Convertire PDF complessi in Markdown può essere una sfida. Ci sono molte librerie open-source disponibili per estrarre testo da PDF, ma quando si tratta di PDF contenenti elementi complessi come tabelle e grafici, i risultati spesso non sono all'altezza. Modelli di linguaggio di grandi dimensioni come GPT o Claude possono gestire questi compiti, ma tendono a essere lenti e a volte producono output imprecisi. Gli strumenti OCR tradizionali, sebbene efficaci per documenti più semplici, spesso faticano a mantenere la struttura esatta e il significato semantico del contenuto originale. D'altra parte, i modelli di linguaggio visivo a volte "hallucinate", portando a risultati di parsing errati. Questo blog spiegherà cosa significa "parse" e dettagliarà i risultati di un'analisi comparativa di più modelli utilizzando diverse metriche.
Cosa significa "parse"?
Nel contesto del parsing PDF, "parse" si riferisce al processo di estrazione di dati specifici da un file PDF utilizzando software specializzati noti come parser PDF. Un parser PDF analizza il contenuto di un documento PDF e identifica elementi come testo, immagini, font, layout e persino metadati. I dati estratti possono quindi essere organizzati ed esportati in diversi formati come XML, JSON o Excel/CSV, che possono essere utilizzati per vari scopi come analisi dei dati, archiviazione o automazione dei flussi di lavoro.
Comprendere cosa significa "parse" è essenziale per valutare l'efficacia di una soluzione di parsing, soprattutto quando si confrontano diversi strumenti di conversione da PDF a Markdown, poiché il parser PDF implica più di una semplice estrazione di testo: richiede di riconoscere e mantenere la struttura semantica del documento.
Come misuriamo la qualità di queste soluzioni di parsing?
Abbiamo definito una serie di metriche a livello di parola per valutare le prestazioni di diversi modelli, concentrandoci su fattori chiave come:
-
Precisione, Recall e F-Measure: Valutazione della qualità e completezza del parsing.
-
Score BLEU e ANLS: Utili per valutare la struttura linguistica e di layout.
-
Distanza di Edit, Divergenza di Jensen-Shannon e Distanza di Jaccard: Metriche specifiche per il dominio OCR, particolarmente utili per comprendere l'esattezza della riproduzione del contenuto.
Il nostro modello di linguaggio visivo, AnyParser, dimostra prestazioni eccezionali, combinando velocità e accuratezza, soprattutto su layout complessi con tabelle ed elementi semantici. AnyParser supera altre soluzioni, offrendo un miglioramento della velocità di 20 volte rispetto a modelli come GPT/Claude, pur raggiungendo una maggiore accuratezza.
Un confronto esteso contro i principali modelli di parsing
Oggetto statistico
Per mostrare veramente le capacità di AnyParser, abbiamo condotto un confronto approfondito contro i principali modelli di parsing del settore e noti Modelli di Linguaggio di Grandi Dimensioni (LLM). La nostra valutazione ha incluso:
1. Modelli di Linguaggio di Grandi Dimensioni
- AnyParser
- GPT-4o di OpenAI
- Gemini 1.5 Pro di Google
- Claude 3.5 Sonnet di Anthropic
2. Servizi basati su OCR
- LlamaParse
- Amazon Textract
- Google Cloud Document AI
- Azure Document Intelligence
Presentazione e analisi dei risultati
Esperimento 1
Per prima cosa, conduciamo una serie di rigorosi confronti delle prestazioni di diversi modelli di AI documentale su oltre 5 metriche di seguito: BLEU, Precisione e recall, F-Measure e ANLS. Puoi trovare la definizione matematica di queste metriche nell'appendice.
I modelli confrontati sono: AnyParser-base, AnyParser-pro, Textract, Llama-Parse, GPT4o, Gemini-1.5-pro, GCP-DocAl e Azure-DocAl.
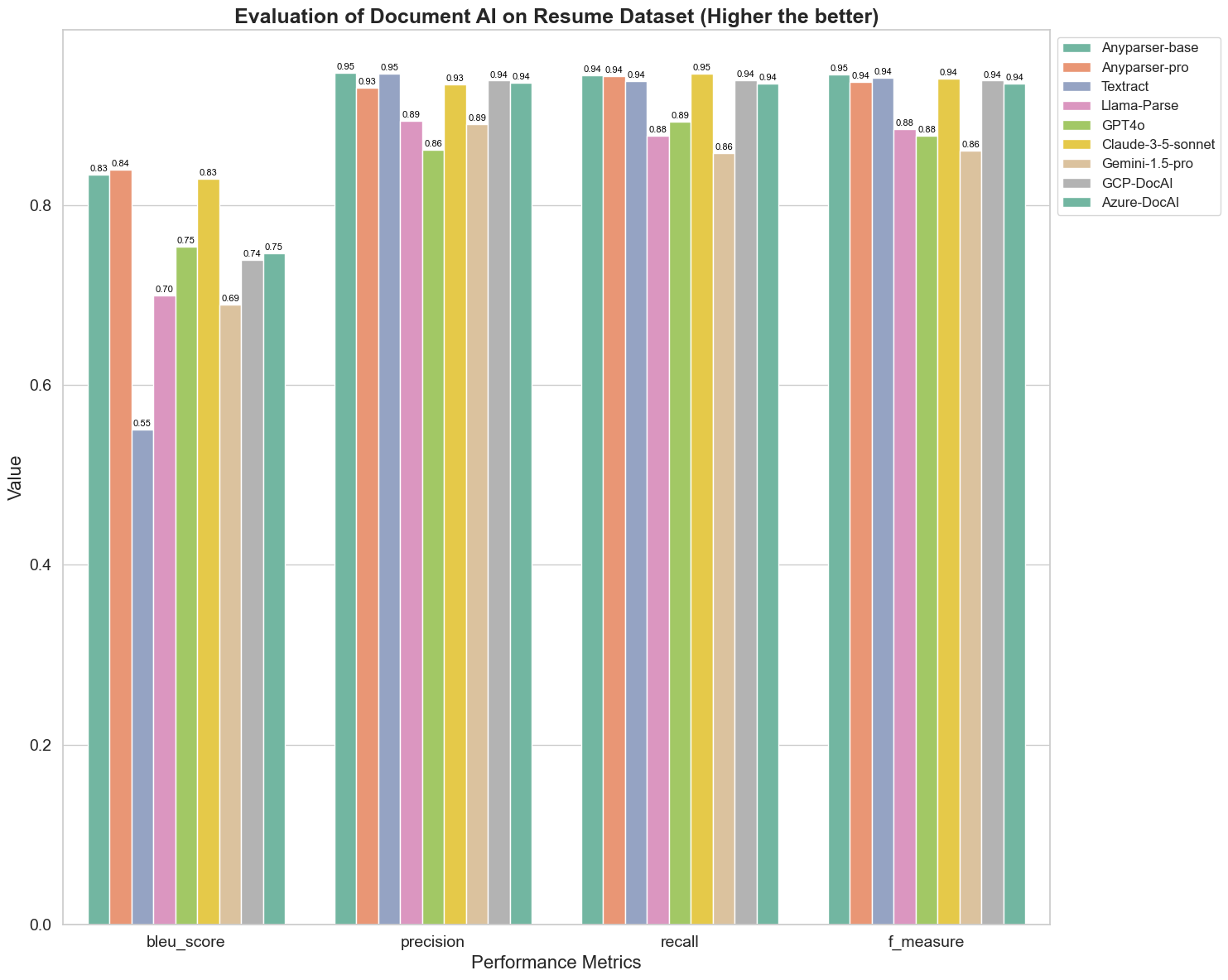
Il BLEU è utilizzato come valutazione della qualità dell'interpretazione bilingue per testare la qualità dei modelli nel processamento delle espressioni. Confrontando i risultati di questi modelli di parsing sotto il metodo di valutazione BLEU, scopriamo che: i punteggi di AnyParser-base e AnyParser-pro sono significativamente più alti rispetto ai punteggi degli altri modelli, Amazon Textract ottiene il punteggio più basso, e i risultati degli altri modelli si collocano a un livello medio relativamente.
L'accuratezza del riconoscimento è solitamente rappresentata da precisione e recall, dove la precisione rappresenta la percentuale di risultati realmente corretti tra i risultati giudicati corretti dal modello, e il recall rappresenta la percentuale di risultati realmente corretti giudicati dal modello tra tutti i risultati realmente corretti. Confrontando la precisione e il recall di questi modelli di parsing, scopriamo che: eccetto Llama-Parse, GPT4o e Gemini-1.5-pro, tutti gli altri modelli sono a un livello elevato. Tra questi, AnyParser e Amazon Textract si distinguono maggiormente in precisione, e AnyParser-base e AnyParser-pro si distinguono maggiormente in recall. Un punteggio più alto del modello sulla Precisione indica che il modello produce più informazioni corrette nei risultati di produzione, e un punteggio più alto sul recall indica che il modello è più capace di ottenere informazioni corrette dal campione. I risultati dei punteggi mostrano che AnyParser ha un chiaro vantaggio in termini di accuratezza di riconoscimento nell'estrazione di testo da PDF.
L'F-Measure è un indice di valutazione complessivo di precisione e recall su questi due indicatori. Confrontando i punteggi di questi modelli di parsing sotto l'F-Measure, possiamo vedere in modo più intuitivo che i cinque modelli, AnyParser-base, AnyParser-pro, Amazon Textract, GCP-DocAI e Azure-DocAI, hanno una migliore forza in termini di accuratezza di riconoscimento rispetto agli altri modelli. Possiamo vedere in modo più intuitivo che i cinque modelli hanno più forza in accuratezza di riconoscimento rispetto agli altri modelli, e AnyParser ha il punteggio più alto sotto l'F-Measure, il che illustra ulteriormente il chiaro vantaggio di AnyParser in accuratezza di riconoscimento nell'estrazione di testo da PDF.
L'ANLS, come indice di valutazione comunemente utilizzato per misurare l'accuratezza e la similarità tra il testo originale e il testo target a livello di carattere, è anche molto informativo per misurare il livello di parsing dei modelli. I punteggi più alti di AnyParser-base, AnyParser-pro e Azure-DocAI riflettono il livello di parsing più elevato di questi modelli rispetto agli altri modelli.
In generale, AnyParser-base e AnyParser-pro superano gli altri modelli.
Esperimento 2
Confrontiamo anche le prestazioni di diversi modelli di AI documentale su tre metriche diverse: Distanza di Edit, Divergenza di Jensen-Shannon e Distanza di Jaccard. Le metriche sono utilizzate per misurare la similarità tra l'output dei modelli e un documento di riferimento. Valori più bassi indicano prestazioni migliori.
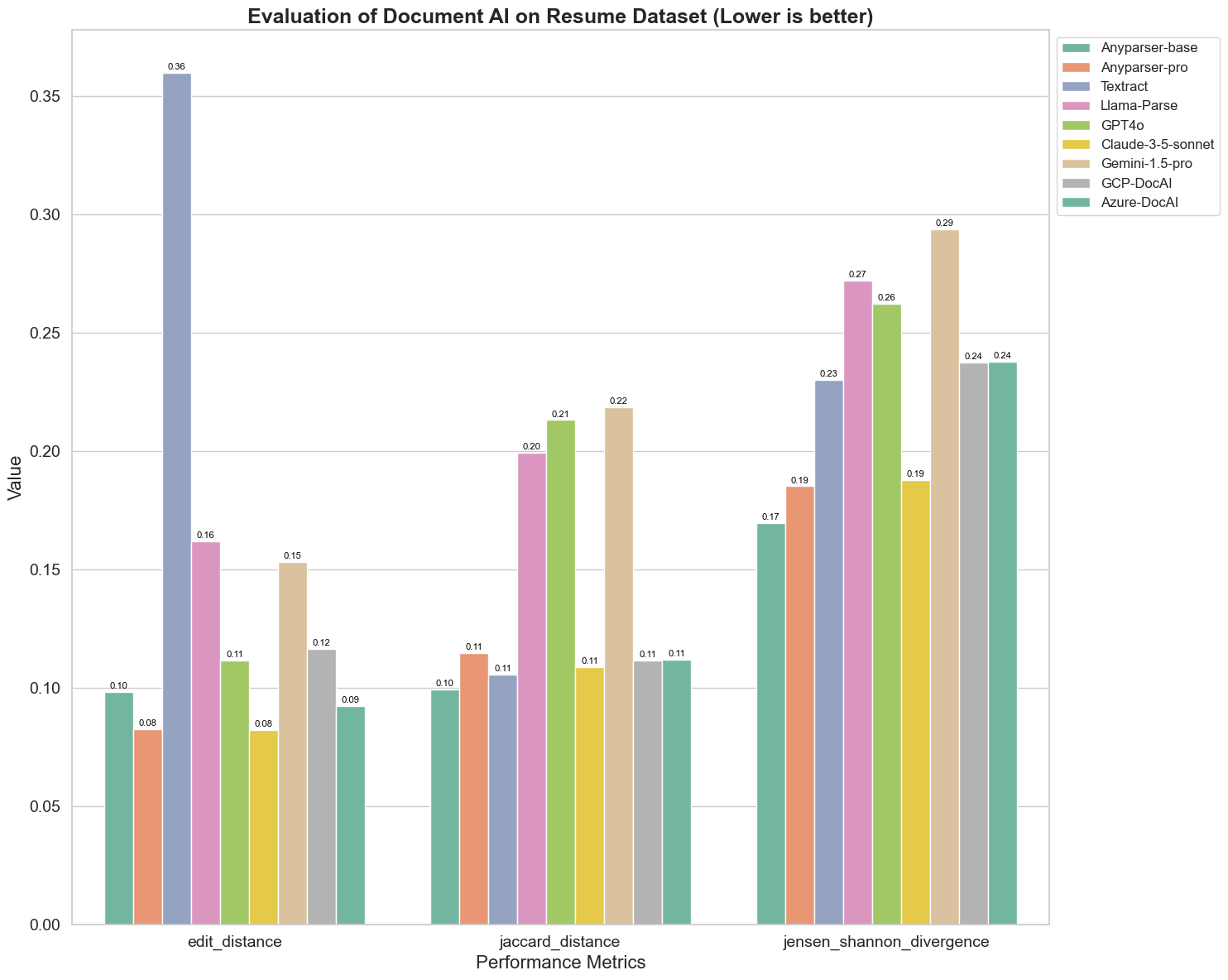
Ecco alcune osservazioni chiave dal grafico:
-
Distanza di Edit: I modelli AnyParser-base e AnyParser-pro si comportano meglio con la distanza di edit più bassa, suggerendo che il loro output è stato il più vicino al documento di riferimento.
-
Divergenza di Jensen-Shannon: I modelli AnyParser-base e AnyParser-pro hanno la divergenza più bassa, implicando che i loro output sono i più simili al documento di riferimento in termini di distribuzione delle parole.
-
Distanza di Jaccard: Oltre a Llama-parse, GPT4O, Gemini-1.5, tutti gli altri modelli si comportano decentemente con la distanza di Jaccard più bassa, indicando che il loro output ha la massima sovrapposizione con il documento di riferimento in termini di insieme di parole utilizzate.
Conclusione
In generale, i nostri rigorosi test suggeriscono che AnyParser-base e AnyParser-pro si comportano bene su varie metriche, indicando il loro potenziale per un'elaborazione documentale accurata. Dai grafici, possiamo vedere che i modelli OCR tradizionali come il famoso Amazon Textract ottengono punteggi molto più bassi rispetto ai modelli di linguaggio visivo. Tuttavia, le prestazioni dei diversi modelli variano a seconda della metrica utilizzata, evidenziando l'importanza di considerare più criteri di valutazione quando si confrontano i modelli di AI.
Introduzione al nostro pipeline di valutazione open-source
Per semplificare le valutazioni, abbiamo creato un pipeline di valutazione che fornisce un metodo standard del settore per confrontare i modelli di parsing. Nel nostro esempio, dimostriamo il suo utilizzo nel dominio HR, dove il parsing dei curriculum è comune. Abbiamo costruito un dataset sintetico diversificato di 128 curriculum, generato utilizzando file immagine-Markdown abbinati. Utilizzando GPT-4, abbiamo generato contenuti HTML, li abbiamo resi in immagini e abbiamo utilizzato il testo estratto come verità di base per il confronto.
Ecco la parte migliore: abbiamo open-sourced questo framework di valutazione su GitHub! Che tu sia uno sviluppatore o un utente aziendale, il nostro pipeline ti consente di valutare e confrontare la qualità del parsing di diversi modelli sul tuo dataset.
Trova la guida rapida nel repo di Github e scopri come i diversi modelli di parsing si confrontano tra loro. Crediamo che mostrando la forza del nostro modello in modo aperto, possiamo attrarre più utenti che desiderano capacità di parsing affidabili, veloci e accurate.
Appendice - Metriche
1. Precisione
La precisione misura l'accuratezza del contenuto analizzato, mostrando quanti degli elementi recuperati erano corretti. Nel parsing, è la proporzione di parole estratte correttamente su tutte le parole estratte.
Precisione = Veri Positivi (TP) / (Veri Positivi (TP) + Falsi Positivi (FP))
- Veri Positivi (TP): Parole correttamente identificate dal parser.
- Falsi Positivi (FP): Parole identificate erroneamente dal parser.
2. Recall
Il recall indica la completezza del parsing, o quante parole rilevanti dal documento originale sono state recuperate.
Recall = Veri Positivi (TP) / (Veri Positivi (TP) + Falsi Negativi (FN))
- Falsi Negativi (FN): Parole nel documento originale che sono state perse dal parser.
3. F-Measure (F1 Score)
L'F1 Score è la media armonica di Precisione e Recall, bilanciando entrambe le metriche per fornire una misura complessiva della qualità del parsing.
F1 Score = 2 × (Precisione × Recall) / (Precisione + Recall)
4. Score BLEU (Bilingual Evaluation Understudy)
Lo score BLEU misura la similarità tra il contenuto analizzato e il testo originale, ponendo particolare enfasi sull'ordine delle parole. È particolarmente utile per valutare la coerenza linguistica e di struttura nei documenti analizzati, poiché penalizza gli output che differiscono nella sequenza rispetto all'originale.
5. ANLS (Average Normalized Levenshtein Similarity)
L'ANLS quantifica la similarità tra il contenuto analizzato e l'originale, utilizzando la distanza di edit normalizzata. È calcolato mediando la Similarità di Levenshtein Normalizzata (NLS) per ogni coppia di parole nei testi analizzati e di riferimento. La NLS è calcolata come segue:
NLS = 1 - (Distanza di Levenshtein (LD)(parola analizzata, parola originale)) / max(Lunghezza della parola analizzata, Lunghezza della parola originale)
Poi, l'ANLS è la media di NLS su tutte le coppie di parole:
ANLS = (1/N) × Σ(NLS_i) per i=1 a N
6. Distanza di Edit
La Distanza di Edit calcola il numero di operazioni a livello di parola (inserimenti, cancellazioni, sostituzioni) necessarie per convertire il testo analizzato in quello originale.
7. Divergenza di Jensen-Shannon
La Divergenza di Jensen-Shannon misura la similarità tra distribuzioni di probabilità discrete dei conteggi di parole analizzate e originali, evidenziando le differenze nella frequenza delle parole.
JSD(P || Q) = (1/2) × KL(P || M) + (1/2) × KL(Q || M)
dove M = (1/2)(P + Q), e KL(P || Q) è la divergenza di Kullback-Leibler
8. Distanza di Jaccard
La Distanza di Jaccard misura la dissimilarità tra insiemi di parole nel contenuto analizzato e originale, utile per valutare la sovrapposizione delle parole.
Distanza di Jaccard = 1 - |A ∩ B| / |A ∪ B|
dove |A ∩ B| è il numero di elementi comuni tra A e B,
e |A ∪ B| è il numero totale di elementi unici in entrambi gli insiemi.