विजन लैंग्वेज मॉडल (VLMs) दस्तावेज़ विश्लेषण के क्षेत्र में क्रांति ला रहे हैं, पारंपरिक ऑप्टिकल कैरेक्टर रिकग्निशन (OCR) प्रणालियों में अंतर्निहित कई सीमाओं को संबोधित कर रहे हैं। जबकि OCR छवियों से पाठ को डिजिटाइज़ करने के लिए एक मुख्य तकनीक रही है, यह जटिल परिदृश्यों में महत्वपूर्ण चुनौतियों का सामना करती है। इनमें निम्न गुणवत्ता वाली छवियों के साथ सटीकता की समस्याएँ, सीमित संदर्भ समझ, मिश्रित भाषाओं के साथ कठिनाइयाँ, और दृश्य तत्वों की व्याख्या करने में असमर्थता शामिल हैं। VLMs उन्नत कंप्यूटर विजन को प्राकृतिक भाषा प्रसंस्करण क्षमताओं के साथ जोड़कर एक आशाजनक समाधान प्रदान करते हैं। यह लेख यह जांचता है कि कैसे VLMs OCR की कमियों को दूर कर रहे हैं, डिजिटल युग में दस्तावेज़ प्रसंस्करण के लिए अधिक मजबूत और बहुपरकारी समाधान प्रदान कर रहे हैं।
OCR क्या है? दस्तावेज़ पार्सिंग में OCR की प्रक्रियाएँ क्या हैं?
ऑप्टिकल कैरेक्टर रिकग्निशन (OCR) एक तकनीक है जो विभिन्न प्रकार के दस्तावेज़ों, जैसे स्कैन किए गए कागज़ के दस्तावेज़, PDF फ़ाइलें, या डिजिटल कैमरे द्वारा कैप्चर की गई छवियों, को संपादित और खोजने योग्य डेटा में परिवर्तित करने में सक्षम बनाती है। यह प्रक्रिया दस्तावेज़ प्रसंस्करण और PDF डेटा निष्कर्षण में महत्वपूर्ण है, जिससे मशीनें डिजिटल छवियों के भीतर मुद्रित या हस्तलिखित पाठ वर्णों को पहचान सकें।
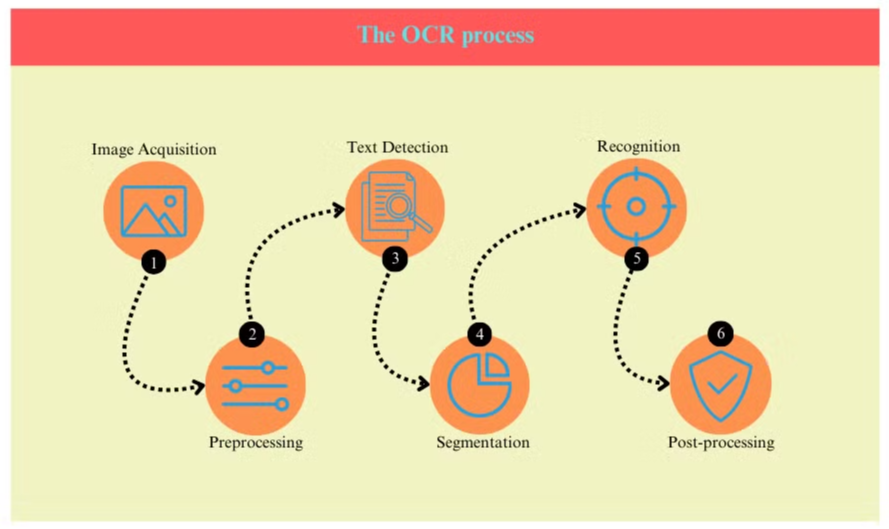
OCR प्रक्रिया
OCR प्रक्रिया आमतौर पर कई चरणों में होती है:
- छवि अधिग्रहण: दस्तावेज़ को स्कैन या फोटो खींचकर एक डिजिटल छवि बनाई जाती है।
- पूर्व-प्रसंस्करण: छवि को साफ किया जाता है, शोर को हटाया जाता है और ब्राइटनेस और कंट्रास्ट को समायोजित किया जाता है।
- पाठ पहचान: सिस्टम छवि के भीतर पाठ वाले क्षेत्रों की पहचान करता है।
- वर्ण विभाजन: पाठ क्षेत्रों के भीतर व्यक्तिगत वर्णों को अलग किया जाता है।
- वर्ण पहचान: प्रत्येक वर्ण का विश्लेषण किया जाता है और ज्ञात वर्णों के डेटाबेस के खिलाफ तुलना की जाती है।
- पोस्ट-प्रसंस्करण: पहचाने गए पाठ को भाषाई और संदर्भ जानकारी का उपयोग करके त्रुटियों के लिए जांचा जाता है।
हालांकि OCR ने दस्तावेज़ पार्सिंग क्षमताओं में काफी सुधार किया है, फिर भी यह जटिल लेआउट, निम्न गुणवत्ता वाली छवियों, और विभिन्न फ़ॉन्ट्स को संभालने में सीमाओं का सामना करता है। यहीं पर विजन लैंग्वेज मॉडल जैसी उन्नत तकनीकें डेटा निकालने में सटीकता और समझ को बढ़ाने के लिए कदम रख रही हैं।
पारंपरिक OCR तकनीक की सीमाएँ
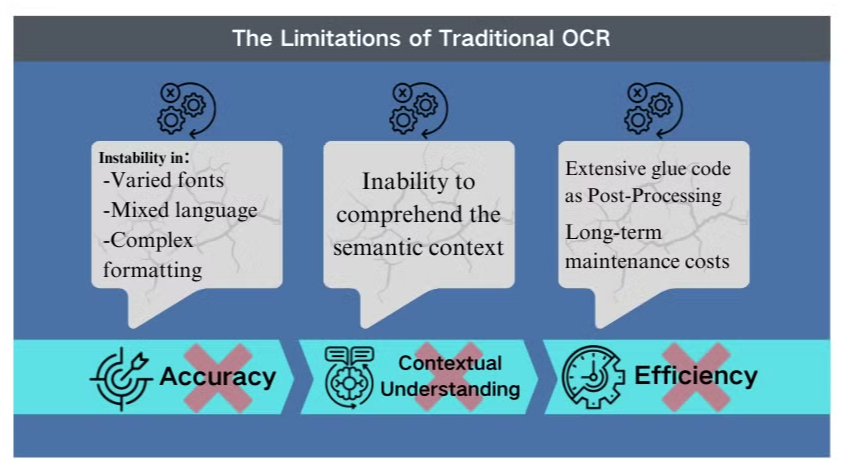
जटिल परिदृश्यों में सटीकता की चुनौतियाँ
पारंपरिक ऑप्टिकल कैरेक्टर रिकग्निशन (OCR) तकनीक, जबकि बुनियादी पाठ निष्कर्षण के लिए लाभकारी है, जटिल दस्तावेज़ लेआउट या निम्न गुणवत्ता वाली छवियों का सामना करते समय महत्वपूर्ण बाधाओं का सामना करती है। ये सिस्टम अक्सर विभिन्न फ़ॉन्ट्स, मिश्रित भाषाओं, या जटिल प्रारूपों वाले दस्तावेज़ों को संसाधित करते समय सटीकता बनाए रखने में संघर्ष करते हैं। उदाहरण के लिए, OCR छवि-भारी प्रस्तुतियों या घनी प्रारूपित PDFs से डेटा निकालने का प्रयास करते समय असफल हो सकता है।
संदर्भ समझने की कमी
पारंपरिक OCR की सबसे स्पष्ट सीमाओं में से एक यह है कि यह प्रक्रिया किए गए पाठ के अर्थपूर्ण संदर्भ को समझने में असमर्थ है। यह कमी विशेष रूप से उन परिदृश्यों में स्पष्ट होती है जहां सूक्ष्म व्याख्या की आवश्यकता होती है, जैसे कानूनी अनुबंध या चिकित्सा रिपोर्ट। OCR का वर्ण पहचान पर ध्यान केंद्रित करना संदर्भ जागरूकता के बिना महत्वपूर्ण गलत व्याख्याओं का कारण बन सकता है, विशेष रूप से जब अस्पष्ट वर्णों या उद्योग-विशिष्ट शब्दावली का सामना करना पड़ता है।
पोस्ट-प्रसंस्करण में असक्षमताएँ
OCR की सीमाएँ अक्सर व्यापक पोस्ट-प्रसंस्करण प्रयासों की आवश्यकता होती हैं। यह अतिरिक्त चरण दस्तावेज़ प्रसंस्करण के लिए आवश्यक समय और संसाधनों को काफी बढ़ा सकता है। इसके अलावा, पारंपरिक OCR सिस्टम आमतौर पर चार्ट, तालिकाओं, या अन्य गैर-पाठ तत्वों से जानकारी निकालने के लिए असफल होते हैं, जो दस्तावेज़ निष्कर्षण प्रक्रिया को और जटिल बनाते हैं। ये असक्षमताएँ अधिक उन्नत समाधानों की आवश्यकता को उजागर करती हैं, जैसे कि विजन लैंग्वेज मॉडल, जो दस्तावेज़ विश्लेषण और डेटा निष्कर्षण के लिए एक अधिक समग्र दृष्टिकोण प्रदान करते हैं।
विजन-लैंग्वेज मॉडल क्या हैं और यह OCR में कैसे सुधार करते हैं
विजन लैंग्वेज मॉडल दस्तावेज़ प्रसंस्करण तकनीक में एक महत्वपूर्ण प्रगति का प्रतिनिधित्व करते हैं, पारंपरिक ऑप्टिकल कैरेक्टर रिकग्निशन (OCR) प्रणालियों में अंतर्निहित कई सीमाओं को संबोधित करते हैं। ये उन्नत मॉडल कंप्यूटर विजन को प्राकृतिक भाषा प्रसंस्करण के साथ जोड़ते हैं ताकि दस्तावेज़ों के दृश्य और पाठ तत्वों को एक साथ समझा जा सके।
सटीकता और संदर्भ समझने में सुधार
OCR की तुलना में, जो निम्न गुणवत्ता वाली छवियों और जटिल लेआउट के साथ संघर्ष करता है, विजन लैंग्वेज मॉडल विविध दस्तावेज़ प्रारूपों की व्याख्या करने में उत्कृष्टता प्राप्त करते हैं। वे छवियों, PDFs, और अन्य दृश्य सामग्री से डेटा को सटीकता से निकाल सकते हैं, भले ही उन्हें चुनौतीपूर्ण परिदृश्यों का सामना करना पड़े। यह सुधारित सटीकता उनके द्वारा दस्तावेज़ के पूरे संदर्भ पर विचार करने की क्षमता से उत्पन्न होती है, न कि केवल व्यक्तिगत वर्णों या शब्दों पर ध्यान केंद्रित करने से।
व्यापक डेटा निष्कर्षण
विजन लैंग्वेज मॉडल सरल पाठ पहचान से परे जाते हैं, व्यापक PDF डेटा निष्कर्षण क्षमताएँ प्रदान करते हैं। वे दस्तावेज़ों के भीतर तालिकाओं, चार्टों, और आंकड़ों की पहचान और व्याख्या कर सकते हैं, जटिल लेआउट की अखंडता को बनाए रखते हुए। दस्तावेज़ विश्लेषण के लिए इस समग्र दृष्टिकोण से अधिक सूक्ष्म और पूर्ण जानकारी पुनर्प्राप्ति संभव होती है, जो निकाली गई डेटा की उपयोगिता को महत्वपूर्ण रूप से बढ़ाती है।
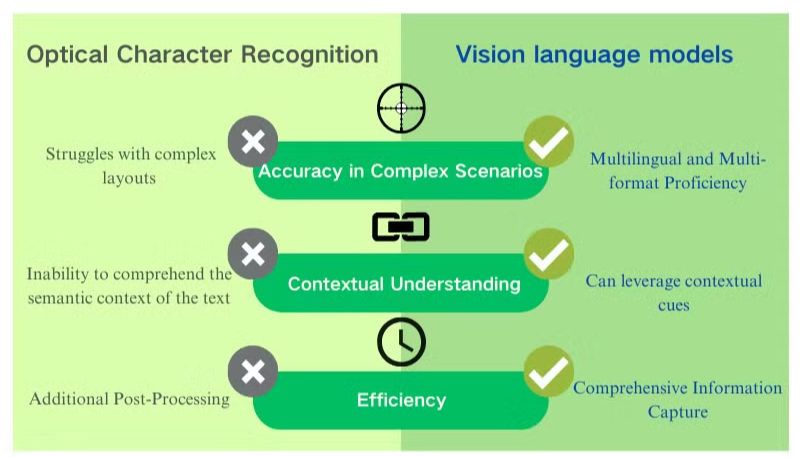
बहुभाषी और बहु-प्रारूप दक्षता
विजन लैंग्वेज मॉडल का एक प्रमुख लाभ यह है कि वे कई भाषाओं और दस्तावेज़ प्रारूपों को संभालने में लचीलापन प्रदान करते हैं। पारंपरिक OCR प्रणालियों की तुलना में जो गैर-लैटिन लिपियों या मिश्रित-भाषा दस्तावेज़ों के साथ संघर्ष कर सकती हैं, ये मॉडल विभिन्न भाषाओं और लिपियों में सामग्री को निर्बाध रूप से संसाधित कर सकते हैं, जिससे वे वैश्विक दस्तावेज़ प्रसंस्करण आवश्यकताओं के लिए अमूल्य बन जाते हैं।
दस्तावेज़ समझने के लिए विजन-लैंग्वेज मॉडल के प्रमुख लाभ
विजन लैंग्वेज मॉडल दस्तावेज़ प्रसंस्करण और डेटा निष्कर्षण के लिए पारंपरिक OCR की तुलना में महत्वपूर्ण लाभ प्रदान करते हैं। ये AI-संचालित सिस्टम विभिन्न दस्तावेज़ प्रकारों में उत्कृष्ट परिणाम देने के लिए दृश्य और पाठ समझ को जोड़ते हैं।
सटीकता और संदर्भ समझने में सुधार
विजन लैंग्वेज मॉडल जटिल लेआउट, निम्न गुणवत्ता वाली छवियों, और विविध फ़ॉन्ट्स को संभालने में उत्कृष्टता प्राप्त करते हैं। OCR की तुलना में, जो अस्पष्ट वर्णों के साथ संघर्ष करता है, ये मॉडल संदर्भ संकेतों का उपयोग करके पाठ को सटीकता से व्याख्या करते हैं। यह क्षमता PDF डेटा निष्कर्षण की सटीकता को नाटकीय रूप से सुधारती है, विशेष रूप से उन दस्तावेज़ों के लिए जिनकी संरचना जटिल है या छवि गुणवत्ता खराब है।
व्यापक जानकारी संग्रहण
जबकि OCR केवल पाठ पहचान पर ध्यान केंद्रित करता है, विजन लैंग्वेज मॉडल छवियों, तालिकाओं, और चार्ट से डेटा निकाल सकते हैं। यह समग्र दृष्टिकोण सुनिश्चित करता है कि दस्तावेज़ प्रसंस्करण चरण के दौरान महत्वपूर्ण जानकारी को नजरअंदाज नहीं किया जाता है। पाठ और दृश्य तत्वों दोनों को कैप्चर करके, ये मॉडल दस्तावेज़ सामग्री की अधिक पूर्ण समझ प्रदान करते हैं।
बहुभाषी और बहु-प्रारूप दक्षता
विजन लैंग्वेज मॉडल विभिन्न भाषाओं और प्रारूपों में दस्तावेज़ों को संसाधित करने मेंRemarkable लचीलापन प्रदर्शित करते हैं। वे मिश्रित-भाषा दस्तावेज़ों और गैर-लैटिन लिपियों को निर्बाध रूप से संभाल सकते हैं, जो पारंपरिक OCR प्रणालियों की एक महत्वपूर्ण सीमा को पार करते हैं। यह बहुपरकारी क्षमता उन्हें विविध दस्तावेज़ प्रकारों और भाषाओं के साथ काम करने वाले वैश्विक उद्यमों के लिए अमूल्य बनाती है।
VLM द्वारा सक्षम वास्तविक-विश्व अनुप्रयोग जो OCR असफल रहे
विजन लैंग्वेज मॉडल वित्त, मानव संसाधन, और अन्य क्षेत्रों में दस्तावेज़ प्रसंस्करण में क्रांति ला रहे हैं, पारंपरिक OCR प्रणालियों की महत्वपूर्ण सीमाओं को संबोधित कर रहे हैं। ये उन्नत AI मॉडल उद्योगों में डिजिटल परिवर्तन प्रयासों को बदल रहे हैं, उत्कृष्ट सटीकता और संदर्भ समझ प्रदान करते हैं।
वित्तीय दस्तावेज़ प्रसंस्करण में क्रांति
विजन लैंग्वेज मॉडल वित्त में दस्तावेज़ प्रसंस्करण को बदल रहे हैं, पारंपरिक OCR की सीमाओं को पार करते हुए। ये उन्नत मॉडल जटिल वित्तीय विवरण, चालान, और रसीदों से डेटा निकालने में उत्कृष्टता प्राप्त करते हैं, जिनकी संरचना जटिल होती है। OCR की तुलना में, वे संदर्भ को समझ सकते हैं, अस्पष्ट वर्णों (जैसे, शून्य और वर्ण O के बीच भेद करना) और वैश्विक वित्तीय दस्तावेज़ों में अक्सर मौजूद मिश्रित भाषाओं को सटीकता से व्याख्या कर सकते हैं।
बुद्धिमान दस्तावेज़ विश्लेषण के माध्यम से HR संचालन को बढ़ाना
HR क्षेत्र में, विजन लैंग्वेज मॉडल फिर से शुरू, कर्मचारी रिकॉर्ड, और प्रदर्शन समीक्षाओं से PDF डेटा निष्कर्षण के लिए अमूल्य साबित हो रहे हैं। ये मॉडल दस्तावेज़ों की अर्थपूर्ण संरचना को समझ सकते हैं, जिससे अधिक सटीक जानकारी पुनर्प्राप्ति और विश्लेषण संभव होता है। यह क्षमता भर्ती प्रक्रियाओं और कर्मचारी डेटा प्रबंधन को महत्वपूर्ण रूप से सरल बनाती है, ऐसे कार्य जहां OCR अक्सर विभिन्न प्रारूपों और हस्तलिखित नोट्स के साथ संघर्ष करता है।
अनुपालन और जोखिम प्रबंधन में सुधार
विजन-लैंग्वेज मॉडल वित्त और HR दोनों में अनुपालन और जोखिम प्रबंधन में विशेष रूप से प्रभावी होते हैं। वे नियामक दस्तावेज़ों, अनुबंधों, और नीतियों से महत्वपूर्ण जानकारी को OCR की तुलना में अधिक सटीकता के साथ निकाल और व्याख्या कर सकते हैं। यह उन्नत दस्तावेज़ प्रसंस्करण क्षमता कानूनी आवश्यकताओं के प्रति बेहतर अनुपालन सुनिश्चित करती है और अधिक कुशल जोखिम मूल्यांकन प्रक्रियाओं को सक्षम बनाती है।
निष्कर्ष
अंत में, विजन लैंग्वेज मॉडल दस्तावेज़ प्रसंस्करण तकनीक में एक महत्वपूर्ण प्रगति का प्रतिनिधित्व करते हैं, पारंपरिक OCR प्रणालियों की अंतर्निहित कई सीमाओं को संबोधित करते हैं। दृश्य और पाठ समझ को जोड़कर, ये उन्नत मॉडल जटिल लेआउट से लेकर मिश्रित भाषाओं और निम्न गुणवत्ता वाली छवियों तक विभिन्न चुनौतीपूर्ण परिदृश्यों में उत्कृष्ट प्रदर्शन प्रदान करते हैं। जैसे-जैसे संगठन अपने संचालन को डिजिटाइज़ करते हैं और अपने दस्तावेज़ भंडार से मूल्य निकालने के अधिक कुशल तरीके खोजते हैं, विजन लैंग्वेज मॉडल डेवलपर्स और इंजीनियरिंग नेताओं के लिए एक शक्तिशाली उपकरण के रूप में उभरते हैं। संदर्भ को समझने, विविध प्रारूपों को संभालने, और अधिक सटीक परिणाम प्रदान करने की उनकी क्षमता उन्हें उन्नत RAG पाइपलाइनों और उद्यम-व्यापी खोज क्षमताओं के लिए एक प्रमुख सक्षमकर्ता बनाती है, अंततः डिजिटल परिवर्तन पहलों को नई ऊँचाइयों तक पहुँचाती है।