संरचित डेटा और असंरचित डेटा क्या है
डिजिटल सूचना युग में, डेटा किसी भी समय उत्पन्न होता है, और उद्यम डेटा के विश्लेषण और प्रसंस्करण के माध्यम से मूल्य उत्पन्न करते हैं। इसलिए, डेटा को एकत्र करना और रिकॉर्ड करना और डेटा को संसाधित करना और विश्लेषण करना व्यवसाय संचालन में दो महत्वपूर्ण कार्य बन गए हैं। डेटा संग्रह के दौरान, असंरचित डेटा अधिक बार सामना किया जाता है, इन डेटा का स्रोत और रूप विविध होते हैं, और इसे सरलता से वर्गीकृत या खोजा नहीं जा सकता। प्रभावी डेटा अधिग्रहण संगठनों के लिए कच्चे डेटा को क्रियाशील अंतर्दृष्टियों में प्रभावी ढंग से परिवर्तित करने के लिए आवश्यक है। डेटा प्रसंस्करण की प्रक्रिया में, अधिकतर संरचित डेटा का सामना किया जाता है, जिसमें स्पष्ट संरचना, स्पष्ट जानकारी होती है, और इसे आसानी से व्यवस्थित, खोजा और विश्लेषित किया जा सकता है। इसलिए, असंरचित डेटा को संरचित डेटा में परिवर्तित करना उद्यमों के लिए डेटा के मूल्य का उपयोग करने के लिए एक महत्वपूर्ण कदम है।
संरचित डेटा
संरचित डेटा वह डेटा है जो एक पूर्वनिर्धारित डेटा मॉडल या स्कीमा में फिट होता है। यह विशेष रूप से वित्तीय संचालन, बिक्री और विपणन आंकड़ों, और वैज्ञानिक मॉडलिंग जैसे विवेचनात्मक, संख्यात्मक डेटा को संभालने के लिए उपयोगी है।
संरचित डेटा आमतौर पर मात्रात्मक होता है और इसे इस तरह से व्यवस्थित किया जाता है कि इसे आसानी से खोजा जा सके। इसमें सामान्य प्रकार जैसे नाम, पते, क्रेडिट कार्ड नंबर, फोन नंबर, स्टार रेटिंग, बैंक जानकारी, और अन्य डेटा शामिल हैं जिन्हें संबंधात्मक डेटाबेस में SQL का उपयोग करके आसानी से क्वेरी किया जा सकता है।
वास्तविक दुनिया के अनुप्रयोगों में संरचित डेटा के उदाहरणों में उड़ान बुकिंग के दौरान उड़ान और आरक्षण डेटा, और Salesforce जैसे CRM सिस्टम में ग्राहक व्यवहार और प्राथमिकताएँ शामिल हैं। यह विवेचनात्मक, छोटे, गैर-निरंतर संख्यात्मक और पाठ मानों के संबंधित संग्रह के लिए सबसे अच्छा है और इसका उपयोग इन्वेंटरी नियंत्रण, CRM सिस्टम, और ERP सिस्टम के लिए किया जाता है।
संरचित डेटा को संबंधात्मक डेटाबेस, ग्राफ डेटाबेस, स्थानिक डेटाबेस, OLAP क्यूब्स, और अन्य में संग्रहीत किया जाता है। इसका सबसे बड़ा लाभ यह है कि इसे व्यवस्थित, साफ, खोजने और विश्लेषण करने में आसान होता है, लेकिन मुख्य चुनौती यह है कि सभी डेटा को निर्धारित डेटा मॉडल में फिट होना चाहिए।
असंरचित डेटा
असंरचित डेटा वह डेटा है जिसमें विशेषताओं को पहचानने के लिए कोई अंतर्निहित मॉडल नहीं होता। इसका उपयोग तब किया जाता है जब डेटा संरचित डेटा प्रारूप में फिट नहीं होता, जैसे वीडियो निगरानी, कंपनी दस्तावेज़, और सोशल मीडिया पोस्ट।
असंरचित डेटा के उदाहरणों में विभिन्न प्रारूप शामिल हैं जैसे ईमेल, छवियाँ, वीडियो फ़ाइलें, ऑडियो फ़ाइलें, सोशल मीडिया पोस्ट, PDFs, और अधिक। लगभग 80-90% डेटा असंरचित होता है, जिसका अर्थ है कि यदि कंपनियाँ इसका लाभ उठा सकें तो इसमें प्रतिस्पर्धात्मक लाभ की विशाल संभावनाएँ हैं।
वास्तविक दुनिया के अनुप्रयोगों में असंरचित डेटा के उदाहरणों में चैटबॉट शामिल हैं जो ग्राहक प्रश्नों का उत्तर देने और जानकारी प्रदान करने के लिए पाठ विश्लेषण करते हैं, और डेटा जो निवेश निर्णयों के लिए स्टॉक मार्केट में परिवर्तनों की भविष्यवाणी करने के लिए उपयोग किया जाता है। असंरचित डेटा उन डेटा, वस्तुओं, या फ़ाइलों के संबंधित संग्रह के लिए सबसे अच्छा है जहाँ विशेषताएँ बदलती हैं या अज्ञात होती हैं, और इसका उपयोग प्रस्तुति या शब्द प्रसंस्करण सॉफ़्टवेयर और मीडिया देखने या संपादित करने के उपकरणों के साथ किया जाता है। असंरचित सहायक सेवा डेटा, जैसे सोशल मीडिया पोस्ट और ग्राहक फीडबैक, संरचित प्रारूपों में परिवर्तित होने पर मूल्यवान अंतर्दृष्टि प्रदान कर सकता है।
इसे आमतौर पर डेटा झीलों, NoSQL डेटाबेस, डेटा वेयरहाउस, और अनुप्रयोगों में संग्रहीत किया जाता है। असंरचित डेटा का सबसे बड़ा लाभ यह है कि यह उस डेटा का विश्लेषण करने की क्षमता है जिसे आसानी से संरचित डेटा में आकार नहीं दिया जा सकता, लेकिन मुख्य चुनौती यह है कि इसका विश्लेषण करना कठिन हो सकता है। असंरचित डेटा के लिए मुख्य विश्लेषण तकनीक संदर्भ और उपयोग किए जाने वाले उपकरणों के आधार पर भिन्न होती है।
संरचित और असंरचित डेटा के बीच अंतर
संरचित डेटा के लाभ और असंरचित डेटा के नुकसान
संरचित डेटा आसानी से खोजे जाने और मशीन लर्निंग एल्गोरिदम के लिए उपयोग किए जाने का लाभ प्रदान करता है, जिससे यह व्यवसायों और संगठनों के लिए डेटा की व्याख्या करने के लिए सुलभ होता है। संरचित डेटा का विश्लेषण करने के लिए असंरचित डेटा की तुलना में अधिक उपकरण उपलब्ध हैं। दूसरी ओर, असंरचित डेटा के लिए डेटा वैज्ञानिकों को डेटा को तैयार करने और विश्लेषण करने में विशेषज्ञता की आवश्यकता होती है, जो संगठन में अन्य कर्मचारियों को इससे पहुँचने से प्रतिबंधित कर सकता है। इसके अलावा, असंरचित डेटा से निपटने के लिए विशेष उपकरणों की आवश्यकता होती है, जो इसकी पहुँच की कमी में और योगदान करते हैं।
संरचित डेटा विश्लेषण बनाम असंरचित डेटा विश्लेषण
संरचित डेटा विश्लेषण आमतौर पर अधिक सीधा होता है क्योंकि डेटा को सख्ती से स्वरूपित किया गया है, जिससे विशेष डेटा प्रविष्टियों को खोजने और स्थानांतरित करने के लिए प्रोग्रामिंग लॉजिक का उपयोग करना संभव होता है, साथ ही प्रविष्टियों को बनाने, हटाने या संपादित करने की अनुमति मिलती है। यह संरचित डेटा के डेटा प्रबंधन और विश्लेषण को स्वचालित करने में अधिक कुशल बनाता है। इसके विपरीत, असंरचित डेटा विश्लेषण में पूर्वनिर्धारित विशेषताएँ नहीं होती हैं, जिससे इसे खोजने और व्यवस्थित करने में अधिक कठिनाई होती है। असंरचित डेटा विश्लेषण अक्सर पूर्व-प्रसंस्करण, हेरफेर, और विश्लेषण के लिए जटिल एल्गोरिदम की आवश्यकता होती है, जो विश्लेषण प्रक्रिया में एक बड़ा चुनौती प्रस्तुत करता है। असंरचित सहायक सेवा डेटा के विश्लेषण के लिए अक्सर महत्वपूर्ण जानकारी निकालने के लिए उन्नत पार्सिंग तकनीकों की आवश्यकता होती है।
संरचित डेटा प्रबंधन बनाम असंरचित डेटा प्रबंधन
संरचित डेटा का प्रबंधन सामान्यतः अधिक कुशल होता है क्योंकि इसकी संगठित और पूर्वानुमानित प्रकृति होती है। कंप्यूटर, डेटा संरचनाएँ, और प्रोग्रामिंग भाषाएँ संरचित डेटा को अधिक आसानी से समझ सकती हैं, जिससे इसके उपयोग में न्यूनतम चुनौतियाँ होती हैं। इसके विपरीत, असंरचित डेटा प्रबंधन दो महत्वपूर्ण चुनौतियों का सामना करता है: भंडारण, क्योंकि असंरचित डेटा प्रबंधन आमतौर पर संरचित डेटा प्रबंधन की तुलना में बड़े प्रसंस्करण का सामना कर रहा होता है, और विश्लेषण, क्योंकि असंरचित डेटा प्रबंधन संरचित डेटा प्रबंधन के विश्लेषण की तुलना में उतना सीधा नहीं होता। असंरचित डेटा को समझने और प्रबंधित करने के लिए, कंप्यूटर सिस्टम को पहले इसे समझने योग्य घटकों में तोड़ना होगा, जो एक अधिक जटिल प्रक्रिया है।
संरचित और असंरचित डेटा के बीच अंतर का सारांश
संरचित डेटा परिभाषित और खोजने योग्य होता है, जिसमें तिथियाँ, फोन नंबर, और उत्पाद SKU जैसे डेटा शामिल होते हैं। यह असंरचित डेटा की तुलना में इसे व्यवस्थित, साफ, खोजने, और विश्लेषण करने में आसान बनाता है, जो अन्य सभी चीजों को शामिल करता है जो वर्गीकृत या खोजने में अधिक कठिन होते हैं, जैसे फ़ोटो, वीडियो, पॉडकास्ट, सोशल मीडिया पोस्ट, और ईमेल। संरचित और असंरचित डेटा के बीच अंतर को समझाने के लिए एक वाक्य: दुनिया में अधिकांश डेटा असंरचित है, लेकिन संरचित डेटा के प्रबंधन और विश्लेषण की आसानी इसे उन अनुप्रयोगों में महत्वपूर्ण बढ़त देती है जहाँ डेटा को ठीक से व्यवस्थित और जल्दी से पहुँचाया जा सकता है।
संरचित और असंरचित डेटा के उदाहरण
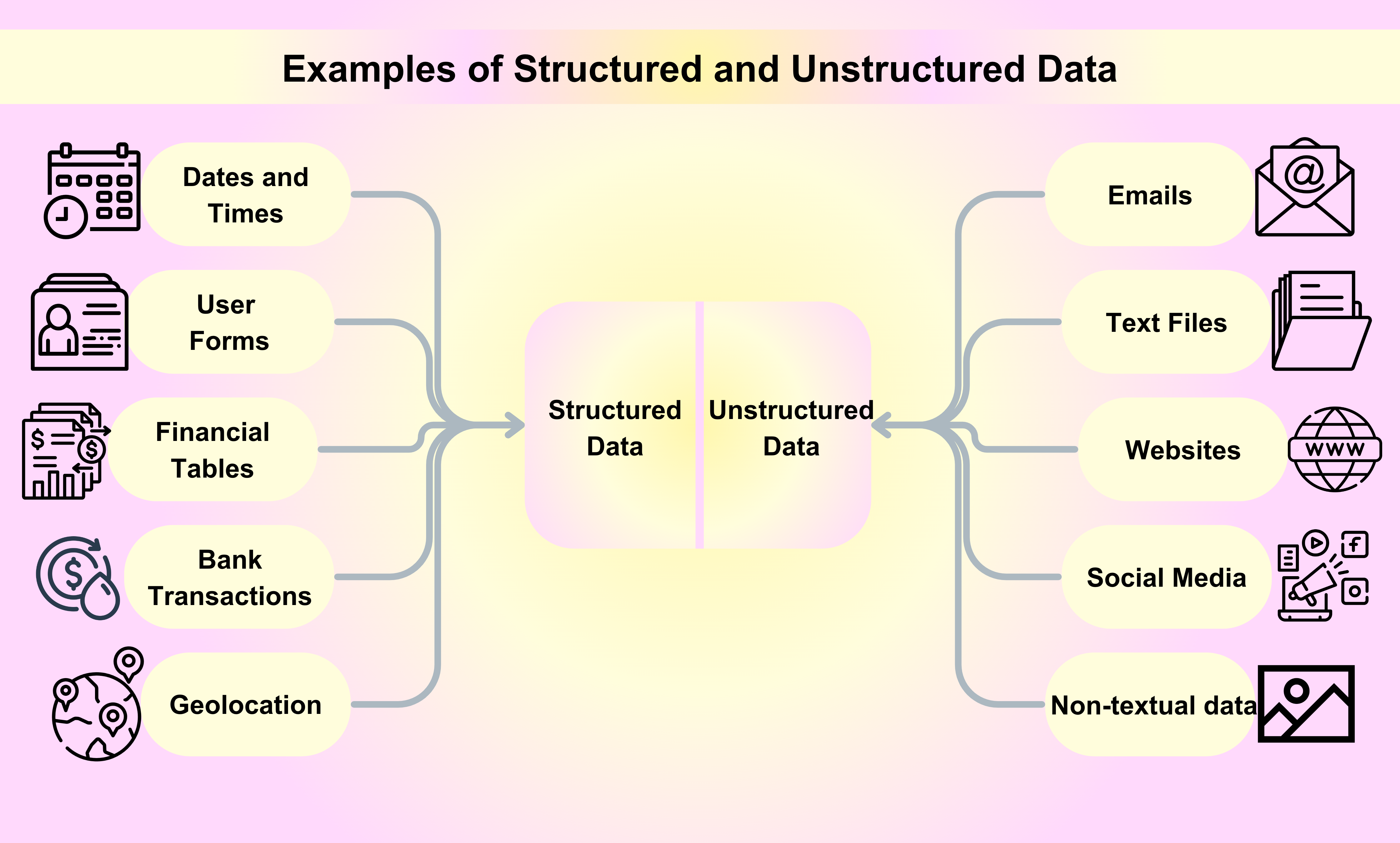
संरचित डेटा के उदाहरण
-
तिथियाँ और समय: तिथियाँ और समय एक विशिष्ट प्रारूप का पालन करते हैं, जिससे मशीनों के लिए उन्हें पढ़ना और विश्लेषण करना आसान हो जाता है। उदाहरण के लिए, एक तिथि को YYYY-MM-DD के रूप में संरचित किया जा सकता है, जबकि समय को HH:MM:SS के रूप में संरचित किया जा सकता है।
-
ग्राहक नाम और संपर्क जानकारी: जब आप किसी सेवा के लिए साइन अप करते हैं या ऑनलाइन उत्पाद खरीदते हैं, तो आपका नाम, ईमेल पता, फोन नंबर, और अन्य संपर्क जानकारी एक संरचित तरीके से एकत्रित और संग्रहीत की जाती है।
-
वित्तीय लेनदेन: वित्तीय लेनदेन जैसे क्रेडिट कार्ड लेनदेन, बैंक जमा, और वायर ट्रांसफर सभी संरचित डेटा के उदाहरण हैं। प्रत्येक लेनदेन में एक विशिष्ट जानकारी होती है जैसे एक अनुक्रम संख्या, एक लेनदेन तिथि, राशि, और शामिल पक्ष।
-
स्टॉक जानकारी: स्टॉक जानकारी जैसे शेयर की कीमतें, व्यापार मात्रा, और बाजार पूंजीकरण एक और उदाहरण है संरचित डेटा का। यह जानकारी व्यवस्थित रूप से व्यवस्थित और वास्तविक समय में अपडेट की जाती है।
-
भौगोलिक स्थिति: भौगोलिक स्थिति डेटा, जिसमें GPS निर्देशांक और IP पते शामिल हैं, विभिन्न अनुप्रयोगों में उपयोग किया जाता है, जैसे नेविगेशन सिस्टम से लेकर स्थान-आधारित विपणन अभियानों तक।
असंरचित डेटा के उदाहरण
-
ईमेल: ईमेल हमारे द्वारा हर दिन व्यापार या व्यक्तिगत उद्देश्यों के लिए उपयोग किए जाने वाले सबसे लोकप्रिय असंरचित डेटा उदाहरणों में से एक हैं।
-
पाठ फ़ाइलें: असंरचित डेटा के उदाहरणों में वर्ड प्रोसेसिंग फ़ाइलें, स्प्रेडशीट, PDF फ़ाइलें, रिपोर्ट, और प्रस्तुतियाँ शामिल हैं।
-
वेबसाइटें: वेबसाइटों से सामग्री जैसे YouTube, Instagram, और Flickr को असंरचित डेटा के उदाहरण के रूप में माना जाता है।
-
सोशल मीडिया: फेसबुक, ट्विटर, और लिंक्डइन जैसे सोशल मीडिया प्लेटफार्मों से उत्पन्न डेटा असंरचित डेटा का उदाहरण है।
-
मीडिया: डिजिटल छवियाँ, ऑडियो रिकॉर्डिंग, और वीडियो असंरचित डेटा के उदाहरणों के रूप में गैर-पाठ्य डेटा की एक बड़ी मात्रा का प्रतिनिधित्व करते हैं।
संरचित डेटा विश्लेषण के लिए तकनीकें
-
SQL क्वेरी: संरचित डेटा को SQL (संरचित क्वेरी भाषा) का उपयोग करके कुशलता से क्वेरी किया जा सकता है, जो संबंधात्मक डेटाबेस में संग्रहीत डेटा की त्वरित पुनर्प्राप्ति और हेरफेर की अनुमति देता है।
-
डेटा वेयरहाउसिंग: संरचित डेटा को डेटा वेयरहाउस में संग्रहीत किया जा सकता है, जो कई स्रोतों से डेटा को एकीकृत करता है और जटिल क्वेरी और विश्लेषण का समर्थन करता है।
-
मशीन लर्निंग एल्गोरिदम: एल्गोरिदम संरचित डेटा को पहचानने के लिए आसानी से संसाधित कर सकते हैं और भविष्यवाणियाँ कर सकते हैं।
संरचित डेटा को समझना और हेरफेर करना आसान होता है, जिससे यह उपयोगकर्ताओं के एक विस्तृत वर्ग के लिए सुलभ होता है। संरचित डेटा कुशल भंडारण, पुनर्प्राप्ति, और विश्लेषण की अनुमति देता है, जिससे निर्णय लेने की प्रक्रियाएँ तेज होती हैं। संरचित डेटा सिस्टम बड़े डेटा वॉल्यूम को संभालने के लिए स्केल कर सकते हैं, यह सुनिश्चित करते हुए कि डेटा बढ़ने पर प्रदर्शन उच्च बना रहे।
असंरचित डेटा विश्लेषण के लिए तकनीकें
-
प्राकृतिक भाषा प्रसंस्करण (NLP): NLP तकनीकों का उपयोग पाठ डेटा का विश्लेषण करने के लिए किया जाता है, जिससे बड़े मात्रा में असंरचित पाठ से अर्थपूर्ण जानकारी और अंतर्दृष्टि निकाली जा सके।
-
मशीन लर्निंग: मशीन लर्निंग एल्गोरिदम को असंरचित डेटा में पैटर्न पहचानने के लिए प्रशिक्षित किया जा सकता है, जैसे छवियाँ या ऑडियो फ़ाइलें।
-
डेटा झीलें: असंरचित डेटा को डेटा झीलों में संग्रहीत किया जा सकता है, जो विश्लेषण के लिए आवश्यक होने तक कच्चे डेटा को इसके मूल प्रारूप में संग्रहीत करने की अनुमति देती हैं।
असंरचित डेटा विश्लेषण तकनीकों के उदाहरण से, असंरचित डेटा का विश्लेषण अधिक जटिल होता है और इसके लिए विशेष उपकरणों और तकनीकों की आवश्यकता होती है। असंरचित डेटा को संसाधित करने के लिए अक्सर महत्वपूर्ण कंप्यूटेशनल संसाधनों और भंडारण क्षमता की आवश्यकता होती है। असंरचित डेटा में असंगतताएँ, त्रुटियाँ, या अप्रासंगिक जानकारी हो सकती है, जिससे डेटा गुणवत्ता सुनिश्चित करना चुनौतीपूर्ण हो जाता है। डेटा अधिग्रहण को सुव्यवस्थित करना एक संगठन की बड़ी मात्रा में डेटा को प्रबंधित और विश्लेषण करने की क्षमता को महत्वपूर्ण रूप से बढ़ा सकता है।
असंरचित डेटा को संरचित डेटा में परिवर्तित करने की आवश्यकता के उदाहरण
-
ग्राहक फीडबैक विश्लेषण: ग्राहक समीक्षाओं और फीडबैक को असंरचित पाठ से संरचित डेटा में परिवर्तित करना व्यवसायों को भावना विश्लेषण करने और ग्राहक संतोष में प्रवृत्तियों की पहचान करने की अनुमति देता है।
-
चिकित्सा रिकॉर्ड: असंरचित चिकित्सा रिकॉर्ड, जैसे डॉक्टर की नोट्स और इमेजिंग रिपोर्ट को संरचित करना इलेक्ट्रॉनिक स्वास्थ्य रिकॉर्ड (EHR) सिस्टम के साथ बेहतर एकीकरण की अनुमति देता है और रोगी की देखभाल में सुधार करता है।
-
अनुपालन और रिपोर्टिंग: डेटा अधिग्रहण की प्रक्रिया में विभिन्न स्रोतों से डेटा को निकालना, लोड करना, और रूपांतरित करना शामिल होता है ताकि विश्लेषण के लिए उपयुक्त प्रारूप में लाया जा सके। संगठनों को नियामक आवश्यकताओं का पालन करने और सटीक रिपोर्टिंग को सुगम बनाने के लिए असंरचित डेटा को संरचित प्रारूपों में परिवर्तित करने की आवश्यकता हो सकती है।
-
बाजार अनुसंधान: सर्वेक्षणों और फोकस समूहों से असंरचित डेटा को संरचित डेटा में परिवर्तित करना बाजार प्रवृत्तियों और उपभोक्ता व्यवहार का विश्लेषण करने में मदद करता है।
AnyParser कैसे असंरचित डेटा को संरचित डेटा में पार्स कर सकता है
AnyParser, जो CambioML द्वारा विकसित किया गया है, एक शक्तिशाली दस्तावेज़ पार्सिंग उपकरण है जो विभिन्न असंरचित डेटा स्रोतों जैसे PDFs, छवियों, और चार्ट से जानकारी निकालने और उन्हें संरचित प्रारूपों में परिवर्तित करने के लिए डिज़ाइन किया गया है। यह डेटा निकालने में उच्च सटीकता और दक्षता प्राप्त करने के लिए उन्नत विज़न भाषा मॉडलों (VLMs) का लाभ उठाता है।
प्रमुख विशेषताएँ
-
सटीकता: मूल लेआउट और प्रारूप बनाए रखते हुए पाठ, संख्याएँ, और प्रतीक को सटीक रूप से निकालता है।
-
गोपनीयता: उपयोगकर्ता की गोपनीयता और संवेदनशील जानकारी की सुरक्षा सुनिश्चित करने के लिए डेटा को स्थानीय रूप से संसाधित करता है।
-
कस्टमाइबिलिटी: उपयोगकर्ताओं को कस्टम निकासी नियम और आउटपुट प्रारूप परिभाषित करने की अनुमति देता है।
-
बहु-स्रोत समर्थन: PDFs, छवियों, और चार्ट सहित विभिन्न असंरचित डेटा स्रोतों से निकासी का समर्थन करता है।
-
संरचित आउटपुट: निकाली गई जानकारी को Markdown, CSV, या JSON जैसे संरचित प्रारूपों में परिवर्तित करता है।
AnyParser का उपयोग करके असंरचित डेटा को पार्स करने के चरण
-
अपने दस्तावेज़ को अपलोड करें: AnyParser के वेब इंटरफेस पर अपने असंरचित डेटा फ़ाइल (जैसे, PDF, छवि) को अपलोड करके शुरू करें। आप अपने फ़ाइल को खींचकर छोड़ सकते हैं या त्वरित प्रसंस्करण के लिए स्क्रीनशॉट चिपका सकते हैं।
-
निकासी विकल्प चुनें: उस प्रकार के डेटा का चयन करें जिसे आप निकालना चाहते हैं। उदाहरण के लिए, यदि आपको PDF से तालिकाएँ निकालने की आवश्यकता है, तो 'केवल तालिका' विकल्प चुनें।
-
दस्तावेज़ को संसाधित करें: AnyParser का API इंजन दस्तावेज़ को संसाधित करेगा, आवश्यक जानकारी को सटीक रूप से पहचानते और निकालते हुए। यह उपकरण प्रासंगिक डेटा बिंदुओं की पहचान करने और उन्हें संरचित प्रारूप में परिवर्तित करने के लिए उन्नत VLM तकनीकों का उपयोग करता है।
-
पूर्वावलोकन और सत्यापित करें: AnyParser की पूर्वावलोकन सुविधा का उपयोग करके निकाली गई डेटा की समीक्षा करें। सटीकता सुनिश्चित करने के लिए प्रारंभिक निकासी की तुलना मूल दस्तावेज़ से करें।
-
डाउनलोड या निर्यात करें: एक बार निकासी से संतुष्ट होने पर, संरचित डेटा फ़ाइल (जैसे, CSV, Excel) डाउनलोड करें या आगे के विश्लेषण के लिए सीधे Google Sheets जैसे प्लेटफार्मों पर निर्यात करें।
AnyParser का उपयोग करने के लाभ
-
कुशलता और सटीकता: डेटा निकालने के कार्यों को स्वचालित करता है, मैन्युअल प्रयास को कम करता है और त्रुटियों को न्यूनतम करता है।
-
डेटा सुरक्षा: सुनिश्चित करता है कि संवेदनशील जानकारी स्थानीय रूप से संसाधित की जाती है, डेटा गोपनीयता मानकों का पालन करते हुए।
-
लचीला अनुकूलन: उपयोगकर्ता विशिष्ट आवश्यकताओं के अनुरूप निकासी पैरामीटर और आउटपुट प्रारूप को अनुकूलित कर सकते हैं।
-
विश्लेषणात्मक ध्यान में वृद्धि: डेटा निकालने को सरल बनाता है, जिससे पेशेवर उच्च मूल्य के विश्लेषण पर ध्यान केंद्रित कर सकते हैं।
अनुप्रयोग
-
AI इंजीनियर्स: AI मॉडल विकसित करने और प्रशिक्षित करने के लिए PDFs से पाठ और लेआउट जानकारी निकालें।
-
वित्तीय विश्लेषक: सटीक वित्तीय विश्लेषण के लिए PDF तालिकाओं से संख्यात्मक डेटा निकालें।
-
डेटा वैज्ञानिक: अंतर्दृष्टि और प्रवृत्तियों को उजागर करने के लिए बड़े मात्रा में असंरचित दस्तावेज़ों को संसाधित करें।
-
उद्यम: विभिन्न दस्तावेजों, जैसे अनुबंधों और रिपोर्टों के प्रसंस्करण और विश्लेषण को स्वचालित करें, जिससे परिचालन दक्षता में सुधार हो सके।
AnyParser का लाभ उठाकर, उपयोगकर्ता जटिल असंरचित डेटा को संरचित, संपादनीय फ़ाइलों में परिवर्तित कर सकते हैं, जिन्हें उनके कार्यप्रवाह में सहजता से एकीकृत किया जा सकता है ताकि डेटा विश्लेषण और प्रबंधन में सुधार हो सके।
निष्कर्ष
डिजिटल युग में, असंरचित डेटा को संरचित प्रारूपों में परिवर्तित करना, जैसे कि AnyParser का उपयोग करना, व्यवसायों के लिए अंतर्दृष्टियों को अनलॉक करने और प्रतिस्पर्धात्मक बढ़त प्राप्त करने के लिए महत्वपूर्ण है। AnyParser का उपयोग असंरचित सहायक सेवा डेटा को पार्स करने के लिए किया जा सकता है, जिससे इसे व्यावसायिक बुद्धिमत्ता प्रणालियों में एकीकृत करना आसान हो जाता है। इस प्रक्रिया को सुव्यवस्थित करके, संगठन अपने डेटा की पूरी क्षमता को प्रभावी ढंग से harness कर सकते हैं, बेहतर निर्णय लेने और रणनीतिक योजना को बढ़ावा दे सकते हैं।