A látásnyelv modellek (VLM-ek) forradalmasítják a dokumentumelemzés területét, kezelve a hagyományos optikai karakterfelismerés (OCR) rendszerekben rejlő sok korlátot. Míg az OCR alapvető technológia a képekből származó szöveg digitalizálásához, jelentős kihívásokkal néz szembe bonyolult helyzetekben. Ezek közé tartoznak a pontossági problémák alacsony minőségű képek esetén, a korlátozott kontextuális megértés, a vegyes nyelvekkel kapcsolatos nehézségek és a vizuális elemek értelmezésének képtelensége. A VLM-ek ígéretes megoldást kínálnak azzal, hogy ötvözik a fejlett szoftveres látást a természetes nyelvfeldolgozási képességekkel. Ez a cikk azt vizsgálja, hogyan küzdenek a VLM-ek az OCR hiányosságaival, és hogyan kínálnak robusztusabb és sokoldalúbb megoldásokat a dokumentumfeldolgozás számára a digitális korban.
Mi az OCR? Milyen folyamatok zajlanak az OCR során a dokumentumok elemzésében?
Az optikai karakterfelismerés (OCR) egy olyan technológia, amely lehetővé teszi különböző típusú dokumentumok, például beolvasott papírdokumentumok, PDF fájlok vagy digitális fényképezőgéppel készült képek átkonvertálását szerkeszthető és kereshető adatokra. Ez a folyamat kulcsfontosságú a dokumentumfeldolgozás és a PDF adatkinyerés terén, lehetővé téve a gépek számára, hogy felismerjék a nyomtatott vagy kézzel írt szöveges karaktereket a digitális képekben.
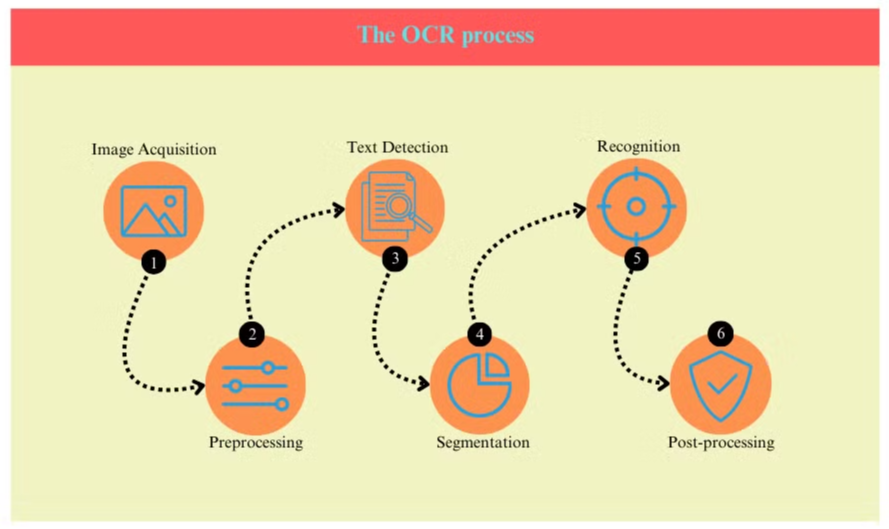
Az OCR Folyamata
Az OCR folyamata általában több lépésből áll:
- Képbeszerzés: A dokumentumot beolvassák vagy lefotózzák, hogy digitális képet készítsenek.
- Előfeldolgozás: A képet megtisztítják, eltávolítva a zajt, és beállítva a fényerőt és a kontrasztot.
- Szövegérzékelés: A rendszer azonosítja a képen található szöveget tartalmazó területeket.
- Karakterszegmentálás: Az egyes karaktereket elkülönítik a szövegterületeken belül.
- Karakterfelismerés: Minden karaktert elemeznek és összehasonlítanak egy ismert karakterek adatbázisával.
- Utófeldolgozás: A felismert szöveget hibák szempontjából ellenőrzik nyelvi és kontextuális információk felhasználásával.
Bár az OCR jelentősen javította a dokumentumok elemzésének képességeit, még mindig korlátokkal néz szembe a bonyolult elrendezések, az alacsony minőségű képek és a változatos betűtípusok kezelésében. Itt lépnek be a fejlett technológiák, mint például a látásnyelv modellek, hogy javítsák a pontosságot és a megértést az adatok képekből és dokumentumokból történő kinyerésében.
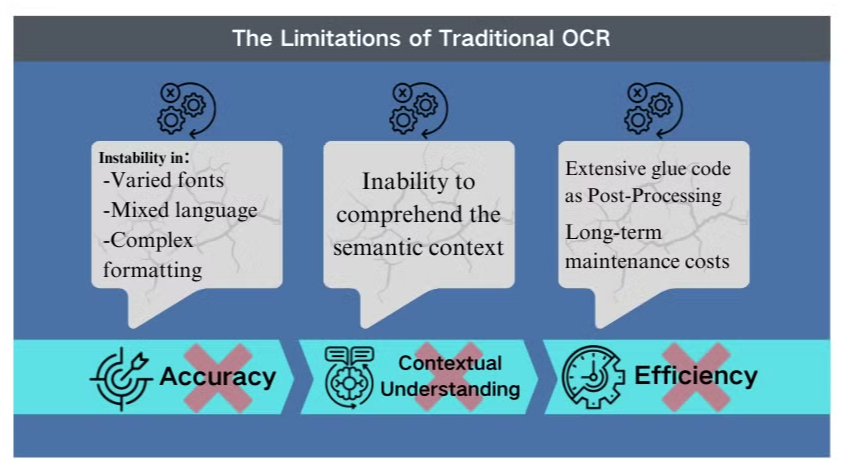
A Hagyományos OCR Technológia Korlátai
Pontossági Kihívások Bonyolult Helyzetekben
A hagyományos optikai karakterfelismerés (OCR) technológia, bár hasznos az alapvető szövegkinyeréshez, jelentős akadályokkal néz szembe, amikor bonyolult dokumentumelrendezésekkel vagy alacsony minőségű képekkel találkozik. Ezek a rendszerek gyakran küzdenek a pontosság fenntartásával, amikor változatos betűtípusú, vegyes nyelvű vagy bonyolult formázású dokumentumokat dolgoznak fel. Például az OCR nehezen tud adatokat kinyerni képekkel teli prezentációkból vagy sűrűn formázott PDF-ekből.
Kontextuális Megértés Hiánya
A hagyományos OCR egyik legszembetűnőbb korlátja a szövegének feldolgozása során a szemantikai kontextus megértésének képtelensége. Ez a hiányosság különösen nyilvánvalóvá válik olyan helyzetekben, amelyek finom értelmezést igényelnek, például jogi szerződések vagy orvosi jelentések esetén. Az OCR a karakterfelismerésre összpontosít kontextuális tudás nélkül, ami kritikus félreértésekhez vezethet, különösen, ha kétértelmű karakterekkel vagy iparág-specifikus terminológiával találkozik.
Hatékonysági Hiányosságok Utófeldolgozásban
Az OCR korlátai gyakran kiterjedt utófeldolgozási erőfeszítéseket igényelnek. Ez a további lépés jelentősen megnövelheti a dokumentumfeldolgozáshoz szükséges időt és erőforrásokat. Ezenkívül a hagyományos OCR rendszerek általában nem teljesítenek jól, amikor információt kell kinyerni táblázatokból, diagramokból vagy egyéb nem szöveges elemekből, tovább bonyolítva a dokumentumkinyerési folyamatot. Ezek a hatékonysági hiányosságok hangsúlyozzák a fejlettebb megoldások, például a látásnyelv modellek iránti igényt, amelyek átfogóbb megközelítést kínálnak a dokumentumelemzéshez és az adatkinyeréshez.
Mi a Látásnyelv Modellek és hogyan javítják az OCR-t
A látásnyelv modellek jelentős előrelépést jelentenek a dokumentumfeldolgozó technológiában, kezelve a hagyományos optikai karakterfelismerés (OCR) rendszerekben rejlő sok korlátot. Ezek a fejlett modellek ötvözik a szoftveres látást a természetes nyelvfeldolgozással, hogy egyidejűleg megértsék a dokumentumok vizuális és szöveges elemeit.
Fokozott Pontosság és Kontextuális Megértés
Ellentétben az OCR-rel, amely küzd az alacsony minőségű képekkel és bonyolult elrendezésekkel, a látásnyelv modellek kiemelkednek a különböző dokumentumformátumok értelmezésében. Pontosan képesek adatokat kinyerni képekből, PDF-ekből és egyéb vizuális tartalmakból, még a kihívásokkal teli helyzetekben is. Ez a javított pontosság abból ered, hogy képesek figyelembe venni a dokumentum teljes kontextusát, nem csupán az egyes karakterekre vagy szavakra összpontosítanak.
Átfogó Adatkinyerés
A látásnyelv modellek túlmutatnak az egyszerű szövegfelismerésen, átfogó PDF adatkinyerési képességeket kínálva. Képesek azonosítani és értelmezni a táblázatokat, diagramokat és ábrákat a dokumentumokban, megőrizve a bonyolult elrendezések integritását. Ez a holisztikus megközelítés a dokumentumelemzéshez lehetővé teszi a finomabb és teljesebb információk visszanyerését, jelentősen növelve az kinyert adatok hasznosságát a további alkalmazások számára.
Többnyelvű és Többformátumú Jártasság
A látásnyelv modellek egyik kulcsfontosságú előnye a rugalmasságuk a több nyelv és dokumentumformátum kezelésében. Ellentétben az OCR rendszerekkel, amelyek nehezen boldogulnak a nem latin írásokkal vagy vegyes nyelvű dokumentumokkal, ezek a modellek zökkenőmentesen képesek feldolgozni a tartalmat különböző nyelveken és írásmódokban, így felbecsülhetetlen értékűek a globális dokumentumfeldolgozási igényekhez.
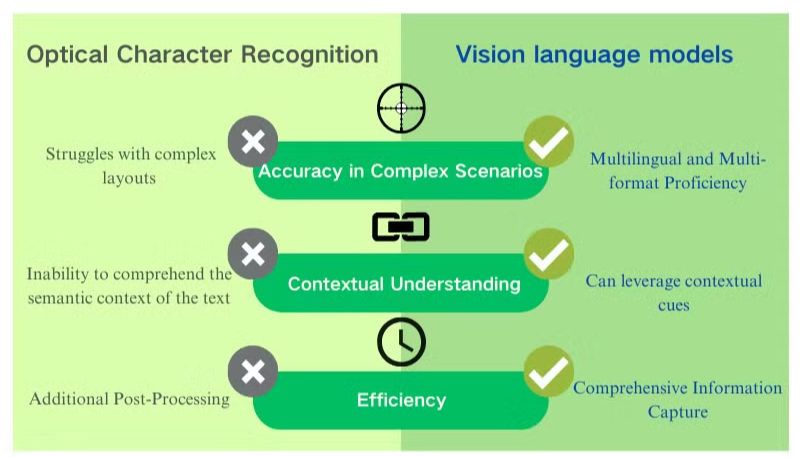
A Látásnyelv Modellek Kulcsfontosságú Előnyei a Dokumentumok Megértésében
A látásnyelv modellek jelentős előnyöket kínálnak a hagyományos OCR-hez képest a dokumentumfeldolgozás és az adatkinyerés terén. Ezek az AI-alapú rendszerek ötvözik a vizuális és szöveges megértést, hogy kiváló eredményeket nyújtsanak különböző dokumentumtípusok esetén.
Fokozott Pontosság és Kontextuális Megértés
A látásnyelv modellek kiemelkednek a bonyolult elrendezések, alacsony minőségű képek és változatos betűtípusok kezelésében. Ellentétben az OCR-rel, amely küzd a kétértelmű karakterekkel, ezek a modellek a kontextuális nyomokat kihasználva pontosan értelmezik a szöveget. Ez a képesség drámaian javítja a PDF adatkinyerés pontosságát, különösen a bonyolult szerkezetű vagy gyenge minőségű képekkel rendelkező dokumentumok esetén.
Átfogó Információgyűjtés
Míg az OCR kizárólag a szövegfelismerésre összpontosít, a látásnyelv modellek képesek adatokat kinyerni képekből, táblázatokból és diagramokból. Ez a holisztikus megközelítés biztosítja, hogy a kritikus információk ne vesszenek el a dokumentumfeldolgozási fázis során. A szöveges és vizuális elemek együttes rögzítésével ezek a modellek teljesebb megértést nyújtanak a dokumentum tartalmáról.
Többnyelvű és Többformátumú Jártasság
A látásnyelv modellek figyelemre méltó rugalmasságot mutatnak a különböző nyelveken és formátumokban történő dokumentumfeldolgozás során. Zökkenőmentesen kezelhetik a vegyes nyelvű dokumentumokat és a nem latin írásokat, leküzdve a hagyományos OCR rendszerek jelentős korlátait. Ez a sokoldalúság felbecsülhetetlen értékűvé teszi őket a globális vállalatok számára, amelyek különböző dokumentumtípusokkal és nyelvekkel foglalkoznak.
Valós Világi Alkalmazások, Amelyeket a VLM Támogat, Amelyekben az OCR Megbukott
A látásnyelv modellek forradalmasítják a dokumentumfeldolgozást a pénzügy, az emberi erőforrások és más szektorok terén, kezelve a hagyományos OCR rendszerek kritikus korlátait. Ezek a fejlett AI modellek átalakítják a digitális átalakulási erőfeszítéseket az iparágakban, mivel kiváló pontosságot és kontextuális megértést kínálnak.
A Pénzügyi Dokumentumfeldolgozás Forradalmasítása
A látásnyelv modellek átalakítják a dokumentumfeldolgozást a pénzügyekben, leküzdve a hagyományos OCR korlátait. Ezek a fejlett modellek kiemelkednek az összetett pénzügyi kimutatások, számlák és nyugták adatainak kinyerésében, amelyeket bonyolult elrendezések jellemeznek. Ellentétben az OCR-rel, képesek megérteni a kontextust, pontosan értelmezve a kétértelmű karaktereket (pl. megkülönböztetni a nullát az O betűtől) és a vegyes nyelveket, amelyek gyakran jelen vannak a globális pénzügyi dokumentumokban.
Az HR Műveletek Fejlesztése Intelligens Dokumentumelemzéssel
Az emberi erőforrások területén a látásnyelv modellek felbecsülhetetlen értékűek a PDF adatkinyerésben önéletrajzokból, munkavállalói nyilvántartásokból és teljesítményértékelésekből. Ezek a modellek képesek megérteni a dokumentumok szemantikai szerkezetét, lehetővé téve a pontosabb információk visszanyerését és elemzését. Ez a képesség jelentősen egyszerűsíti a toborzási folyamatokat és a munkavállalói adatok kezelését, olyan feladatokat, ahol az OCR gyakran küzd a változatos formátumokkal és kézírásos jegyzetekkel.
A Megfelelés és Kockázatkezelés Fejlesztése
A látásnyelv modellek különösen hatékonyak a megfelelés és kockázatkezelés terén a pénzügyek és az emberi erőforrások területén egyaránt. Képesek kinyerni és értelmezni a kritikus információkat a szabályozási dokumentumokból, szerződésekből és politikákból, nagyobb pontossággal, mint az OCR. Ez a fejlettebb dokumentumfeldolgozási képesség biztosítja a jogi követelmények jobb betartását és a hatékonyabb kockázatértékelési eljárásokat.
Következtetés
Összefoglalva, a látásnyelv modellek jelentős előrelépést jelentenek a dokumentumfeldolgozó technológiában, kezelve a hagyományos OCR rendszerekben rejlő sok korlátot. A vizuális és szöveges megértés ötvözésével ezek a fejlett modellek kiváló teljesítményt nyújtanak a kihívásokkal teli helyzetek széles spektrumában, a bonyolult elrendezésektől kezdve a vegyes nyelvekig és az alacsony minőségű képekig. Ahogy a szervezetek folytatják műveleteik digitalizálását és hatékonyabb módokat keresnek az érték kinyerésére dokumentumgyűjteményeikből, a látásnyelv modellek erőteljes eszközként emelkednek ki a fejlesztők és mérnöki vezetők számára egyaránt. Képességük, hogy megértsék a kontextust, kezeljék a különböző formátumokat, és pontosabb eredményeket nyújtsanak, kulcsszereplővé teszi őket a kifinomult RAG csővezetékek és a vállalati keresési képességek szempontjából, végső soron új magasságokba emelve a digitális átalakulási kezdeményezéseket.