Az adatkezelés világában a parsing a tartalom—például szöveg, képek, táblázatok és metaadatok—használható formátumba (pl. sima szöveg, strukturált adatok vagy képek) való átkonvertálását jelenti, amely további feldolgozásra vagy elemzésre kerülhet. Ennek legnyilvánvalóbb példája a PDF parsing, amely egy kulcsfontosságú folyamat, amely a nyers információt strukturált, felhasználható adatokba alakítja. Ez a részletes útmutató a PDF parsing bonyolultságait tárgyalja, tisztázva annak definícióját, az általa kinyerhető adatok spektrumát, a kihívásokat, sokrétű alkalmazásait, valamint a rendelkezésre álló módszerek gazdagságát, amelyek segítségével teljes potenciálját kihasználhatjuk. Felfedezi a különböző parsing módszereket, különös figyelmet fordítva a PDF parsingra és arra, hogy az olyan eszközök, mint az AnyParser, hogyan tűnnek ki a tömegből.
A PDF Parser Megértése: Mi az a Parsing?
Mi a parsing: gondos adatgyűjtési folyamat
Alapvetően a PDF parsing a PDF (Portable Document Format) fájlokból való adatkinyerés és értelmezés folyamatát jelenti. Mivel a PDF-eket elsősorban megjelenítésre tervezték, nem pedig strukturált adatok tárolására, a parsing a tartalom—például szöveg, képek, táblázatok és metaadatok—használható formátumba (pl. sima szöveg, strukturált adatok vagy képek) való átkonvertálását jelenti, amely további feldolgozásra vagy elemzésre kerülhet. A parsing magas szintű elemzést igényel, hogy azonosítsa és visszanyerje a PDF-en belüli specifikus elemeket, amelyek túlmutatnak a puszta szövegen és képeken, magukban foglalva a betűtípusokat, elrendezéseket, táblázatokat és metaadatokat. Ez a folyamat nem csupán technikai részlet, hanem szükségszerűség olyan iparágakban, mint a pénzügy, jog, logisztika és egészségügy, ahol az információ újrafelhasználása alapvető fontosságú.
A PDF-ekből Kinyerhető Adatok
A PDF-ekből kinyerhető adatok változatosak és széleskörűek, beleértve:
-
Szöveges bekezdések: Szavak és karakterek sorozatai.
-
Egyedi adatmezők: Olyan egyedi elemek, mint dátumok, nyomkövetési számok és nevek.
-
Táblázatos adatok: Információk táblázatokba és listákba rendezve.
-
Képek: A PDF-be beágyazott grafikai tartalom.
-
Fejlettebb elemek: Fejléc, objektumok, kereszt-referencia táblák, trailer és metaadatok, amelyek bonyolultabb parsing eszközöket igényelnek.
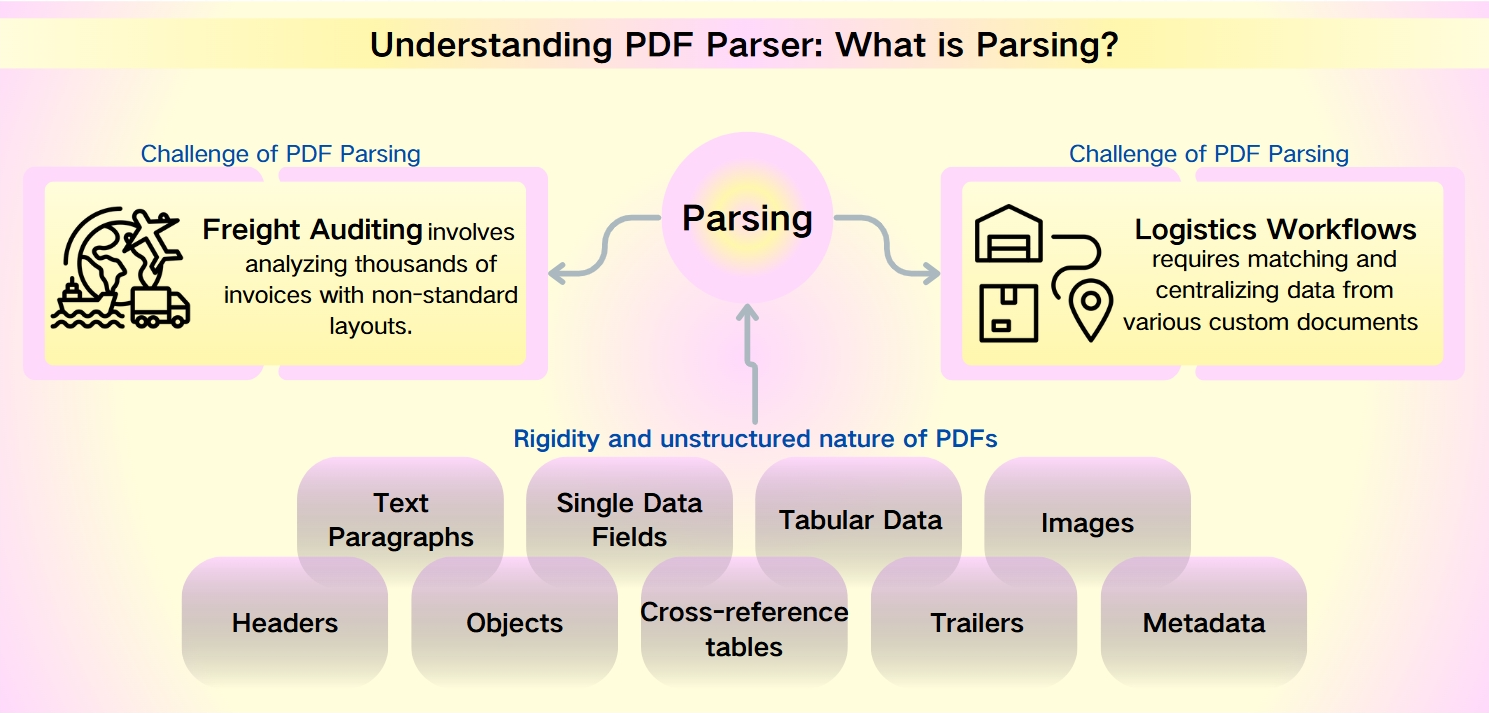
A PDF Parsing Kihívásai: a PDF metaadatainak struktúrázatlan természete
A PDF-ek robusztussága—amelyet biztonságuk, eszközkompatibilitásuk és tömör fájlméretük jellemez—ellenére az adatok kinyerése belőlük komoly kihívást jelent. A PDF-ek merevsége és struktúrázatlan természete megnehezíti a gyors elemzést és az információk visszakeresését. Ez különösen kifejezett olyan helyzetekben, mint a szállítmányok ellenőrzése és a logisztikai munkafolyamatok, ahol a nem szabványos elrendezések és a hatalmas adathalmazok fokozzák a bonyolultságot.
A szállítmányok ellenőrzése több ezer, nem szabványos elrendezésű számla elemzését jelenti. A logisztikai munkafolyamatok megkövetelik az adatok összehangolását és központosítását különböző egyedi dokumentumokból, mint például csomaglisták, kereskedelmi számlák és fuvarlevelek.
A Parsing Jelentősége
A parsing alapvető szerepet játszik különböző területeken, a webfejlesztéstől az adatgyűjtésig. Lehetővé teszi a vállalkozások számára, hogy értékes betekintéseket nyerjenek ki struktúrázatlan adatforrásokból, mint például PDF dokumentumok, HTML fájlok és XML adatok. A parsing elősegíti:
-
A döntéshozatal javítását adatvezérelt betekintések révén.
-
Az adatok pontosságának és következetességének növelését.
-
Az adatok feldolgozásának és elemzésének egyszerűsítését.
-
Az információk hatékony visszakeresését és tárolását.
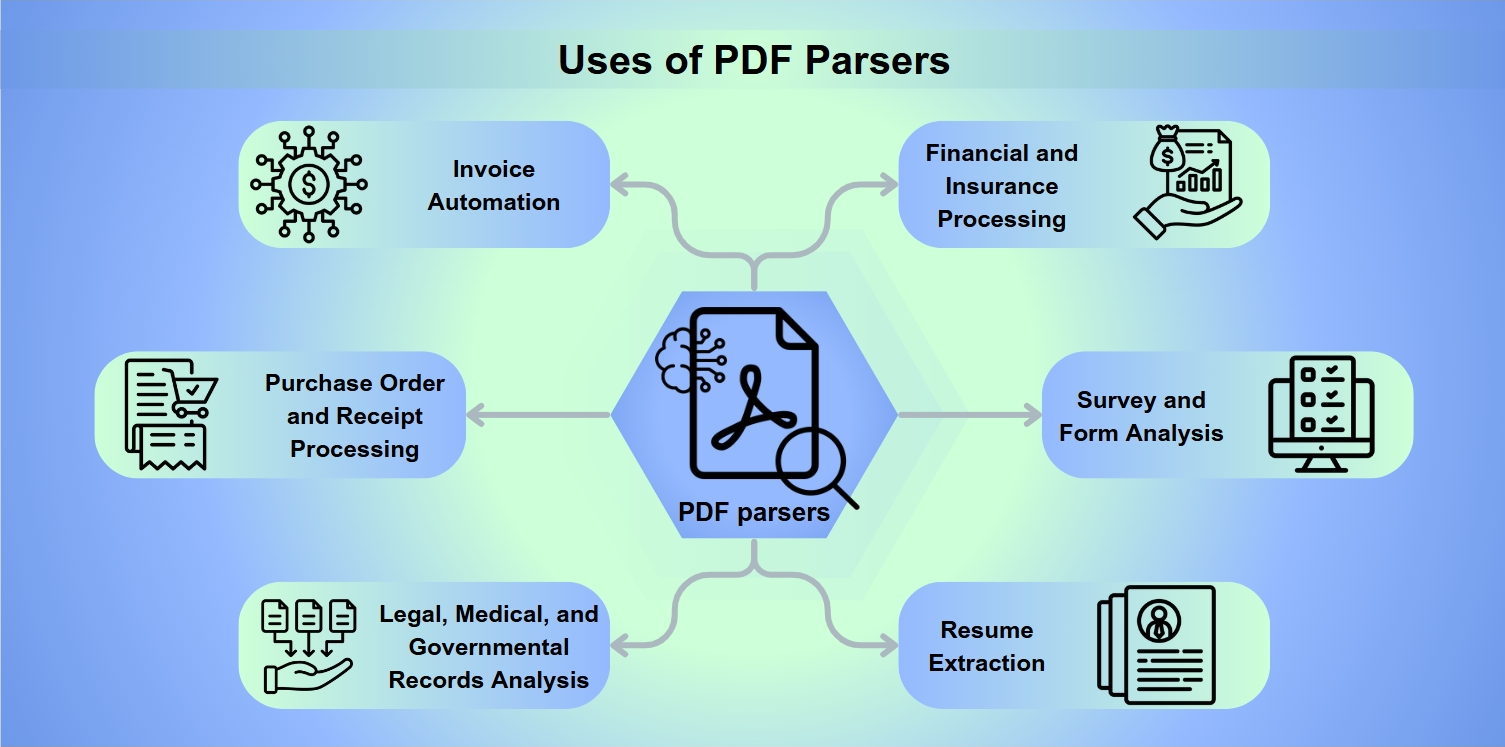
A PDF Parserek Használata
A PDF parserek nélkülözhetetlen eszközök számos alkalmazásban, beleértve:
-
Számlaautomatizálás: A számlák feldolgozásának és kifizetésének egyszerűsítése.
-
Megrendelések és nyugták feldolgozása: Visszatérítések és kártalanítások elősegítése.
-
Jogi, orvosi és kormányzati nyilvántartások elemzése: Mélyreható adatkinyerés lehetővé tétele az elemzéshez.
-
Pénzügyi és biztosítási feldolgozás: Kockázatok értékelése és mérleg elemzése.
-
Kérdőívek és űrlapok elemzése: Űrlapválaszok gyűjtése és értelmezése.
-
Önéletrajzok kinyerése: A toborzók segítése a jelöltek előszűrésében.
Különböző Parsing Módszerek Összehasonlítása
Az adatkinyerési módszerek az idő múlásával jelentősen fejlődtek. A hagyományos adatgyűjtési megközelítések gyakran a reguláris kifejezések (regex) használatára támaszkodnak a szövegből történő specifikus minták kinyerésére. Bár hatékony, a regex bonyolulttá és karbantarthatatlanná válhat összetett parsing feladatok esetén. Egy másik gyakori technika a szövegmanipuláció, amely a szöveg felosztását és feldolgozását jelenti elválasztók vagy specifikus karakterek alapján. Ezek a módszerek, bár bizonyos helyzetekben még mindig hasznosak, küzdhetnek a struktúrázatlan vagy következetlen adatformátumokkal.
A PDF parsing táját különféle módszerek szolgálják ki, mindegyik saját egyedi előnyeivel és hátrányaival:
-
Online PDF Konverterek/Parsers: Mint például a Zamzar és a Smallpdf, kényelmet és sebességet kínálnak, de funkcióik korlátozottak és potenciálisan nem biztonságosak.
-
Adobe Acrobat: Megőrzi a struktúrát és a formázást, de a konverzió után manuális beállításokat igényelhet.
-
Másolás és Beillesztés: Teljes ellenőrzést biztosít, de fárasztó és hibákra hajlamos.
-
Automatizált Platformok: A modern parsing technológiák, mint az AnyParser, gépi tanulást és természetes nyelvfeldolgozást (NLP) használnak a bonyolultabb adatstruktúrák kezelésére.
Ezek az AI-vezérelt megközelítések képesek megérteni a kontextust és a szemantikát, így különösen hatékonyak a struktúrázatlan szöveg vagy változó formátumú dokumentumok parsingjában. Néhány fejlett parser mélytanulási modelleket használ a releváns információk azonosítására és kinyerésére, magas pontossággal, még a korábban nem látott dokumentumelrendezésekből is.
Hogyan Végezhetünk PDF Parsingot: A Legjobb Ingyenes PDF Parser a PDF Metaadatok Kinyerésére
A PDF Metaadatok Megértése
A PDF metaadatok fontos információkat tartalmaznak egy dokumentumról, beleértve annak címét, szerzőjét, létrehozási dátumát és kulcsszavait. E metaadatok hatékony kinyerése elengedhetetlen a PDF fájlok nagy gyűjteményeinek rendszerezéséhez, kereséséhez és kezeléséhez. Egy robusztus PDF parser egyszerűsítheti ezt a folyamatot, időt takarítva meg és javítva a munkafolyamatok termelékenységét.
A Legjobb PDF Parserek Kulcsfontosságú Jellemzői
A legjobb ingyenes PDF parserek a pontosság, sebesség és sokoldalúság kombinációját kínálják. Képesek kell, hogy legyenek különböző PDF formátumok kezelésére, beleértve a beolvasott dokumentumokat és a bonyolult elrendezésű fájlokat. Olyan parsereket keressen, amelyek nemcsak alapvető metaadatokat, hanem egyedi mezőket és rejtett információkat is ki tudnak nyerni. Ezenkívül a csúcsminőségű parserek gyakran lehetőségeket kínálnak a PDF adatok kinyerésére, a kötegelt feldolgozásra és más szoftverrendszerekkel való integrációra.
Az AnyParser Jellemzői
Az AnyParser, amelyet a CambioML fejlesztett, különösen figyelemre méltó a pontossága, adatvédelme és konfigurálhatósága miatt. Az AnyParser képessége, hogy több fájlformátumot kezel, felhasználóbarát felülete és skálázhatósága kiváló választássá teszi minden méretű vállalkozás számára. Ezenkívül API-ja lehetővé teszi a zökkenőmentes integrációt a meglévő munkafolyamatokba, javítva a dokumentumkezelés hatékonyságát. Íme néhány kulcsfontosságú jellemző, amely az AnyParser-t kiváló választássá teszi a PDF parsinghoz:
-
Pontosság: Az AnyParser-t úgy tervezték, hogy pontosan kinyerje a szöveget, számokat és szimbólumokat, miközben megőrzi az eredeti elrendezést és formátumot. Fejlett nyelvi modelleket használ a dokumentumok megértésének és az információk kinyerésének javítására, akár 2x magasabb pontossági arányt kínálva a hagyományos OCR modellekhez képest.
-
Adatvédelem: Támogatja a helyi és felhő alapú adatkinyerést, biztosítva, hogy az érzékeny információk privátak és biztonságosak maradjanak.
-
Konfigurálhatóság: A felhasználók testreszabhatják a kinyerési szabályokat és a kimeneti formátumokat, hogy megfeleljenek a specifikus igényeknek.
-
Többforrás Támogatás: Az AnyParser különböző dokumentumtípusokat támogat, beleértve a PDF-eket, képeket és diagramokat.
-
Strukturált Kimenet: A kinyert információk strukturált formátumokká alakíthatók, mint például Markdown, Excel vagy JSON, megkönnyítve a további feldolgozást és elemzést.
-
Felhőalapú Telepítési Lehetőségek: Az AnyParser SDK felhőben, adatközpontokban vagy privát módon telepíthető, rugalmasságot és skálázhatóságot kínálva.
-
Felhasználóbarát Felület: Az eszköz egyszerű API-t kínál, amely lehetővé teszi a bonyolult dokumentum parsing feladatok elvégzését mindössze néhány kódsorral.
-
Magas Teljesítmény: Az optimalizált algoritmusok biztosítják a nagy számú dokumentum gyors feldolgozását, akár 5X gyorsabban, mint az általános LLM-ek, mint a GPT4o.
-
Közösségi Támogatás: Mint nyílt forráskódú projekt, az AnyParser aktív közösséggel rendelkezik, és örömmel fogadja a hozzájárulásokat.
-
Ingyenes Használati Kvóta: Az AnyParser ingyenes használati kvótát kínál minden fiókhoz, lehetővé téve a felhasználók számára, hogy teszteljék az eszköz képességeit, mielőtt elköteleződnének egy fizetős terv mellett.
-
Vásárlói Visszajelzés: A felhasználók dicsérték az AnyParser-t a magas pontossága, adatvédelme és az adatkinyerés hatékonysága miatt, esettanulmányok mutatják a jelentős időmegtakarítást és a javított adatminőséget.
Ezek az előnyök értékes PDF adatkinyerő eszközzé teszik az AnyParser-t a dokumentumok parsingjához és információk kinyeréséhez, különösen az olyan vállalati felhasználók számára, akik magas pontosságot és biztonságot igényelnek. A folyamatos technológiai fejlődés és az aktív közösségi részvétel révén az AnyParser egyre fontosabb szerepet játszik a dokumentum parsing és információk kinyerésének területén.
A PDF Parserek Technikai Magyarázata
A PDF parsing fogalmilag hasonlít a web scrapinghez, mégis hiányzik belőle a HTML strukturált hierarchiája. Míg a webdokumentumokat elérhető HTML tagek segítségével parse-olják, a PDF-ek egy lapos karakter- és pixelmátrixot mutatnak, amely bonyolultabb algoritmusokat és könyvtárakat igényel az adatok kinyeréséhez.
PDF Parser vs Python PDF Parser: Kulcsfontosságú Különbségek
A PDF parser gyakran egy önálló eszköz, mint PDF adatkinyerő vagy könyvtár, amelyet kifejezetten PDF fájlokból való adatkinyerésre terveztek. Ezek a parserek általában felhasználóbarát felületeket kínálnak, és minimális kódolási ismereteket igényelnek. Ezzel szemben a Python PDF parserek modulok vagy könyvtárak, amelyek integrálódnak a Python szkriptekbe, nagyobb rugalmasságot biztosítva, de programozási szakértelmet igényelnek.
A fejlesztők finomhangolhatják a parsing folyamatot, végrehajthatják a fejlett szövegelemzést, és zökkenőmentesen integrálhatják a PDF adatok kinyerését szélesebb Python alkalmazásokba. A PDF parserek, bár a testreszabás szempontjából korlátozottabbak, mint a Python PDF parserek, gyakran előre elkészített funkciókat kínálnak a gyakori felhasználási esetekhez, így ideálisak azok számára, akik gyors eredményekre vágynak, anélkül hogy kiterjedt programozásra lenne szükségük.
Az AnyParser Előnyei a VLM-el az Adat Parsinghoz
-
Magas Pontosság: Az AnyParser VLM-jei biztosítják, hogy az adatkinyerés magas hűséggel történjen, még bonyolult dokumentumelrendezések esetén is.
-
Sebesség: A konverziós sebesség terén élen jár, növelve a termelékenységet azáltal, hogy csökkenti a dokumentumok feldolgozásához szükséges időt.
-
Felhasználóbarát: Az AnyParser egyszerű felületet kínál, amely minden szintű felhasználó számára hozzáférhetővé teszi.
-
Sokoldalúság: A PDF-eken túl az AnyParser egy erőteljes képből Excelbe konvertáló eszköz, amely támogatja a különböző dokumentumtípusokat.
Következtetés
A PDF parsing több mint egy technikai folyamat; ez egy kapu, amely átalakítja, hogyan kezelik a vállalkozások az adatokat. A kihívások ellenére a szoftvermegoldások fejlődése lehetővé tette, hogy soha nem volt még ilyen könnyen hozzáférhető. Akár számlák feldolgozásáról, akár bonyolult adat-elemzésről van szó, a megfelelő PDF parser kiválasztása elengedhetetlen. Arról van szó, hogy megtaláljuk azt az eszközt, amely a pontosság, biztonság és hatékonyság tökéletes egyensúlyát kínálja, hogy támogassa adatvezérelt kezdeményezéseinket.
Kezdje El Ingyenes Próbáját Ma
Készen áll arra, hogy forradalmasítsa dokumentumfeldolgozását? Próbálja ki az AnyParser-t INGYEN, hitelkártya nélkül, a https://www.cambioml.com/sandbox oldalon. Az ingyenes próba lehetővé teszi, hogy dokumentumonként legfeljebb 10 oldalt dolgozzon fel, legfeljebb 10 MB fájlmérettel. Tapasztalja meg első kézből, hogyan alakíthatja át az AnyParser PDF parser a struktúrázatlan adatok és dokumentumok kinyerésének megközelítését. Ne hagyja ki ezt a lehetőséget, hogy javítsa adat-elemzési képességeit és egyszerűsítse munkafolyamatát a legmodernebb AI technológiával.