データ管理の領域において、パースとはテキスト、画像、表、メタデータなどのコンテンツを使用可能な形式(例:プレーンテキスト、構造化データ、または画像)に変換するプロセスを指します。これは特にPDFパースの分野で顕著であり、生の情報を構造化された使用可能なデータに変換する重要なプロセスです。この包括的なガイドでは、PDFパースの複雑さを掘り下げ、その定義、抽出可能なデータの範囲、直面する課題、多様なアプリケーション、そしてその可能性を最大限に引き出すための方法の豊富さについて説明します。さまざまなパース手法を探求し、特にPDFパースと、AnyParserのようなツールがどのように群を抜いているかに焦点を当てます。
PDFパーサーの理解:パースとは何か?
パースとは:細心のデータキャプチャプロセス
基本的に、PDFパースはPDF(Portable Document Format)ファイルからデータを抽出し解釈するプロセスを指します。PDFは主に表示用に設計されているため、構造化データの保存には向いていません。パースは、テキスト、画像、表、メタデータなどのコンテンツを使用可能な形式(例:プレーンテキスト、構造化データ、または画像)に変換することを含みます。パースには、PDF内の特定の要素を特定し取得するための高レベルの分析が必要であり、単なるテキストや画像を超えてフォント、レイアウト、表、メタデータを含みます。このプロセスは単なる技術的な手続きではなく、情報の再利用が重要な金融、法律、物流、医療などの多様な業界において必要不可欠です。
PDFからパース可能なデータ
PDFから抽出可能なデータは多様で広範囲にわたります。以下を含みます:
-
テキスト段落:単語と文字の列。
-
単一データフィールド:日付、追跡番号、名前などの個別の要素。
-
表形式データ:表やリストに整理された情報。
-
画像:PDF内に埋め込まれたグラフィカルコンテンツ。
-
高度な要素:ヘッダー、オブジェクト、クロスリファレンステーブル、トレーラー、メタデータなど、より高度なパースツールを必要とするもの。
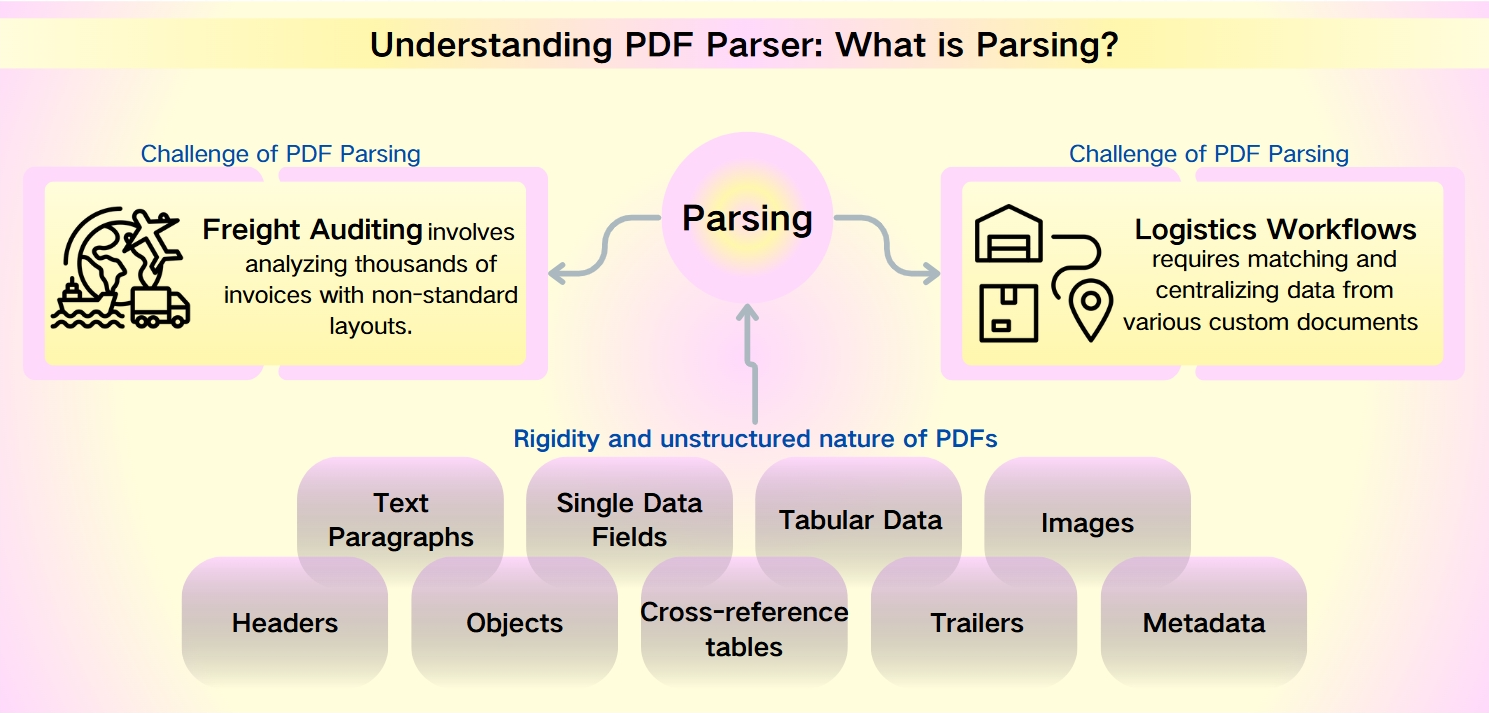
PDFパースの課題:PDFメタデータの非構造的な性質
PDFの堅牢性—セキュリティ、デバイス互換性、コンパクトなファイルサイズによって特徴付けられる—にもかかわらず、そこからデータを抽出することは大きな課題です。PDFの硬直性と非構造的な性質は、迅速な分析と情報取得を妨げます。これは特に、非標準のレイアウトや膨大なデータセットが複雑さを増す貨物監査や物流ワークフローのシナリオで顕著です。
貨物監査は、非標準のレイアウトを持つ数千の請求書を分析することを含みます。物流ワークフローは、梱包リスト、商業請求書、運送状などのさまざまなカスタムドキュメントからデータを照合し中央集権化する必要があります。
パースの重要性
パースは、ウェブ開発からデータキャプチャまで、さまざまな分野で重要な役割を果たします。企業がPDF文書、HTMLファイル、XMLデータなどの非構造的データソースから貴重な洞察を抽出することを可能にします。パースは以下を促進します:
-
データ駆動型の洞察を通じた意思決定の改善。
-
データの正確性と一貫性の向上。
-
データ処理と分析の効率化。
-
情報の取得と保存の効率化。
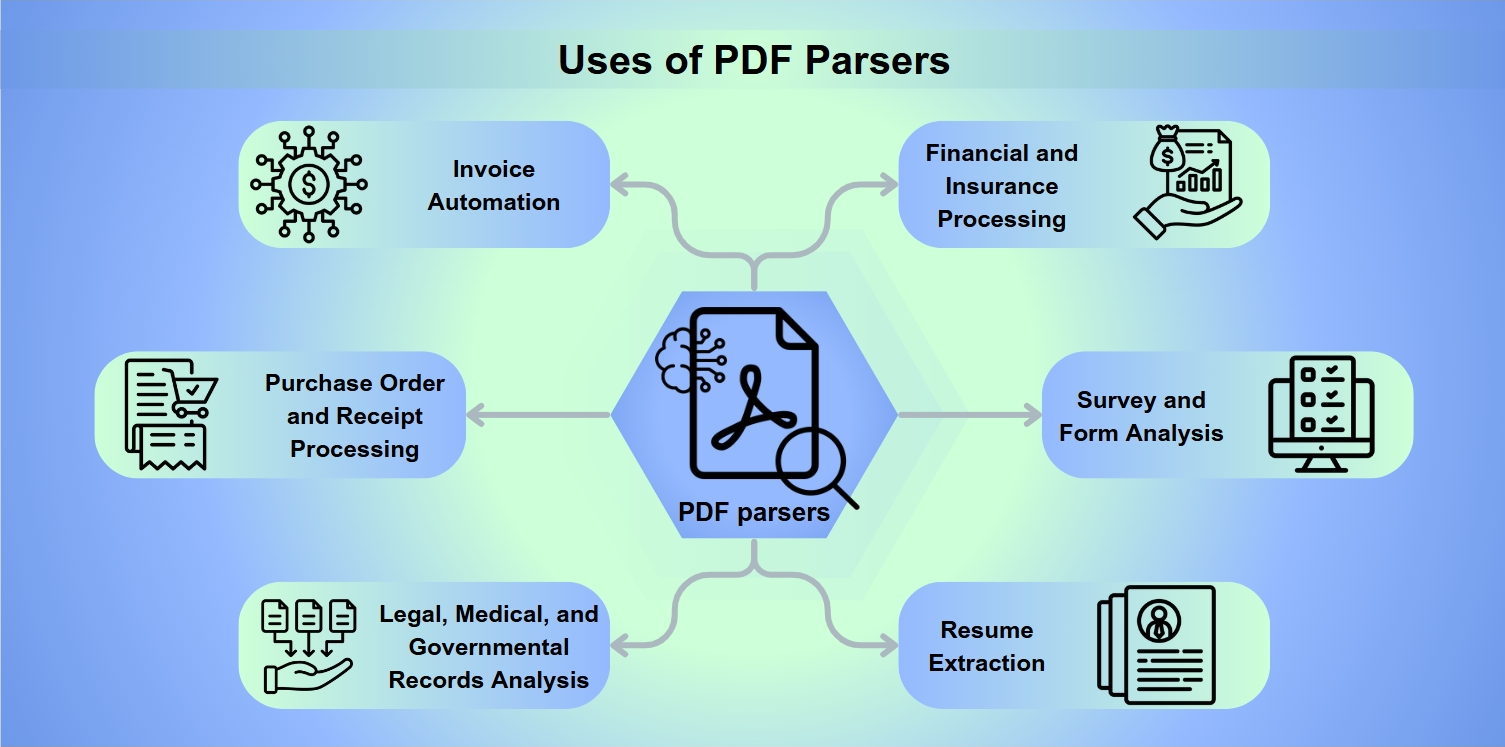
PDFパーサーの用途
PDFパーサーは、以下を含むさまざまなアプリケーションで不可欠なツールです:
-
請求書自動化:請求書の処理と支払いを効率化。
-
購入注文と領収書処理:払い戻しと返金を促進。
-
法律、医療、政府記録の分析:分析のための詳細なデータ抽出を可能に。
-
金融および保険処理:リスク評価とバランスシート分析。
-
調査およびフォーム分析:フォームの回答を収集し解釈。
-
履歴書抽出:採用担当者が候補者を絞り込むのを支援。
異なるパース手法の比較
データパース手法は時間とともに大きく進化しました。従来のデータキャプチャアプローチは、特定のパターンをテキストから抽出するために正規表現(regex)に依存することが多いです。強力ですが、regexは複雑になり、複雑なパースタスクのメンテナンスが難しくなることがあります。もう一つの一般的な技術は文字列操作で、区切り文字や特定の文字に基づいてテキストを分割し処理します。これらの手法は特定のシナリオでは依然として有用ですが、非構造的または不一致なデータ形式には苦労することがあります。
PDFパースの分野は、各々に独自の長所と短所を持つさまざまな手法によってサポートされています:
-
オンラインPDFコンバーター/パーサー:ZamzarやSmallpdfなどは、便利さとスピードを提供しますが、機能が制限されており、潜在的に安全性に欠けることがあります。
-
Adobe Acrobat:構造とフォーマットを保持しますが、変換後に手動調整が必要な場合があります。
-
コピー&ペースト:完全な制御を提供しますが、手間がかかりエラーが発生しやすいです。
-
自動化プラットフォーム:AnyParserのような現代のパース技術は、機械学習や自然言語処理(NLP)を活用して、より複雑なデータ構造を処理します。
これらのAI駆動アプローチは、コンテキストや意味を理解できるため、非構造的なテキストやさまざまな形式のドキュメントをパースするのに特に効果的です。一部の高度なパーサーは、ディープラーニングモデルを利用して、以前に見たことのないドキュメントレイアウトからも高い精度で関連情報を特定し抽出します。
PDFパースを実行する方法:PDFメタデータを抽出するための最高の無料PDFパーサー
PDFメタデータの理解
PDFメタデータには、文書のタイトル、著者、作成日、キーワードなど、文書に関する重要な情報が含まれています。このメタデータを効率的に抽出することは、大規模なPDFファイルコレクションを整理、検索、管理するために不可欠です。強力なPDFパーサーはこのプロセスを効率化し、時間を節約し、ワークフローの生産性を向上させます。
トップPDFパーサーの主な機能
最高の無料PDFパーサーは、精度、速度、柔軟性の組み合わせを提供します。スキャンされた文書や複雑なレイアウトのPDF形式を扱うことができる必要があります。基本的なメタデータだけでなく、カスタムフィールドや隠れた情報を抽出できるパーサーを探してください。さらに、トップクラスのパーサーは、バッチ処理や他のソフトウェアシステムとの統合のためのPDFデータ抽出ツールのオプションを提供することがよくあります。
AnyParserの機能
CambioMLによって開発されたAnyParserは、その精度、プライバシー、設定可能性により特に注目に値します。AnyParserは、複数のファイル形式を処理できる能力、ユーザーフレンドリーなインターフェース、スケーラビリティにより、あらゆる規模の企業にとって優れた選択肢となります。さらに、そのAPIは既存のワークフローへのシームレスな統合を可能にし、全体的な文書管理の効率を向上させます。以下は、AnyParserがPDFパースにおいて優れた選択肢となる主な機能です:
-
精度:AnyParserは、元のレイアウトとフォーマットを維持しながら、テキスト、数字、記号を正確に抽出するように設計されています。高度な言語モデルを利用して文書理解と情報抽出を向上させ、従来のOCRモデルと比較して最大2倍の精度を誇ります。
-
プライバシー:オンプレミスとクラウドのデータパースの両方をサポートし、機密情報がプライベートで安全に保たれることを保証します。
-
設定可能性:ユーザーは特定のニーズに合わせて抽出ルールや出力形式をカスタマイズできます。
-
マルチソースサポート:AnyParserは、PDF、画像、チャートなど、さまざまなドキュメントタイプをサポートします。
-
構造化出力:抽出された情報は、Markdown、Excel、JSONなどの構造化形式に変換でき、さらなる処理と分析を促進します。
-
クラウドベースの展開オプション:AnyParser SDKは、クラウド、データセンター、またはプライベートに展開でき、柔軟性とスケーラビリティを提供します。
-
ユーザーフレンドリーなインターフェース:このツールは、複雑な文書パースタスクを数行のコードで実行できるシンプルなAPIを提供します。
-
高性能:最適化されたアルゴリズムにより、大量の文書を迅速に処理でき、一般的なLLM(大規模言語モデル)であるGPT4oよりも5倍速くなります。
-
コミュニティサポート:オープンソースプロジェクトとして、AnyParserは活発なコミュニティからの恩恵を受けており、貢献を歓迎します。
-
無料使用クォータ:AnyParserは、各アカウントに無料使用クォータを提供し、ユーザーが有料プランにコミットする前にツールの機能を試すことができます。
-
顧客フィードバック:ユーザーは、AnyParserの高い精度、プライバシーの保護、データ抽出の効率性を称賛しており、ケーススタディでは大幅な時間の節約とデータ品質の向上が示されています。
これらの利点により、AnyParserは文書パースと情報抽出のための貴重なPDFデータ抽出ツールとなり、特に高精度とセキュリティを必要とする企業ユーザーにとって重要です。技術の進歩とコミュニティの積極的な関与により、AnyParserは文書パースと情報抽出の分野でますます重要な役割を果たすことが期待されています。
PDFパーサーの技術的説明
PDFパースはウェブスクレイピングと概念的に共通していますが、HTMLの構造的階層が欠けています。ウェブ文書はアクセス可能なHTMLタグを通じてパースされますが、PDFは文字とピクセルのフラットな配列を提示し、データ抽出のためにより高度なアルゴリズムやライブラリを必要とします。
PDFパーサーとPython PDFパーサーの主な違い
PDFパーサーは、PDFファイルからデータを抽出するために特化したスタンドアロンツールまたはライブラリです。これらのパーサーは通常、ユーザーフレンドリーなインターフェースを提供し、最小限のコーディング知識を必要とします。一方、Python PDFパーサーは、Pythonスクリプトに統合されるモジュールやライブラリであり、柔軟性を提供しますが、プログラミングの専門知識が求められます。
開発者はパースプロセスを微調整し、高度なテキスト分析を実装し、PDFデータ抽出をより広範なPythonアプリケーションにシームレスに統合できます。PDFパーサーは、Python PDFパーサーよりもカスタマイズの面で制限がありますが、一般的なユースケースのための事前構築された機能を提供することが多く、広範なプログラミングなしで迅速な結果を必要とするユーザーに最適です。
AnyParserとVLMのデータパースの利点
-
高精度:AnyParserのVLMは、複雑な文書レイアウトでもデータ抽出の高忠実度を維持します。
-
スピード:変換速度でリードし、文書処理に必要な時間を短縮することで生産性を向上させます。
-
ユーザーフレンドリー:AnyParserはシンプルなインターフェースを提供し、すべてのレベルのユーザーにアクセス可能です。
-
多様性:PDFだけでなく、AnyParserは強力な画像からExcelへの変換ツールとしても機能し、多様な文書タイプをサポートします。
結論
PDFパースは単なる技術的プロセス以上のものであり、企業がデータを扱う方法を変革するための入り口です。課題があるにもかかわらず、ソフトウェアソリューションの進化により、これまで以上にアクセスしやすくなりました。請求書処理や複雑なデータ分析に取り組んでいる場合、適切なPDFパーサーを選択することが重要です。正確性、セキュリティ、効率の完璧なバランスを提供するツールを見つけることが、データ駆動型の取り組みを強化する鍵です。
今すぐ無料トライアルを開始
文書処理を革命化する準備はできましたか?クレジットカード不要でAnyParserを無料で試してみてください。https://www.cambioml.com/sandboxで、各文書につき最大10ページ、最大ファイルサイズ10MBを処理できます。AnyParserのPDFパーサーが、非構造的データと文書抽出へのアプローチをどのように変革できるかを直接体験してください。この機会を逃さず、最先端のAI技術でデータ分析能力を向上させ、ワークフローを効率化しましょう。