In numerosi settori, estrarre informazioni da dati complessi come l'estrazione di tabelle da PDF è cruciale per il processo decisionale. La trasformazione digitale ha evidenziato la necessità di estrarre in modo efficiente tabelle da PDF e copiare tabelle PDF in Excel. Tuttavia, sfide come il volume dei dati e la complessità dei formati ostacolano i metodi di estrazione tradizionali, che spesso portano a imprecisioni e richiedono interventi manuali per copiare tabelle da PDF in Excel. AnyParser di CambioML offre una soluzione moderna a queste sfide, semplificando il processo di estrazione dei dati dai PDF con precisione e velocità.
Sfide nel copiare tabelle da PDF in Excel
Gli strumenti tradizionali di estrazione PDF non riescono a soddisfare le diverse esigenze dei settori per estrarre dati da PDF. Sono inefficienti, soggetti a errori e faticano con layout complessi e documenti scansionati, ostacolando il loro utilizzo per l'estrazione di dati su larga scala.
Necessità di Estrarre Tabelle dai PDF
-
Ricerca Accademica: I ricercatori estraggono dati da PDF per analisi approfondite.
-
Analisi Dati: Le aziende copiano tabelle da PDF in Excel ed estraggono dati da rapporti per ulteriori elaborazioni.
-
Gestione delle Informazioni: Le organizzazioni convertono tabelle PDF per una gestione più semplice.
-
Settori Legali e Finanziari: Questi settori richiedono l'estrazione di dati critici da numerosi PDF.
Metodi Esistenti per Estrarre Tabelle dai PDF
-
Inserimento Manuale: Copiare tabelle da PDF in Excel è sempre dispendioso in termini di tempo e soggetto a errori.
-
Convertitori PDF: Intuitivi ma presentano problemi di compatibilità e personalizzazione.
-
Strumenti di Estrazione: Consentono estrazioni selettive ma sono limitati ai PDF nativi.
-
Estrazione Basata su OCR: Manca di precisione con documenti complessi e formati misti.
Principali Sfide dell'Estrazione di Tabelle PDF
-
Imprecisione: Gli strumenti che aiutano a copiare tabelle PDF in Excel faticano con layout complessi e celle unite.
-
Gestione di Documenti Complessi: Difficoltà nell'estrarre tabelle da documenti intricati. Quando è necessario copiare tabelle da PDF in Excel, ci vuole tempo per gestire documenti complessi.
-
Modifiche Manuali: Necessità frequente di controlli e correzioni manuali.
-
Diversità nei Formati: I vari formati dei PDF richiedono laboriose regolazioni di formattazione. Estrarre dati da PDF non può essere fatto in un colpo solo.
-
Limitazioni degli Strumenti: Scarsa efficacia con documenti scansionati o immagini di bassa qualità.
Copia Tabelle PDF in Excel Facilmente e Velocemente: Prova AnyParser
AnyParser offre un nuovo approccio all'analisi dei documenti, sfruttando i più recenti progressi nei Modelli Vision-Language (VLM) per fornire soluzioni di recupero documentale precise, private e configurabili. AnyParser è una buona scelta per estrarre tabelle da PDF e copiare tabelle PDF in Excel.
Guida Passo-Passo per Estrarre Tabelle da PDF Utilizzando AnyParser
AnyParser, dotato di avanzati Modelli di Linguaggio Visivo, è uno strumento robusto per estrarre tabelle dai PDF con precisione. Segui questi semplici passaggi per convertire le tue tabelle PDF in formati utilizzabili come CSV o Excel:
-
Carica il Tuo Documento: Inizia caricando il tuo documento PDF o Word. Puoi facilmente trascinare e rilasciare il tuo file nell'interfaccia web di AnyParser o incollare uno screenshot del PDF per un'elaborazione rapida.
-
Scegli Estrazione Tabella: Per concentrarti sull'estrazione delle tabelle, seleziona l'opzione "Solo Tabella" e fai clic su "Estrai". Il motore API di AnyParser rileverà e estrarrà con precisione le tabelle dal tuo documento PDF.
-
Anteprima e Verifica: È importante rivedere i dati estratti. Usa la funzione di anteprima di AnyParser per confrontare l'estrazione iniziale con il documento originale affiancato nell'interfaccia utente.
-
Scarica il Tuo CSV: Dopo l'estrazione, i dati vengono salvati in un file .csv. Puoi scaricare questo file con un solo clic o esportarlo direttamente su Google Sheets per ulteriori manipolazioni.
-
Esporta per Ulteriori Utilizzi: Quando sei sicuro che l'estrazione sia accurata, procedi all'esportazione dei tuoi dati. Il file .csv può essere importato in fogli di calcolo come Excel o database per analisi approfondite.
Seguendo questa guida passo-passo, puoi sfruttare le capacità di AnyParser e dei Modelli di Linguaggio Visivo per trasformare tabelle PDF complesse in file strutturati e modificabili, integrandoli senza problemi nel tuo flusso di lavoro per un'analisi e gestione dei dati migliorate.
Aumentare l'Efficienza con AnyParser per l'Estrazione di Tabelle PDF
AnyParser semplifica l'estrazione di tabelle PDF, offrendo vantaggi chiave che migliorano la produttività e la gestione dei dati nei vari settori:
-
Efficienza e Precisione: Automatizzare i compiti di estrazione dei dati consente un focus più strategico e riduce al minimo gli errori, essenziale per decisioni informate.
-
Sicurezza dei Dati: L'elaborazione locale dei dati protegge le informazioni sensibili, rispettando gli standard di privacy dei dati del settore.
-
Personalizzazione Flessibile: Gli utenti possono personalizzare i parametri di estrazione e i formati di report per adattarsi a specifiche esigenze analitiche, garantendo un'integrazione fluida nel flusso di lavoro.
-
Maggiore Focus Analitico: Semplificando l'estrazione dei dati, i professionisti possono concentrarsi su analisi di maggior valore, migliorando sia la qualità che la velocità.
AnyParser semplifica le sfide dell'estrazione di tabelle PDF, dando potere agli utenti con soluzioni di gestione dei dati efficienti ed efficaci.
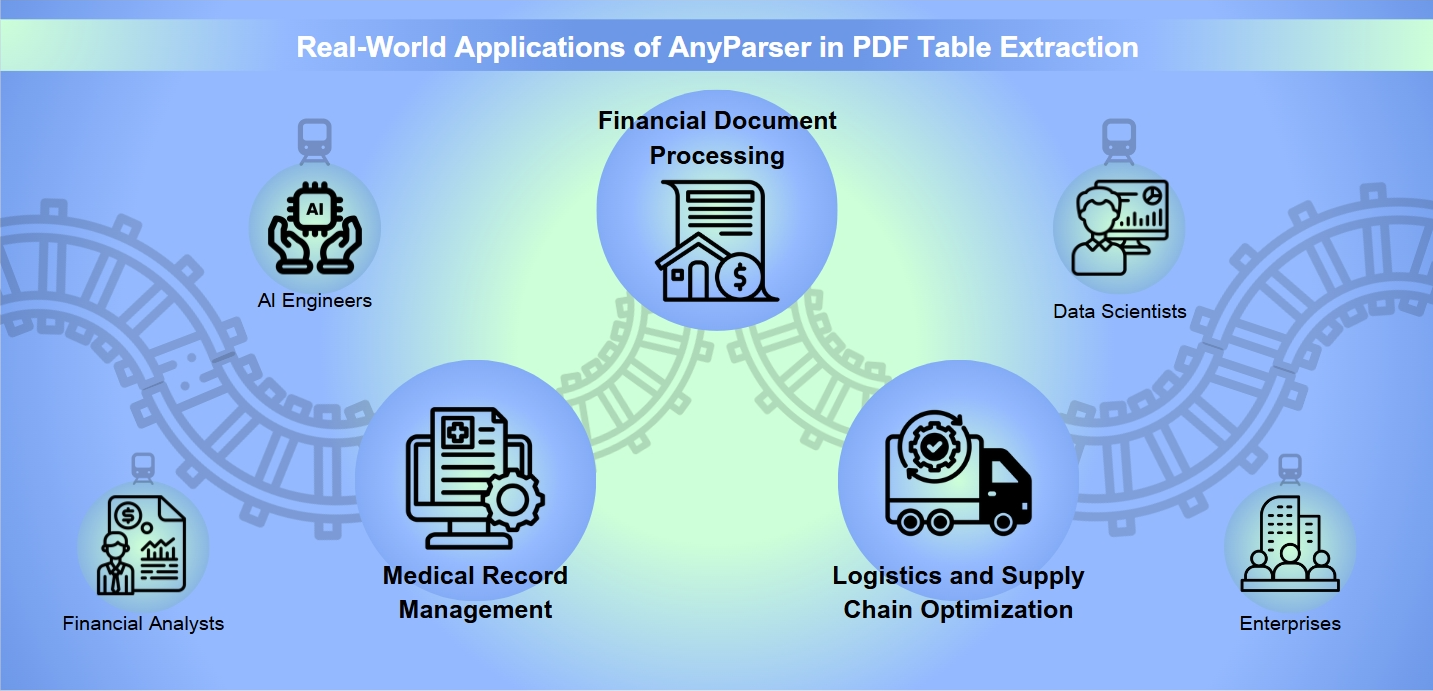
Applicazioni Reali di AnyParser nell'Estrazione di Tabelle PDF:
Vari scenari professionali:
-
Elaborazione di Documenti Finanziari: Nel settore finanziario, AnyParser eccelle nell'estrazione di dati numerici precisi da immagini o tabelle PDF, semplificando il flusso di lavoro per gli analisti finanziari che necessitano di informazioni accurate per decisioni di investimento e reporting finanziario.
-
Gestione dei Documenti Medici: Per i professionisti della salute, AnyParser fornisce una soluzione affidabile per gestire i documenti medici. Estrae con precisione informazioni testuali e di layout dai PDF, garantendo che i dati dei pazienti siano organizzati e facilmente accessibili per la revisione medica o scopi di ricerca.
-
Ottimizzazione della Logistica e della Catena di Fornitura: Nella logistica, AnyParser gioca un ruolo cruciale nell'ottimizzazione della gestione della catena di fornitura automatizzando l'elaborazione e l'analisi di documenti come manifesti di spedizione e rapporti di inventario, portando a un monitoraggio dell'inventario e pianificazione dei percorsi più efficienti.
Una scelta preferita per professionisti come:
-
Ingegneri AI: Che si affidano a AnyParser per estrarre con precisione informazioni testuali e di layout dai PDF, migliorando la loro capacità di sviluppare e addestrare modelli AI con dati di alta qualità.
-
Analisti Finanziari: Che dipendono dallo strumento per estrarre dati numerici precisi da tabelle PDF, garantendo che le loro analisi e previsioni finanziarie siano basate su informazioni accurate e aggiornate.
-
Data Scientist: Che lavorano con grandi volumi di documenti non strutturati e sfruttano AnyParser per estrarre informazioni chiave, consentendo loro di scoprire intuizioni e tendenze che guidano le decisioni aziendali.
-
Aziende: Che cercano di automatizzare l'elaborazione e l'analisi di vari documenti, come contratti e rapporti, per migliorare l'efficienza operativa e il processo decisionale basato sui dati.
Coprendo queste diverse esigenze, AnyParser emerge come uno strumento potente che migliora la produttività, garantisce l'accuratezza dei dati e facilita la trasformazione digitale nei vari settori.
Approfondimenti Tecnici su AnyParser: Elevare l'Estrazione di Tabelle PDF
AnyParser di CambioML sfrutta i Modelli Vision-Language (VLM) per un'estrazione avanzata di tabelle PDF:
Caratteristiche Tecniche
-
Precisione Basata su VLM: Garantisce la copia precisa di tabelle PDF in Excel.
-
Design Modulare: Facilita la personalizzazione per diversi scenari di estrazione dati PDF.
-
Elaborazione Locale: Protegge la privacy dei dati elaborando le informazioni localmente.
-
Alte Prestazioni: Gestisce rapidamente grandi volumi di documenti per un'estrazione efficiente delle tabelle.
-
Integrazione API: Offre un'interfaccia fluida per flussi di lavoro automatizzati di estrazione dati PDF.
Approfondimento Tecnico
AnyParser supera le limitazioni della tecnologia OCR tradizionale nel migliorare la precisione della conversione dei documenti grazie a:
-
Interpretazione di Strutture Documentali Complesse: I VLM possono estrarre con precisione i dati delle tabelle dai PDF, anche quando i documenti presentano layout intricati.
-
Comprensione Contestuale: Forniscono un'estrazione accurata dei dati comprendendo il contesto in cui testo e tabelle appaiono nei PDF.
-
Supporto Multilingue e Multi-Formato: I VLM consentono ad AnyParser di estrarre tabelle da PDF in più lingue e formati, rendendolo uno strumento versatile per l'uso globale.
-
Riduzione del Rumore: I VLM di AnyParser filtrano efficacemente il rumore, garantendo un'estrazione di alta qualità anche da scansioni di bassa qualità di documenti PDF.
Osservazioni:
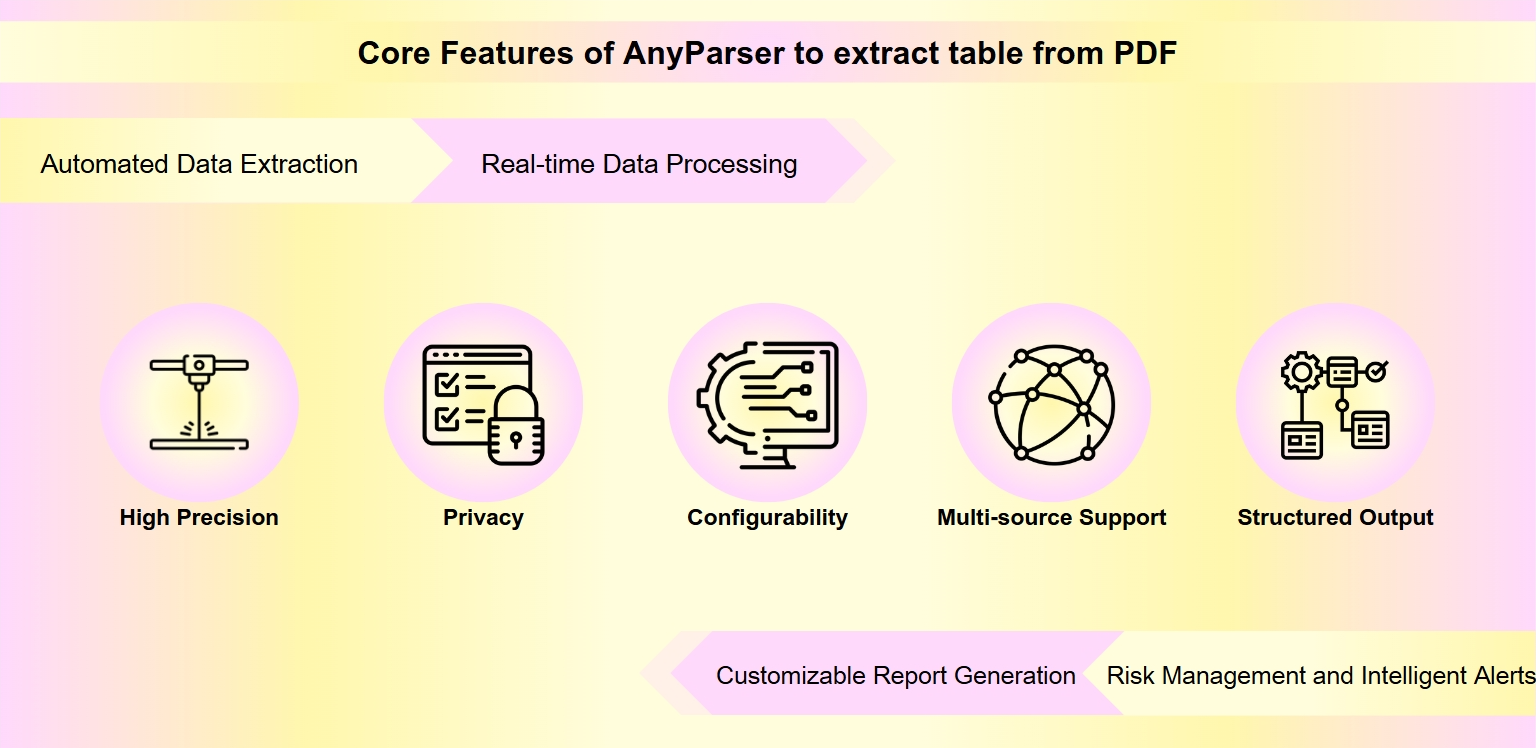
Caratteristiche Fondamentali di AnyParser per Estrarre Tabelle da PDF
-
Alta Precisione: AnyParser è progettato per copiare con precisione i dati delle tabelle dai PDF a Excel mantenendo il layout e il formato originali, garantendo precisione nell'estrazione dei dati.
-
Privacy: Elabora i dati localmente, proteggendo la privacy degli utenti e le informazioni sensibili, che è cruciale quando si estraggono dati dai PDF.
-
Configurabilità: Gli utenti possono definire regole di estrazione personalizzate e formati di output, fornendo flessibilità per estrarre tabelle dai PDF secondo requisiti specifici.
-
Supporto Multi-Sorgente: AnyParser è in grado di estrarre informazioni da varie fonti di dati non strutturati, inclusi PDF, immagini e grafici.
-
Output Strutturato: Lo strumento converte le informazioni estratte in formati strutturati come Excel, facilitando un'analisi e un'elaborazione più semplici.
Semplificare i Flussi di Lavoro dei Dati con AnyParser: Automazione, Integrazione e Analisi
- Estrazione Dati Automatica
- Elaborazione Dati in Tempo Reale
- Generazione di Report Personalizzabili
- Gestione del Rischio e Avvisi Intelligenti
Come AnyParser Trasforma l'Estrazione di Tabelle PDF:
- Flusso di Lavoro Semplificato da PDF a Excel
- Estrazione e Elaborazione Dati in Tempo Reale
- Generazione Automatica di Report per Intuizioni Personalizzate
- Gestione Proattiva del Rischio e Avvisi Intelligenti
FAQ sull'Estrazione di Tabelle da PDF Utilizzando Modelli di Linguaggio Visivo
Come si confronta l'estrazione basata su VLM con i metodi OCR tradizionali?
I Modelli di Linguaggio Visivo (VLM) offrono miglioramenti notevoli rispetto all'OCR tradizionale per l'estrazione di tabelle dai PDF. A differenza dell'OCR, i VLM decifrano con precisione layout intricati, comprendono le sfumature contestuali e gestiscono facilmente più lingue.
Quali tipi di documenti sono più adatti per l'estrazione VLM?
I VLM sono particolarmente abili nel gestire documenti strutturati che contengono tabelle, grafici ed elementi di contenuto misto. Gli strumenti basati su VLM possono preservare le strutture delle tabelle ed estrarre dati con precisione anche da scansioni di bassa qualità o documenti con contenuti complessi multilingue.
L'estrazione basata su VLM è più accurata dell'inserimento manuale dei dati?
Sì, le soluzioni basate su VLM come AnyParser superano significativamente l'inserimento manuale dei dati o l'OCR tradizionale in termini di accuratezza. Questi strumenti sfruttano sia l'intelligenza visiva che contestuale, riducendo potenzialmente gli errori di conversione fino al 50% nel passaggio da PDF a Excel o Google Sheets.
I VLM possono elaborare formati di file diversi dai PDF?
Assolutamente, gli strumenti avanzati basati su VLM non sono limitati ai PDF. Sono in grado di estrarre dati da una varietà di formati, inclusi immagini, documenti Word, presentazioni PowerPoint e documenti scansionati.
Conclusione
AnyParser fornisce una soluzione potente, flessibile e user-friendly per estrarre informazioni preziose da documenti complessi. Che tu sia un ingegnere AI, un data scientist o un utente aziendale, AnyParser può aiutarti a navigare in modo efficiente attraverso le sfide dei dati non strutturati. Mentre inizi a sfruttare i Modelli di Linguaggio Visivo per l'estrazione di tabelle PDF, ricorda che il successo risiede in un approccio ben strutturato. Implementando una robusta pre-elaborazione, una classificazione accurata dei documenti e un'accurata post-elaborazione, puoi sfruttare appieno il potenziale dei VLM per le tue esigenze di estrazione dei dati.
Chiamata all'Azione:
Procediamo implementando queste intuizioni. Considera di contattare esperti in Modelli di Linguaggio Visivo come il team di AnyParser per:
Prova AnyParser gratuitamente per estrarre tabelle da PDF su https://www.cambioml.com/sandbox
Ottieni una consulenza gratuita su come i VLM possono migliorare il tuo flusso di lavoro di estrazione dei dati.
Sfruttare appieno il potere dei Modelli di Linguaggio Visivo richiede di attingere all'esperienza e alle migliori pratiche degli specialisti della conversione. Fai il passo successivo collegandoti con i leader del settore per accelerare la tua transizione verso un processo di estrazione dei dati più automatizzato, accurato e perspicace.