जटिल PDFs को Markdown में परिवर्तित करना चुनौतीपूर्ण हो सकता है। PDF से टेक्स्ट निकालने के लिए कई ओपन-सोर्स पुस्तकालय उपलब्ध हैं, लेकिन जब बात जटिल तत्वों जैसे तालिकाओं और चार्ट्स वाले PDFs की होती है, तो परिणाम अक्सर असंतोषजनक होते हैं। लोकप्रिय बड़े भाषा मॉडल जैसे GPT या Claude इन कार्यों को संभाल सकते हैं लेकिन आमतौर पर धीमे होते हैं और कभी-कभी गलत आउटपुट उत्पन्न करते हैं। पारंपरिक OCR उपकरण, जबकि सरल दस्तावेजों के लिए प्रभावी होते हैं, अक्सर मूल सामग्री की सटीक संरचना और अर्थ को बनाए रखने में संघर्ष करते हैं। दूसरी ओर, दृष्टि-भाषा मॉडल कभी-कभी भ्रमित होते हैं, जिससे गलत पार्सिंग परिणाम निकलते हैं। यह ब्लॉग पार्स का अर्थ समझाएगा और विभिन्न मेट्रिक्स का उपयोग करके कई मॉडलों के तुलनात्मक विश्लेषण के परिणामों का विवरण देगा।
पार्स का क्या अर्थ है?
PDF पार्सिंग के संदर्भ में, "पार्स" का अर्थ है PDF फ़ाइल से विशिष्ट डेटा निकालने की प्रक्रिया, जिसे PDF पार्सर के रूप में जाने जाने वाले विशेष सॉफ़्टवेयर का उपयोग करके किया जाता है। एक PDF पार्सर PDF दस्तावेज़ की सामग्री का विश्लेषण करता है और टेक्स्ट, चित्र, फ़ॉन्ट, लेआउट और यहां तक कि मेटाडेटा जैसे तत्वों की पहचान करता है। निकाला गया डेटा फिर विभिन्न प्रारूपों जैसे XML, JSON, या Excel/CSV में व्यवस्थित और निर्यात किया जा सकता है, जिसका उपयोग डेटा विश्लेषण, रिकॉर्ड रखने, या कार्यप्रवाह के स्वचालन के लिए किया जा सकता है।
पार्स का क्या अर्थ है, यह समझना एक पार्सिंग समाधान की प्रभावशीलता का मूल्यांकन करने के लिए आवश्यक है, विशेष रूप से PDF से Markdown रूपांतरण उपकरणों की तुलना करते समय, क्योंकि PDF पार्सर केवल सरल टेक्स्ट निष्कर्षण से अधिक है—यह दस्तावेज़ की अर्थात्मक संरचना को पहचानने और बनाए रखने की आवश्यकता होती है।
हम इन पार्सिंग समाधानों की गुणवत्ता को कैसे मापते हैं?
हमने विभिन्न मॉडलों के प्रदर्शन का आकलन करने के लिए शब्द-स्तरीय मेट्रिक्स की एक श्रृंखला को परिभाषित किया है, जिसमें प्रमुख कारकों पर ध्यान केंद्रित किया गया है जैसे:
-
सटीकता, पुनःकाल, और F-माप: पार्सिंग की गुणवत्ता और पूर्णता का मूल्यांकन करना।
-
BLEU स्कोर और ANLS: भाषा और लेआउट संरचना का मूल्यांकन करने के लिए उपयोगी।
-
एडिट डिस्टेंस, जेन्सन-शैनन डाइवर्जेंस, और जैकार्ड डिस्टेंस: OCR क्षेत्र के लिए विशिष्ट मेट्रिक्स, विशेष रूप से सामग्री पुनरुत्पादन की सटीकता को समझने में सहायक।
हमारा दृष्टि-भाषा मॉडल, AnyParser, असाधारण प्रदर्शन प्रदर्शित करता है, विशेष रूप से तालिकाओं और अर्थात्मक तत्वों वाले जटिल लेआउट पर गति और सटीकता को संयोजित करता है। AnyParser अन्य समाधानों की तुलना में बेहतर प्रदर्शन करता है, GPT/Claude जैसे मॉडलों की तुलना में 20x गति में सुधार प्रदान करते हुए उच्च सटीकता प्राप्त करता है।
प्रमुख पार्सिंग मॉडलों के खिलाफ विस्तृत तुलना परिणाम
सांख्यिकीय वस्तु
AnyParser की क्षमताओं को सही ढंग से प्रदर्शित करने के लिए, हमने उद्योग में प्रमुख पार्सिंग मॉडलों और प्रसिद्ध बड़े भाषा मॉडलों (LLMs) के खिलाफ एक विस्तृत तुलना की। हमारे मूल्यांकन में शामिल थे:
1. बड़े भाषा मॉडल
- AnyParser
- OpenAI का GPT-4o
- Google का Gemini 1.5 Pro
- Anthropic का Claude 3.5 Sonnet
2. OCR-आधारित सेवाएँ
- LlamaParse
- Amazon Textract
- Google Cloud Document AI
- Azure Document Intelligence
परिणाम प्रस्तुति और विश्लेषण
प्रयोग 1
पहले, हम विभिन्न दस्तावेज़ AI मॉडलों के प्रदर्शन की एक श्रृंखला का कठोर तुलना करते हैं, जो नीचे 5 मेट्रिक्स पर आधारित हैं: BLEU, सटीकता और पुनःकाल, F-माप और ANLS। आप इन परिभाषाओं की गणितीय परिभाषा परिशिष्ट में पा सकते हैं।
तुलना किए गए मॉडल हैं: AnyParser-base, AnyParser-pro, Textract, Llama-Parse, GPT4o, Gemini-1.5-pro, GCP-DocAl, और Azure-DocAl।
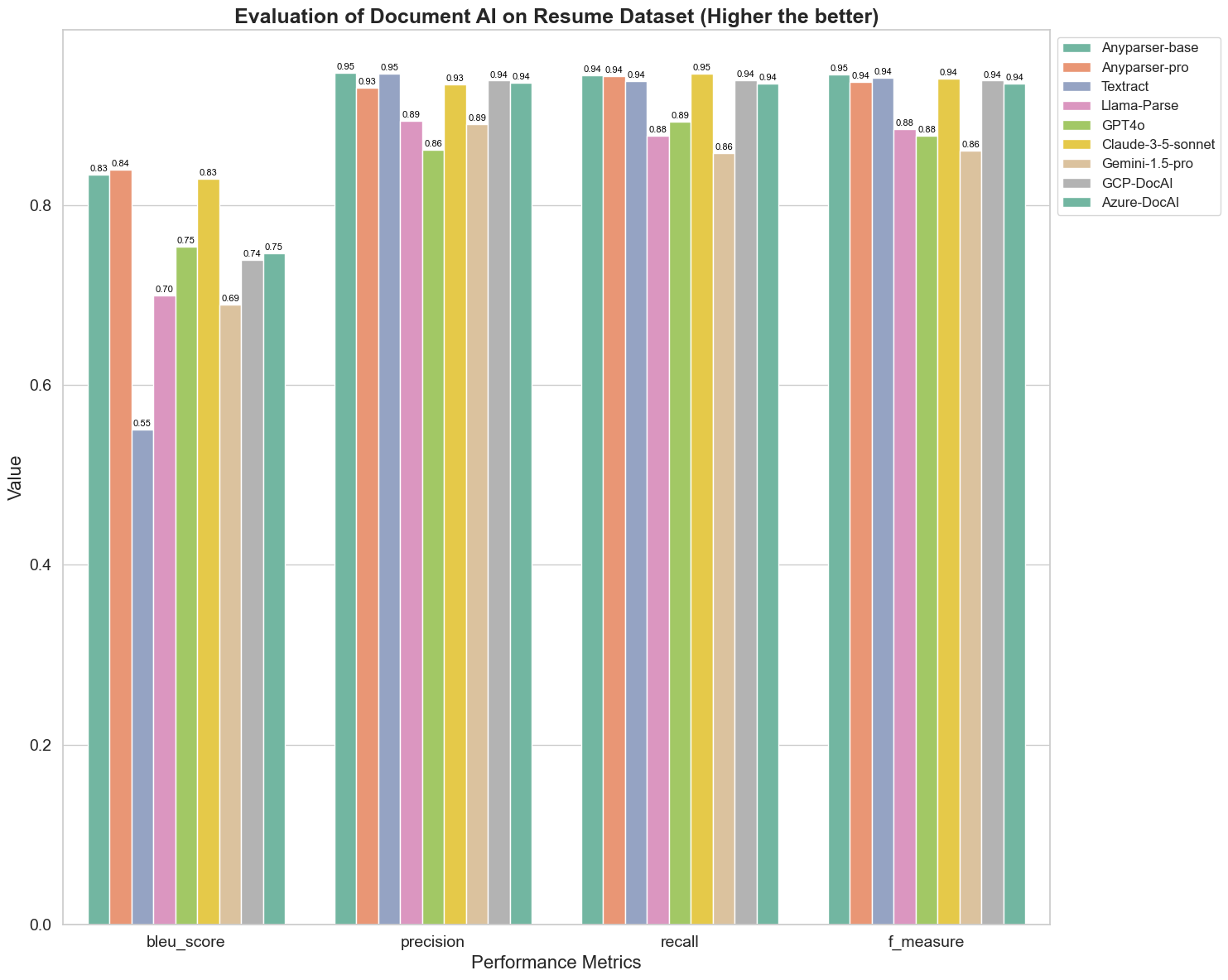
BLEU का उपयोग द्विभाषी व्याख्या की गुणवत्ता के आकलन के रूप में किया जाता है ताकि यह परीक्षण किया जा सके कि मॉडल वाक्यांशों को संसाधित करने में कितने सक्षम हैं। इन पार्सिंग मॉडलों के BLEU आकलन विधि के तहत परिणामों की तुलना करने पर, हम पाते हैं कि: AnyParser-base और AnyParser-pro के स्कोर अन्य मॉडलों के स्कोर की तुलना में काफी अधिक हैं, Amazon Textract का स्कोर सबसे कम है, और अन्य मॉडलों के स्कोर का परिणाम एक अपेक्षाकृत औसत स्तर के बीच में है।
पहचान सटीकता आमतौर पर सटीकता और पुनःकाल द्वारा दर्शाई जाती है, जहां सटीकता उन परिणामों में से सही परिणामों का प्रतिशत है जिन्हें मॉडल द्वारा सही माना गया है, और पुनःकाल उन सभी वास्तव में सही परिणामों में से सही रूप से न्याय किए गए परिणामों का प्रतिशत है। इन पार्सिंग मॉडलों की सटीकता और पुनःकाल की तुलना करने पर, हम पाते हैं कि: Llama-Parse, GPT4o और Gemini-1.5-pro को छोड़कर, सभी अन्य मॉडल उच्च स्तर पर हैं। इनमें, AnyParser और Amazon Textract सटीकता में अधिक प्रमुख हैं, और AnyParser-base और AnyParser-pro पुनःकाल में अधिक प्रमुख हैं। मॉडल का सटीकता पर उच्च स्कोर यह दर्शाता है कि मॉडल उत्पादन परिणामों में अधिक सही जानकारी प्रदान करता है, और पुनःकाल पर उच्च स्कोर यह दर्शाता है कि मॉडल नमूने से सही जानकारी प्राप्त करने में अधिक सक्षम है। स्कोर के परिणाम यह दर्शाते हैं कि AnyParser के पास PDF से टेक्स्ट निकालने के संदर्भ में पहचान सटीकता में स्पष्ट लाभ है।
F-माप इन दोनों संकेतकों पर सटीकता और पुनःकाल का एक समग्र मूल्यांकन सूचकांक है। F-माप के तहत इन पार्सिंग मॉडलों के स्कोर की तुलना करने पर, हम अधिक स्पष्ट रूप से देख सकते हैं कि पांच मॉडल, AnyParser-base, AnyParser-pro, Amazon Textract, GCP-DocAI और Azure-DocAI, अन्य मॉडलों की तुलना में पहचान सटीकता के मामले में बेहतर हैं। हम अधिक स्पष्ट रूप से देख सकते हैं कि ये पांच मॉडल अन्य मॉडलों की तुलना में पहचान सटीकता में अधिक मजबूत हैं, और AnyParser F-माप के तहत सबसे उच्च स्कोर प्राप्त करता है, जो PDF से टेक्स्ट निकालने में AnyParser के स्पष्ट लाभ को और स्पष्ट करता है।
ANLS, मूल टेक्स्ट और लक्षित टेक्स्ट के बीच वर्ण स्तर पर सटीकता और समानता को मापने के लिए एक सामान्य रूप से उपयोग किया जाने वाला मूल्यांकन सूचकांक है, जो मॉडलों के पार्सिंग स्तर को मापने के लिए भी बहुत सूचनात्मक है। AnyParser-base, AnyParser-pro और Azure-DocAI के उच्च स्कोर इन मॉडलों के पार्सिंग स्तर को अन्य मॉडलों की तुलना में दर्शाते हैं।
कुल मिलाकर, AnyParser-base और AnyParser-pro अन्य मॉडलों की तुलना में बेहतर प्रदर्शन करते हैं।
प्रयोग 2
हम Edit Distance, Jensen-Shannon Divergence, और Jaccard Distance पर विभिन्न दस्तावेज़ AI मॉडलों के प्रदर्शन की भी तुलना करते हैं। ये मेट्रिक्स मॉडल के आउटपुट और एक संदर्भ दस्तावेज़ के बीच समानता को मापने के लिए उपयोग किए जाते हैं। निम्न मान बेहतर प्रदर्शन का संकेत देते हैं।
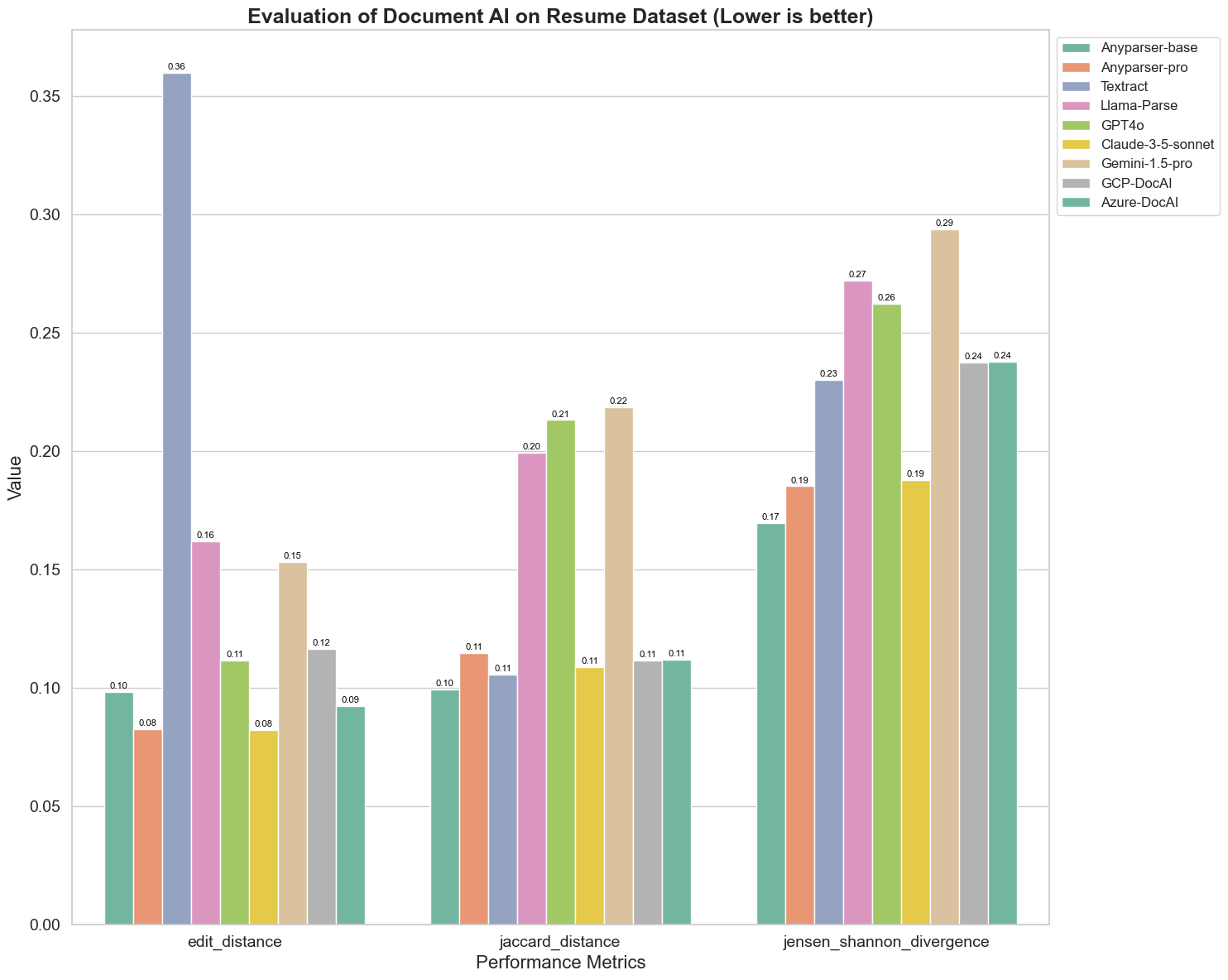
चार्ट से कुछ प्रमुख अवलोकन इस प्रकार हैं:
-
Edit Distance: मॉडल AnyParser-base और AnyParser-pro सबसे अच्छे प्रदर्शन करते हैं, जिनका एडिट डिस्टेंस सबसे कम है, यह सुझाव देता है कि उनका आउटपुट संदर्भ दस्तावेज़ के सबसे करीब था।
-
Jensen-Shannon Divergence: मॉडल AnyParser-base और AnyParser-pro का डाइवर्जेंस सबसे कम है, यह संकेत करता है कि उनके आउटपुट संदर्भ दस्तावेज़ के शब्द वितरण के मामले में सबसे समान हैं।
-
Jaccard Distance: Llama-parse, GPT4O, Gemini-1.5 को छोड़कर, सभी अन्य मॉडल अच्छे प्रदर्शन करते हैं जिनका Jaccard डिस्टेंस सबसे कम है, यह संकेत करता है कि उनके आउटपुट संदर्भ दस्तावेज़ के साथ शब्दों के सेट के मामले में सबसे अधिक ओवरलैप करते हैं।
निष्कर्ष
कुल मिलाकर, हमारे कठोर परीक्षण यह सुझाव देते हैं कि AnyParser-base और AnyParser-pro सामान्यतः विभिन्न मेट्रिक्स में अच्छा प्रदर्शन करते हैं, जो इसके सटीक दस्तावेज़ प्रसंस्करण की क्षमता को दर्शाता है। ग्राफ से, हम देख सकते हैं कि पारंपरिक OCR मॉडल जैसे प्रसिद्ध Amazon Textract दृष्टि भाषा मॉडलों की तुलना में बहुत कम स्कोर करते हैं। हालाँकि, विभिन्न मॉडलों का प्रदर्शन उपयोग किए गए मेट्रिक्स के आधार पर भिन्न होता है, जो AI मॉडलों की तुलना करते समय कई मूल्यांकन मानदंडों पर विचार करने के महत्व को उजागर करता है।
हमारे ओपन-सोर्स मूल्यांकन पाइपलाइन का परिचय
मूल्यांकन को सरल बनाने के लिए, हमने एक मूल्यांकन पाइपलाइन बनाई है जो पार्सिंग मॉडलों की तुलना के लिए एक उद्योग-मानक विधि प्रदान करती है। हमारे उदाहरण में, हम इसका उपयोग HR क्षेत्र में करते हैं, जहां रिज़्यूमे पार्सिंग सामान्य है। हमने 128 रिज़्यूमे का एक विविध सिंथेटिक डेटासेट बनाया, जो जोड़े गए इमेज-मार्कडाउन फ़ाइलों का उपयोग करके उत्पन्न किया गया। GPT-4 का उपयोग करके, हमने HTML सामग्री उत्पन्न की, इसे छवियों में प्रस्तुत किया, और तुलना के लिए निकाले गए टेक्स्ट को ग्राउंड ट्रुथ के रूप में उपयोग किया।
और यहाँ सबसे अच्छी बात है: हमने इस मूल्यांकन ढांचे को GitHub पर ओपन-सोर्स किया है! चाहे आप एक डेवलपर हों या एक व्यवसाय उपयोगकर्ता, हमारी पाइपलाइन आपको अपने स्वयं के डेटासेट पर विभिन्न मॉडलों की पार्सिंग गुणवत्ता का मूल्यांकन और तुलना करने में सक्षम बनाती है।
Github repo में त्वरित प्रारंभ गाइड खोजें और देखें कि विभिन्न पार्सिंग मॉडल एक-दूसरे के खिलाफ कैसे खड़े होते हैं। हमें विश्वास है कि हमारे मॉडल की ताकत को सार्वजनिक रूप से प्रदर्शित करके, हम अधिक उपयोगकर्ताओं को आकर्षित कर सकते हैं जो विश्वसनीय, तेज, और सटीक पार्सिंग क्षमताएँ चाहते हैं।
परिशिष्ट - मेट्रिक्स
1. सटीकता
सटीकता पार्स की गई सामग्री की सटीकता को मापती है, यह दिखाते हुए कि कितने निकाले गए तत्व सही थे। पार्सिंग में, यह उन सभी शब्दों में से सही निकाले गए शब्दों का अनुपात है।
सटीकता = सही सकारात्मक (TP) / (सही सकारात्मक (TP) + गलत सकारात्मक (FP))
- सही सकारात्मक (TP): वे शब्द जो पार्सर द्वारा सही ढंग से पहचाने गए।
- गलत सकारात्मक (FP): वे शब्द जो पार्सर द्वारा गलत ढंग से पहचाने गए।
2. पुनःकाल
पुनःकाल पार्सिंग की पूर्णता को दर्शाता है, या यह कि मूल दस्तावेज़ से कितने प्रासंगिक शब्द निकाले गए।
पुनःकाल = सही सकारात्मक (TP) / (सही सकारात्मक (TP) + गलत नकारात्मक (FN))
- गलत नकारात्मक (FN): मूल दस्तावेज़ में वे शब्द जो पार्सर द्वारा छूट गए।
3. F-माप (F1 स्कोर)
F1 स्कोर सटीकता और पुनःकाल का हार्मोनिक माध्य है, दोनों मेट्रिक्स को संतुलित करते हुए पार्सिंग गुणवत्ता का एक समग्र माप प्रदान करता है।
F1 स्कोर = 2 × (सटीकता × पुनःकाल) / (सटीकता + पुनःकाल)
4. BLEU स्कोर (द्विभाषी मूल्यांकन अधीनता)
BLEU स्कोर पार्स की गई सामग्री और मूल टेक्स्ट के बीच समानता को मापता है, विशेष रूप से शब्दों के क्रम पर जोर देता है। यह पार्स किए गए दस्तावेज़ों में भाषा और संरचना की निरंतरता का मूल्यांकन करने के लिए विशेष रूप से उपयोगी है, क्योंकि यह उन आउटपुट को दंडित करता है जो मूल से अनुक्रम में भिन्न होते हैं।
5. ANLS (औसत सामान्यीकृत लेवेनस्टाइन समानता)
ANLS पार्स की गई सामग्री और मूल के बीच समानता को मापता है, सामान्यीकृत संपादन दूरी का उपयोग करते हुए। इसे पार्स किए गए और संदर्भ पाठों में प्रत्येक शब्द जोड़ी के लिए सामान्यीकृत लेवेनस्टाइन समानता (NLS) को औसत करके गणना की जाती है। NLS को निम्नलिखित रूप से गणना की जाती है:
NLS = 1 - (लेवेनस्टाइन दूरी (LD)(पार्स किया गया शब्द, मूल शब्द)) / अधिकतम(पार्स किए गए शब्द की लंबाई, मूल शब्द की लंबाई)
फिर, ANLS सभी शब्द जोड़ों के लिए NLS का औसत है:
ANLS = (1/N) × Σ(NLS_i) जहाँ i=1 से N तक
6. एडिट डिस्टेंस
एडिट डिस्टेंस पार्स किए गए टेक्स्ट को मूल में परिवर्तित करने के लिए आवश्यक शब्द-स्तरीय संचालन (सम्मिलन, विलोपन, प्रतिस्थापन) की संख्या की गणना करता है।
7. जेन्सन-शैनन डाइवर्जेंस
जेन्सन-शैनन डाइवर्जेंस पार्स किए गए और मूल शब्द गणनाओं के बीच विवर्तनिक संभाव्यता वितरण की समानता को मापता है, शब्द आवृत्ति में भिन्नताओं को उजागर करता है।
JSD(P || Q) = (1/2) × KL(P || M) + (1/2) × KL(Q || M)
जहाँ M = (1/2)(P + Q), और KL(P || Q) कुलबैक-लेब्लर डाइवर्जेंस है
8. जैकार्ड डिस्टेंस
जैकार्ड डिस्टेंस पार्स किए गए और मूल सामग्री में शब्दों के सेट के बीच असमानता को मापता है, जो शब्द ओवरलैप का आकलन करने के लिए उपयोगी है।
जैकार्ड डिस्टेंस = 1 - |A ∩ B| / |A ∪ B|
जहाँ |A ∩ B| A और B के बीच सामान्य तत्वों की संख्या है,
और |A ∪ B| दोनों सेटों में अद्वितीय तत्वों की कुल संख्या है।