I modelli di linguaggio visivo (VLM) stanno rivoluzionando il campo dell'analisi dei documenti, affrontando molte delle limitazioni intrinseche nei tradizionali sistemi di riconoscimento ottico dei caratteri (OCR). Sebbene l'OCR sia stata una tecnologia fondamentale per la digitalizzazione del testo dalle immagini, deve affrontare sfide significative in scenari complessi. Queste includono problemi di accuratezza con immagini di bassa qualità, comprensione contestuale limitata, difficoltà con lingue miste e incapacità di interpretare elementi visivi. I VLM offrono una soluzione promettente combinando visione artificiale avanzata con capacità di elaborazione del linguaggio naturale. Questo articolo esplora come i VLM stiano superando le carenze dell'OCR, fornendo soluzioni più robuste e versatili per l'elaborazione dei documenti nell'era digitale.
Cos'è l'OCR? Quali sono i processi dell'OCR nell'analisi dei documenti?
Il riconoscimento ottico dei caratteri (OCR) è una tecnologia che consente la conversione di diversi tipi di documenti, come documenti cartacei scansionati, file PDF o immagini catturate da una fotocamera digitale, in dati modificabili e ricercabili. Questo processo è cruciale nell'elaborazione dei documenti e nell'estrazione dei dati da PDF, consentendo alle macchine di riconoscere caratteri di testo stampati o scritti a mano all'interno di immagini digitali.
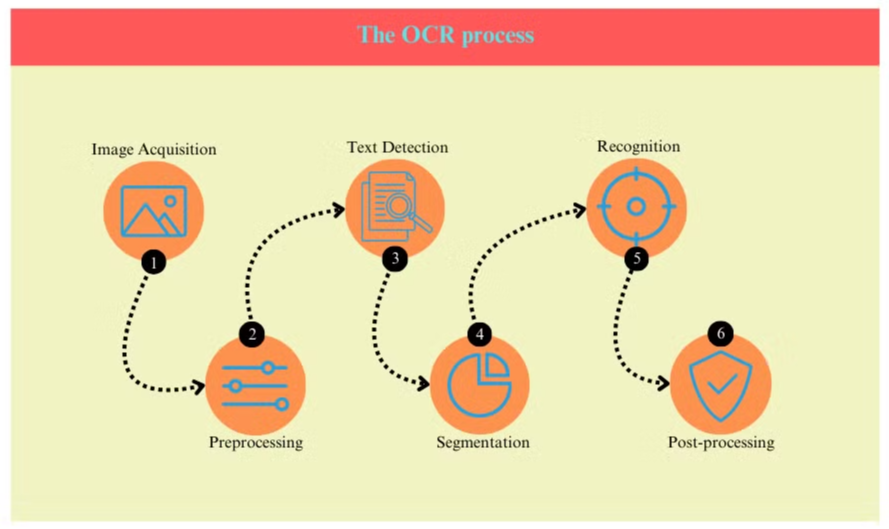
Il Processo OCR
Il processo OCR tipicamente coinvolge diversi passaggi:
- Acquisizione dell'Immagine: Il documento viene scansionato o fotografato per creare un'immagine digitale.
- Pre-elaborazione: L'immagine viene ripulita, rimuovendo il rumore e regolando luminosità e contrasto.
- Rilevamento del Testo: Il sistema identifica le aree contenenti testo all'interno dell'immagine.
- Segmentazione dei Caratteri: I singoli caratteri vengono isolati all'interno delle aree di testo.
- Riconoscimento dei Caratteri: Ogni carattere viene analizzato e confrontato con un database di caratteri noti.
- Post-elaborazione: Il testo riconosciuto viene controllato per errori utilizzando informazioni linguistiche e contestuali.
Sebbene l'OCR abbia notevolmente migliorato le capacità di analisi dei documenti, deve ancora affrontare limitazioni nella gestione di layout complessi, immagini di bassa qualità e font vari. È qui che tecnologie avanzate come i modelli di linguaggio visivo stanno intervenendo per migliorare l'accuratezza e la comprensione nell'estrazione dei dati da immagini e documenti.
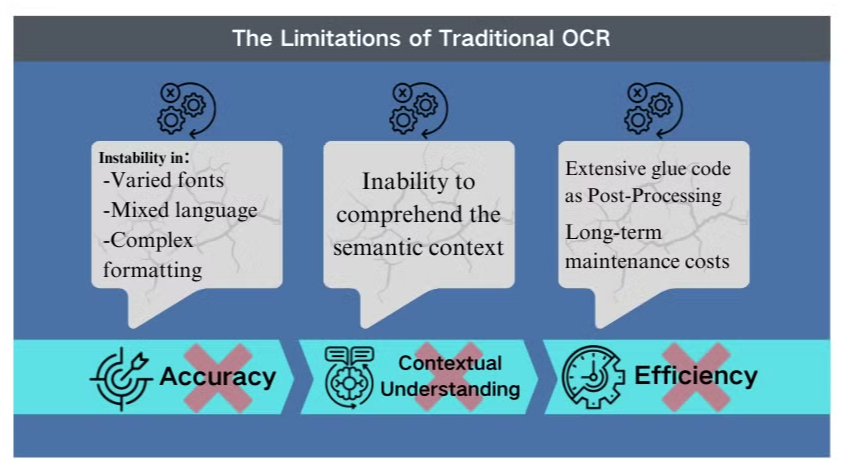
Le Limitazioni della Tecnologia OCR Tradizionale
Sfide di Accuratezza in Scenari Complessi
La tecnologia di riconoscimento ottico dei caratteri (OCR) tradizionale, sebbene utile per l'estrazione di testo di base, affronta ostacoli significativi quando si confronta con layout documentali intricati o immagini di bassa qualità. Questi sistemi spesso faticano a mantenere l'accuratezza nel processamento di documenti con font vari, lingue miste o formattazioni complesse. Ad esempio, l'OCR può fallire nel tentativo di estrarre dati da presentazioni ricche di immagini o PDF densamente formattati.
Mancanza di Comprensione Contestuale
Una delle limitazioni più evidenti dell'OCR convenzionale è la sua incapacità di comprendere il contesto semantico del testo che elabora. Questa carenza diventa particolarmente evidente in scenari che richiedono interpretazioni sfumate, come contratti legali o referti medici. Il focus dell'OCR sul riconoscimento dei caratteri senza consapevolezza contestuale può portare a interpretazioni critiche errate, specialmente quando si tratta di caratteri ambigui o terminologia specifica del settore.
Inefficienze nella Post-elaborazione
Le limitazioni dell'OCR spesso richiedono ampi sforzi di post-elaborazione. Questo passaggio aggiuntivo può aumentare significativamente il tempo e le risorse necessarie per l'elaborazione dei documenti. Inoltre, i sistemi OCR tradizionali di solito non riescono quando devono estrarre informazioni da grafici, tabelle o altri elementi non testuali, complicando ulteriormente il processo di estrazione dei documenti. Queste inefficienze sottolineano la necessità di soluzioni più avanzate, come i modelli di linguaggio visivo, che offrono un approccio più completo all'analisi dei documenti e all'estrazione dei dati.
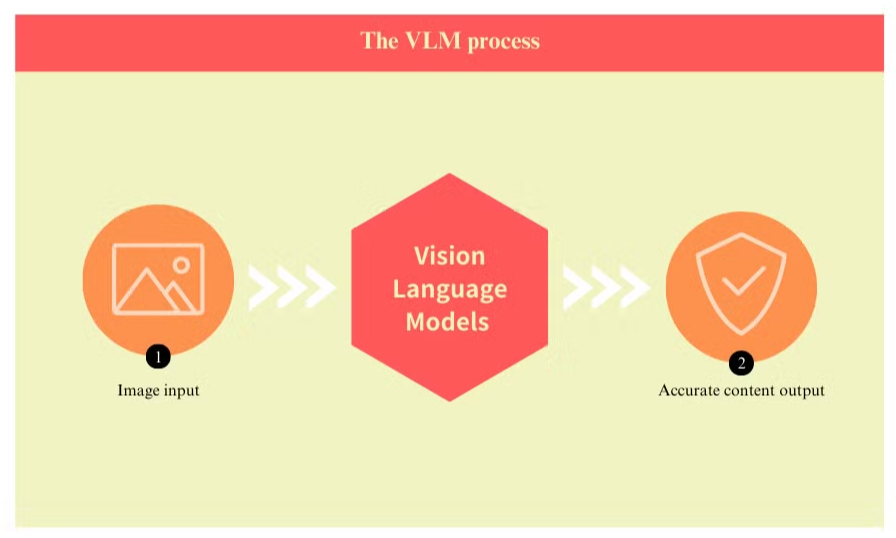
Cos'è il Modello di Linguaggio Visivo e come Migliora l'OCR
I modelli di linguaggio visivo rappresentano un significativo passo avanti nella tecnologia di elaborazione dei documenti, affrontando molte delle limitazioni intrinseche nei sistemi di riconoscimento ottico dei caratteri (OCR) tradizionali. Questi modelli avanzati combinano la visione artificiale con l'elaborazione del linguaggio naturale per comprendere simultaneamente sia gli elementi visivi che testuali dei documenti.
Maggiore Accuratezza e Comprensione Contestuale
A differenza dell'OCR, che fatica con immagini di bassa qualità e layout complessi, i modelli di linguaggio visivo eccellono nell'interpretare diversi formati documentali. Possono estrarre dati in modo accurato da immagini, PDF e altri contenuti visivi, anche quando si trovano di fronte a scenari difficili. Questa maggiore accuratezza deriva dalla loro capacità di considerare l'intero contesto di un documento, piuttosto che concentrarsi esclusivamente su singoli caratteri o parole.
Estrazione Completa dei Dati
I modelli di linguaggio visivo vanno oltre il semplice riconoscimento del testo, offrendo capacità complete di estrazione dei dati da PDF. Possono identificare e interpretare tabelle, grafici e figure all'interno dei documenti, preservando l'integrità di layout complessi. Questo approccio olistico all'analisi dei documenti consente un recupero delle informazioni più sfumato e completo, migliorando significativamente l'utilità dei dati estratti per le applicazioni successive.
Competenza Multilingue e Multi-formato
Uno dei principali vantaggi dei modelli di linguaggio visivo è la loro flessibilità nella gestione di più lingue e formati documentali. A differenza dei sistemi OCR che possono avere difficoltà con scritture non latine o documenti in lingue miste, questi modelli possono elaborare senza problemi contenuti in diverse lingue e scritture, rendendoli inestimabili per le esigenze di elaborazione documentale globale.
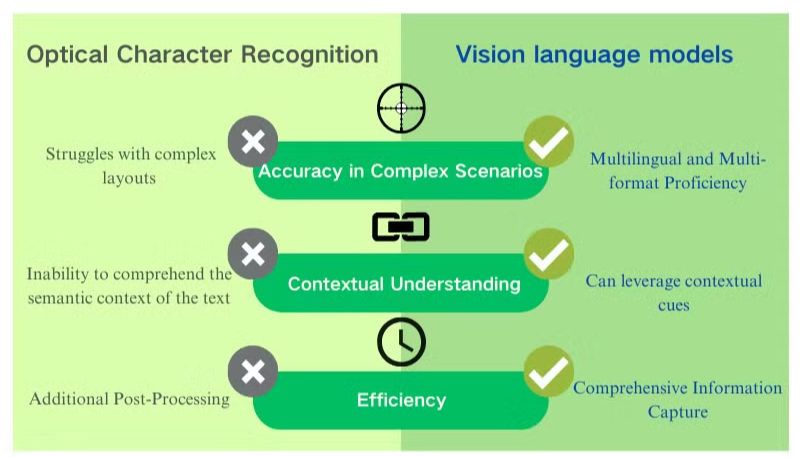
Vantaggi Chiave dei Modelli di Linguaggio Visivo per la Comprensione dei Documenti
I modelli di linguaggio visivo offrono vantaggi significativi rispetto all'OCR tradizionale per l'elaborazione dei documenti e l'estrazione dei dati. Questi sistemi alimentati dall'AI combinano comprensione visiva e testuale per fornire risultati superiori attraverso vari tipi di documenti.
Maggiore Accuratezza e Comprensione Contestuale
I modelli di linguaggio visivo eccellono nella gestione di layout complessi, immagini di bassa qualità e font diversi. A differenza dell'OCR, che fatica con caratteri ambigui, questi modelli sfruttano indizi contestuali per interpretare accuratamente il testo. Questa capacità migliora notevolmente l'accuratezza dell'estrazione dei dati da PDF, specialmente per documenti con strutture intricate o scarsa qualità dell'immagine.
Cattura Completa delle Informazioni
Mentre l'OCR si concentra esclusivamente sul riconoscimento del testo, i modelli di linguaggio visivo possono estrarre dati da immagini, tabelle e grafici. Questo approccio olistico garantisce che informazioni critiche non vengano trascurate durante la fase di elaborazione dei documenti. Catturando sia elementi testuali che visivi, questi modelli forniscono una comprensione più completa dei contenuti del documento.
Competenza Multilingue e Multi-formato
I modelli di linguaggio visivo dimostrano una notevole flessibilità nell'elaborazione di documenti in diverse lingue e formati. Possono gestire senza problemi documenti in lingue miste e scritture non latine, superando una limitazione significativa dei sistemi OCR tradizionali. Questa versatilità li rende inestimabili per le imprese globali che trattano diversi tipi di documenti e lingue.
Applicazioni Reali Abilitati dai VLM che l'OCR ha Fallito
I modelli di linguaggio visivo stanno rivoluzionando l'elaborazione dei documenti in finanza, risorse umane e altri settori affrontando limitazioni critiche dei sistemi OCR tradizionali. Questi modelli AI avanzati stanno trasformando gli sforzi di digitalizzazione in tutti i settori offrendo maggiore accuratezza e comprensione contestuale.
Rivoluzionare l'Elaborazione dei Documenti Finanziari
I modelli di linguaggio visivo stanno trasformando l'elaborazione dei documenti in finanza, superando le limitazioni dell'OCR tradizionale. Questi modelli avanzati eccellono nell'estrazione di dati da complessi bilanci finanziari, fatture e ricevute con layout intricati. A differenza dell'OCR, possono comprendere il contesto, interpretando accuratamente caratteri ambigui (ad esempio, differenziare tra uno zero e la lettera O) e lingue miste spesso presenti nei documenti finanziari globali.
Migliorare le Operazioni HR attraverso l'Analisi Intelligente dei Documenti
Nel settore HR, i modelli di linguaggio visivo si stanno rivelando inestimabili per l'estrazione dei dati da PDF da curricula, registri dei dipendenti e valutazioni delle prestazioni. Questi modelli possono comprendere la struttura semantica dei documenti, consentendo un recupero e un'analisi delle informazioni più accurati. Questa capacità semplifica notevolmente i processi di assunzione e la gestione dei dati dei dipendenti, compiti in cui l'OCR spesso fatica con formati vari e note scritte a mano.
Migliorare la Conformità e la Gestione del Rischio
I modelli di linguaggio visivo sono particolarmente efficaci nella conformità e nella gestione del rischio sia in finanza che in HR. Possono estrarre e interpretare informazioni critiche da documenti normativi, contratti e politiche con maggiore accuratezza rispetto all'OCR. Questa capacità migliorata di elaborazione dei documenti garantisce una migliore aderenza ai requisiti legali e procedure di valutazione del rischio più efficienti.
Conclusione
In conclusione, i modelli di linguaggio visivo rappresentano un significativo passo avanti nella tecnologia di elaborazione dei documenti, affrontando molte delle limitazioni intrinseche dei sistemi OCR tradizionali. Combinando comprensione visiva e testuale, questi modelli avanzati offrono prestazioni superiori in una vasta gamma di scenari impegnativi, da layout complessi a lingue miste e immagini di bassa qualità. Man mano che le organizzazioni continuano a digitalizzare le loro operazioni e cercano modi più efficienti per estrarre valore dai loro archivi documentali, i modelli di linguaggio visivo emergono come uno strumento potente per sviluppatori e leader ingegneristici. La loro capacità di comprendere il contesto, gestire formati diversi e fornire risultati più accurati li posiziona come un abilitante chiave per pipeline RAG sofisticate e capacità di ricerca a livello aziendale, guidando infine le iniziative di trasformazione digitale a nuovi livelli.