी करना सहज हो जाता है।
AI तालिका निष्कर्षण न केवल कार्यप्रवाहों को सुव्यवस्थित करता है बल्कि डेटा की संदर्भीय अखंडता को भी सुनिश्चित करता है, जिससे यह उद्योगों के लिए तालिका संबंधी जानकारी को संभालने के तरीके को बदल देता है। यह दक्षता आज के डेटा-चालित विश्व में महत्वपूर्ण है, जहाँ तालिका संबंधी डेटा की त्वरित और सटीक प्रसंस्करण एक प्रतिस्पर्धात्मक लाभ है।
बहु-फॉर्मेट और बहु-भाषा चुनौतियों का समाधान
आधुनिक AI समाधान प्रारूपों और भाषाओं की विविधता को संभालने में उत्कृष्टता प्राप्त करते हैं, विविध डेटा सेटों में सुसंगत सटीकता और दक्षता सुनिश्चित करते हैं:
-
बहु-फॉर्मेट क्षमताएँ: AI-संचालित उपकरण PDFs, स्कैन किए गए दस्तावेज़ों, और तालिका PNG जैसी छवि फ़ाइलों को सहजता से संसाधित कर सकते हैं। यह बहुपरकारी विशेषता विशेष रूप से महत्वपूर्ण है जब उपयोगकर्ताओं को PDF से तालिका निकालने या विश्लेषण और रिपोर्टिंग के लिए छवि को तालिका में परिवर्तित करने की आवश्यकता होती है।
-
बहु-भाषा समर्थन: AI मॉडल बहु-भाषाई डेटा सेटों पर प्रशिक्षित होते हैं, जिससे वे विभिन्न भाषाओं में दस्तावेज़ों को संभालने में सक्षम होते हैं। यह वैश्विक उद्योगों के लिए अमूल्य है जो अंतरराष्ट्रीय दस्तावेज़ों के साथ काम करते हैं।
-
डेटा संबंधों का संरक्षण: चाहे छवि को तालिका में संसाधित करना हो या PDF से जटिल संरचना निकालना हो, AI प्रणालियाँ सुनिश्चित करती हैं कि हेडर, पंक्तियाँ, और कॉलम संरक्षित रहें, डेटा की अखंडता बनाए रखते हुए।
इन चुनौतियों का समाधान करके, AI समाधान बड़े पैमाने पर, बहु-भाषाई, और बहु-फॉर्मेट दस्तावेज़ों को संभालने वाले संगठनों के लिए अनिवार्य उपकरणों के रूप में स्थापित हो गए हैं।
तालिका निष्कर्षण में AI का भविष्य
AI तालिका निष्कर्षण का भविष्य उज्ज्वल है, जिसमें उन्नतियाँ इसकी क्षमताओं को और बढ़ाने के लिए निर्धारित हैं:
-
उन्नत दृष्टि-भाषा मॉडल (VLMs): उभरती VLM तकनीकें PDF से तालिका निकालने और जटिल तालिका PNG प्रारूपों को संरचित डेटा में परिवर्तित करने के लिए और भी अधिक परिष्कृत तरीके प्रदान करेंगी। ये मॉडल दृश्य तत्वों और पाठ्य समझ के बीच की खाई को पाटेंगे।
-
जनरेटिव AI के साथ एकीकरण: भविष्य के समाधान जनरेटिव AI के साथ एकीकृत करके न केवल PDF या छवियों से तालिका निकाल सकते हैं, बल्कि निकाली गई डेटा का विश्लेषण करके अंतर्दृष्टि, सारांश, और सिफारिशें भी प्रदान कर सकते हैं।
-
अंत-से-अंत स्वचालन: AI-संचालित उपकरण कार्यप्रवाहों को स्वचालित रूप से फ़ाइलों को परिवर्तित करके सुव्यवस्थित करेंगे, जैसे कि छवि को तालिका में परिवर्तित करना, डेटा को वर्गीकृत करना, और इसे सीधे विश्लेषण पाइपलाइनों में फीड करना।
-
व्यापक पहुंच: AI प्रणालियाँ अधिक उपयोगकर्ता-अनुकूल और सुलभ बनेंगी, जिससे गैर-तकनीकी उपयोगकर्ताओं को भी तालिका PNG फ़ाइलों को संसाधित करना या डेटा को आसानी से निकालना संभव हो सकेगा।
AI तालिका निष्कर्षण दस्तावेज़ प्रसंस्करण को फिर से परिभाषित करने के लिए तैयार है, जिससे डेटा निष्कर्षण तेज़, स्मार्ट, और विकसित होती उद्योग आवश्यकताओं के लिए अधिक अनुकूल हो जाएगा। जो व्यवसाय इन समाधानों को अपनाएंगे, वे अपने डेटा को प्रभावी ढंग से प्रबंधित करने और उपयोग करने में प्रतिस्पर्धात्मक बढ़त प्राप्त करेंगे।
AnyParser: दस्तावेज़ पार्सिंग और तालिका निष्कर्षण में एक गेम-चेंजर
AnyParser बुद्धिमान दस्तावेज़ पार्सिंग के क्षेत्र में अग्रणी है, जो व्यवसायों को सबसे जटिल दस्तावेज़ों से डेटा निकालने का एक कुशल और विश्वसनीय तरीका प्रदान करता है। इसकी उन्नत क्षमताएँ विशेष रूप से तालिका निष्कर्षण के मामले में स्पष्ट होती हैं, जो विभिन्न उद्योगों के लिए सटीक और स्केलेबल डेटा कैप्चर सुनिश्चित करती हैं।
तालिका निष्कर्षण के लिए AnyParser के प्रमुख लाभ
-
व्यापक प्रारूप समर्थन: चाहे PDFs, छवियों, या अन्य फ़ाइल प्रकारों के साथ काम कर रहे हों, AnyParser डेटा कैप्चर को सरल बनाता है, प्रारूप की परवाह किए बिना तालिका संबंधी जानकारी को सटीकता से निकालता है।
-
उच्च सटीकता और संदर्भीय समझ: पारंपरिक उपकरणों के विपरीत, AnyParser तालिका संबंधी डेटा की संरचना, संबंधों, और संदर्भ को बनाए रखता है, विश्लेषण और एकीकरण के लिए तैयार परिणाम प्रदान करता है।
-
AI-संचालित दक्षता: दृष्टि-भाषा मॉडल (VLMs) द्वारा संचालित, AnyParser बहु-भाषा और बहु-फॉर्मेट वातावरण में उत्कृष्टता प्राप्त करता है, जिससे बड़े पैमाने पर डेटा कैप्चर सुनिश्चित होता है।
-
अनुकूलन योग्य कार्यप्रवाह: यह प्लेटफ़ॉर्म आपकी अनूठी आवश्यकताओं के अनुसार अनुकूलित होता है, चाहे आप वित्तीय तालिकाएँ, स्वास्थ्य देखभाल रिकॉर्ड, या अनुसंधान डेटा निकाल रहे हों।
AnyParser के साथ, व्यवसाय अपने प्रक्रियाओं को अनुकूलित कर सकते हैं, त्रुटियों को कम कर सकते हैं, और संरचित डेटा कैप्चर के लिए तालिकाओं को निकालने के जटिल कार्य को स्वचालित करके समय बचा सकते हैं।
निष्कर्ष
AI-संचालित तालिका निष्कर्षण ने व्यवसायों के लिए संरचित डेटा को संसाधित करने और उपयोग करने के तरीके को फिर से परिभाषित किया है। चाहे कार्य PDF से तालिकाएँ निकालने का हो, छवियों को संसाधित करने का हो, या सटीक डेटा कैप्चर प्राप्त करने का हो, AnyParser जैसे उपकरण असंरचित दस्तावेज़ों को क्रियाशील अंतर्दृष्टियों में परिवर्तित करना पहले से कहीं अधिक आसान बनाते हैं। AnyParser आपके दस्तावेज़ पार्सिंग को सरल बनाने के लिए आपका विश्वसनीय समाधान है, जो बेजोड़ सटीकता और दक्षता प्रदान करता है। विभिन्न प्रारूपों और संदर्भों को संभालने की इसकी क्षमता, AnyParser को संगठनों को उनके कार्यप्रवाहों को स्वचालित करने और उनके डेटा की पूरी क्षमता को अनलॉक करने के लिए सशक्त बनाती है।
कार्रवाई के लिए कॉल
दस्तावेज़ पार्सिंग के अगले स्तर का अनुभव करने के लिए क्यों इंतजार करें? AnyParser की पूरी क्षमता को एक हाथों-हाथ वातावरण में आजमाकर अनलॉक करें!
नीचे दिए गए लिंक पर क्लिक करें ताकि आप Sandbox में प्रवेश कर सकें, जहाँ आप देख सकते हैं कि यह कैसे सरल बनाता है:
- PDFs और छवियों से सटीक डेटा कैप्चर।
- विश्लेषणात्मक उपकरणों में एकीकरण के लिए तालिकाओं का सहज निष्कर्षण।
- जटिल और बड़े डेटा सेटों में विश्वसनीय प्रदर्शन।
अब Sandbox में AnyParser का अनुभव करें
यह देखने का मौका न चूकें कि AnyParser आपके कार्यप्रवाहों को कैसे क्रांतिकारी बना सकता है। आज ही इसका परीक्षण करें और जानें कि दस्तावेज़ पार्सिंग और तालिका निष्कर्षण कितनी सहज हो सकती है!