今日のデータ駆動型の世界では、複雑な文書をPDFからCSV形式に変換することは、多くの専門家にとって重要な作業です。銀行明細書、医療報告書、またはPDF形式の出荷注文に悩まされている場合、効率的な解決策を求めていることでしょう。
ここで登場するのがビジョン言語モデル(VLM)です。これは、従来のOCR手法を超えた最先端の技術です。視覚的および文脈的理解を活用することで、VLMは複雑で構造化された文書を機械可読形式に変換するための強力なツールを提供します。
このガイドでは、VLMを活用してPDFをCSVまたはExcelファイルに変換するプロセスを説明し、ワークフローを効率化し、貴重なデータインサイトを解放します。AnyParserを使用すれば、数回のクリックでPDFをCSV、PDFをExcel、さらにはWordをCSVに簡単に変換できます。
PDFからCSVへの変換の強いニーズと従来のOCRモデルの限界
PDFからCSVへの変換の需要の高まり
今日のデータ駆動型の世界では、PDFをCSVに変換する必要性がますます重要になっています。企業や個人は、静的なPDF文書を動的で分析可能なスプレッドシートに変換する効率的な方法を求めています。この変換プロセスは、銀行明細書、医療報告書、出荷注文など、さまざまな文書から貴重な情報を抽出するために不可欠です。WordをExcelに変換したり、PDFからCSVへの変換ツールを使用したりすることで、データ管理と分析プロセスを大幅に効率化できます。
従来のOCR技術の短所
従来の光学文字認識(OCR)モデルは、テキスト抽出に長い間使用されてきましたが、複雑な文書を扱う際にはしばしば限界があります。これらの制限は、複雑なPDFをGoogle Sheetsや他のスプレッドシート形式に変換しようとする際に明らかになります。OCRシステムは以下の点で苦労します:
- 低品質のスキャンや画像を正確に解釈すること
- 複数列のレイアウトやテーブルを処理すること
- 多様なフォントや言語を認識すること
- 元の文書構造を維持すること
これらの課題は、PDFからCSVへの変換プロセスをシームレスに処理し、元の文書の内容と文脈を保持できるより高度なソリューションの必要性を浮き彫りにしています。
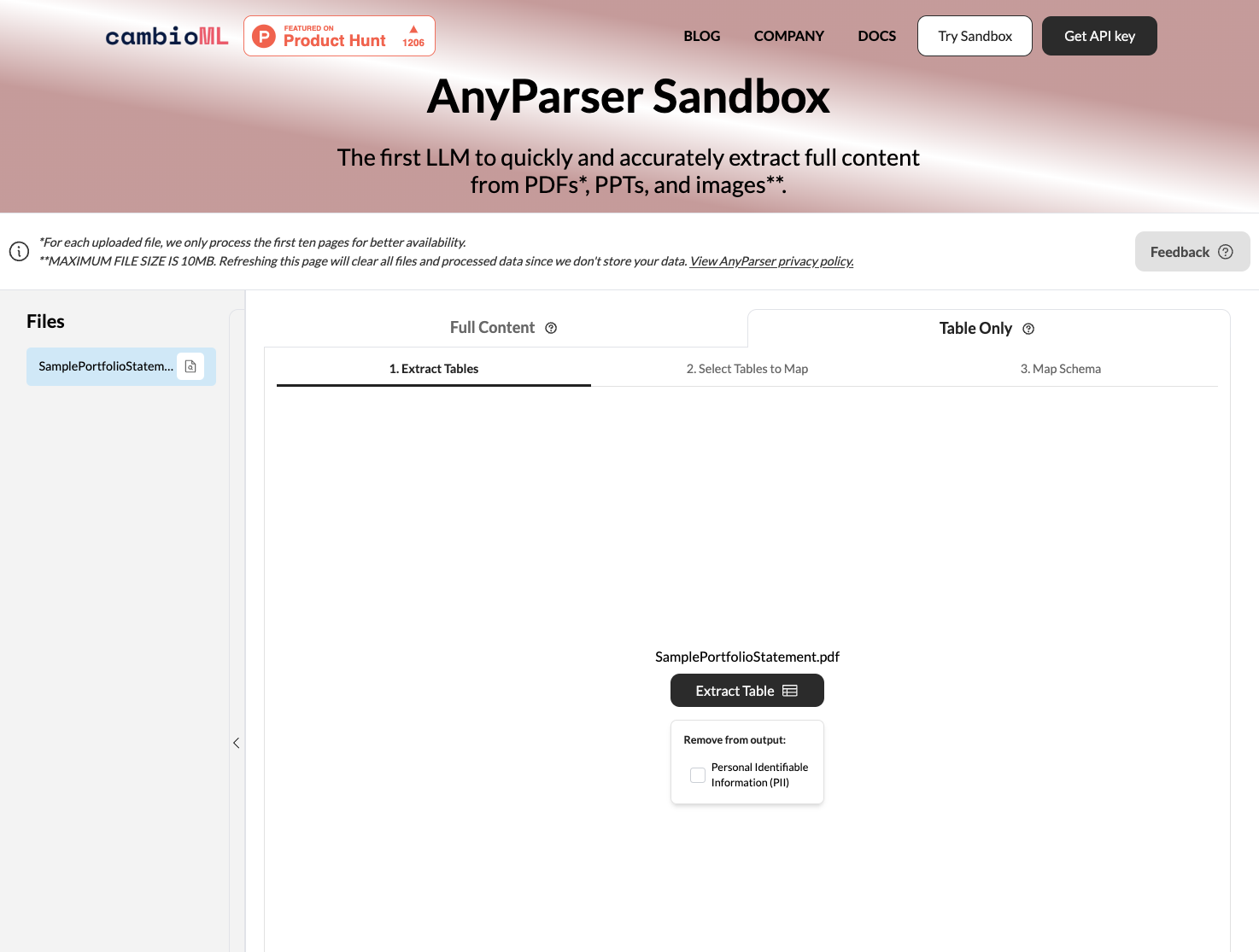
AnyParserを使用したPDF文書の変換手順
AnyParserは、複雑なPDF文書からデータを正確に抽出するために高度なビジョン言語モデルを活用する強力なPDFからCSVへの変換ツールです。以下は、AnyParserを使用してPDFファイルを変換する基本的な手順です:
-
PDFまたはWordをアップロードします。PDF文書をAnyParserのウェブインターフェースにドラッグ&ドロップするか、PDFのスクリーンショットをAnyParserのUIに貼り付けます。
-
「テーブルのみ」を選択し、「抽出」をクリックします。AnyParserのAPIエンジンはPDF内のテーブルを自動的に検出し、高精度で抽出します。抽出されたデータは.csvファイルに保存され、ワンクリックでダウンロードまたはGoogle Sheetsにエクスポートできます。
-
プレビューと比較を行います。抽出されたデータが期待通りであることを確認するために、プレビューで確認します。AnyParserの初期抽出をプレビューし、UI上で並べて比較します。
-
CSVまたはExcelにエクスポートします。抽出に満足したら、.csvファイルをダウンロードして、自分のアプリケーションやシステムでデータを使用します。抽出されたデータは、さらなる分析のためにスプレッドシートやデータベースに簡単にインポートできます。
これらの簡単な手順に従い、ビジョン言語モデルの力を活用することで、AnyParserは最も複雑なPDF文書を構造化された編集可能なCSVファイルに効率的に変換できるようにします。
ステップバイステップのビデオデモをチェックしてください!
PDFからCSV/Excelへの変換におけるVLMの実世界の応用
ビジョン言語モデル(VLM)は、PDFをCSVおよびExcel形式に変換する方法を革新しており、さまざまな業界に強力なソリューションを提供しています。これらの高度なモデルを活用することで、複雑な文書を構造化された機械可読データに効率的に変換できます。
財務文書処理
銀行業界では、VLMが銀行明細書のPDFをCSVに変換するのに優れています。これらのモデルは、複雑なレイアウトや複数の通貨を含む文書からも、取引詳細、口座番号、残高情報を正確に抽出できます。この能力は、財務分析や調整プロセスを効率化します。
医療記録管理
医療専門家にとって、VLMは医療報告書をWordからExcelに変換するための貴重なツールを提供します。複雑な医療用語を正確に解釈し、検査結果の構造を保持することで、VLMは包括的な患者データベースの作成を促進します。この変換により、トレンド分析が容易になり、患者ケアが改善されます。
ロジスティクスとサプライチェーンの最適化
物流業界では、VLMがPDFからGoogle Sheetsに出荷注文を変換する際に優れた性能を発揮します。これらのモデルは、配達先住所、アイテムの説明、追跡番号などの重要な情報を抽出し、表形式のデータの整合性を維持します。この変換により、効率的な在庫管理とルート最適化が可能になります。
VLMを搭載したPDFからCSVへの変換ツールを利用することで、さまざまな分野でデータ処理の効率を大幅に向上させることができます。これらの高度なモデルは、多言語文書、複雑なレイアウト、さらには低品質のスキャンを扱う際に比類のない精度を提供し、現代のビジネスにとって不可欠なツールとなっています。
OCRの課題を克服するためのビジョン言語モデルの仕組み
ビジョン言語モデル(VLM)は、PDFをCSVに変換し、複雑な文書を機械可読形式に変換する方法を革新しています。従来のOCRとは異なり、VLMは視覚的および言語的理解の両方を活用して、文書変換の最も難しい側面に取り組みます。
複雑なレイアウトの解釈
VLMは、複雑な文書構造を解読するのに優れており、WordをExcelに変換したり、さまざまな形式の銀行明細書を処理したりするのに最適です。テキスト要素間の空間的関係を分析することで、VLMはテーブルを正確に再構築し、レイアウトの整合性を保持できます。たとえば、VLMは異なる列数と行数を持つ複数のテーブルを含む請求書のPDFを正しく解釈できますが、従来のOCRでは行と列が混乱してしまいます。
文脈的理解
VLMの主要な利点の1つは、文書内容の意味を把握する能力です。この文脈的な認識により、PDFからCSVへの変換時に、特に医療のCBC報告書や物流の出荷注文など、特定のドメインの文書の抽出がより正確になります。たとえば、VLMは、内容に基づいて医療報告書を専門分野ごとに正しく分類し、「白血球」数が「白血球(WBC)」数であることを理解することができます!
多言語対応
VLMは、単一の文書内で複数のスクリプトや言語をシームレスに処理することで、言語の壁を打破します。これにより、多様な文書タイプを扱う国際的なビジネスにとって特に便利です。たとえば、VLMは英語とフランス語の両方のテキストを含むPDFからデータを抽出できます。
ノイズ除去
低品質のスキャンや画像は、従来のOCRシステムにとって課題となることがよくあります。しかし、VLMは効果的にノイズを除去し、関連情報に焦点を当てることができるため、文書をGoogle Sheetsや他の形式に変換する際に高品質な出力を確保します。たとえば、VLMはぼやけたまたは色あせたPDF文書から正確にデータを抽出できます。
VLMを使用したPDFからCSVへの変換に関するFAQ
VLMベースの変換は従来のOCRとどのように異なりますか?
ビジョン言語モデル(VLM)は、PDFをCSVまたはExcelに変換する際に、従来のOCRに比べて大きな利点を提供します。OCRとは異なり、VLMは複雑なレイアウトを正確に解釈し、文脈を理解し、複数の言語をシームレスに処理できます。これにより、銀行明細書、医療のCBC報告書、物流の出荷注文を機械可読形式に変換するのに最適です。
VLM変換に最適な文書の種類は何ですか?
VLMは、テーブル、チャート、混合コンテンツを含む構造化された文書の変換に優れています。特に財務諸表、医療報告書、出荷マニフェストに効果的です。VLMを搭載したPDFからCSVへの変換ツールは、テーブルの整合性を維持し、低品質のスキャンや複雑な多言語文書からもデータを抽出できます。
VLMベースの変換は手動データ入力と比べてどれくらい正確ですか?
AnyParserのようなVLMベースのソリューションは、手動データ入力や従来のOCRと比較して、正確性を大幅に向上させることができます。視覚的および文脈的理解を活用することで、これらのツールはWordをExcelに変換したり、PDFをGoogle Sheetsに変換したりする際のエラーを最大50%削減できます。この正確性は、財務、医療、物流のアプリケーションにおけるデータ整合性を維持するために重要です。
VLMはPDF以外の異なるファイル形式も処理できますか?
はい、高度なVLMベースのツールはさまざまなファイル形式を処理できます。PDFからCSVへの変換が一般的ですが、これらのモデルは画像、Word文書、PowerPointプレゼンテーション、スキャン文書からもデータを抽出できます。この柔軟性により、VLMは業界全体の包括的な文書処理ニーズに対する強力なソリューションとなります。
結論
ビジョン言語モデルを活用してPDFからCSVへの変換を行う際には、成功の鍵はしっかりとしたアプローチにあります。堅牢な前処理、正確な文書分類、徹底的な後処理を実施することで、データ抽出ニーズに対してVLMの全潜在能力を引き出すことができます。複雑な銀行明細書、精巧な医療報告書、詳細な出荷注文を扱う際に、VLMは非構造化データを実用的なインサイトに変換するための強力なソリューションを提供します。この最先端の技術を活用して、ワークフローを効率化し、データの正確性を向上させ、文書処理の新たな可能性を開きましょう。VLMがあれば、最も難しいPDF変換タスクにも効率的かつ効果的に取り組むことができます。
行動を促す
これらのインサイトを実行に移しましょう。AnyParserのチームのようなビジョン言語モデルの専門家に連絡して、以下を検討してください:
- PDFをCSVに変換するためにAnyParserを無料で試す:https://www.cambioml.com/sandbox
- コード不要の体験で大量のPDFをExcelに変換したい場合は、https://www.energent.ai をご覧ください。
- VLMがデータ抽出ワークフローを改善する方法について無料相談を受ける
ビジョン言語モデルの全力を引き出すには、変換の専門家の経験とベストプラクティスを活用することが必要です。業界のリーダーとつながり、より自動化され、正確で洞察に満ちたデータ抽出プロセスへの移行を加速させる次のステップを踏み出しましょう。