आज के डेटा-प्रेरित विश्व में, PDF प्रारूप से CSV प्रारूप में जटिल दस्तावेज़ों को परिवर्तित करना कई पेशेवरों के लिए एक महत्वपूर्ण कार्य है। यदि आप बैंक स्टेटमेंट, चिकित्सा रिपोर्ट, या शिपिंग ऑर्डर को PDF रूप में संभाल रहे हैं, तो आप शायद एक प्रभावी समाधान की तलाश में हैं।
यहां विज़न लैंग्वेज मॉडल (VLMs) हैं, जो पारंपरिक OCR विधियों को पार करते हुए एक अत्याधुनिक तकनीक है। दृश्य और संदर्भात्मक समझ का लाभ उठाकर, VLMs जटिल, संरचित दस्तावेज़ों को मशीन-पठनीय प्रारूपों में बदलने के लिए एक शक्तिशाली उपकरण प्रदान करते हैं।
यह गाइड आपको AnyParser का उपयोग करके अपने PDFs को CSV या Excel फ़ाइलों में परिवर्तित करने की प्रक्रिया के माध्यम से ले जाएगी, जिससे आपके कार्यप्रवाह को सरल बनाया जा सके और मूल्यवान डेटा अंतर्दृष्टियों को अनलॉक किया जा सके। AnyParser के साथ, आप आसानी से PDF को CSV, PDF को Excel, या यहां तक कि Word को CSV में कुछ ही क्लिक में परिवर्तित कर सकते हैं।
PDF से CSV रूपांतरण की मजबूत आवश्यकताएँ और पारंपरिक OCR मॉडलों की सीमाएँ
PDF से CSV रूपांतरण की बढ़ती मांग
आज के डेटा-प्रेरित विश्व में, PDF को CSV में परिवर्तित करने की आवश्यकता तेजी से महत्वपूर्ण होती जा रही है। व्यवसाय और व्यक्ति दोनों ही स्थिर PDF दस्तावेज़ों को गतिशील, विश्लेषणीय स्प्रेडशीट में बदलने के लिए प्रभावी तरीकों की तलाश कर रहे हैं। यह रूपांतरण प्रक्रिया विभिन्न दस्तावेज़ों जैसे बैंक स्टेटमेंट, चिकित्सा रिपोर्ट, और शिपिंग ऑर्डर से मूल्यवान जानकारी निकालने के लिए आवश्यक है। शब्द को एक्सेल में परिवर्तित करने की क्षमता या PDF से CSV कनवर्टर का उपयोग डेटा प्रबंधन और विश्लेषण प्रक्रियाओं को महत्वपूर्ण रूप से सरल बना सकता है।
पारंपरिक OCR प्रौद्योगिकी की कमियाँ
हालांकि पारंपरिक ऑप्टिकल कैरेक्टर रिकॉग्निशन (OCR) मॉडल लंबे समय से पाठ निकालने के लिए उपयोग किए जा रहे हैं, वे अक्सर जटिल दस्तावेज़ों के साथ काम करते समय असफल रहते हैं। ये सीमाएँ तब स्पष्ट होती हैं जब जटिल PDFs को Google Sheets या अन्य स्प्रेडशीट प्रारूपों में परिवर्तित करने का प्रयास किया जाता है। OCR सिस्टम निम्नलिखित में संघर्ष करते हैं:
- निम्न गुणवत्ता वाले स्कैन या छवियों को सटीक रूप से व्याख्या करना
- मल्टी-कॉलम लेआउट और तालिकाओं को संभालना
- विविध फ़ॉन्ट और भाषाओं को पहचानना
- मूल दस्तावेज़ संरचना को बनाए रखना
ये चुनौतियाँ अधिक उन्नत समाधानों की आवश्यकता को उजागर करती हैं जो PDF से CSV रूपांतरण प्रक्रिया को सहजता से संभाल सकें, मूल दस्तावेज़ों की सामग्री और संदर्भ दोनों को संरक्षित करते हुए।
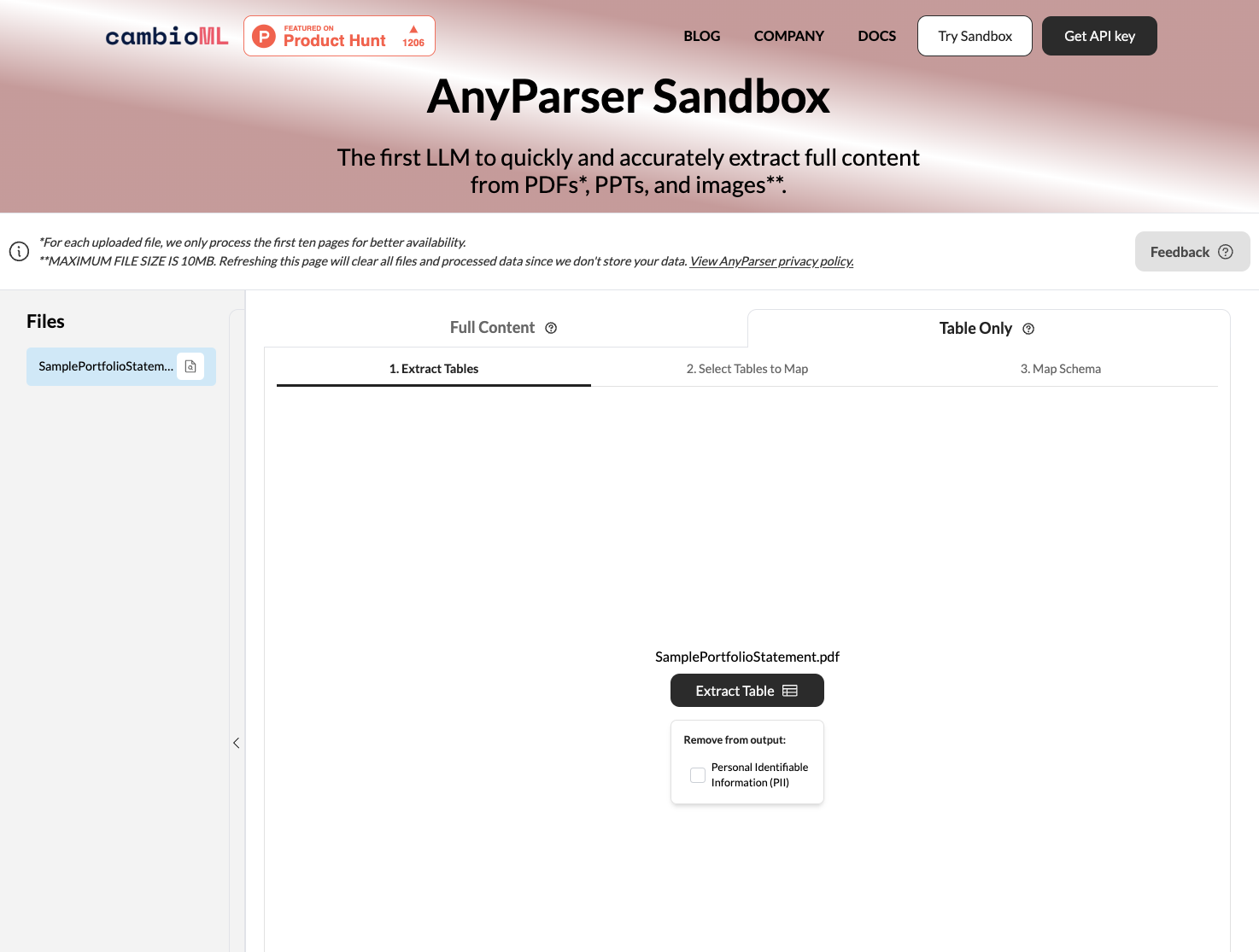
AnyParser का उपयोग करके PDF दस्तावेज़ों को परिवर्तित करने के लिए चरण-दर-चरण गाइड
AnyParser एक शक्तिशाली PDF से CSV रूपांतरण उपकरण है जो जटिल PDF दस्तावेज़ों से डेटा को सटीक रूप से निकालने के लिए उन्नत विज़न लैंग्वेज मॉडल का लाभ उठाता है। यहां AnyParser का उपयोग करके अपने PDF फ़ाइलों को परिवर्तित करने के लिए मूलभूत चरण दिए गए हैं:
-
अपने PDF या Word को अपलोड करें। बस अपने PDF दस्तावेज़ों को AnyParser के वेब इंटरफ़ेस में खींचें और छोड़ें या आप PDF स्क्रीनशॉट को AnyParser UI में पेस्ट कर सकते हैं।
-
"केवल तालिका" चुनें और "निकालें" पर क्लिक करें। AnyParser API इंजन स्वचालित रूप से PDF में तालिकाओं का पता लगाएगा और उन्हें उच्च सटीकता के साथ निकालेगा। निकाला गया डेटा एक .csv फ़ाइल में संग्रहीत होता है जिसे आप केवल एक क्लिक में डाउनलोड या Google Sheets में निर्यात कर सकते हैं।
-
पूर्वावलोकन और तुलना करें। निकाले गए डेटा की पूर्वावलोकन में समीक्षा करें ताकि यह सुनिश्चित हो सके कि यह आपकी अपेक्षाओं के अनुरूप है। AnyParser के प्रारंभिक निष्कर्ष का पूर्वावलोकन करें और UI पर साइड-बाय-साइड तुलना करें।
-
CSV या Excel में निर्यात करें। एक बार जब आप निष्कर्षण से संतुष्ट हो जाएं, तो अपने अनुप्रयोगों और सिस्टम में डेटा का उपयोग करने के लिए .csv फ़ाइल डाउनलोड करें। निकाला गया डेटा स्प्रेडशीट और डेटाबेस में आगे के विश्लेषण के लिए आसानी से आयात किया जा सकता है।
इन सरल चरणों का पालन करके और विज़न लैंग्वेज मॉडल की शक्ति का लाभ उठाकर, AnyParser आपको जटिल PDF दस्तावेज़ों को संरचित, संपादनीय CSV फ़ाइलों में कुशलतापूर्वक परिवर्तित करने में सक्षम बनाता है जिन्हें आप अपने कार्यप्रवाह में विश्लेषण और एकीकृत कर सकते हैं।
इस वीडियो को देखें ताकि आप चरण-दर-चरण वीडियो डेमो देख सकें!
PDF से CSV/Excel रूपांतरण के लिए VLM के वास्तविक-विश्व अनुप्रयोग
विज़न लैंग्वेज मॉडल (VLMs) PDF को CSV और एक्सेल प्रारूपों में परिवर्तित करने के तरीके में क्रांति ला रहे हैं, विभिन्न उद्योगों के लिए शक्तिशाली समाधान प्रदान कर रहे हैं। इन उन्नत मॉडलों का लाभ उठाकर, आप जटिल दस्तावेज़ों को संरचित, मशीन-पठनीय डेटा में कुशलतापूर्वक परिवर्तित कर सकते हैं।
वित्तीय दस्तावेज़ प्रसंस्करण
बैंकिंग क्षेत्र में, VLMs बैंक स्टेटमेंट के लिए PDF को CSV में परिवर्तित करने में उत्कृष्ट हैं। ये मॉडल लेन-देन विवरण, खाता नंबर, और बैलेंस जानकारी को सटीकता से निकाल सकते हैं, यहां तक कि जटिल लेआउट या कई मुद्राओं वाले दस्तावेज़ों से भी। यह क्षमता वित्तीय विश्लेषण और सामंजस्य प्रक्रियाओं को सरल बनाती है।
चिकित्सा रिकॉर्ड प्रबंधन
स्वास्थ्य पेशेवरों के लिए, VLMs चिकित्सा रिपोर्टों के लिए शब्द को एक्सेल में परिवर्तित करने के लिए एक अमूल्य उपकरण प्रदान करते हैं। जटिल चिकित्सा शब्दावली की सटीक व्याख्या करके और प्रयोगशाला परिणामों की संरचना को बनाए रखकर, VLMs व्यापक रोगी डेटाबेस बनाने की सुविधा प्रदान करते हैं। यह रूपांतरण प्रवृत्ति विश्लेषण को आसान बनाता है और रोगी देखभाल में सुधार करता है।
लॉजिस्टिक्स और आपूर्ति श्रृंखला अनुकूलन
लॉजिस्टिक्स उद्योग में, VLMs शिपिंग ऑर्डर को PDF से Google Sheets में परिवर्तित करते समय चमकते हैं। ये मॉडल महत्वपूर्ण जानकारी जैसे डिलीवरी पते, आइटम विवरण, और ट्रैकिंग नंबर निकाल सकते हैं, तालिका डेटा की अखंडता बनाए रखते हुए। यह रूपांतरण कुशल इन्वेंटरी प्रबंधन और मार्ग अनुकूलन की अनुमति देता है।
VLMs द्वारा संचालित PDF से CSV कनवर्टर का उपयोग करके, आप विभिन्न क्षेत्रों में डेटा प्रसंस्करण की दक्षता को महत्वपूर्ण रूप से बढ़ा सकते हैं। ये उन्नत मॉडल बहुभाषी दस्तावेज़ों, जटिल लेआउट, और यहां तक कि निम्न गुणवत्ता वाले स्कैन को संभालने में बेजोड़ सटीकता प्रदान करते हैं, जिससे वे आधुनिक व्यवसायों के लिए एक अनिवार्य उपकरण बन जाते हैं।
OCR चुनौतियों को पार करने के लिए विज़न लैंग्वेज मॉडल कैसे काम करते हैं
विज़न लैंग्वेज मॉडल (VLMs) PDF को CSV में परिवर्तित करने और जटिल दस्तावेज़ों को मशीन-पठनीय प्रारूपों में बदलने के तरीके में क्रांति ला रहे हैं। पारंपरिक OCR के विपरीत, VLMs दृश्य और भाषाई समझ दोनों का लाभ उठाते हैं ताकि दस्तावेज़ रूपांतरण के सबसे चुनौतीपूर्ण पहलुओं का सामना किया जा सके।
जटिल लेआउट की व्याख्या करना
VLMs जटिल दस्तावेज़ संरचनाओं को समझने में उत्कृष्ट हैं, जिससे वे शब्द को एक्सेल में परिवर्तित करने या विभिन्न प्रारूपों वाले बैंक स्टेटमेंट को संभालने के लिए आदर्श बन जाते हैं। पाठ तत्वों के बीच स्थानिक संबंधों का विश्लेषण करके, VLMs तालिकाओं को सटीक रूप से पुनर्निर्माण कर सकते हैं और लेआउट की अखंडता बनाए रख सकते हैं। उदाहरण के लिए, VLMs एक PDF को सही ढंग से व्याख्या कर सकते हैं जिसमें एक चालान है जिसमें विभिन्न कॉलम और पंक्तियों की संख्या वाली कई तालिकाएँ हैं, जबकि पारंपरिक OCR पंक्तियों और कॉलमों को गड़बड़ कर देगा।
संदर्भात्मक समझ
VLMs का एक प्रमुख लाभ यह है कि वे दस्तावेज़ सामग्री के अर्थ को समझने में सक्षम हैं। यह संदर्भात्मक जागरूकता PDF से CSV कनवर्टर का उपयोग करते समय अधिक सटीक निष्कर्षण की अनुमति देती है, विशेष रूप से डोमेन-विशिष्ट दस्तावेज़ों जैसे चिकित्सा CBC रिपोर्ट या लॉजिस्टिक्स शिपिंग ऑर्डर के लिए। उदाहरण के लिए, VLMs चिकित्सा रिपोर्टों को उनके सामग्री के आधार पर विशेषज्ञता द्वारा सही ढंग से वर्गीकृत कर सकते हैं, यहां तक कि "ल्यूकोसाइट" की गिनती को "सफेद रक्त कोशिकाएं (WBCs)" की गिनती के रूप में समझ सकते हैं!
बहुभाषी क्षमता
VLMs एक ही दस्तावेज़ के भीतर कई स्क्रिप्ट और भाषाओं को सहजता से संभालकर भाषा की बाधाओं को तोड़ते हैं। यह उन्हें अंतरराष्ट्रीय व्यवसायों के लिए विशेष रूप से उपयोगी बनाता है जो विविध दस्तावेज़ प्रकारों के साथ काम कर रहे हैं। उदाहरण के लिए, VLMs एक PDF से डेटा निकाल सकते हैं जिसमें अंग्रेजी और फ्रेंच दोनों में पाठ है।
शोर में कमी
निम्न गुणवत्ता वाले स्कैन या छवियाँ अक्सर पारंपरिक OCR सिस्टम के लिए चुनौतियाँ पेश करती हैं। हालाँकि, VLMs प्रभावी रूप से शोर को फ़िल्टर कर सकते हैं और प्रासंगिक जानकारी पर ध्यान केंद्रित कर सकते हैं, यह सुनिश्चित करते हुए कि दस्तावेज़ों को Google Sheets या अन्य प्रारूपों में परिवर्तित करते समय उच्च गुणवत्ता का आउटपुट मिले। उदाहरण के लिए, VLMs धुंधले या फीके PDF दस्तावेज़ से डेटा को सटीकता से निकाल सकते हैं।
VLM का उपयोग करके PDF को CSV में परिवर्तित करने पर अक्सर पूछे जाने वाले प्रश्न
VLM-आधारित रूपांतरण पारंपरिक OCR से कैसे भिन्न है?
विज़न लैंग्वेज मॉडल (VLMs) PDF को CSV या Excel में परिवर्तित करते समय पारंपरिक OCR की तुलना में महत्वपूर्ण लाभ प्रदान करते हैं। OCR के विपरीत, VLMs जटिल लेआउट को सटीकता से व्याख्या कर सकते हैं, संदर्भ को समझ सकते हैं, और कई भाषाओं को सहजता से संभाल सकते हैं। यह उन्हें बैंक स्टेटमेंट, चिकित्सा CBC रिपोर्ट, और लॉजिस्टिक्स शिपिंग ऑर्डर को मशीन-पठनीय प्रारूपों में परिवर्तित करने के लिए आदर्श बनाता है।
किस प्रकार के दस्तावेज़ VLM रूपांतरण के लिए सबसे अच्छे होते हैं?
VLMs तालिकाओं, चार्टों, और मिश्रित सामग्री वाले संरचित दस्तावेज़ों को परिवर्तित करने में उत्कृष्ट होते हैं। वे वित्तीय स्टेटमेंट, चिकित्सा रिपोर्ट, और शिपिंग मैनिफेस्ट के लिए विशेष रूप से प्रभावी हैं। VLMs द्वारा संचालित PDF से CSV कनवर्टर तालिका की अखंडता बनाए रख सकता है और निम्न गुणवत्ता वाले स्कैन या जटिल बहुभाषी दस्तावेज़ों से डेटा निकाल सकता है।
VLM-आधारित रूपांतरण की सटीकता मैनुअल डेटा प्रविष्टि की तुलना में कितनी है?
AnyParser जैसे VLM-आधारित समाधान मैनुअल डेटा प्रविष्टि या पारंपरिक OCR की तुलना में सटीकता में महत्वपूर्ण सुधार कर सकते हैं। दृश्य और संदर्भात्मक समझ का लाभ उठाकर, ये उपकरण शब्द को एक्सेल या PDF को Google Sheets में परिवर्तित करते समय त्रुटियों को 50% तक कम कर सकते हैं। यह सटीकता वित्तीय, चिकित्सा, और लॉजिस्टिक्स अनुप्रयोगों में डेटा की अखंडता बनाए रखने के लिए महत्वपूर्ण है।
क्या VLMs PDF के अलावा विभिन्न फ़ाइल प्रारूपों को संभाल सकते हैं?
हाँ, उन्नत VLM-आधारित उपकरण विभिन्न फ़ाइल प्रारूपों को संसाधित कर सकते हैं। जबकि PDF से CSV रूपांतरण सामान्य है, ये मॉडल छवियों, Word दस्तावेज़ों, PowerPoint प्रस्तुतियों, और स्कैन किए गए दस्तावेज़ों से भी डेटा निकाल सकते हैं। यह बहुपरकारिता VLMs को विभिन्न उद्योगों में व्यापक दस्तावेज़ प्रसंस्करण आवश्यकताओं के लिए एक शक्तिशाली समाधान बनाती है।
निष्कर्ष
जब आप PDF से CSV रूपांतरण के लिए विज़न लैंग्वेज मॉडल का लाभ उठाने की शुरुआत करते हैं, तो याद रखें कि सफलता एक सुव्यवस्थित दृष्टिकोण में निहित है। मजबूत पूर्व-प्रसंस्करण, सटीक दस्तावेज़ वर्गीकरण, और गहन पोस्ट-प्रसंस्करण को लागू करके, आप अपने डेटा निष्कर्षण आवश्यकताओं के लिए VLMs की पूरी क्षमता का लाभ उठा सकते हैं। चाहे आप जटिल बैंक स्टेटमेंट, जटिल चिकित्सा रिपोर्ट, या विस्तृत शिपिंग ऑर्डर से निपट रहे हों, VLMs अव्यवस्थित डेटा को क्रियाशील अंतर्दृष्टियों में बदलने के लिए एक शक्तिशाली समाधान प्रदान करते हैं। इस अत्याधुनिक तकनीक को अपनाएं ताकि आप अपने कार्यप्रवाह को सरल बना सकें, डेटा की सटीकता को बढ़ा सकें, और दस्तावेज़ प्रसंस्करण में नई संभावनाओं को अनलॉक कर सकें। VLMs के साथ, आप सबसे चुनौतीपूर्ण PDF रूपांतरण कार्यों को कुशलता से और प्रभावी ढंग से संभालने के लिए अच्छी तरह से तैयार हैं।
कार्रवाई के लिए कॉल
आइए इन अंतर्दृष्टियों को लागू करके आगे बढ़ें। विज़न लैंग्वेज मॉडल में विशेषज्ञों से संपर्क करने पर विचार करें जैसे कि AnyParser की टीम:
- https://www.cambioml.com/sandbox पर अपने PDF को CSV में परिवर्तित करने के लिए AnyParser का मुफ्त में प्रयास करें
- यदि आप बड़ी मात्रा में PDF को Excel में बदलने के लिए नो-कोड अनुभव पसंद करते हैं, तो https://www.energent.ai देखें
- जानें कि VLMs आपके डेटा निष्कर्षण कार्यप्रवाह को कैसे सुधार सकते हैं, इस पर मुफ्त परामर्श प्राप्त करें
विज़न लैंग्वेज मॉडल की पूरी शक्ति का लाभ उठाने के लिए रूपांतरण विशेषज्ञों के अनुभव और सर्वोत्तम प्रथाओं का लाभ उठाना आवश्यक है। एक अधिक स्वचालित, सटीक और अंतर्दृष्टिपूर्ण डेटा निष्कर्षण प्रक्रिया में संक्रमण को तेज करने के लिए उद्योग के नेताओं के साथ जुड़ने के लिए अगला कदम उठाएं।