A bonyolult PDF-ek Markdown formátumba történő konvertálása kihívást jelenthet. Számos nyílt forráskódú könyvtár áll rendelkezésre a PDF-ből történő szövegek kinyerésére, de amikor bonyolult elemeket, például táblázatokat és diagramokat tartalmazó PDF-ekről van szó, az eredmények gyakran elmaradnak a várttól. Népszerű nagy nyelvi modellek, mint a GPT vagy a Claude képesek kezelni ezeket a feladatokat, de általában lassúak, és néha pontatlan kimeneteket produkálnak. A hagyományos OCR eszközök, bár hatékonyak egyszerűbb dokumentumok esetén, gyakran küzdenek az eredeti tartalom pontos struktúrájának és szemantikai jelentésének megőrzésével. Másrészt a vision-language modellek néha hallucinálnak, ami téves parsing eredményekhez vezet. Ez a blog elmagyarázza, mit jelent a parsing, és részletezi a különböző modellek összehasonlító elemzésének eredményeit, több metrika felhasználásával.
Mit jelent a parsing?
A PDF parsing kontextusában a "parsing" a PDF fájl specifikus adatainak kinyerésére utal, amelyet egy PDF parser nevű speciális szoftver segítségével végeznek. A PDF parser elemzi a PDF dokumentum tartalmát, és azonosítja az olyan elemeket, mint a szöveg, képek, betűtípusok, elrendezések és akár a metaadatok is. A kinyert adatokat ezután különböző formátumokba, például XML, JSON vagy Excel/CSV exportálhatók, amelyeket különböző célokra használhatunk, például adat-elemzésre, nyilvántartás vezetésére vagy munkafolyamatok automatizálására.
A parsing jelentésének megértése elengedhetetlen a parsing megoldás hatékonyságának értékeléséhez, különösen különböző PDF-ből Markdown-ba történő konverziós eszközök összehasonlításakor, mivel a PDF parser nem csupán egyszerű szövegkinyerést jelent—fel kell ismernie és meg kell őriznie a dokumentum szemantikai struktúráját.
Hogyan mérjük a parsing megoldások minőségét?
Sorozatnyi szó szintű metrikát határoztunk meg a különböző modellek teljesítményének értékelésére, a következő kulcsfontosságú tényezőkre összpontosítva:
-
Pontosság, Recall és F-Mérték: A parsing minőségének és teljességének értékelése.
-
BLEU Pontszám és ANLS: Hasznos a nyelvi és elrendezési struktúra értékelésére.
-
Edit Distance, Jensen-Shannon Divergence és Jaccard Distance: Az OCR területre vonatkozó metrikák, különösen hasznosak a tartalom reprodukciójának pontosságának megértésében.
Vision-language modelünk, az AnyParser, kivételes teljesítményt mutat, ötvözve a sebességet és a pontosságot, különösen a bonyolult elrendezéseknél, amelyek táblázatokat és szemantikai elemeket tartalmaznak. Az AnyParser felülmúlja a többi megoldást, 20x sebességnövekedést kínálva a GPT/Claude modellekhez képest, miközben magasabb pontosságot ér el.
Kiterjedt összehasonlító eredmények a vezető parsing modellek ellen
Statisztikai objektum
Az AnyParser képességeinek valódi bemutatásához kiterjedt összehasonlítást végeztünk az iparág vezető parsing modelljeivel és a jól ismert Nagy Nyelvi Modellekkel (LLM). Értékelésünk a következőket tartalmazta:
1. Nagy Nyelvi Modellek
- AnyParser
- OpenAI GPT-4o
- Google Gemini 1.5 Pro
- Anthropic Claude 3.5 Sonnet
2. OCR-alapú Szolgáltatások
- LlamaParse
- Amazon Textract
- Google Cloud Document AI
- Azure Document Intelligence
Eredmények bemutatása és elemzése
Kísérlet 1
Először egy sor szigorú összehasonlítást végeztünk a különböző dokumentum AI modellek teljesítményéről az alábbi 5 metrikán: BLEU, Pontosság és recall, F-Mérték és ANLS. A metrikák matematikai definícióját az függelékben találhatja.
A modellek, amelyeket összehasonlítottunk: AnyParser-base, AnyParser-pro, Textract, Llama-Parse, GPT4o, Gemini-1.5-pro, GCP-DocAl és Azure-DocAl.
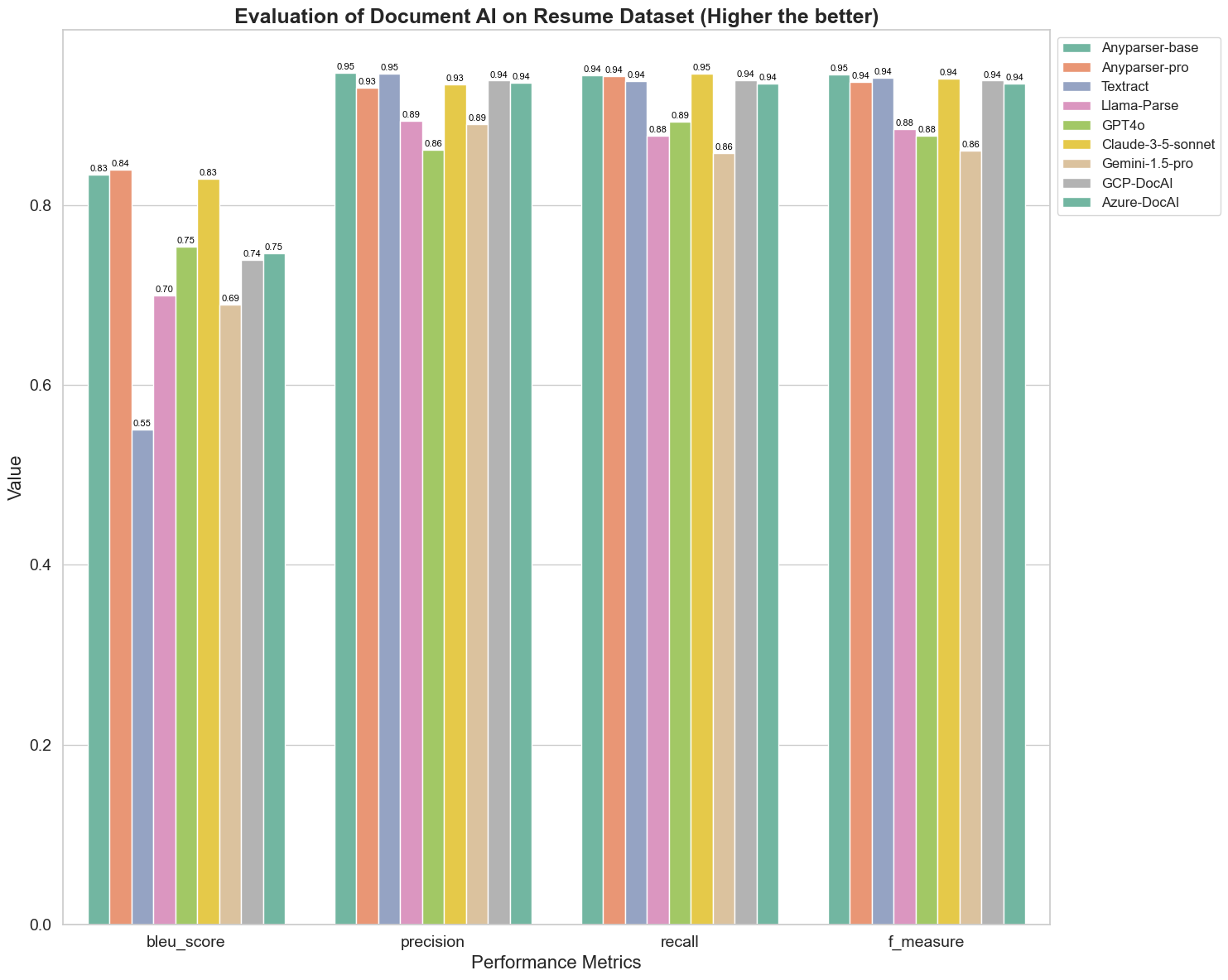
A BLEU-t a kétnyelvű értelmezés minőségének értékelésére használják, hogy teszteljék a modellek teljesítményét a kifejezések feldolgozásában. A parsing modellek BLEU értékelési módszer szerinti eredményeinek összehasonlításával megállapítottuk, hogy: az AnyParser-base és AnyParser-pro pontszámai jelentősen magasabbak a többi modell pontszámánál, az Amazon Textract a legalacsonyabb pontszámot érte el, míg a többi modell pontszámai viszonylag átlagos szinten helyezkednek el.
A felismerési pontosságot általában a pontosság és a recall képviseli, ahol a pontosság azt a százalékot jelenti, amely valóban helyes eredmények között szerepel, míg a recall azt a százalékot mutatja, amely valóban helyesen azonosított eredmények közül a modell által az összes ténylegesen helyes eredményből származik. A parsing modellek pontosságának és recall-jának összehasonlításával megállapítottuk, hogy: a Llama-Parse, GPT4o és Gemini-1.5-pro kivételével minden más modell magas szinten teljesít. Közülük az AnyParser és az Amazon Textract kiemelkedőbb a pontosságban, míg az AnyParser-base és AnyParser-pro a recall-ban. A modell magasabb pontszáma a Pontosságban azt jelzi, hogy a modell több helyes információt ad ki a produkált eredményekben, míg a recall magasabb pontszáma azt jelzi, hogy a modell képes több helyes információt kinyerni a mintából. A pontszámok eredményei azt mutatják, hogy az AnyParser egyértelmű előnnyel bír a PDF-ből történő szövegkinyerés pontosságában.
Az F-Mérték a pontosság és a recall átfogó értékelési indexe e két mutató alapján. Az F-Mérték szerinti parsing modellek pontszámainak összehasonlításával intuitívan láthatjuk, hogy az öt modell, AnyParser-base, AnyParser-pro, Amazon Textract, GCP-DocAI és Azure-DocAI, jobb erősséggel bír a felismerési pontosság terén a többi modellhez képest. Intuitívan látható, hogy az öt modell erősebb a felismerési pontosságban, mint a többi modell, és az AnyParser a legmagasabb pontszámot éri el az F-Mérték alatt, ami tovább hangsúlyozza az AnyParser nyilvánvaló előnyét a PDF-ből történő szövegkinyerés pontosságában.
Az ANLS, mint a karakter szintű eredeti szöveg és a cél szöveg közötti pontosság és hasonlóság mérésére általánosan használt értékelési index, szintén nagyon informatív a modellek parsing szintjének mérésére. Az AnyParser-base, AnyParser-pro és Azure-DocAI magasabb pontszámai a modellek ezen szintjeinek magasabb parsing szintjét tükrözik a többi modellhez képest.
Összességében az AnyParser-base és AnyParser-pro felülmúlja a többi modellt.
Kísérlet 2
A különböző dokumentum AI modellek teljesítményét három különböző metrikán is összehasonlítjuk: Edit Distance, Jensen-Shannon Divergence és Jaccard Distance. Ezek a metrikák a modellek kimenete és egy referencia dokumentum közötti hasonlóságot mérik. Az alacsonyabb értékek jobb teljesítményt jeleznek.
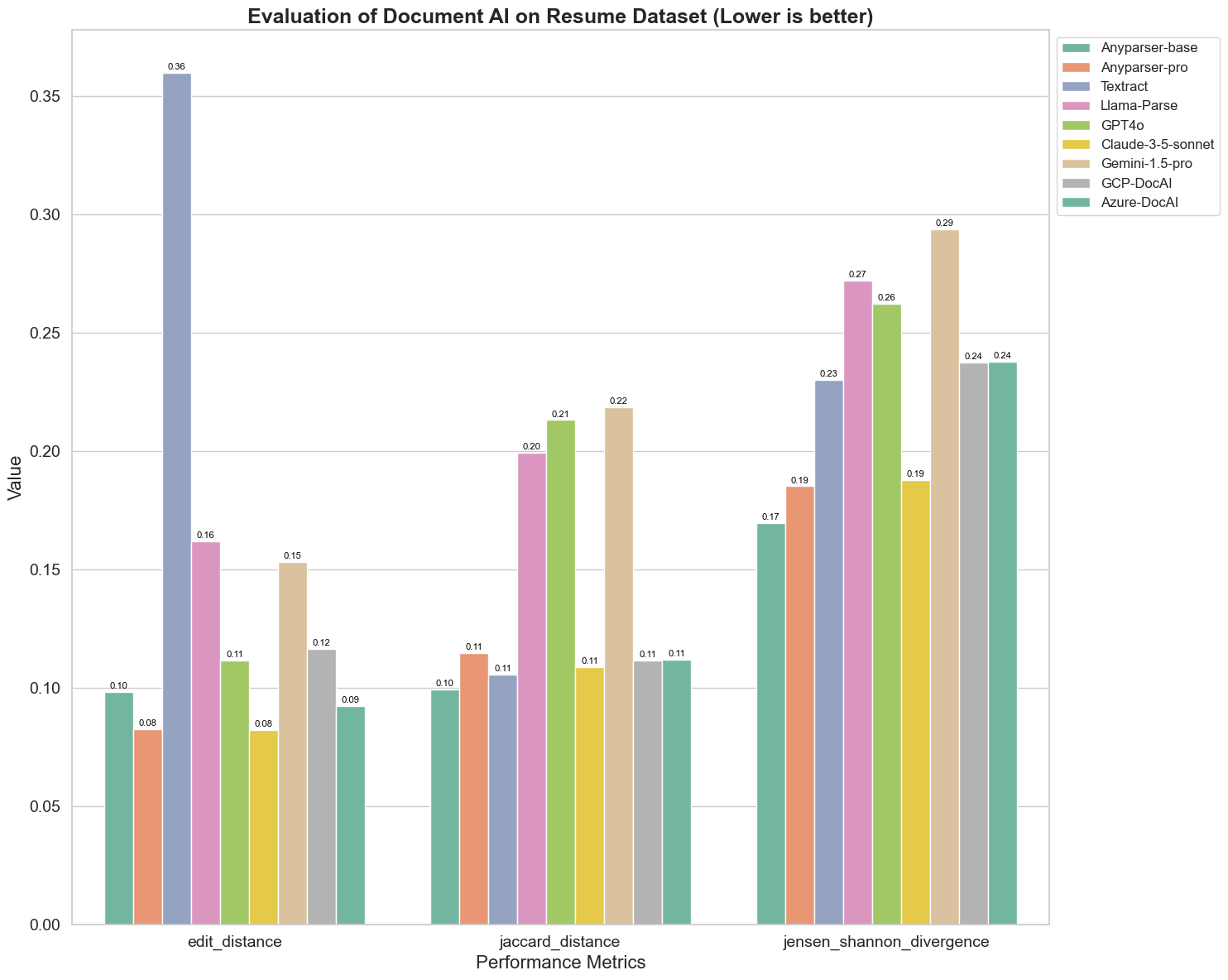
Íme néhány kulcsfontosságú megfigyelés a diagramról:
-
Edit Distance: Az AnyParser-base és AnyParser-pro modellek a legjobban teljesítenek a legalacsonyabb edit distance-szel, ami azt jelzi, hogy kimenetük a legközelebb áll a referencia dokumentumhoz.
-
Jensen-Shannon Divergence: Az AnyParser-base és AnyParser-pro modellek a legalacsonyabb divergenciát mutatják, ami azt jelenti, hogy kimeneteik a legjobban hasonlítanak a referencia dokumentumhoz a szószerkezet szempontjából.
-
Jaccard Distance: A Llama-parse, GPT4O, Gemini-1.5 kivételével az összes többi modell megfelelően teljesít a legalacsonyabb Jaccard distance-szel, ami azt jelzi, hogy kimeneteik a legnagyobb átfedést mutatják a referencia dokumentummal a használt szavak halmaza szempontjából.
Következtetés
Összességében a szigorú tesztelésünk azt sugallja, hogy az AnyParser-base és AnyParser-pro általában jól teljesít a különböző metrikákon, ami jelzi a pontos dokumentumfeldolgozásra való potenciálját. A grafikonokból látható, hogy a hagyományos OCR modellek, mint a híres Amazon Textract, sokkal alacsonyabb pontszámot érnek el, mint a vision language modellek. Azonban a különböző modellek teljesítménye a használt metrikától függően változik, ami hangsúlyozza a több értékelési kritérium figyelembevételének fontosságát az AI modellek összehasonlításakor.
Nyílt Forráskódú Értékelési Pipeline Bemutatása
Az értékelések egyszerűsítése érdekében létrehoztunk egy értékelési pipeline-t, amely ipari szabványos módszert kínál a parsing modellek összehasonlítására. Példánkban bemutatjuk annak használatát az HR területén, ahol a önéletrajz parsing gyakori. Készítettünk egy sokszínű szintetikus adatbázist 128 önéletrajzról, amelyeket párosított kép-Markdown fájlok felhasználásával generáltunk. A GPT-4 segítségével HTML tartalmat generáltunk, amelyet képekké alakítottunk, és a kinyert szöveget használtuk alapként az összehasonlításhoz.
És itt a legjobb rész: ezt az értékelési keretrendszert nyílt forráskódúvá tettük a GitHub-on! Akár fejlesztő, akár üzleti felhasználó vagy, pipeline-unk lehetővé teszi, hogy saját adatbázisán értékelje és összehasonlítsa a különböző modellek parsing minőségét.
Találja meg a gyorsindító útmutatót a Github repo oldalon, és nézze meg, hogyan állnak össze a különböző parsing modellek egymással. Hisszük, hogy azáltal, hogy bemutatjuk modellünk erejét nyilvánosan, több felhasználót vonzhatunk, akik megbízható, gyors és pontos parsing képességeket keresnek.
Függelék - Metrikák
1. Pontosság
A pontosság méri a kinyert tartalom pontosságát, megmutatva, hogy a visszanyert elemek közül hány volt helyes. A parsing során ez a helyesen kinyert szavak arányát jelenti az összes kinyert szóhoz képest.
Pontosság = Igaz Pozitívok (TP) / (Igaz Pozitívok (TP) + Hamis Pozitívok (FP))
- Igaz Pozitívok (TP): A parser által helyesen azonosított szavak.
- Hamis Pozitívok (FP): A parser által helytelenül azonosított szavak.
2. Recall
A recall a parsing teljességét jelzi, vagyis azt, hogy az eredeti dokumentumból hány releváns szót nyertek ki.
Recall = Igaz Pozitívok (TP) / (Igaz Pozitívok (TP) + Hamis Negatívok (FN))
- Hamis Negatívok (FN): Az eredeti dokumentumban a parser által kihagyott szavak.
3. F-Mérték (F1 Pontszám)
Az F1 pontszám a pontosság és a recall harmonikus átlaga, amely egyensúlyt teremt a két metrika között, hogy átfogó mérést adjon a parsing minőségéről.
F1 Pontszám = 2 × (Pontosság × Recall) / (Pontosság + Recall)
4. BLEU Pontszám (Kétnyelvű Értékelési Módszer)
A BLEU pontszám méri a kinyert tartalom és az eredeti szöveg közötti hasonlóságot, különös hangsúlyt fektetve a szavak sorrendjére. Különösen hasznos a nyelvi és struktúra konzisztencia értékelésére a kinyert dokumentumokban, mivel bünteti azokat a kimeneteket, amelyek eltérnek az eredeti sorrendtől.
5. ANLS (Átlagos Normalizált Levenshtein Hasonlóság)
Az ANLS a kinyert tartalom és az eredeti közötti hasonlóságot kvantálja, normalizált edit distance használatával. Az ANLS-t a kinyert és referencia szövegek közötti szó pár átlagolt Normalizált Levenshtein Hasonlóság (NLS) átlagolásával számítják ki. Az NLS a következőképpen számítható:
NLS = 1 - (Levenshtein Distance (LD)(kinyert szó, eredeti szó)) / max(kinyert szó hossza, eredeti szó hossza)
Ezután az ANLS a NLS átlagát jelenti az összes szó párra:
ANLS = (1/N) × Σ(NLS_i) ahol i=1-től N-ig
6. Edit Distance
Az Edit Distance kiszámítja a kinyert szöveg és az eredeti közötti konvertáláshoz szükséges szó szintű műveletek (beszúrások, törlések, helyettesítések) számát.
7. Jensen-Shannon Divergence
A Jensen-Shannon Divergence méri a kinyert és az eredeti szó számok diszkrét valószínűségi eloszlásainak hasonlóságát, kiemelve a szavak gyakoriságában lévő eltéréseket.
JSD(P || Q) = (1/2) × KL(P || M) + (1/2) × KL(Q || M)
ahol M = (1/2)(P + Q), és KL(P || Q) a Kullback-Leibler divergencia
8. Jaccard Distance
A Jaccard Distance méri a kinyert és az eredeti tartalom szavainak halmazai közötti eltérést, hasznos a szavak átfedésének értékelésére.
Jaccard Distance = 1 - |A ∩ B| / |A ∪ B|
ahol |A ∩ B| a közös elemek száma A és B között,
és |A ∪ B| a két halmaz összes egyedi elemének száma.