क्या आपने कभी सोचा है कि OCR का क्या मतलब है? ऑप्टिकल कैरेक्टर रिकॉग्निशन एक शक्तिशाली तकनीक है जो टेक्स्ट की छवियों को मशीन-पठनीय डेटा में परिवर्तित करती है। जबकि OCR दस्तावेज़ों को डिजिटाइज करने और जानकारी निकालने के लिए अद्भुत लाभ प्रदान करता है, इसके कुछ नुकसान भी हैं। जब आप इस तकनीक का पता लगाते हैं, तो इसके क्षमताओं और सीमाओं को समझना महत्वपूर्ण है। इस लेख में, आप OCR के पीछे के अर्थ को जानेंगे और इसके संभावित नुकसान में गहराई से जाएंगे। ऑप्टिकल कैरेक्टर रिकॉग्निशन की व्यापक समझ प्राप्त करके, आप यह निर्धारित करने के लिए बेहतर तरीके से सक्षम होंगे कि इस तकनीक को अपने कार्यप्रवाह और परियोजनाओं में कैसे लागू करना है।
OCR का मतलब क्या है और OCR क्या है?
OCR का मतलब क्या है?
OCR का मतलब है ऑप्टिकल कैरेक्टर रिकॉग्निशन, एक तकनीक जो कंप्यूटरों को विभिन्न प्रकार के दस्तावेज़ों को पहचानने और परिवर्तित करने में सक्षम बनाती है। इसके मूल में, OCR मुद्रित या हस्तलिखित टेक्स्ट को स्कैन करने और इसे मशीन-कोडित टेक्स्ट में परिवर्तित करने की प्रक्रिया है। यह टेक्स्ट को आसानी से खोजने, संपादित करने और स्थानांतरित करने योग्य बनाता है। OCR का मतलब क्या है, यह समझना उन सभी के लिए आवश्यक है जो दस्तावेज़ स्कैनिंग और टेक्स्ट रिकॉग्निशन तकनीकों के साथ काम कर रहे हैं।
OCR क्या है?
जो लोग इस शब्द से अपरिचित हैं, उनके लिए 'OCR क्या है' एक सामान्य प्रश्न है, जो ऑप्टिकल कैरेक्टर रिकॉग्निशन का संदर्भ देता है, एक तकनीक जो कंप्यूटरों को छवियों या स्कैन किए गए दस्तावेज़ों से टेक्स्ट पढ़ने की अनुमति देती है।
OCR मुद्रित या हस्तलिखित टेक्स्ट को मशीन-पठनीय डेटा में परिवर्तित करता है, कागज और डिजिटल प्रारूपों के बीच की खाई को पाटता है। यह तकनीक पत्र के आकार, शब्द संरचनाओं और यहां तक कि पूरे वाक्यों का पता लगाने के लिए उन्नत एल्गोरिदम का उपयोग करती है। इस प्रकार, यह स्थिर छवियों को संपादनीय और खोजने योग्य टेक्स्ट फ़ाइलों में परिवर्तित करती है।
OCR तकनीक मूल रूप से कंप्यूटर दृष्टि और पैटर्न पहचान तकनीकों पर आधारित है। OCR का मतलब है दस्तावेज़ों या टेक्स्ट वाली छवियों को स्कैन करना और टेक्स्ट को डिजिटल, संपादनीय प्रारूप में पहचानने और परिवर्तित करने के लिए उन्नत एल्गोरिदम का उपयोग करना। OCR तकनीक के इतिहास में एक प्रमुख क्षण 1974 में था जब रे कुर्ज़वेल ने एक ओमनी-फॉन्ट OCR प्रणाली विकसित की जो लगभग किसी भी फ़ॉन्ट में टेक्स्ट को पहचान सकती थी। वर्षों से, OCR सरल टेम्पलेट मिलान से अधिक उन्नत प्रणालियों में विकसित हुआ है।
इसके क्षमताओं के बावजूद, OCR तकनीक वर्तमान में कुछ सीमाओं का सामना कर रही है। इनमें खराब गुणवत्ता वाली छवियों में टेक्स्ट को पहचानने में चुनौतियाँ, जटिल लेआउट या पृष्ठभूमियों को संभालने में कठिनाई, और विभिन्न फ़ॉन्ट, भाषाओं या हस्तलेख के साथ काम करते समय भिन्न सटीकता शामिल हैं। इसके अतिरिक्त, OCR सिस्टम रंगीन पृष्ठभूमियों वाले दस्तावेज़ों, धुंधली या तिरछी छवियों, और कर्सिव हस्तलेख के साथ संघर्ष कर सकते हैं।
ऑप्टिकल कैरेक्टर रिकॉग्निशन सॉफ़्टवेयर को समझना
ऑप्टिकल कैरेक्टर रिकॉग्निशन सॉफ़्टवेयर एक परिवर्तनकारी तकनीक है जो विभिन्न प्रकार के दस्तावेज़ों को संपादनीय और खोजने योग्य डेटा में परिवर्तित करती है। यह हमारे विश्व को डिजिटाइज करने में एक महत्वपूर्ण भूमिका निभाता है, जानकारी को अधिक सुलभ और प्रबंधनीय बनाता है। OCR सॉफ़्टवेयर टेक्स्ट की छवियों को मशीन-पठनीय डेटा में परिवर्तित करने के लिए एक जटिल प्रक्रिया का उपयोग करता है।
OCR सॉफ़्टवेयर कैसे काम करता है
1. छवि अधिग्रहण
OCR की यात्रा दस्तावेज़ की छवि कैप्चर करने से शुरू होती है। यह एक स्कैनर या डिजिटल कैमरे के माध्यम से किया जा सकता है। छवि को फिर एक डिजिटल प्रारूप में अनुवादित किया जाता है जिसे कंप्यूटर प्रोसेस कर सकता है।
2. पूर्व-प्रसंस्करण और छवि संवर्धन
दूसरा चरण छवि की गुणवत्ता को बढ़ाने में शामिल होता है। एक बार जब छवि प्राप्त हो जाती है, तो इसे बेहतर पहचान के लिए गुणवत्ता बढ़ाने के लिए पूर्व-प्रसंस्करण से गुजरना पड़ता है। इस चरण में छवि के कंट्रास्ट, ब्राइटनेस और शार्पनेस को समायोजित करना, साथ ही किसी भी शोर या अप्रासंगिक तत्वों को हटाना शामिल हो सकता है। यह पूर्व-प्रसंस्करण चरण सटीक परिणाम प्राप्त करने के लिए महत्वपूर्ण है, विशेष रूप से निम्न गुणवत्ता वाले स्कैन या फ़ोटोग्राफ़ के साथ काम करते समय।
3. टेक्स्ट पहचान
OCR सॉफ़्टवेयर पूर्व-प्रसंस्कृत छवि का विश्लेषण करता है ताकि उन क्षेत्रों का पता लगाया जा सके जिनमें टेक्स्ट है। यह टेक्स्ट के विशेषताओं जैसे विभिन्न मोटाई और ऊँचाई की रेखाओं की पहचान करके करता है।
4. कैरेक्टर विभाजन
एक बार जब टेक्स्ट क्षेत्र का पता लगा लिया जाता है, तो सॉफ़्टवेयर टेक्स्ट को छोटे इकाइयों में तोड़ता है, जैसे ब्लॉक, पंक्तियाँ, शब्द, या यहां तक कि व्यक्तिगत अक्षर। OCR सॉफ़्टवेयर छवि का पिक्सेल दर पिक्सेल विश्लेषण करता है ताकि अक्षरों के रूपों का पता लगाया जा सके। यह छवि को छोटे खंडों में तोड़ता है, प्रत्येक अक्षर को अलग करता है।
5. टेक्स्ट पहचान और निष्कर्षण
फिर सॉफ़्टवेयर इन अलग किए गए आकारों की तुलना ज्ञात कैरेक्टर पैटर्न के विशाल डेटाबेस से करता है ताकि यह निर्धारित किया जा सके कि प्रत्येक अक्षर क्या है। सॉफ़्टवेयर अक्षरों से विशेषताएँ निकालता है, जैसे रेखाओं, वक्रों, या कोणों की संख्या। ये विशेषताएँ OCR को विभिन्न अक्षरों के बीच पहचानने और भेद करने में मदद करती हैं।
6. पोस्ट-प्रसंस्करण
एक बार जब अक्षरों की पहचान हो जाती है, तो OCR सिस्टम एक पोस्ट-प्रसंस्करण चरण से गुजरता है जहां यह संभावित त्रुटियों को सुधारता है और आउटपुट के लिए टेक्स्ट को प्रारूपित करता है। फिर सही टेक्स्ट को इच्छित प्रारूप में निर्यात किया जाता है, जैसे कि एक वर्ड दस्तावेज़ या एक खोजने योग्य PDF।
ऑप्टिकल कैरेक्टर रिकॉग्निशन सॉफ़्टवेयर के उपयोग के मामले
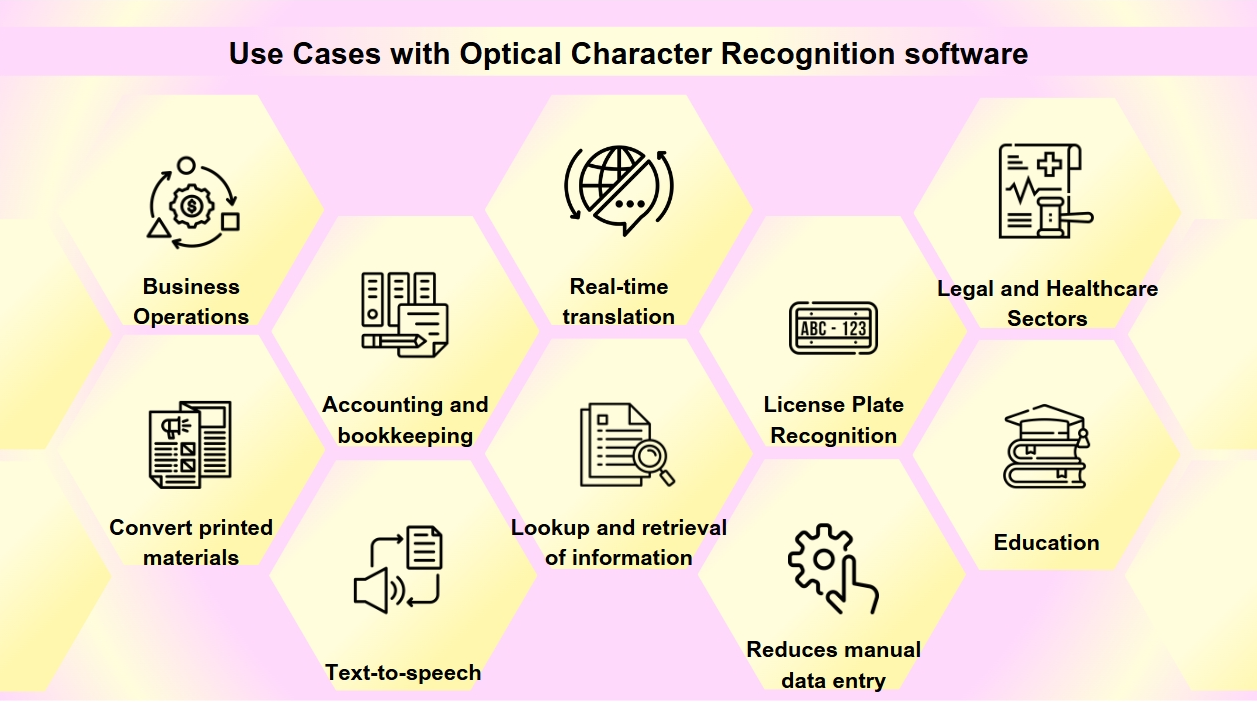
OCR कई उद्योगों के डिजिटल परिवर्तन में एक आवश्यक उपकरण बन गया है, प्रक्रियाओं को सरल बनाते हुए और डेटा की सुलभता और सटीकता में सुधार करते हुए। आप शायद OCR को उससे अधिक बार सामना करते हैं जितना आप समझते हैं। व्यवसाय कार्ड स्कैन करने से लेकर पुराने पुस्तकों को डिजिटाइज करने तक, OCR विभिन्न उद्योगों में एक महत्वपूर्ण भूमिका निभाता है। OCR तकनीक के कई अनुप्रयोग हैं:
-
दस्तावेज़ डिजिटाइजेशन: OCR का उपयोग मुद्रित सामग्रियों जैसे पुराने पुस्तकों, समाचार पत्रों, और ऐतिहासिक दस्तावेज़ों को डिजिटल प्रारूपों में परिवर्तित करने के लिए किया जाता है, जिससे उन्हें खोजने योग्य बनाया जा सके और भविष्य की पीढ़ियों के लिए संरक्षित किया जा सके।
-
फॉर्म प्रोसेसिंग: व्यवसाय OCR का उपयोग फॉर्म से डेटा को स्वचालित रूप से निकालने के लिए करते हैं, जिससे मैनुअल डेटा प्रविष्टि कम होती है और वित्त और स्वास्थ्य सेवा जैसे विभिन्न क्षेत्रों में दक्षता बढ़ती है।
-
इनवॉइस प्रोसेसिंग: OCR तकनीक इनवॉइस पर टेक्स्ट पढ़ सकती है और डेटा को स्वचालित रूप से वित्तीय प्रणालियों में इनपुट कर सकती है, जिससे लेखांकन और बहीखाता प्रक्रियाएँ सरल होती हैं।
-
सुलभता: OCR टेक्स्ट-टू-स्पीच कार्यक्षमता को सक्षम बनाता है, दृष्टिहीन व्यक्तियों के लिए टेक्स्ट के ऑडियो संस्करण बनाता है, जिससे मुद्रित सामग्रियों को अधिक सुलभ बनाया जा सके।
-
मोबाइल एप्लिकेशन: OCR व्यवसाय कार्ड स्कैन करने, फ़ोटो में टेक्स्ट पहचानने, और वास्तविक समय में अनुवाद करने जैसी कार्यों के लिए ऐप्स में एकीकृत किया गया है।
-
खोजने की क्षमता: OCR स्कैन किए गए दस्तावेज़ों की खोजने की क्षमता को बढ़ाता है, छवियों या PDFs से टेक्स्ट निकालकर, जानकारी की आसान खोज और पुनर्प्राप्ति की अनुमति देता है।
-
लाइसेंस प्लेट पहचान: पार्किंग और ट्रैफिक प्रबंधन के लिए उपयोग किया जाता है, OCR लाइसेंस प्लेटों को पहचान सकता है, जिससे कुशल निगरानी और प्रवर्तन संभव होता है।
-
व्यवसाय संचालन: OCR दस्तावेज़ों जैसे इनवॉइस, रसीदें, और खरीद आदेशों से डेटा प्रविष्टि को स्वचालित करके व्यवसाय प्रक्रियाओं को सरल बनाता है, साथ ही नौकरी आवेदनों और रिज़्यूमे को स्कैन और प्रोसेस करके भर्ती को तेज करता है।
-
कानूनी और स्वास्थ्य सेवा क्षेत्र: कानून फर्म OCR का उपयोग केस फ़ाइलों और कानूनी दस्तावेज़ों को डिजिटाइज करने के लिए करते हैं ताकि जानकारी की पुनर्प्राप्ति आसान हो सके, जबकि स्वास्थ्य सेवा प्रदाता इसे रोगी रिकॉर्ड और चिकित्सा फ़ॉर्म को इलेक्ट्रॉनिक स्वास्थ्य रिकॉर्ड (EHRs) में परिवर्तित करने के लिए उपयोग करते हैं, डेटा प्रबंधन और रोगी देखभाल में सुधार करते हैं।
-
शिक्षा: शैक्षणिक सेटिंग्स में, OCR डिजिटल पाठ्यपुस्तकों और शिक्षण सामग्रियों को बनाने के लिए उपयोग किया जाता है, छात्रों की विविध आवश्यकताओं के लिए सुलभता में सुधार करता है और एक समावेशी शिक्षण वातावरण का समर्थन करता है।
जैसे-जैसे OCR तकनीक विकसित होती है, यह जानकारी को अधिक सुलभ और डिजिटल युग में संभालने के लिए कुशल बनाने में महत्वपूर्ण भूमिका निभाती है।
OCR का नुकसान: सीमाएँ और कमियाँ
सटीकता की चुनौतियाँ
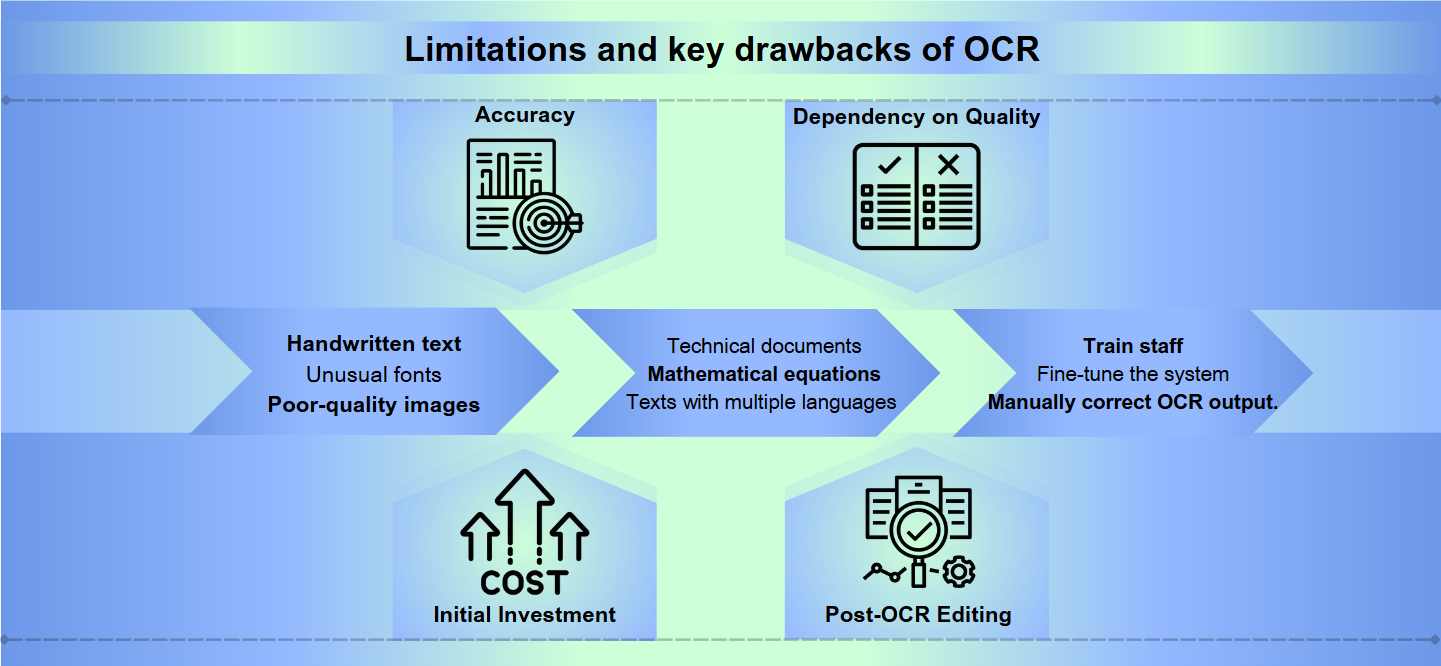
हालांकि ऑप्टिकल कैरेक्टर रिकॉग्निशन (OCR) तकनीक ने काफी प्रगति की है, फिर भी यह पूर्ण सटीकता प्राप्त करने में महत्वपूर्ण बाधाओं का सामना करती है। हस्तलिखित टेक्स्ट, असामान्य फ़ॉन्ट, या खराब गुणवत्ता वाली छवियाँ गलत व्याख्याओं और त्रुटियों का कारण बन सकती हैं। अक्षर के आकार या आकार में थोड़े से भिन्नताएँ भी OCR सिस्टम को भ्रमित कर सकती हैं, जिसके परिणामस्वरूप गड़बड़ आउटपुट होता है जिसे मैन्युअल रूप से सुधारने की आवश्यकता होती है।
भाषा और प्रारूप की सीमाएँ
अधिकांश OCR समाधान मानक भाषाओं और प्रारूपों में उत्कृष्ट होते हैं लेकिन विशेष सामग्री के साथ संघर्ष करते हैं। तकनीकी दस्तावेज़, गणितीय समीकरण, या कई भाषाओं के साथ टेक्स्ट महत्वपूर्ण चुनौतियाँ पेश कर सकते हैं। इसके अतिरिक्त, OCR जटिल लेआउट, तालिकाओं, या जटिल प्रारूप वाले दस्तावेज़ों का सामना करते समय असफल हो सकता है, जिससे महत्वपूर्ण संरचनात्मक जानकारी खो सकती है।
संसाधन की तीव्रता
एक प्रभावी OCR प्रणाली को लागू करना और बनाए रखना संसाधन-गहन हो सकता है। उच्च गुणवत्ता वाला OCR सॉफ़्टवेयर अक्सर महंगा होता है, और बड़े पैमाने पर दस्तावेज़ों को प्रोसेस करने के लिए आवश्यक हार्डवेयर महंगा हो सकता है। इसके अलावा, कर्मचारियों को प्रशिक्षित करने, सिस्टम को ठीक करने, और OCR आउटपुट की मैन्युअल समीक्षा और सुधार करने में आवश्यक समय और प्रयास संगठनात्मक संसाधनों पर दबाव डाल सकता है।
OCR के प्रमुख नुकसान
-
सटीकता: OCR सॉफ़्टवेयर सटीकता के साथ संघर्ष कर सकता है, विशेष रूप से खराब गुणवत्ता वाली छवियों, जटिल लेआउट, या हस्तलिखित टेक्स्ट के साथ। त्रुटियाँ अक्षरों को गलत पढ़ने से लेकर टेक्स्ट के पूरे अनुभागों को छोड़ने तक हो सकती हैं।
-
गुणवत्ता पर निर्भरता: OCR की प्रभावशीलता मूल दस्तावेज़ की गुणवत्ता पर बहुत निर्भर करती है। फीका स्याही, धब्बे, या कुचले हुए कागज गलत अनुवाद का कारण बन सकते हैं।
-
प्रारंभिक निवेश: एक OCR प्रणाली स्थापित करने के लिए महत्वपूर्ण प्रारंभिक लागत की आवश्यकता हो सकती है, जिसमें न केवल सॉफ़्टवेयर बल्कि स्कैनर जैसे संगत हार्डवेयर भी शामिल हैं।
-
पोस्ट-OCR संपादन: अक्सर, OCR प्रक्रियाओं से प्राप्त आउटपुट की मैन्युअल समीक्षा और सुधार की आवश्यकता होती है, जो समय लेने वाली हो सकती है।
दृष्टि भाषा मॉडल OCR की सीमाओं को पार करना
जैसे-जैसे तकनीक विकसित होती है, पारंपरिक ऑप्टिकल कैरेक्टर रिकॉग्निशन (OCR) की कमियों को दूर करने के लिए नवोन्मेषी समाधान उभर रहे हैं। एक ऐसा ब्रेकथ्रू दृष्टि भाषा मॉडल (VLM) है, जो टेक्स्ट निष्कर्षण और समझ में क्रांति लाने के लिए कंप्यूटर दृष्टि और प्राकृतिक भाषा प्रसंस्करण को जोड़ता है।
संवर्धित संदर्भीय समझ
VLMs टेक्स्ट के चारों ओर के संदर्भ को समझने में उत्कृष्ट होते हैं, जबकि OCR का अलग अक्षर पहचान। ये मॉडल टेक्स्ट के साथ-साथ दृश्य तत्वों का विश्लेषण करके जटिल लेआउट, हस्तलिखित नोट्स, और यहां तक कि आंशिक रूप से अस्पष्ट टेक्स्ट को अद्भुत सटीकता के साथ व्याख्या कर सकते हैं।
बहुभाषी और बहु-मोडल क्षमताएँ
जबकि OCR अक्सर विविध भाषाओं और लिपियों के साथ संघर्ष करता है, VLMs प्रभावशाली बहुपरकता प्रदर्शित करते हैं। वे कई भाषाओं को सहजता से प्रोसेस कर सकते हैं और यहां तक कि चित्रों या चार्ट जैसे दृश्य सामग्री को भी व्याख्या कर सकते हैं, दस्तावेज़ों की अधिक व्यापक समझ प्रदान करते हैं।
अनुकूली शिक्षण और निरंतर सुधार
स्थिर OCR प्रणालियों के विपरीत, VLMs मशीन लर्निंग का उपयोग करते हैं ताकि समय के साथ अनुकूलित और सुधार किया जा सके। जैसे-जैसे वे नए डेटा और परिदृश्यों का सामना करते हैं, ये मॉडल अपने प्रदर्शन को परिष्कृत करते हैं, विभिन्न दस्तावेज़ प्रकारों और प्रारूपों को संभालने में अधिक सक्षम बनते हैं।
OCR की सीमाओं को पार करके, दृष्टि भाषा मॉडल अधिक सटीक, कुशल, और बुद्धिमान दस्तावेज़ प्रोसेसिंग के लिए रास्ता प्रशस्त कर रहे हैं।
दृष्टि भाषा मॉडल चुनें: AnyParser आजमाएँ
दृष्टि भाषा मॉडलों (VLM) की प्रगति पर आधारित, AnyParser एक परिष्कृत समाधान के रूप में उभरता है जो पारंपरिक OCR तकनीक की सीमाओं को पार करता है। CambioML टीम द्वारा विकसित, AnyParser एक शक्तिशाली दस्तावेज़ पार्सिंग उपकरण है जो PDFs, छवियों, और चार्ट जैसे विभिन्न असंरचित डेटा स्रोतों से जानकारी निकालने के लिए एक सटीक और कॉन्फ़िगर करने योग्य API का उपयोग करता है, उन्हें संरचित प्रारूपों में परिवर्तित करता है।
तकनीकी आधार और क्षमताएँ
AnyParser बड़े भाषा मॉडलों (LLMs) की मजबूत नींव पर आधारित है, जो दस्तावेज़ों से टेक्स्ट, तालिका, चार्ट, और लेआउट निष्कर्षण में उच्च सटीकता सुनिश्चित करता है। यह मूल लेआउट और प्रारूप को बनाए रखने की अपनी क्षमता के साथ खड़ा है, जो जटिल लेआउट वाले दस्तावेज़ों या मूल सौंदर्य को बनाए रखने की आवश्यकता वाले दस्तावेज़ों के लिए विशेष रूप से लाभकारी है।
गोपनीयता और सुरक्षा
उपयोगकर्ता की गोपनीयता को उजागर करते हुए, AnyParser स्थानीय रूप से डेटा प्रोसेस करता है, इस प्रकार संवेदनशील जानकारी की सुरक्षा करता है। यह सुविधा उन उद्यमों और व्यक्तियों के लिए एक महत्वपूर्ण लाभ है जो गोपनीय डेटा के साथ काम कर रहे हैं।
अनुकूलनशीलता और लचीलापन
उच्च स्तर की कॉन्फ़िगर करने की क्षमता प्रदान करते हुए, AnyParser उपयोगकर्ताओं को कस्टम निष्कर्षण नियम सेट करने और आउटपुट प्रारूपों को परिभाषित करने की अनुमति देता है जो उनकी विशिष्ट आवश्यकताओं के अनुकूल होते हैं। यह अनुकूलन इसे AI इंजीनियरिंग से लेकर वित्तीय विश्लेषण तक के विभिन्न अनुप्रयोगों के लिए एक आदर्श उपकरण बनाता है।
निष्कर्ष
जैसा कि आपने सीखा है, OCR तकनीक टेक्स्ट को डिजिटाइज करने के लिए शक्तिशाली क्षमताएँ प्रदान करती है, लेकिन यह सीमाओं के बिना नहीं है। जबकि ऑप्टिकल कैरेक्टर रिकॉग्निशन दक्षता में नाटकीय रूप से सुधार कर सकता है, आपको संभावित नुकसान को सावधानीपूर्वक तौलना चाहिए। OCR समाधान को लागू करने से पहले सटीकता की समस्याओं, प्रारूपिंग चुनौतियों, और संसाधन आवश्यकताओं पर विचार करें। अंततः, OCR का उपयोग करने का निर्णय आपकी विशिष्ट आवश्यकताओं और परिस्थितियों पर निर्भर करता है। लाभों और नुकसान दोनों को समझकर, आप यह तय करने के लिए एक सूचित विकल्प बना सकते हैं कि क्या OCR आपके संगठन के लिए सही है। जैसे-जैसे OCR विकसित होता है, वर्तमान कमियों को दूर करने और इस परिवर्तनकारी तकनीक के लिए और भी अधिक संभावनाएँ खोलने के लिए नए विकास से अवगत रहें।
कार्रवाई के लिए कॉल
दृष्टि भाषा मॉडलों की शक्ति को अपनाएँ और AnyParser को मुफ्त में आजमाएँ ताकि आप अपने PDFs को Google Sheets में परिवर्तित कर सकें https://www.cambioml.com/sandbox पर। जानें कि VLMs आपके डेटा निष्कर्षण कार्यप्रवाह को कैसे बढ़ा सकते हैं, इसके लिए मुफ्त परामर्श प्राप्त करें।