Ti sei mai chiesto cosa significhi OCR? Il riconoscimento ottico dei caratteri è una tecnologia potente che converte le immagini di testo in dati leggibili dalla macchina. Sebbene l'OCR offra enormi vantaggi per la digitalizzazione dei documenti e l'estrazione delle informazioni, non è privo di svantaggi. Mentre esplori questa tecnologia, è fondamentale comprendere sia le sue capacità che le sue limitazioni. In questo articolo, scoprirai il significato di OCR e approfondirai i suoi potenziali svantaggi. Acquisendo una comprensione completa del riconoscimento ottico dei caratteri, sarai meglio attrezzato per determinare se e come implementare questa tecnologia nei tuoi flussi di lavoro e progetti.
Cosa significa OCR e cos'è un OCR?
Cosa significa OCR?
OCR sta per riconoscimento ottico dei caratteri, una tecnologia che consente ai computer di riconoscere e convertire vari tipi di documenti. Alla base, l'OCR è il processo di scansione di testo stampato o scritto a mano e la sua conversione in testo codificato dalla macchina. Questo consente al testo di essere ricercabile, modificabile e trasferibile con facilità. Comprendere cosa significa OCR è essenziale per chiunque lavori con tecnologie di scansione dei documenti e riconoscimento del testo.
Cos'è un OCR?
Per chi non è familiare con il termine, "cos'è un OCR" è una domanda comune, che si riferisce al riconoscimento ottico dei caratteri, una tecnologia che consente ai computer di leggere il testo da immagini o documenti scansionati.
L'OCR converte il testo stampato o scritto a mano in dati leggibili dalla macchina, colmando il divario tra formati cartacei e digitali. Questa tecnologia impiega algoritmi sofisticati per rilevare le forme delle lettere, le strutture delle parole e persino intere frasi. In questo modo, trasforma immagini statiche in file di testo modificabili e ricercabili.
La tecnologia OCR si basa fondamentalmente su tecnologie di visione artificiale e riconoscimento dei modelli. L'OCR funziona scansionando documenti o immagini contenenti testo e utilizzando algoritmi avanzati per identificare e convertire il testo in un formato digitale e modificabile. Uno dei momenti chiave nella storia della tecnologia OCR è stato nel 1974, quando Ray Kurzweil sviluppò un sistema OCR omni-font in grado di riconoscere il testo in praticamente qualsiasi font. Nel corso degli anni, l'OCR è evoluto da un semplice abbinamento di modelli a sistemi più sofisticati.
Nonostante le sue capacità, la tecnologia OCR attualmente affronta alcune limitazioni. Queste includono sfide nel riconoscere il testo in immagini di scarsa qualità, difficoltà nella gestione di layout o sfondi complessi e variazioni di accuratezza quando si tratta di diversi font, lingue o scrittura a mano. Inoltre, i sistemi OCR possono avere difficoltà con documenti che presentano sfondi colorati, sono sfocati o inclinati, e con la scrittura corsiva.
Comprendere il software di riconoscimento ottico dei caratteri
Il software di riconoscimento ottico dei caratteri è una tecnologia trasformativa che converte vari tipi di documenti in dati modificabili e ricercabili. Gioca un ruolo cruciale nella digitalizzazione del nostro mondo, rendendo le informazioni più accessibili e gestibili. Il software OCR impiega un processo sofisticato per convertire le immagini di testo in dati leggibili dalla macchina.
Come funziona il software OCR
1. Acquisizione dell'immagine
Il viaggio dell'OCR inizia con la cattura di un'immagine del documento. Questo può avvenire tramite uno scanner o una fotocamera digitale. L'immagine viene quindi tradotta in un formato digitale che un computer può elaborare.
2. Pre-elaborazione e miglioramento dell'immagine
Il secondo passo implica il miglioramento della qualità dell'immagine. Una volta acquisita l'immagine, essa subisce una pre-elaborazione per migliorare la qualità per un riconoscimento migliore. Questo passaggio può comportare la regolazione del contrasto, della luminosità e della nitidezza dell'immagine, oltre alla rimozione di rumori o elementi irrilevanti. Questa fase di pre-elaborazione è cruciale per ottenere risultati accurati, specialmente quando si tratta di scansioni o fotografie di bassa qualità.
3. Rilevamento del testo
Il software OCR analizza l'immagine pre-elaborata per rilevare le aree che contengono testo. Lo fa cercando schemi e forme caratteristici del testo, come righe di diverse spessori e altezze.
4. Segmentazione dei caratteri
Una volta rilevate le aree di testo, il software suddivide il testo in unità più piccole, come blocchi, righe, parole o persino singoli caratteri. Il software OCR analizza l'immagine pixel per pixel per identificare schemi che formano caratteri. Suddivide l'immagine in segmenti più piccoli, isolando ciascun carattere.
5. Riconoscimento ed estrazione del testo
Il software confronta quindi queste forme isolate con un vasto database di schemi di caratteri noti per determinare cosa rappresenti ciascun carattere. Il software estrae caratteristiche dai caratteri, come il numero di linee, curve o angoli. Queste caratteristiche aiutano l'OCR a riconoscere e distinguere tra diversi caratteri.
6. Post-elaborazione
Dopo che i caratteri sono stati identificati, il sistema OCR passa attraverso una fase di post-elaborazione in cui corregge eventuali errori potenziali e formatta il testo per l'output. Il testo corretto viene quindi esportato nel formato desiderato, come un documento Word o un PDF ricercabile.
Casi d'uso con il software di riconoscimento ottico dei caratteri
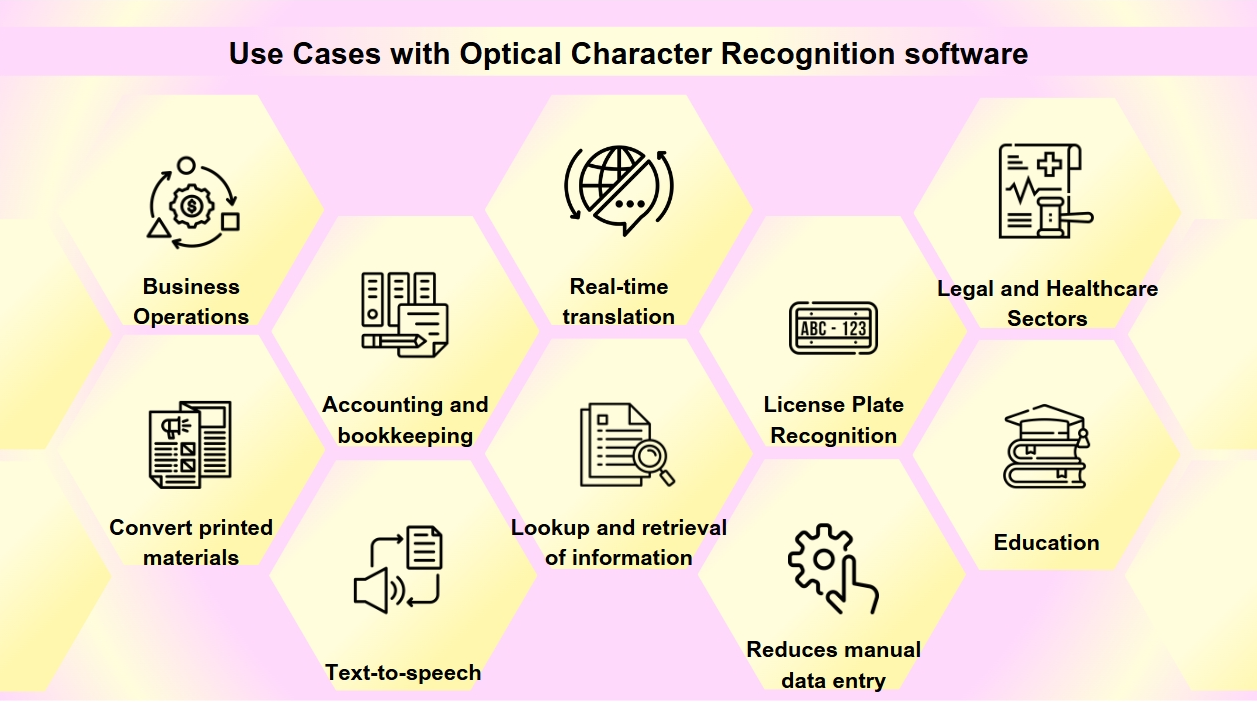
L'OCR è diventato uno strumento essenziale nella trasformazione digitale di molte industrie, semplificando i processi e migliorando l'accessibilità e l'accuratezza dei dati. Potresti incontrare l'OCR più spesso di quanto tu non realizzi. Dalla scansione di biglietti da visita alla digitalizzazione di vecchi libri, l'OCR gioca un ruolo cruciale in vari settori. La tecnologia OCR ha una vasta gamma di applicazioni:
-
Digitalizzazione dei documenti: L'OCR viene utilizzato per convertire materiali stampati come vecchi libri, giornali e documenti storici in formati digitali, rendendoli ricercabili e preservandoli per le generazioni future.
-
Elaborazione dei moduli: Le aziende sfruttano l'OCR per estrarre automaticamente dati dai moduli, riducendo l'inserimento manuale dei dati e aumentando l'efficienza in vari settori come finanza e sanità.
-
Elaborazione delle fatture: La tecnologia OCR può leggere il testo sulle fatture e inserire automaticamente i dati nei sistemi finanziari, semplificando i processi contabili e di registrazione.
-
Accessibilità: L'OCR consente la funzionalità di sintesi vocale, creando versioni audio del testo per persone non vedenti, rendendo così i materiali stampati più accessibili.
-
Applicazioni mobili: L'OCR è integrato in app per attività come la scansione di biglietti da visita, il riconoscimento del testo nelle foto e la facilitazione della traduzione in tempo reale.
-
Ricercabilità: L'OCR migliora la ricercabilità dei documenti scansionati estraendo testo da immagini o PDF, consentendo una facile ricerca e recupero delle informazioni.
-
Riconoscimento delle targhe: Utilizzato per la gestione del parcheggio e del traffico, l'OCR può riconoscere le targhe, consentendo un monitoraggio e un'applicazione efficienti.
-
Operazioni aziendali: L'OCR semplifica i processi aziendali automatizzando l'inserimento dei dati da documenti come fatture, ricevute e ordini di acquisto, oltre a velocizzare il reclutamento scansionando e elaborando domande di lavoro e curriculum.
-
Settori legali e sanitari: Gli studi legali utilizzano l'OCR per digitalizzare fascicoli e documenti legali per un recupero delle informazioni più semplice, mentre i fornitori di assistenza sanitaria lo utilizzano per convertire registri dei pazienti e moduli medici in registri elettronici della salute (EHR), migliorando la gestione dei dati e l'assistenza ai pazienti.
-
Istruzione: Negli ambienti educativi, l'OCR viene utilizzato per creare libri di testo digitali e materiali didattici, migliorando l'accessibilità per studenti con esigenze diverse e supportando un ambiente di apprendimento inclusivo.
Man mano che la tecnologia OCR avanza, continua a svolgere un ruolo vitale nel rendere le informazioni più accessibili e facili da gestire nell'era digitale.
Gli svantaggi dell'OCR: Limitazioni e problemi
Sfide di accuratezza
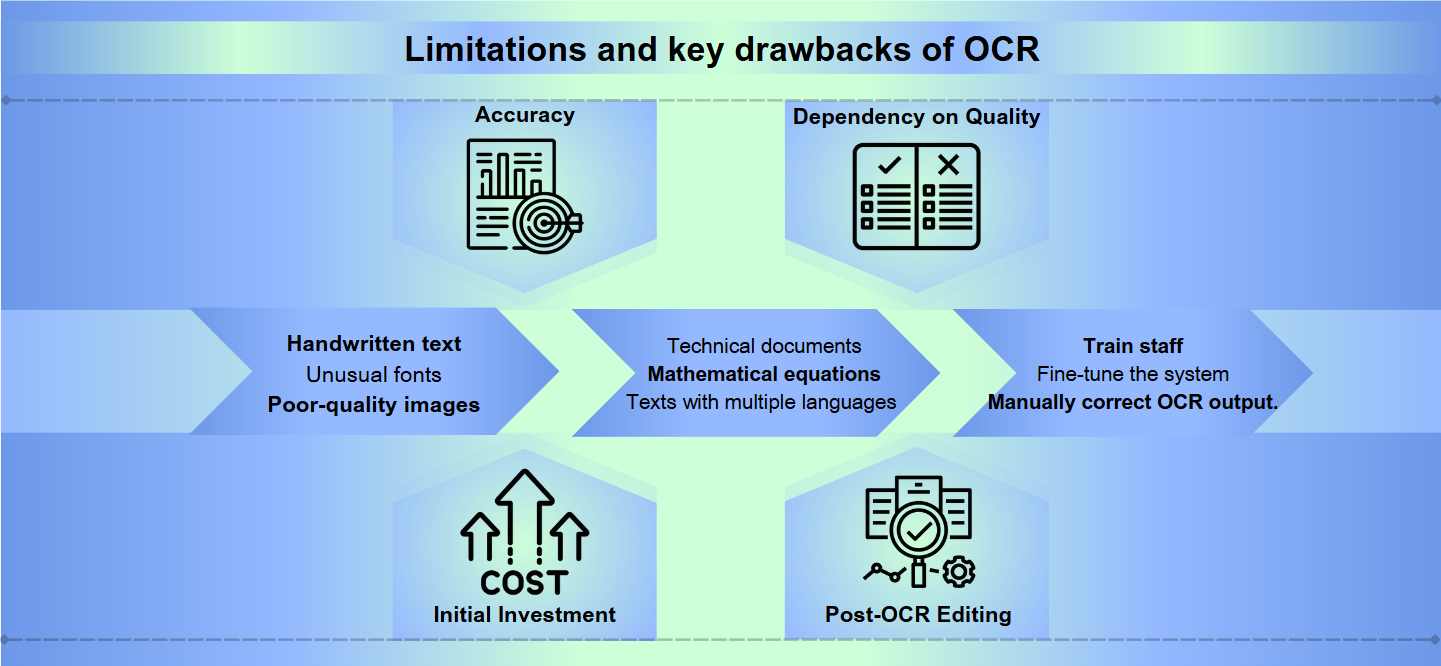
Sebbene la tecnologia di riconoscimento ottico dei caratteri (OCR) abbia fatto molta strada, affronta ancora ostacoli significativi nel raggiungere un'accuratezza perfetta. Il testo scritto a mano, i font insoliti o le immagini di scarsa qualità possono portare a interpretazioni errate ed errori. Anche lievi variazioni nelle forme o nelle dimensioni dei caratteri possono confondere i sistemi OCR, risultando in output illeggibili che richiedono correzioni manuali.
Restrizioni linguistiche e di formato
La maggior parte delle soluzioni OCR eccelle con lingue e formati standard, ma fatica con contenuti specializzati. Documenti tecnici, equazioni matematiche o testi con più lingue possono presentare sfide significative. Inoltre, l'OCR può avere difficoltà quando si confronta con layout complessi, tabelle o documenti con formattazioni intricate, perdendo potenzialmente informazioni strutturali cruciali.
Intensità delle risorse
Implementare e mantenere un sistema OCR efficace può essere intensivo in termini di risorse. Un software OCR di alta qualità spesso ha un costo elevato, e l'hardware necessario per elaborare grandi volumi di documenti può essere costoso. Inoltre, il tempo e lo sforzo necessari per formare il personale, ottimizzare il sistema e rivedere e correggere manualmente l'output OCR possono mettere a dura prova le risorse organizzative.
Principali svantaggi dell'OCR
-
Accuratezza: Il software OCR può avere difficoltà con l'accuratezza, specialmente quando si tratta di immagini di scarsa qualità, layout complessi o testo scritto a mano. Gli errori possono variare dalla lettura errata dei caratteri al salto di intere sezioni di testo.
-
Dipendenza dalla qualità: L'efficacia dell'OCR dipende fortemente dalla qualità del documento originale. Inchiostro sbiadito, macchie o carta spiegazzata possono portare a traduzioni inaccurate.
-
Investimento iniziale: L'installazione di un sistema OCR può richiedere un costo iniziale significativo, che include non solo il software ma anche hardware compatibile come scanner.
-
Modifica post-OCR: Spesso, l'output dei processi OCR richiede una revisione e una correzione manuale, il che può richiedere tempo.
Modello di linguaggio visivo che supera le limitazioni dell'OCR
Con l'avanzare della tecnologia, stanno emergendo soluzioni innovative per affrontare le carenze del riconoscimento ottico dei caratteri (OCR) tradizionale. Una di queste innovazioni è il Modello di Linguaggio Visivo (VLM), che combina visione artificiale e elaborazione del linguaggio naturale per rivoluzionare l'estrazione e la comprensione del testo.
Comprensione contestuale migliorata
I VLM eccellono nella comprensione del contesto che circonda il testo, a differenza del riconoscimento isolato dei caratteri dell'OCR. Analizzando gli elementi visivi insieme al testo, questi modelli possono interpretare layout complessi, appunti scritti a mano e persino testo parzialmente oscurato con notevole accuratezza.
Capacità multilingue e multimodali
Mentre l'OCR spesso fatica con lingue e scritture diverse, i VLM dimostrano un'imponente versatilità. Possono elaborare senza problemi più lingue e persino interpretare contenuti visivi come diagrammi o grafici, fornendo una comprensione più completa dei documenti.
Apprendimento adattivo e miglioramento continuo
A differenza dei sistemi OCR statici, i VLM sfruttano l'apprendimento automatico per adattarsi e migliorare nel tempo. Man mano che incontrano nuovi dati e scenari, questi modelli affinano le loro prestazioni, diventando sempre più abili nella gestione di vari tipi e formati di documenti.
Superando le limitazioni dell'OCR, i Modelli di Linguaggio Visivo stanno aprendo la strada a un'elaborazione dei documenti più accurata, efficiente e intelligente in tutti i settori.
Scegli il Modello di Linguaggio Visivo: Prova AnyParser
Basandosi sui progressi dei Modelli di Linguaggio Visivo (VLM), AnyParser emerge come una soluzione sofisticata che trascende le limitazioni della tecnologia OCR tradizionale. Sviluppato dal team di CambioML, AnyParser è uno strumento potente per l'analisi dei documenti che utilizza un'API precisa e configurabile per estrarre informazioni da varie fonti di dati non strutturati come PDF, immagini e grafici, convertendoli in formati strutturati.
Fondamento tecnico e capacità
AnyParser è ancorato su una solida base di modelli di linguaggio di grandi dimensioni (LLM), garantendo alta accuratezza nell'estrazione di testo, tabelle, grafici e layout dai documenti. Si distingue per la sua capacità di mantenere il layout e il formato originali, una caratteristica particolarmente vantaggiosa per documenti con layout complessi o che richiedono la preservazione dell'estetica originale.
Privacy e sicurezza
Sottolineando la privacy degli utenti, AnyParser elabora i dati localmente, proteggendo così le informazioni sensibili. Questa caratteristica è un vantaggio significativo per le aziende e gli individui che trattano dati riservati.
Personalizzabilità e flessibilità
Offrendo un alto grado di configurabilità, AnyParser consente agli utenti di impostare regole di estrazione personalizzate e definire formati di output che soddisfano le loro esigenze specifiche. Questa adattabilità lo rende uno strumento ideale per una vasta gamma di applicazioni, dall'ingegneria AI all'analisi finanziaria.
Conclusione
Come hai appreso, la tecnologia OCR offre potenti capacità per la digitalizzazione del testo, ma non è priva di limitazioni. Sebbene il riconoscimento ottico dei caratteri possa migliorare notevolmente l'efficienza, è necessario valutare attentamente i potenziali svantaggi. Considera i problemi di accuratezza, le sfide di formattazione e i requisiti di risorse prima di implementare una soluzione OCR. In definitiva, la decisione di utilizzare l'OCR dipende dalle tue esigenze e circostanze specifiche. Comprendendo sia i benefici che gli svantaggi, puoi prendere una decisione informata su se l'OCR sia adatto alla tua organizzazione. Man mano che l'OCR continua ad evolversi, rimani aggiornato sulle nuove sviluppi che potrebbero affrontare le carenze attuali e sbloccare un potenziale ancora maggiore per questa tecnologia trasformativa.
Invito all'azione
Abbraccia il potere dei Modelli di Linguaggio Visivo provando AnyParser gratuitamente per convertire i tuoi PDF in Google Sheets su https://www.cambioml.com/sandbox. Richiedi una consulenza gratuita su come i VLM possono migliorare il tuo flusso di lavoro di estrazione dei dati.