डेटा प्रबंधन के क्षेत्र में, पार्सिंग का अर्थ है सामग्री को एक उपयोगी प्रारूप (जैसे, साधारण पाठ, संरचित डेटा, या छवियाँ) में परिवर्तित करना जिसे आगे संसाधित या विश्लेषित किया जा सके। यह PDF पार्सिंग के क्षेत्र में विशेष रूप से स्पष्ट है, पार्सिंग की दुनिया में प्रवेश करें, एक महत्वपूर्ण प्रक्रिया जो कच्ची जानकारी को संरचित, उपयोगी डेटा में बदल देती है। यह व्यापक गाइड PDF पार्सिंग की जटिलताओं में गहराई से उतरती है, इसकी परिभाषा, यह कौन-कौन से डेटा निकाल सकती है, इसके सामने आने वाली बाधाएँ, इसके बहुआयामी अनुप्रयोग, और इसके पूर्ण क्षमता का उपयोग करने के लिए उपलब्ध तरीकों की भरपूरता को स्पष्ट करती है। आप विभिन्न पार्सिंग विधियों का अन्वेषण करेंगे, विशेष रूप से PDF पार्सिंग पर ध्यान केंद्रित करते हुए और यह कैसे उपकरण जैसे AnyParser भीड़ से अलग खड़े होते हैं।
PDF पार्सर को समझना: पार्सिंग क्या है?
पार्सिंग क्या है: डेटा कैप्चर की सावधानीपूर्वक प्रक्रिया
PDF पार्सिंग का मूलतः मतलब है PDF (पोर्टेबल डॉक्यूमेंट फॉर्मेट) फ़ाइलों से डेटा निकालना और उसकी व्याख्या करना। चूंकि PDFs को मुख्य रूप से प्रदर्शन के लिए डिज़ाइन किया गया है न कि संरचित डेटा भंडारण के लिए, पार्सिंग में सामग्री को एक उपयोगी प्रारूप (जैसे, साधारण पाठ, संरचित डेटा, या छवियाँ) में परिवर्तित करना शामिल है जिसे आगे संसाधित या विश्लेषित किया जा सके। पार्सिंग में एक उच्च-स्तरीय विश्लेषण शामिल होता है ताकि PDF के भीतर विशिष्ट तत्वों को पहचानना और पुनर्प्राप्त करना संभव हो सके, जो केवल पाठ और छवियों से परे जाकर फोंट, लेआउट, तालिकाएँ और मेटाडेटा को भी शामिल करता है। यह प्रक्रिया केवल एक तकनीकीता नहीं है बल्कि विभिन्न उद्योगों में एक आवश्यकता है जैसे कि वित्त, कानून, लॉजिस्टिक्स, और स्वास्थ्य देखभाल, जहाँ जानकारी का पुनः उपयोग अत्यंत महत्वपूर्ण है।
PDFs से पार्स की जा सकने वाली डेटा
PDFs से निकाली जा सकने वाली डेटा विविध और व्यापक है, जिसमें शामिल हैं:
-
पाठ अनुच्छेद: शब्दों और अक्षरों के अनुक्रम।
-
एकल डेटा फ़ील्ड: तिथियाँ, ट्रैकिंग नंबर, और नाम जैसे व्यक्तिगत तत्व।
-
तालिका डेटा: तालिकाओं और सूचियों में व्यवस्थित जानकारी।
-
छवियाँ: PDF के भीतर एम्बेडेड ग्राफिकल सामग्री।
-
उन्नत तत्व: हेडर, ऑब्जेक्ट, क्रॉस-रेफरेंस तालिकाएँ, ट्रेलर, और मेटाडेटा, जिन्हें अधिक उन्नत पार्सिंग उपकरणों की आवश्यकता होती है।
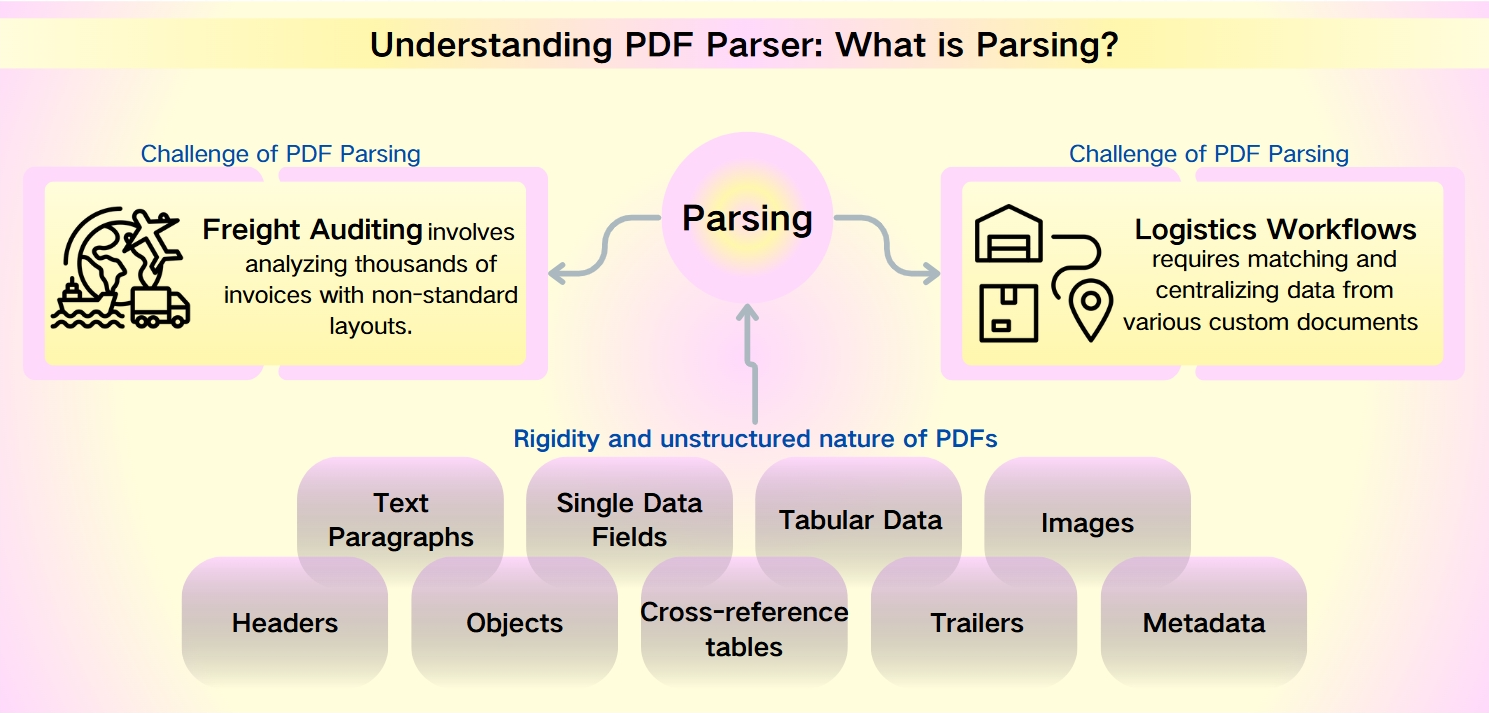
PDF पार्सिंग की चुनौतियाँ: PDF मेटाडेटा की असंरचित प्रकृति
PDFs की मजबूती के बावजूद—जो उनकी सुरक्षा, डिवाइस संगतता, और संकुचित फ़ाइल आकार द्वारा विशेषता है—इनसे डेटा निकालना एक कठिन चुनौती है। PDFs की कठोरता और असंरचित प्रकृति त्वरित विश्लेषण और सूचना पुनर्प्राप्ति में बाधा डालती है। यह विशेष रूप से उन परिदृश्यों में स्पष्ट है जैसे कि माल परिवहन ऑडिटिंग और लॉजिस्टिक्स कार्यप्रवाह, जहाँ गैर-मानक लेआउट और विशाल डेटा सेट जटिलता को बढ़ाते हैं।
माल परिवहन ऑडिटिंग में हजारों चालान का विश्लेषण करना शामिल होता है जिनमें गैर-मानक लेआउट होते हैं। लॉजिस्टिक्स कार्यप्रवाह में विभिन्न कस्टम दस्तावेजों जैसे पैकिंग सूचियों, वाणिज्यिक चालानों, और बिल ऑफ लाडिंग से डेटा मिलाना और केंद्रीकरण करना आवश्यक होता है।
पार्सिंग का महत्व
पार्सिंग विभिन्न क्षेत्रों में एक महत्वपूर्ण भूमिका निभाता है, वेब विकास से लेकर डेटा कैप्चर तक। यह व्यवसायों को असंरचित डेटा स्रोतों, जैसे PDF दस्तावेज़ों, HTML फ़ाइलों, और XML डेटा से मूल्यवान अंतर्दृष्टि निकालने में सक्षम बनाता है। पार्सिंग निम्नलिखित को सक्षम बनाता है:
-
डेटा-आधारित अंतर्दृष्टियों के माध्यम से बेहतर निर्णय लेना।
-
डेटा की सटीकता और स्थिरता में सुधार।
-
डेटा प्रसंस्करण और विश्लेषण को सरल बनाना।
-
सूचना पुनर्प्राप्ति और भंडारण में दक्षता।
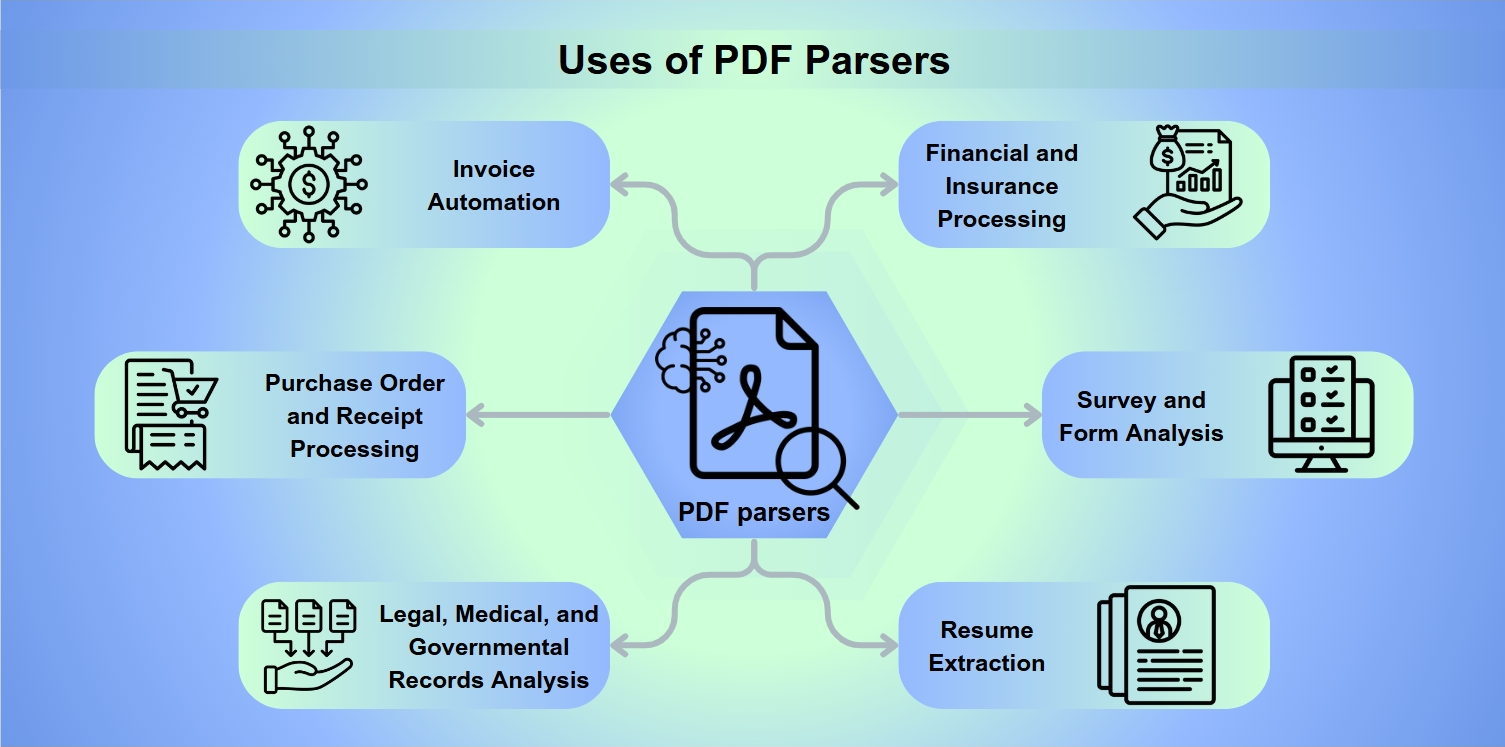
PDF पार्सर्स के उपयोग
PDF पार्सर्स विभिन्न अनुप्रयोगों में अनिवार्य उपकरण हैं, जिनमें शामिल हैं:
-
चालान स्वचालन: चालानों की प्रक्रिया और भुगतान को सरल बनाना।
-
खरीद आदेश और रसीद प्रसंस्करण: रिफंड और प्रतिपूर्ति को सुविधाजनक बनाना।
-
कानूनी, चिकित्सा, और सरकारी रिकॉर्ड विश्लेषण: विश्लेषण के लिए गहन डेटा निष्कर्षण को सक्षम बनाना।
-
वित्तीय और बीमा प्रसंस्करण: जोखिम का आकलन और बैलेंस शीट का विश्लेषण करना।
-
सर्वेक्षण और फॉर्म विश्लेषण: फॉर्म प्रतिक्रियाओं को एकत्र करना और व्याख्या करना।
-
रिज़्यूमे निष्कर्षण: भर्ती करने वालों को उम्मीदवारों की शॉर्टलिस्टिंग में सहायता करना।
विभिन्न पार्सिंग विधियों की तुलना
डेटा पार्सिंग विधियाँ समय के साथ काफी विकसित हुई हैं। डेटा कैप्चर के पारंपरिक दृष्टिकोण अक्सर पाठ से विशिष्ट पैटर्न निकालने के लिए नियमित अभिव्यक्तियों (regex) पर निर्भर करते हैं। जबकि यह शक्तिशाली है, regex जटिल हो सकता है और जटिल पार्सिंग कार्यों के लिए बनाए रखना कठिन हो सकता है। एक अन्य सामान्य तकनीक स्ट्रिंग मैनिपुलेशन है, जिसमें डिलीमीटर या विशिष्ट अक्षरों के आधार पर पाठ को विभाजित और संसाधित करना शामिल है। ये विधियाँ, हालांकि कुछ परिदृश्यों में अभी भी उपयोगी हैं, असंरचित या असंगत डेटा प्रारूपों के साथ संघर्ष कर सकती हैं।
PDF पार्सिंग का परिदृश्य विभिन्न विधियों द्वारा सेवा प्रदान किया जाता है, प्रत्येक के अपने अद्वितीय लाभ और हानियाँ:
-
ऑनलाइन PDF कन्वर्टर्स/पार्सर्स: जैसे Zamzar और Smallpdf, सुविधा और गति प्रदान करते हैं लेकिन कार्यक्षमता में सीमित होते हैं और संभावित रूप से असुरक्षित होते हैं।
-
Adobe Acrobat: संरचना और प्रारूप को बनाए रखता है लेकिन परिवर्तित करने के बाद मैनुअल समायोजन की आवश्यकता हो सकती है।
-
कॉपी और पेस्ट: पूर्ण नियंत्रण प्रदान करता है लेकिन श्रमसाध्य और त्रुटि-प्रवण होता है।
-
स्वचालित प्लेटफ़ॉर्म: आधुनिक पार्सिंग तकनीकें जैसे AnyParser मशीन लर्निंग और प्राकृतिक भाषा प्रसंस्करण (NLP) का उपयोग करती हैं ताकि अधिक जटिल डेटा संरचनाओं को संभाला जा सके।
ये AI-चालित दृष्टिकोण संदर्भ और अर्थ को समझ सकते हैं, जिससे वे असंरचित पाठ या विभिन्न प्रारूपों वाले दस्तावेज़ों के लिए विशेष रूप से प्रभावी बनते हैं। कुछ उन्नत पार्सर्स गहरे शिक्षण मॉडलों का उपयोग करते हैं ताकि प्रासंगिक जानकारी की पहचान और निष्कर्षण उच्च सटीकता के साथ किया जा सके, यहां तक कि पहले से अनदेखे दस्तावेज़ लेआउट से भी।
PDF पार्सिंग कैसे करें: PDF मेटाडेटा निकालने के लिए सर्वश्रेष्ठ मुफ्त PDF पार्सर
PDF मेटाडेटा को समझना
PDF मेटाडेटा दस्तावेज़ के बारे में महत्वपूर्ण जानकारी होती है, जिसमें इसका शीर्षक, लेखक, निर्माण तिथि, और कीवर्ड शामिल होते हैं। इस मेटाडेटा को कुशलतापूर्वक निकालना बड़े PDF फ़ाइल संग्रह को व्यवस्थित, खोजने और प्रबंधित करने के लिए आवश्यक है। एक मजबूत PDF पार्सर इस प्रक्रिया को सरल बना सकता है, समय बचा सकता है और कार्यप्रवाह की उत्पादकता में सुधार कर सकता है।
शीर्ष PDF पार्सर्स की प्रमुख विशेषताएँ
सर्वश्रेष्ठ मुफ्त PDF पार्सर्स सटीकता, गति, और बहुपरकारिता का संयोजन प्रदान करते हैं। उन्हें विभिन्न PDF प्रारूपों को संभालने में सक्षम होना चाहिए, जिसमें स्कैन किए गए दस्तावेज़ और जटिल लेआउट वाले दस्तावेज़ शामिल हैं। ऐसे पार्सर्स की तलाश करें जो न केवल बुनियादी मेटाडेटा निकाल सकें बल्कि कस्टम फ़ील्ड और छिपी हुई जानकारी भी निकाल सकें। इसके अलावा, शीर्ष श्रेणी के पार्सर्स अक्सर बैच प्रसंस्करण और अन्य सॉफ़्टवेयर सिस्टम के साथ एकीकरण के लिए PDF डेटा एक्सट्रैक्टर के विकल्प प्रदान करते हैं।
AnyParser की विशेषताएँ
CambioML द्वारा विकसित AnyParser विशेष रूप से इसकी सटीकता, गोपनीयता, और कॉन्फ़िगर करने की क्षमता के कारण उल्लेखनीय है। AnyParser की कई फ़ाइल प्रारूपों को संभालने की क्षमता, उपयोगकर्ता के अनुकूल इंटरफ़ेस, और इसकी स्केलेबिलिटी इसे सभी आकार के व्यवसायों के लिए एक उत्कृष्ट विकल्प बनाती है। इसके अलावा, इसका API मौजूदा कार्यप्रवाहों में निर्बाध एकीकरण की अनुमति देता है, कुल मिलाकर दस्तावेज़ प्रबंधन की दक्षता को बढ़ाता है। यहाँ कुछ प्रमुख विशेषताएँ हैं जो AnyParser को PDF पार्सिंग के लिए एक उत्कृष्ट विकल्प बनाती हैं:
-
सटीकता: AnyParser को मूल लेआउट और प्रारूप को बनाए रखते हुए पाठ, संख्याएँ, और प्रतीक सटीकता से निकालने के लिए डिज़ाइन किया गया है। यह दस्तावेज़ की समझ और जानकारी निष्कर्षण को बढ़ाने के लिए उन्नत भाषा मॉडल का उपयोग करता है, पारंपरिक OCR मॉडलों की तुलना में 2x उच्च सटीकता दर का दावा करता है।
-
गोपनीयता: यह ऑन-प्रेम और क्लाउड डेटा पार्सिंग दोनों का समर्थन करता है, यह सुनिश्चित करते हुए कि संवेदनशील जानकारी गोपनीय और सुरक्षित रहे।
-
कॉन्फ़िगर करने की क्षमता: उपयोगकर्ता विशिष्ट आवश्यकताओं के अनुसार निष्कर्षण नियम और आउटपुट प्रारूप को अनुकूलित कर सकते हैं।
-
बहु-स्रोत समर्थन: AnyParser विभिन्न दस्तावेज़ प्रकारों का समर्थन करता है, जिसमें PDFs, छवियाँ, और चार्ट शामिल हैं।
-
संरचित आउटपुट: निकाली गई जानकारी को Markdown, Excel या JSON जैसे संरचित प्रारूपों में परिवर्तित किया जा सकता है, जिससे आगे की प्रसंस्करण और विश्लेषण को सुविधाजनक बनाया जा सके।
-
क्लाउड-आधारित तैनाती विकल्प: AnyParser SDK को क्लाउड, डेटा केंद्रों, या निजी रूप से तैनात किया जा सकता है, लचीलापन और स्केलेबिलिटी प्रदान करता है।
-
उपयोगकर्ता के अनुकूल इंटरफ़ेस: उपकरण एक सरल API प्रदान करता है जो जटिल दस्तावेज़ पार्सिंग कार्यों को केवल कुछ पंक्तियों के कोड के साथ पूरा करने की अनुमति देता है।
-
उच्च प्रदर्शन: अनुकूलित एल्गोरिदम बड़ी संख्या में दस्तावेज़ों की तेज़ी से प्रसंस्करण सुनिश्चित करते हैं, सामान्यीकृत LLMs जैसे GPT4o की तुलना में 5X तेज़।
-
समुदाय समर्थन: एक ओपन-सोर्स प्रोजेक्ट के रूप में, AnyParser एक सक्रिय समुदाय से लाभान्वित होता है और योगदान का स्वागत करता है।
-
मुफ्त उपयोग कोटा: AnyParser प्रत्येक खाते के साथ एक मुफ्त उपयोग कोटा प्रदान करता है, जिससे उपयोगकर्ता उपकरण की क्षमताओं का परीक्षण कर सकते हैं इससे पहले कि वे भुगतान योजना में शामिल हों।
-
ग्राहक फीडबैक: उपयोगकर्ताओं ने AnyParser की उच्च सटीकता, गोपनीयता संरक्षण, और डेटा निष्कर्षण में दक्षता की प्रशंसा की है, केस स्टडीज़ में महत्वपूर्ण समय की बचत और डेटा गुणवत्ता में सुधार दिखाया गया है।
ये लाभ AnyParser को दस्तावेज़ पार्सिंग और जानकारी निष्कर्षण के लिए एक मूल्यवान PDF डेटा एक्सट्रैक्टर बनाते हैं, विशेष रूप से उन उद्यम उपयोगकर्ताओं के लिए जो उच्च सटीकता और सुरक्षा की आवश्यकता रखते हैं। निरंतर तकनीकी प्रगति और सक्रिय समुदाय की भागीदारी के साथ, AnyParser दस्तावेज़ पार्सिंग और जानकारी निष्कर्षण के क्षेत्र में एक महत्वपूर्ण भूमिका निभाने के लिए तैयार है।
PDF पार्सर्स का तकनीकी विवरण
PDF पार्सिंग वेब स्क्रैपिंग के साथ वैचारिक आधार साझा करता है, फिर भी इसमें HTML की संरचित पदानुक्रम की कमी होती है। जबकि वेब दस्तावेज़ों को सुलभ HTML टैग के माध्यम से पार्स किया जाता है, PDFs अक्षरों और पिक्सल के एक सपाट सरणी को प्रस्तुत करते हैं, जिसके लिए डेटा निष्कर्षण के लिए अधिक उन्नत एल्गोरिदम और पुस्तकालयों की आवश्यकता होती है।
PDF पार्सर बनाम Python PDF पार्सर: मुख्य अंतर
एक PDF पार्सर अक्सर एक स्वतंत्र उपकरण होता है या PDF फ़ाइलों से डेटा निकालने के लिए विशेष रूप से डिज़ाइन किया गया एक पुस्तकालय होता है। ये पार्सर्स आमतौर पर उपयोगकर्ता के अनुकूल इंटरफेस प्रदान करते हैं और न्यूनतम कोडिंग ज्ञान की आवश्यकता होती है। दूसरी ओर, Python PDF पार्सर्स ऐसे मॉड्यूल या पुस्तकालय होते हैं जो Python स्क्रिप्ट में एकीकृत होते हैं, अधिक लचीलापन प्रदान करते हैं लेकिन प्रोग्रामिंग विशेषज्ञता की मांग करते हैं।
डेवलपर्स पार्सिंग प्रक्रिया को ठीक कर सकते हैं, उन्नत पाठ विश्लेषण लागू कर सकते हैं, और PDF डेटा निष्कर्षण को व्यापक Python अनुप्रयोगों में निर्बाध रूप से एकीकृत कर सकते हैं। PDF पार्सर्स, जबकि Python PDF पार्सर की तुलना में अनुकूलन में अधिक सीमित होते हैं, अक्सर सामान्य उपयोग के मामलों के लिए पूर्व-निर्मित सुविधाएँ प्रदान करते हैं, जिससे वे उन उपयोगकर्ताओं के लिए आदर्श बनते हैं जिन्हें व्यापक प्रोग्रामिंग के बिना त्वरित परिणामों की आवश्यकता होती है।
AnyParser के साथ VLM के लाभ
-
उच्च सटीकता: AnyParser के VLMs यह सुनिश्चित करते हैं कि डेटा निष्कर्षण उच्च निष्ठा बनाए रखता है, यहां तक कि जटिल दस्तावेज़ लेआउट के साथ भी।
-
गति: यह रूपांतरण गति में अग्रणी है, दस्तावेज़ों को संसाधित करने के लिए आवश्यक समय को कम करके उत्पादकता बढ़ाता है।
-
उपयोगकर्ता के अनुकूल: AnyParser एक सरल इंटरफ़ेस प्रदान करता है, जिससे यह सभी स्तरों के उपयोगकर्ताओं के लिए सुलभ होता है।
-
बहुपरकारिता: PDFs के अलावा, AnyParser एक शक्तिशाली छवि से Excel कन्वर्टर के रूप में कार्य करता है, विभिन्न दस्तावेज़ प्रकारों का समर्थन करता है।
निष्कर्ष
PDF पार्सिंग केवल एक तकनीकी प्रक्रिया नहीं है; यह व्यवसायों के डेटा को संभालने के तरीके को बदलने का एक द्वार है। चुनौतियों के बावजूद, सॉफ़्टवेयर समाधानों का विकास इसे पहले से कहीं अधिक सुलभ बना चुका है। चाहे आप चालान प्रसंस्करण कर रहे हों या जटिल डेटा विश्लेषण, सही PDF पार्सर का चयन करना आवश्यक है। यह उस उपकरण को खोजने के बारे में है जो सटीकता, सुरक्षा, और दक्षता का सही संतुलन प्रदान करता है ताकि आपके डेटा-आधारित पहलों को सशक्त बनाया जा सके।
आज ही अपनी मुफ्त ट्रायल शुरू करें
क्या आप अपने दस्तावेज़ प्रसंस्करण में क्रांति लाने के लिए तैयार हैं? AnyParser को बिना किसी क्रेडिट कार्ड की आवश्यकता के लिए मुफ्त में आजमाएँ https://www.cambioml.com/sandbox। मुफ्त ट्रायल आपको प्रति दस्तावेज़ 10 पृष्ठों तक संसाधित करने की अनुमति देती है, अधिकतम फ़ाइल आकार 10MB है। अनुभव करें कि कैसे AnyParser का PDF पार्सर आपके असंरचित डेटा और दस्तावेज़ निष्कर्षण के दृष्टिकोण को बदल सकता है। इस अवसर को न चूकें अपने डेटा विश्लेषण क्षमताओं को बढ़ाने और अत्याधुनिक AI तकनीक के साथ अपने कार्यप्रवाह को सरल बनाने के लिए।