はじめに
今日のデータ駆動型の世界では、画像から情報を抽出する能力が業界を問わずビジネスにとって重要です。請求書、チャート、スキャンしたフォーム、または領収書など、画像を含む文書は貴重な洞察を持っていますが、データ抽出には課題があります。AI画像処理は、視覚に埋め込まれたデータを効率的に抽出し解釈するための変革的なソリューションとして浮上しています。
PNGからテキストへの変換や、画像からCSVまたはExcelファイルへの変換ができるツールの必要性は、これまで以上に重要です。人工知能によって強化されたインテリジェントドキュメントパーシングは、これらの変換を簡素化するだけでなく、複雑な画像や混合フォーマットに対処する際にも高い精度と速度を確保します。このブログでは、AI画像抽出がデータワークフローをどのように再定義しているのか、そしてなぜそれがビジネスにとってゲームチェンジャーであるのかを探ります。

AI画像抽出とは?
AI画像抽出は、特に視覚言語モデル(VLM)によって強化された高度な人工知能技術を使用して、文書に埋め込まれた画像から意味のある情報を特定、分析、抽出することを含みます。従来のルールベースのアプローチや基本的な画像処理に依存する方法とは異なり、AI駆動の抽出は文脈理解を取り入れて精度とスケーラビリティを向上させます。
VLMは、コンピュータビジョンと自然言語処理を組み合わせて、画像内の視覚要素(形状、色、レイアウトなど)と埋め込まれたテキストの両方を解釈します。たとえば、VLMはスキャンした請求書からテキストを抽出するだけでなく、その役割(たとえば、他のテキストとの空間的関係に基づいて値を小計や税額としてラベル付けする)を理解することができます。このマルチモーダル機能により、AIは表面的なデータ抽出を超えて、注釈付きの図、チャート、または混合言語コンテンツのような複雑な視覚を処理することができます。
これらのモデルを活用することで、AI画像抽出は比類のない精度と適応性を提供し、インテリジェントドキュメントパーシングワークフローの重要な要素となっています。
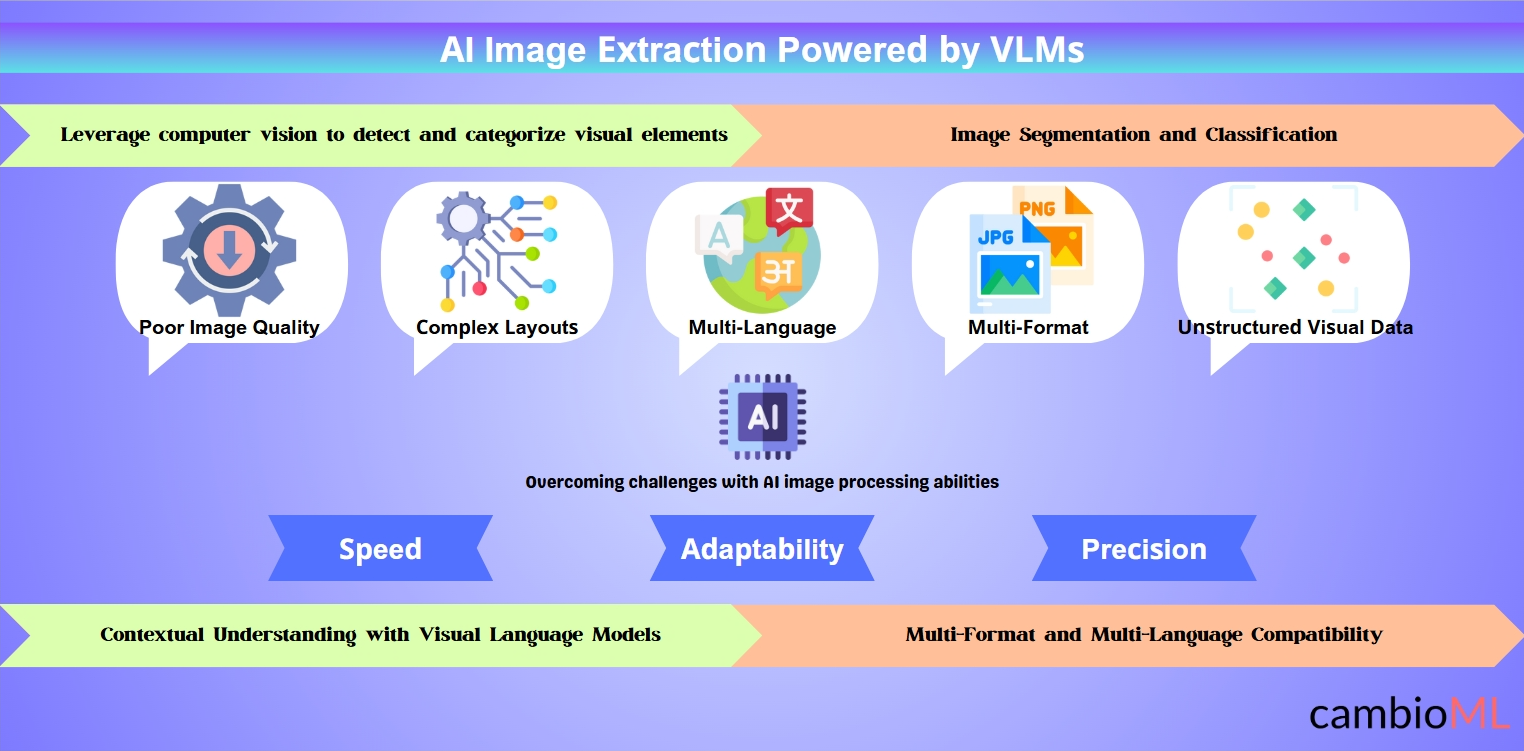
画像ベースのドキュメントパーシングにおける課題
画像が多い文書からデータを抽出することは、特にAI画像処理の適応性が欠如している従来のシステムにとって多くの課題を伴います。以下は、最も一般的な障害のいくつかです:
-
画像の質が悪い: スキャンしたフォームや領収書など、多くの文書は低解像度、ぼやけ、ノイズなどの問題を抱えています。これにより、従来のツールが正確なデータを抽出したり、画像をCSVまたはExcel形式に変換したりすることが難しくなります。
-
複雑なレイアウト: 重なり合った要素、入れ子構造、または混合コンテンツタイプ(たとえば、テキストと並んだチャート)を含む画像は、高度なAIシステムなしでは解析が困難です。たとえば、グラフや注釈を含む文書でPNGをテキストに変換するには、文脈理解が必要です。
-
多言語および多フォーマットの課題: 文書には複数の言語が含まれている場合や、スキャンしたPDFやPNGなどの多様なフォーマットで提供されることがあります。AIなしでは、そのようなソースから正確なデータを抽出したり、画像をCSVに変換したりすることはほぼ不可能です。
-
非構造化視覚データ: 図やインフォグラフィックなどの視覚データは、明確な構造が欠如していることが多く、従来のツールが実用的な洞察を抽出したり、画像をExcelにシームレスに変換したりすることが困難です。
AI画像処理は、強力なアルゴリズムと文脈的知性を組み合わせることで、これらの課題を克服し、最も複雑な視覚データを正確かつ効率的に解析することを可能にします。
AIがドキュメントパーシングにおける画像抽出を向上させる方法
AIは、複数の最先端技術を統合することにより、画像抽出を効率的で正確かつスケーラブルなプロセスに変革します。AIがこのタスクをどのように向上させるかを見てみましょう:
1. 視覚分析のためのコンピュータビジョン
AIはコンピュータビジョンを活用して、形状、パターン、テキストなどの視覚要素を検出し、分類します。これにより、スキャンした文書内の画像の異なる部分を区別することができます。
2. 光学文字認識(OCR)
AIによって強化されたOCR技術は、画像内のテキストを機械可読形式に変換します。高度なOCRツールは、多様なフォント、言語、さらには手書きにも対応し、複雑な視覚からのテキストデータの抽出を改善します。
3. 画像のセグメンテーションと分類
AIモデルは画像を異なる領域にセグメント化し、スキャンした契約書からテーブル、ロゴ、署名などの関連エリアを特定して焦点を合わせることができます。
4. 視覚言語モデル(VLM)による文脈理解
VLMは、AIシステムがテキストと画像の相互作用を理解することを可能にします。たとえば、チャート内では、VLMは凡例、ラベル、データポイントを一緒に解釈し、正確なデータ解析を確保します。
5. 多フォーマットおよび多言語の互換性
AIは、さまざまなファイル形式(JPEG、PNG、TIFF、PDF)で画像を認識し処理するように訓練されており、複数の言語でテキストを抽出できるため、従来のシステムの大きな制限を克服しています。
使用例:
- 会計目的でスキャンした請求書から数値データを抽出する。
- 医療処方箋の手書きメモをデジタル化するために解析する。
- エンジニアリング文書からの図面などの視覚データを特定して分離する。
スピード、精度、適応性を組み合わせることで、AIは従来の技術では不可能な方法で画像抽出を向上させ、組織が視覚データを効率的に活用できるようにします。
業界におけるAI画像抽出の応用
インテリジェントドキュメントパーシングの進展に支えられたAI画像抽出は、さまざまな業界で応用されています。以下は、主要な使用例のいくつかです:
-
医療: 医療分野では、AI画像処理を使用してスキャンしたフォームから患者データを抽出し、医療チャートや処方箋をPNGからテキストに変換し、さらには臨床診断のために画像を分析します。
-
銀行および金融: 金融セクターは、AIを使用して小切手、請求書、領収書を処理することで利益を得ています。画像をExcelやCSVに変換できるツールは、経費追跡や口座調整などのワークフローを効率化します。
-
小売: 小売業者は、商品ラベル、バーコード、スキャンした領収書からデータを抽出するためにAIを使用します。PNGからテキストや画像からCSVへの変換は、小売業者が在庫記録を効率的にデジタル化し、分析することを可能にします。
-
物流: AIは物流業界の企業がラベルや追跡文書から出荷詳細を抽出し、画像をExcelスプレッドシートに変換してデータベースとのシームレスな統合を実現します。
-
法務およびコンプライアンス: 法律専門家は、AIツールを使用して契約を分析し、条項を抽出し、スキャンした法的文書をCSVやExcelなどの構造化された形式に変換してコンプライアンスワークフローを簡素化します。
これらのプロセスを自動化することで、AI画像抽出は効率を高めるだけでなく、正確性、スケーラビリティ、コスト削減を確保します。PNGからテキストへの変換や高度なAI画像処理などの機能を統合したソリューションは、業務を現代化しようとする企業にとって不可欠なものとなっています。
AI画像抽出の主な利点
AIによる画像抽出は、画像が多い文書を扱う組織にとって比類のない利点を提供します。以下は、主な利点のいくつかです:
-
精度と速度の向上: AI画像処理は、低品質または複雑な画像から迅速かつ正確に情報を抽出できます。分析のために画像をテーブル形式に変換したり、データ統合のために画像をExcelに変換したりする場合でも、結果は正確で信頼性があります。
-
スケーラビリティ: AIシステムは、大量の文書を処理できるため、大規模なデータフローを持つ業界に最適です。たとえば、数百のスキャンした請求書を処理したり、大量の画像データをExcelに変換したりすることは、もはやボトルネックではありません。
-
フォーマット間の互換性: AIは多様なファイルタイプでの作業に優れており、組織がPNG、PDF、その他のフォーマットからデータを抽出し、テーブルやスプレッドシートのような構造化された出力に変換することを可能にします。
-
コスト削減: 手動プロセスを自動化することで、企業は労働コストを削減し、特に画像をテーブルレイアウトに変換したり、他の反復的なタスクを実行したりする際のエラーを最小限に抑えることができます。
これらの利点により、AI画像処理は現代のビジネスにとって不可欠なツールとなり、業務を最適化し、データの潜在能力を最大限に引き出すのに役立ちます。
AI画像抽出の背後にある技術
AI画像抽出は、視覚と言語モデル(VLM)と関連技術の統合によって革命を迎え、機械が画像と関連するテキストデータを全体的に処理できるようにします。これらの技術がどのように貢献するかを見てみましょう:
視覚言語モデル(VLM)
VLMは、画像とテキストの理解を組み合わせて、複雑な視覚データを処理します。これらのモデルは、画像を孤立した視覚としてではなく、含まれるまたは関連するテキストの文脈で分析します。たとえば:
- 技術図面では、VLMは画像要素とともに注釈を解釈できます。
- 多言語文書では、異なる言語でのテキスト抽出をシームレスに切り替え、関連する視覚とリンクさせることができます。
畳み込みニューラルネットワーク(CNN)
CNNは、VLMと連携して、形状、パターン、レイアウトなどの視覚的特徴を特定し処理します。これらのネットワークは、テキスト抽出のために画像領域を分離したり、テーブルやチャートなどの構造的コンポーネントを検出したりするタスクを処理します。
事前学習済みマルチモーダルモデル
最先端の事前学習済みマルチモーダルモデルは、画像とテキストを同時に処理するように設計されています。これらのモデルは、文書の視覚的および言語的側面の相互作用を理解するのに優れており、文脈的に正確なデータ抽出を保証します。
AIによって強化された光学文字認識(OCR)
VLM機能を統合した最新のOCRシステムは、曲面や不良スキャン文書などの困難な視覚からテキストを抽出できます。また、VLMからの文脈的手がかりを利用して出力を洗練し、フォーム内のラベルと値を区別することができます。
新たな応用
-
意味理解: VLMは、AIがテキストを抽出するだけでなく、その文脈での意味を理解できるようにし、法的文書のハイライト部分を重要な条項として認識します。
-
適応型多言語処理: 複数の言語で視覚的および言語的データを解析する能力を持つVLMは、グローバルに多様な文書タイプを処理する上で重要です。
VLMと補完的なAI技術を活用することで、現代の画像抽出は比類のない深さを達成し、組織が最も複雑で非構造化された画像を行動可能なデータに変換できるようにします。
AI画像抽出の未来のトレンド
AI画像処理の未来は、ドキュメントパーシングのためのさらに強力な機能を実現するためのエキサイティングな進展が期待されています:
品質向上のための生成AI
生成的敵対ネットワーク(GAN)などの新興AIモデルは、抽出データの品質を向上させています。たとえば、ぼやけた画像を処理のために改善し、画像をExcelに正確に変換できるようにします。
マルチモーダルAIシステム
将来のシステムは、視覚、テキスト、音声処理を組み合わせて文書を全体的に解釈します。これにより、画像をテーブル形式に抽出して構造化するタスクの精度が向上する可能性があります。
倫理的およびプライバシー重視のAI
データセキュリティの懸念が高まる中、AIシステムは、機密情報を安全かつ倫理的に取り扱うことに焦点を当て、Excelに機密画像を変換するなどのタスクを実行する際にコンプライアンスを確保します。
業界特化型ソリューション
特定の業界向けにカスタマイズされたAIツールが引き続き登場し、金融や医療における複雑な視覚データの抽出など、ニッチな機能を提供します。
これらのトレンドは、AIがデータワークフローにますます不可欠な存在となり、企業が競争力を維持し、革新を続けることを可能にする未来を示しています。
AnyParserの画像処理機能の紹介
AnyParserは、インテリジェントドキュメントパーシングの最前線に立ち、データ抽出ワークフローを効率化したい企業に最先端のソリューションを提供しています。その画像処理機能は業界のリーダーとして際立っており、ユーザーが以下を実現できます:
- 画像をExcelスプレッドシートや構造化データ形式に簡単に変換する。
- 精度を持って表形式の情報を抽出し、即座に分析に適した画像からテーブル形式に変換する。
- PNGからスキャンしたPDFまで、さまざまな画像タイプを処理し、互換性と効率を確保する。
- 高度なAIモデルを活用して、チャート、フォーム、図面などの複雑な視覚を高精度で解析する。
AnyParserの直感的なインターフェースと強力なバックエンドは、文書ワークフローを最適化したい企業にとっての頼れるソリューションとなります。財務データ、医療記録、小売在庫を管理している場合でも、AnyParserは業務を変革するためのツールを提供します。
結論
AI画像抽出は、組織が画像が多い文書を管理する方法を変革しています。高度なAI画像処理技術を活用することで、企業はデータをより効率的に抽出し、構造化することができます。PNGをExcelスプレッドシートに変換することから、画像データをテーブル形式に変換することまで、これらのツールは比類のない精度、スケーラビリティ、柔軟性を提供します。
AnyParserは、この変革をさらに進めるために、最先端のドキュメントパーシング機能を提供し、最も複雑な画像処理タスクを処理できるように設計されています。業界が進化する中、こうした高度なツールを採用することは、競争力を維持し、革新を続けるために不可欠です。
行動を促す
AnyParserの力を体験する準備はできましたか?こちらをクリックして、私たちのサンドボックス環境に入って、画像をExcelに変換し、画像からテーブル形式にデータを抽出し、ドキュメントパーシングワークフローを革命的に変える方法を確認してください。今すぐ無料トライアルを開始し、インテリジェントな画像処理の可能性を解き放ちましょう!