Nel campo della gestione dei dati, il parsing implica convertire il contenuto—come testo, immagini, tabelle e metadati—in un formato utilizzabile (ad esempio, testo semplice, dati strutturati o immagini) che può essere ulteriormente elaborato o analizzato. Questo è particolarmente evidente nel dominio del parsing PDF, un processo cruciale che trasforma informazioni grezze in dati strutturati e utilizzabili. Questa guida completa esplora le complessità del parsing PDF, chiarendo la sua definizione, lo spettro di dati che può estrarre, le sfide che affronta, le sue molteplici applicazioni e la varietà di metodi disponibili per sfruttarne appieno il potenziale. Esplorerai vari metodi di parsing, con un focus particolare sul parsing PDF e su come strumenti come AnyParser si distinguano dalla massa.
Comprendere il Parser PDF: Cos'è il Parsing?
Cos'è il parsing: processo meticoloso di acquisizione dei dati
Alla base, il parsing PDF si riferisce al processo di estrazione e interpretazione dei dati dai file PDF (Portable Document Format). Poiché i PDF sono progettati principalmente per la visualizzazione piuttosto che per l'archiviazione di dati strutturati, il parsing implica la conversione del contenuto—come testo, immagini, tabelle e metadati—in un formato utilizzabile (ad esempio, testo semplice, dati strutturati o immagini) che può essere ulteriormente elaborato o analizzato. Il parsing comporta un'analisi di alto livello per individuare e recuperare elementi specifici all'interno di un PDF, estendendosi oltre il semplice testo e immagini per includere font, layout, tabelle e metadati. Questo processo non è solo una questione tecnica, ma una necessità in settori così diversi come finanza, diritto, logistica e sanità, dove il riutilizzo delle informazioni è fondamentale.
Dati che possono essere Estratti dai PDF
I dati estraibili dai PDF sono vari e ampi, includendo:
-
Paragrafi di Testo: Sequenze di parole e caratteri.
-
Campi Dati Singoli: Elementi individuali come date, numeri di tracciamento e nomi.
-
Dati Tabulari: Informazioni organizzate in tabelle e liste.
-
Immagini: Contenuti grafici incorporati nel PDF.
-
Elementi Avanzati: Intestazioni, oggetti, tabelle di riferimento incrociato, trailer e metadati, che richiedono strumenti di parsing più sofisticati.
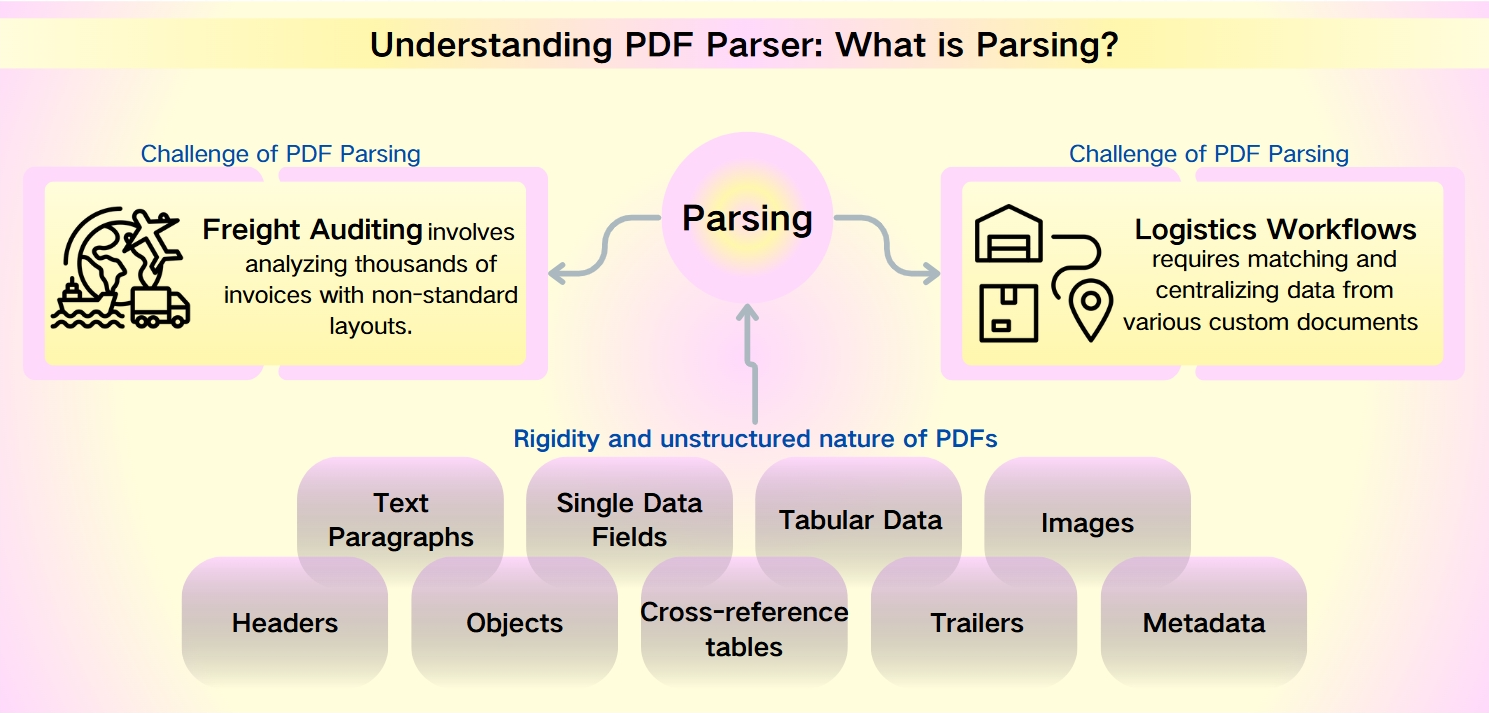
Sfide del Parsing PDF: natura non strutturata dei metadati PDF
Nonostante la robustezza dei PDF—caratterizzati dalla loro sicurezza, compatibilità con i dispositivi e dimensioni dei file compatte—l'estrazione di dati da essi rappresenta una sfida formidabile. La rigidità e la natura non strutturata dei PDF ostacolano un'analisi rapida e il recupero delle informazioni. Questo è particolarmente pronunciato in scenari come l'audit delle spedizioni e i flussi di lavoro logistici, dove layout non standard e set di dati voluminosi complicano la complessità.
L'Audit delle Spedizioni comporta l'analisi di migliaia di fatture con layout non standard. I Flussi di Lavoro Logistici richiedono di abbinare e centralizzare i dati provenienti da vari documenti personalizzati come liste di imballaggio, fatture commerciali e bolle di carico.
L'Importanza del Parsing
Il parsing gioca un ruolo vitale in vari campi, dallo sviluppo web all'acquisizione dei dati. Permette alle aziende di estrarre preziose intuizioni da fonti di dati non strutturati, come documenti PDF, file HTML e dati XML. Il parsing facilita:
-
Miglioramento del processo decisionale attraverso intuizioni basate sui dati.
-
Maggiore accuratezza e coerenza dei dati.
-
Elaborazione e analisi dei dati semplificate.
-
Recupero e archiviazione delle informazioni efficienti.
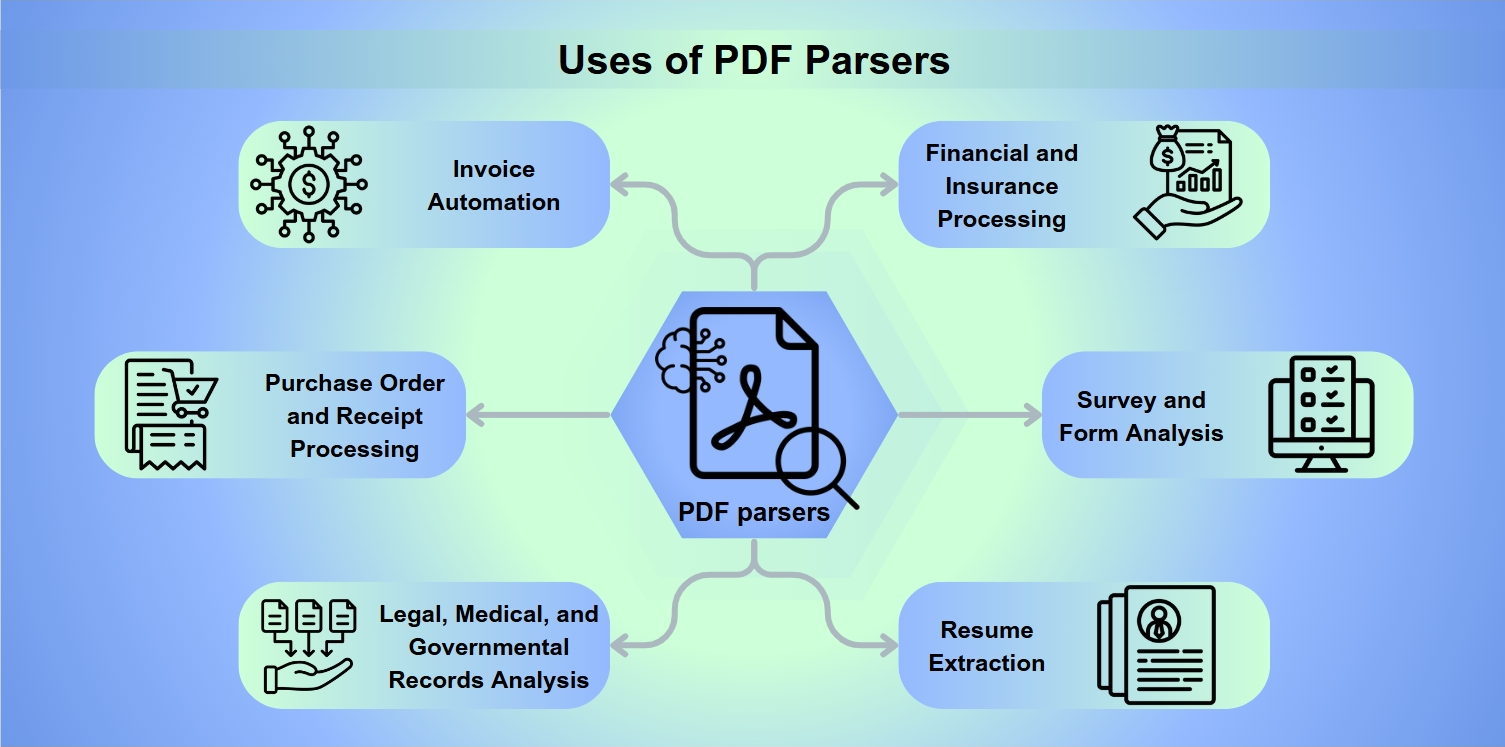
Utilizzi dei Parser PDF
I parser PDF sono strumenti indispensabili in una gamma di applicazioni, tra cui:
-
Automazione delle Fatture: Semplificazione del processo di elaborazione e pagamento delle fatture.
-
Elaborazione di Ordini di Acquisto e Ricevute: Facilitazione di rimborsi e indennizzi.
-
Analisi di Documenti Legali, Medici e Governativi: Abilitazione di estrazioni di dati approfondite per analisi.
-
Elaborazione Finanziaria e Assicurativa: Valutazione dei rischi e analisi dei bilanci.
-
Analisi di Sondaggi e Moduli: Raccolta e interpretazione delle risposte ai moduli.
-
Estrazione di Curriculum: Assistenza ai reclutatori nella selezione dei candidati.
Confronto dei Diversi Metodi di Parsing
I metodi di parsing dei dati si sono evoluti significativamente nel tempo. Gli approcci tradizionali di acquisizione dei dati spesso si basano su espressioni regolari (regex) per estrarre schemi specifici dal testo. Sebbene potenti, le regex possono diventare complesse e difficili da mantenere per compiti di parsing intricati. Un'altra tecnica comune è la manipolazione delle stringhe, che implica la suddivisione e l'elaborazione del testo in base a delimitatori o caratteri specifici. Questi metodi, sebbene ancora utili in alcuni scenari, possono avere difficoltà con formati di dati non strutturati o incoerenti.
Il panorama del parsing PDF è servito da una varietà di metodi, ognuno con i propri meriti e svantaggi:
-
Convertitori/Parser PDF Online: Come Zamzar e Smallpdf, offrono convenienza e velocità ma sono limitati nelle funzionalità e potenzialmente insicuri.
-
Adobe Acrobat: Preserva la struttura e il formato ma può richiedere aggiustamenti manuali dopo la conversione.
-
Copia e Incolla: Fornisce il controllo completo, ma è laborioso e soggetto a errori.
-
Piattaforme Automatizzate: Tecnologie moderne di parsing come AnyParser sfruttano l'apprendimento automatico e l'elaborazione del linguaggio naturale (NLP) per gestire strutture di dati più complesse.
Questi approcci guidati dall'IA possono comprendere contesto e semantica, rendendoli particolarmente efficaci per il parsing di testo non strutturato o documenti con formati variabili. Alcuni parser avanzati utilizzano modelli di deep learning per identificare ed estrarre informazioni rilevanti con alta precisione, anche da layout di documenti precedentemente sconosciuti.
Come Eseguire il Parsing PDF: Il Miglior Parser PDF Gratuito per Estrarre Metadati PDF
Comprendere i Metadati PDF
I metadati PDF contengono informazioni cruciali su un documento, inclusi titolo, autore, data di creazione e parole chiave. Estrarre questi metadati in modo efficiente è essenziale per organizzare, cercare e gestire grandi collezioni di file PDF. Un robusto parser PDF può semplificare questo processo, risparmiando tempo e migliorando la produttività del flusso di lavoro.
Caratteristiche Chiave dei Migliori Parser PDF
I migliori parser PDF gratuiti offrono una combinazione di accuratezza, velocità e versatilità. Dovrebbero essere in grado di gestire vari formati PDF, inclusi documenti scansionati e quelli con layout complessi. Cerca parser che possano estrarre non solo metadati di base, ma anche campi personalizzati e informazioni nascoste. Inoltre, i parser di alto livello spesso forniscono opzioni per l'estrazione di dati PDF per l'elaborazione in batch e l'integrazione con altri sistemi software.
Caratteristiche di AnyParser
AnyParser, sviluppato da CambioML, è particolarmente degno di nota per la sua accuratezza, privacy e configurabilità. La capacità di AnyParser di gestire più formati di file, la sua interfaccia user-friendly e la sua scalabilità lo rendono un'ottima scelta per aziende di tutte le dimensioni. Inoltre, la sua API consente un'integrazione senza soluzione di continuità nei flussi di lavoro esistenti, migliorando l'efficienza complessiva nella gestione dei documenti. Ecco alcune delle caratteristiche chiave che rendono AnyParser un'ottima scelta per il parsing PDF:
-
Precisione: AnyParser è progettato per estrarre con precisione testo, numeri e simboli mantenendo il layout e il formato originali. Utilizza modelli linguistici avanzati per migliorare la comprensione dei documenti e l'estrazione delle informazioni, vantando un tasso di accuratezza fino a 2 volte superiore rispetto ai modelli OCR tradizionali.
-
Privacy: Supporta sia il parsing dei dati on-premise che in cloud, garantendo che le informazioni sensibili rimangano private e sicure.
-
Configurabilità: Gli utenti possono personalizzare le regole di estrazione e i formati di output per soddisfare esigenze specifiche.
-
Supporto Multi-sorgente: AnyParser supporta una varietà di tipi di documenti, inclusi PDF, immagini e grafici.
-
Output Strutturato: Le informazioni estratte possono essere convertite in formati strutturati come Markdown, Excel o JSON, facilitando ulteriori elaborazioni e analisi.
-
Opzioni di Distribuzione Basate sul Cloud: AnyParser SDK può essere distribuito nel cloud, in data center o privatamente, offrendo flessibilità e scalabilità.
-
Interfaccia User-Friendly: Lo strumento offre un'API semplice che consente di completare compiti complessi di parsing dei documenti con poche righe di codice.
-
Alte Prestazioni: Algoritmi ottimizzati garantiscono un'elaborazione rapida di un gran numero di documenti, 5 volte più veloce rispetto a LLM generalizzati come GPT4o.
-
Supporto della Comunità: Essendo un progetto open-source, AnyParser beneficia di una comunità attiva e accoglie contributi.
-
Quota di Utilizzo Gratuita: AnyParser offre una quota di utilizzo gratuita con ogni account, consentendo agli utenti di testare le capacità dello strumento prima di impegnarsi in un piano a pagamento.
-
Feedback dei Clienti: Gli utenti hanno lodato AnyParser per la sua alta accuratezza, preservazione della privacy e efficienza nell'estrazione dei dati, con casi studio che mostrano significativi risparmi di tempo e miglioramenti nella qualità dei dati.
Questi vantaggi rendono AnyParser un prezioso estrattore di dati PDF per il parsing dei documenti e l'estrazione delle informazioni, specialmente per gli utenti aziendali che richiedono alta precisione e sicurezza. Con i continui progressi tecnologici e il coinvolgimento attivo della comunità, AnyParser è destinato a svolgere un ruolo sempre più vitale nel campo del parsing dei documenti e dell'estrazione delle informazioni.
Spiegazione Tecnica dei Parser PDF
Il parsing PDF condivide un terreno concettuale con lo scraping web, ma manca della gerarchia strutturata dell'HTML. Mentre i documenti web vengono analizzati attraverso tag HTML accessibili, i PDF presentano un array piatto di caratteri e pixel, richiedendo algoritmi e librerie più sofisticati per l'estrazione dei dati.
Parser PDF vs Parser PDF Python: Differenze Chiave
Un parser PDF è spesso uno strumento autonomo come estrattore di dati PDF o libreria progettata specificamente per estrarre dati dai file PDF. Questi parser offrono tipicamente interfacce user-friendly e richiedono una conoscenza minima di programmazione. D'altra parte, i parser PDF Python sono moduli o librerie che si integrano negli script Python, offrendo maggiore flessibilità ma richiedendo competenze di programmazione.
Gli sviluppatori possono affinare il processo di parsing, implementare analisi testuali avanzate e integrare senza soluzione di continuità l'estrazione dei dati PDF in applicazioni Python più ampie. I parser PDF, sebbene più limitati nella personalizzazione rispetto ai parser PDF Python, offrono spesso funzionalità pre-costruite per casi d'uso comuni, rendendoli ideali per gli utenti che necessitano di risultati rapidi senza una programmazione estesa.
Vantaggi di AnyParser con VLM per il Parsing dei Dati
-
Alta Precisione: I VLM di AnyParser garantiscono che l'estrazione dei dati mantenga alta fedeltà, anche con layout di documenti complessi.
-
Velocità: È leader nella velocità di conversione, migliorando la produttività riducendo il tempo necessario per elaborare i documenti.
-
User-Friendly: AnyParser offre un'interfaccia semplice, rendendolo accessibile per utenti di tutti i livelli.
-
Versatilità: Oltre ai PDF, AnyParser funge da potente convertitore da immagine a Excel, supportando diversi tipi di documenti.
Conclusione
Il parsing PDF è più di un semplice processo tecnico; è una porta d'accesso per trasformare il modo in cui le aziende gestiscono i dati. Nonostante le sfide, l'evoluzione delle soluzioni software lo ha reso più accessibile che mai. Che tu stia affrontando l'elaborazione delle fatture o analisi di dati complesse, scegliere il giusto parser PDF è essenziale. Si tratta di trovare lo strumento che offre il perfetto equilibrio di accuratezza, sicurezza ed efficienza per potenziare le tue iniziative basate sui dati.
Inizia la Tua Prova Gratuita Oggi
Pronto a rivoluzionare il tuo processo di gestione dei documenti? Prova AnyParser GRATUITAMENTE senza necessità di carta di credito su https://www.cambioml.com/sandbox. La prova gratuita ti consente di elaborare fino a 10 pagine per documento, con una dimensione massima del file di 10MB. Scopri in prima persona come il parser PDF di AnyParser può trasformare il tuo approccio ai dati non strutturati e all'estrazione dei documenti. Non perdere questa opportunità di migliorare le tue capacità di analisi dei dati e semplificare il tuo flusso di lavoro con tecnologia AI all'avanguardia.