今日のデータ駆動型の世界では、PDFファイルをGoogle Sheetsのような編集可能な形式に変換する必要が頻繁に発生します。財務諸表、医療記録、物流文書など、効率的な変換ソリューションの必要性は非常に重要です。
従来の方法では不十分で、貴重な時間を無駄にすることになります。ここで登場するのがVision Language Models(VLMs)で、ドキュメント変換の取り扱い方を革命的に変えています。
このガイドでは、VLMの力を活用してPDFをGoogle Sheetsにシームレスに変換する最先端のツール、AnyParserの使い方を説明します。この技術の実用的な応用を発見し、従来のOCR手法に対する利点を探り、よくある質問への回答を見つけましょう。データ管理プロセスにおける新たな効率性を解き放つ準備をしてください。
PDFをGoogle Sheetsに変換する必要性の高まり
PDFをGoogle Sheetsに変換する需要は高まっており、企業や個人がデータの完全な潜在能力を引き出そうとしています。この変換により、動的なデータ分析と管理が可能になり、業界全体でプロセスが効率化されます。
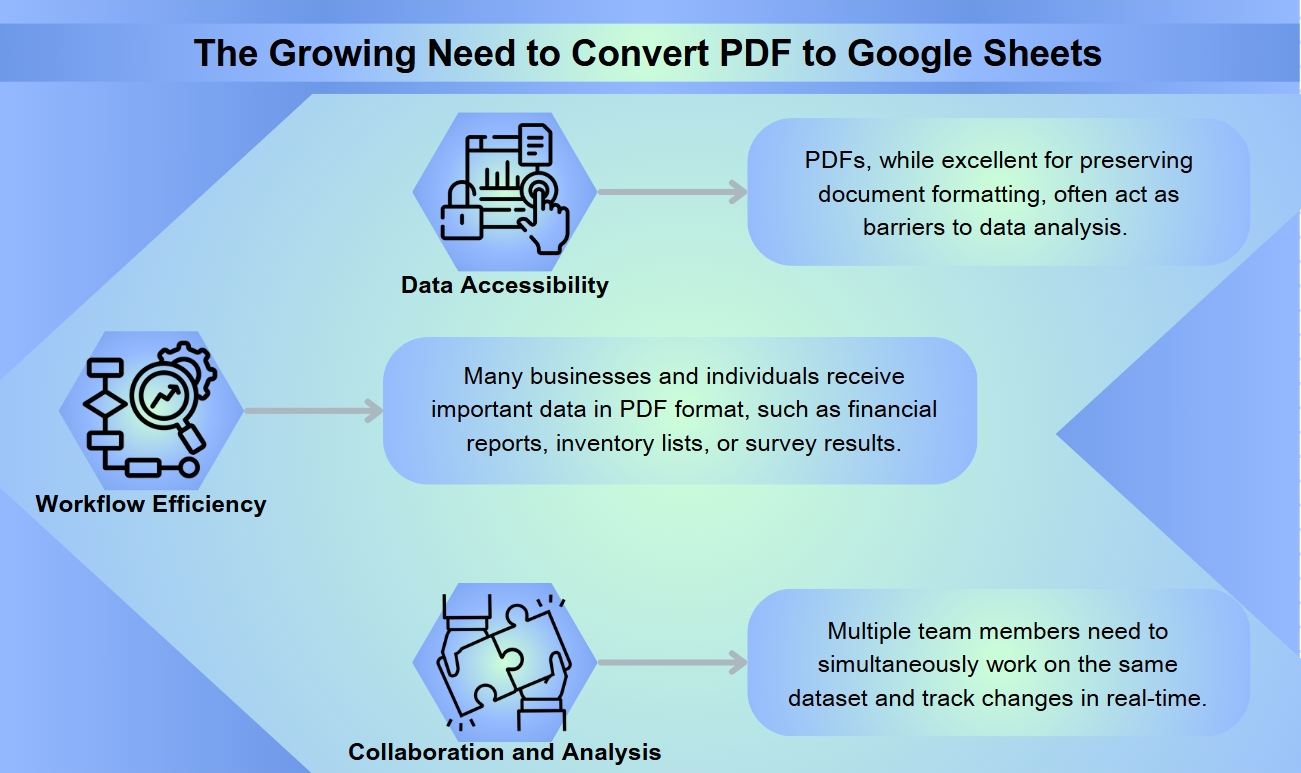
データアクセスの課題を克服する
今日のデータ駆動型の世界では、情報に簡単にアクセスし、操作する能力が重要です。PDFは文書のフォーマットを保持するのに優れていますが、データ分析の障壁となることがよくあります。PDFをGoogle Sheetsに変換することで、ユーザーは以前は静的だった情報を並べ替えたり、フィルタリングしたり、計算を行ったりすることができるようになります。
ワークフローの効率化
多くの企業や個人は、財務報告書、在庫リスト、調査結果など、重要なデータをPDF形式で受け取ります。このデータを手動でスプレッドシートに再入力する必要があるのは時間がかかり、エラーが発生しやすいです。PDFをGoogle Sheetsに変換することで、ユーザーはこのプロセスを自動化し、無数の時間を節約し、データの正確性を確保できます。
コラボレーションと分析の強化
Google Sheetsは、PDFでは実現できない強力なコラボレーション機能を提供します。変換後、複数のチームメンバーが同じデータセットで同時に作業し、コメントを追加し、リアルタイムで変更を追跡できます。この静的な文書から動的なスプレッドシートへの変換は、組織がより深い洞察を得て、データ駆動型の意思決定をより効率的に行うことを可能にします。
PDFをシートに変換するための従来の方法
手動データ入力
PDFファイルをGoogle Sheetsに変換することは、従来は労力を要するプロセスでした。多くのユーザーはデータを手動で再入力することに頼り、この方法は時間がかかり、エラーが発生しやすいです。このアプローチは、大量のデータや複雑なPDFレイアウトを扱う際に特に困難になります。
コピー&ペースト技術
もう一つの一般的な方法は、PDFから内容をコピーしてGoogle Sheetsに貼り付けることです。これは手動入力よりも早い場合がありますが、フォーマットの問題が発生しがちです。テーブルの構造が失われたり、テキストが正しく整列しなかったりするため、広範なクリーンアップが必要になります。
OCRソフトウェア
光学文字認識(OCR)ソフトウェアは、多くの人にとって頼りにされてきた解決策です。これらのツールはPDF内のテキストを認識し、編集可能な形式に変換しようとします。しかし、OCR技術は手書きのテキスト、複雑なレイアウト、または低品質のスキャンに苦労することがあります。OCRベースの変換の精度は大きく異なることがあり、手動でのレビューと修正が必要になることがよくあります。一般的な問題には以下が含まれます:
- 低品質のスキャンや画像を正確に解釈できない
- 複数列のレイアウトやテーブルを扱うのが難しい
- 多様なフォントや言語を認識するのが難しい
- 元の文書構造を維持するのが不一致になる
サードパーティのコンバータ
さまざまなサードパーティのツールやオンラインコンバータがPDFからGoogle Sheetsへの変換を提供しています。一部は良好な結果を提供しますが、複雑なPDFや大きなファイルを扱う際には制限があります。また、ユーザーはこれらのプラットフォームに機密文書をアップロードする際にプライバシーの懸念に直面することもあります。
AnyParserを使用してPDFをGoogle Sheetsに変換する手順
AnyParserは、高度なVLMによって駆動され、PDFをGoogle Sheetsに変換するための正確で効率的なソリューションを提供します。AnyParserの使い方は以下の通りです:
-
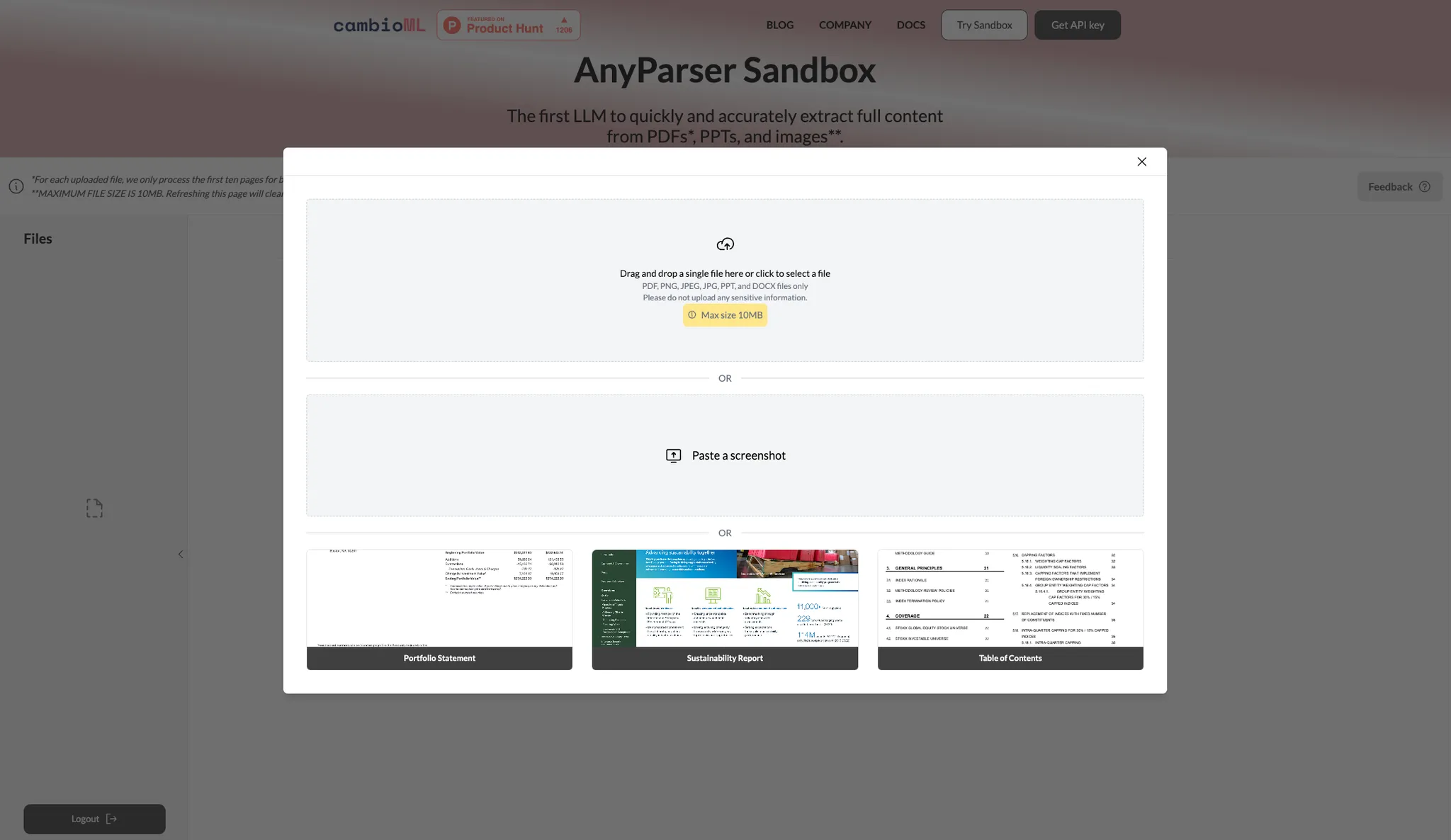
PDFまたはWord文書をアップロードする PDFをAnyParserのウェブインターフェースにドラッグ&ドロップするか、PDFのスクリーンショットを貼り付けます。
-
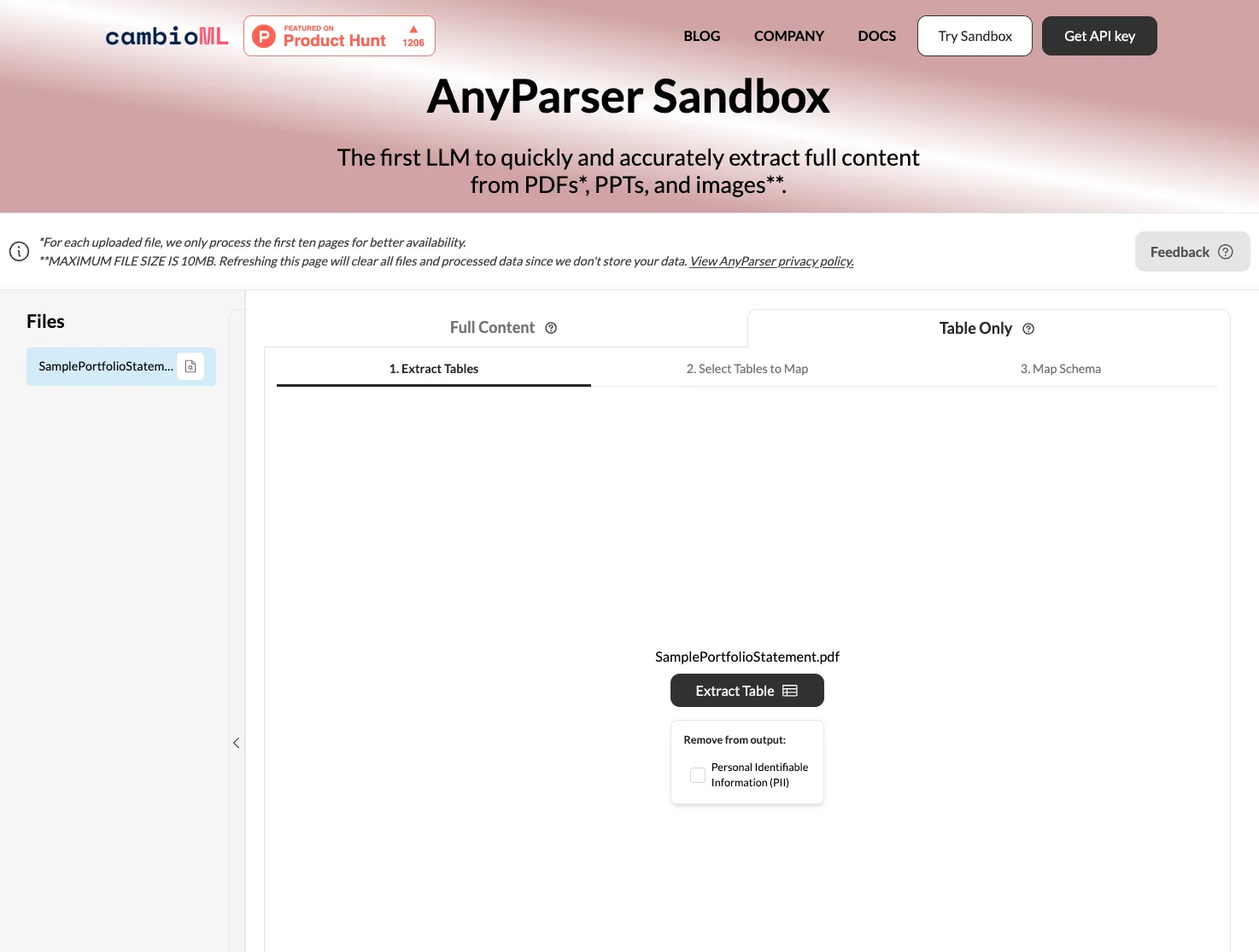
「テーブルのみ」を選択し、「抽出」をクリックする AnyParserのAPIエンジンはPDF内のテーブルを自動的に検出し、高精度で抽出します。データはその後、直接Google Sheetsにエクスポートする準備が整います。
-
プレビューと比較 抽出されたデータを確認して、期待に応えているかを確認します。AnyParserでは、初期抽出をプレビューし、並べて比較することができます。
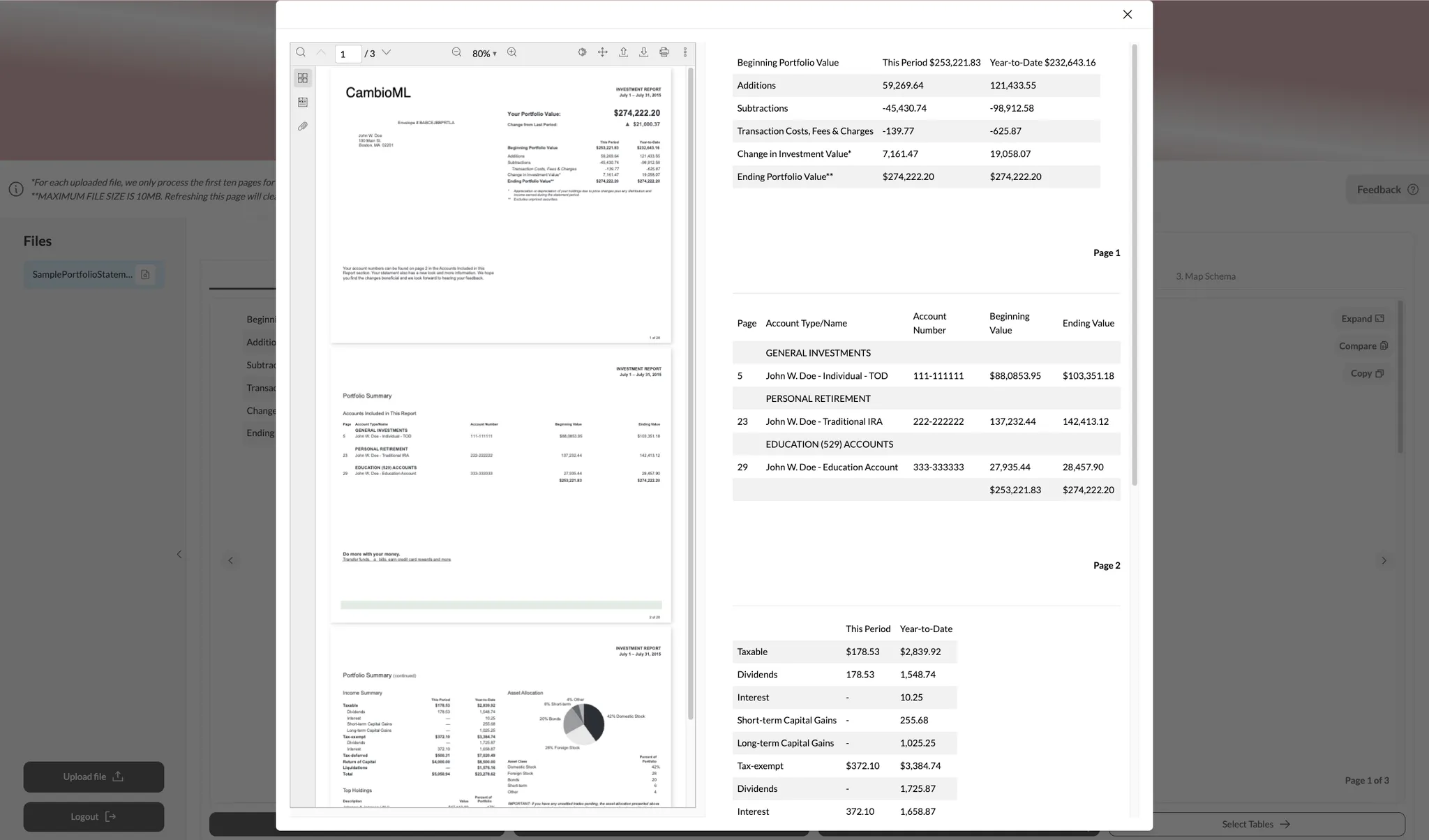
-
Google Sheetsにエクスポート 満足したら、データを直接Google Sheetsにエクスポートして、さらなる分析やワークフローへの統合を行います。
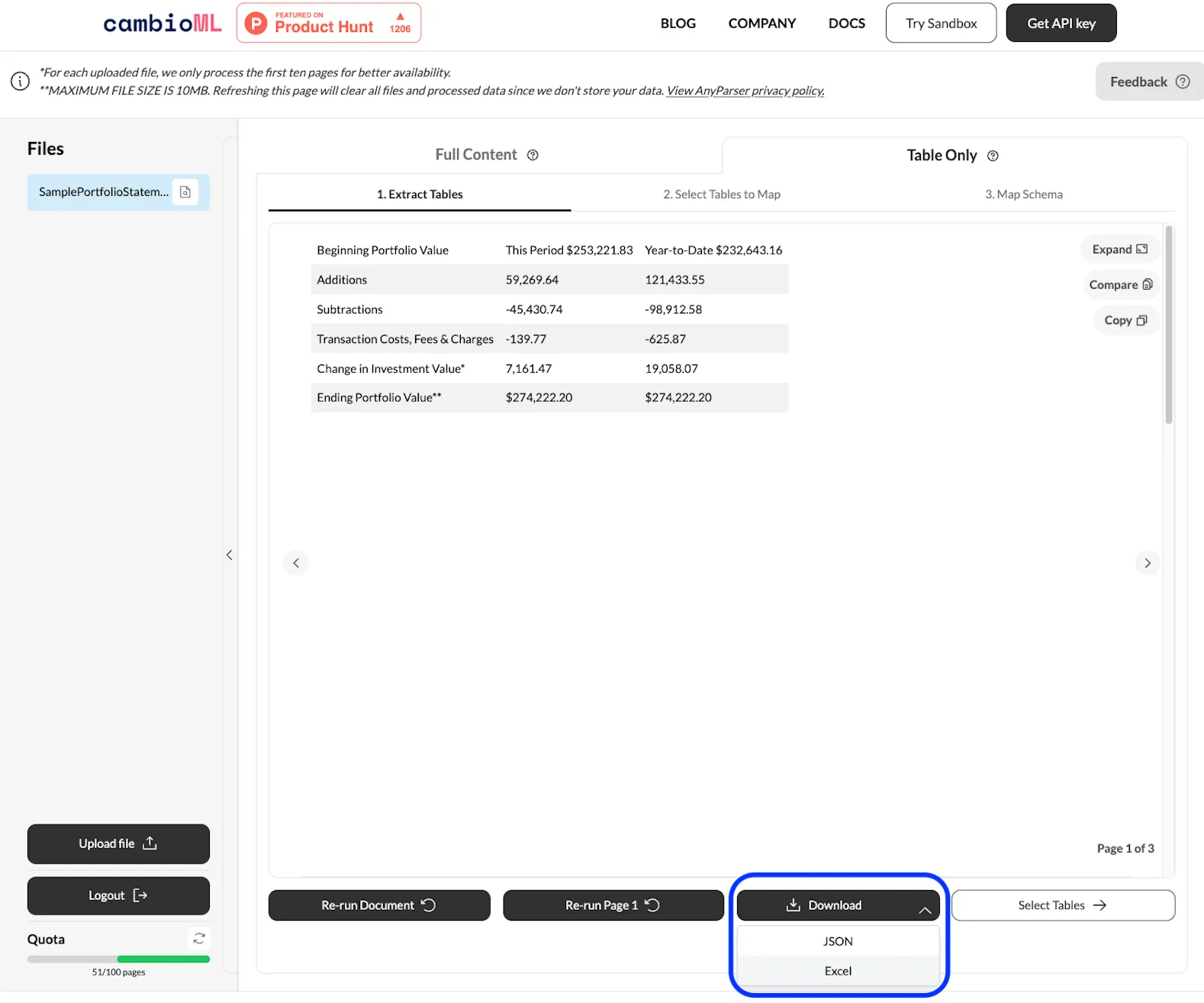
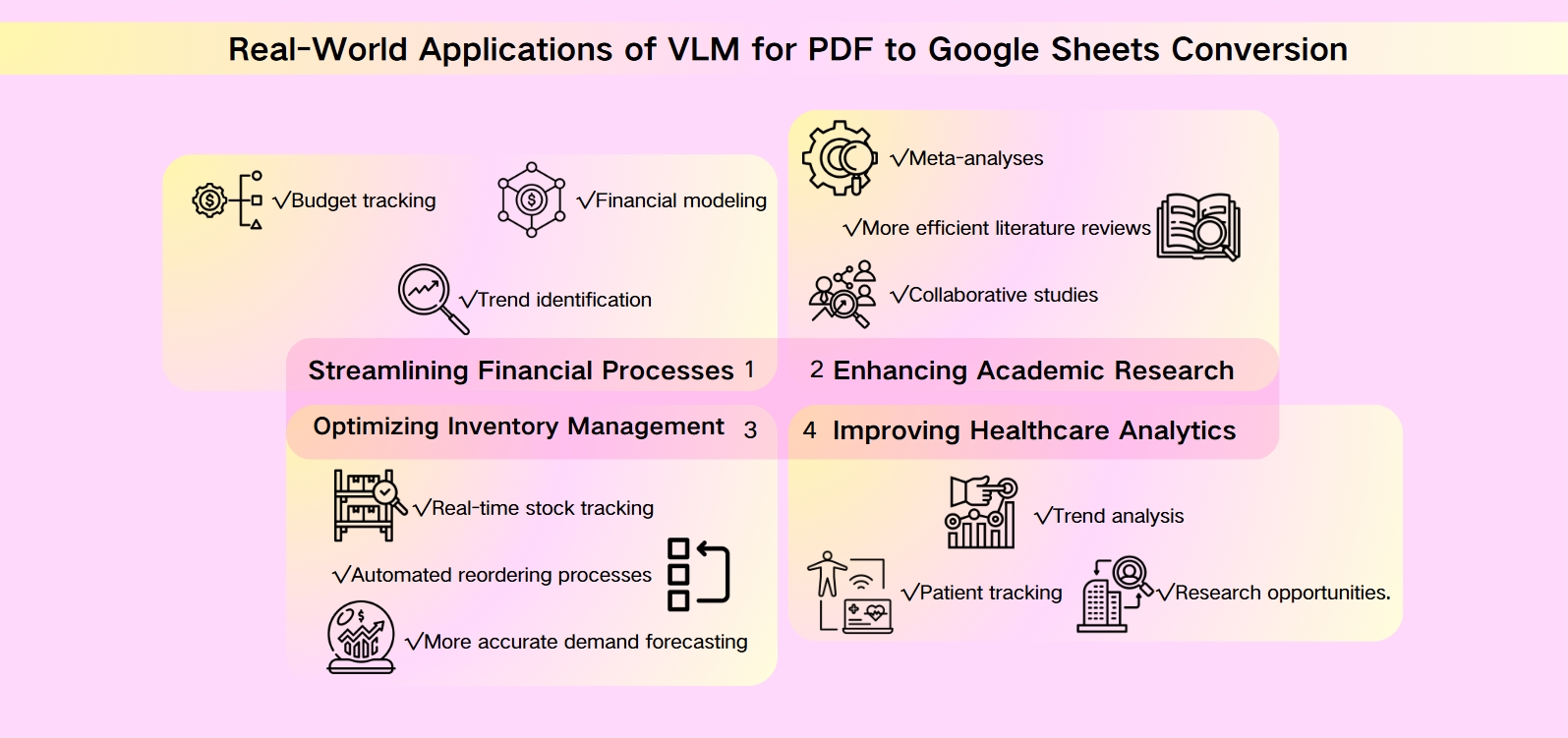
PDFからGoogle Sheetsへの変換におけるVLMの実世界での応用
財務プロセスの効率化
Vision Language Models(VLMs)は、企業が財務データを扱う方法を革命的に変えています。複雑なPDFの財務諸表をGoogle Sheetsに変換することで、企業はデータ入力と分析を自動化できます。この変革により、リアルタイムの財務モデリング、予算追跡、トレンドの特定が可能になり、意思決定者に最新の洞察を提供します。
学術研究の強化
研究者や学生は、VLMを活用したPDFからGoogle Sheetsへの変換から大きな恩恵を受けています。学術論文からの大規模なデータセットは、PDF形式に閉じ込められていることが多く、操作可能なスプレッドシートに簡単に変換できます。この能力により、メタ分析、共同研究、より効率的な文献レビューが促進され、科学的発見のペースが加速します。
在庫管理の最適化
小売業者や製造業者は、PDFの在庫報告書を動的なGoogle Sheetsに変換するためにVLMを活用しています。この移行により、リアルタイムの在庫追跡、自動再注文プロセス、より正確な需要予測が可能になります。このデータを他のビジネスシステムと統合することで、企業はサプライチェーンを最適化し、保管コストを削減できます。
医療分析の改善
医療分野では、VLMが患者データ管理を変革しています。PDFの医療記録をGoogle Sheetsに変換することで、患者の追跡、トレンド分析、研究機会が向上します。この応用は、患者ケアを改善するだけでなく、より広範な公衆衛生の取り組みや疫学研究にも寄与します。
PDFからシートへの変換におけるOCRの課題を克服するためのVision Language Modelsの利点
精度と文脈理解の向上
Vision Language Models(VLMs)は、PDFからシートへの変換において従来の光学文字認識(OCR)手法を超える重要な進歩を提供します。VLMは複雑なレイアウトを解釈し、手書きのテキストを解読し、文書内の文脈を理解するのに優れています。この高度な能力により、特に複雑なデザインや画像品質が悪いPDFからのデータ抽出がより正確になります。
様々な文書タイプへの適応性
OCRが非標準フォーマットに苦労するのに対し、VLMは驚くべき柔軟性を示します。請求書や領収書から学術論文や財務報告書まで、さまざまな文書スタイルを効果的に処理できます。この適応性により、複数の専門ツールを必要とせず、さまざまなPDFタイプの変換プロセスが簡素化されます。
インテリジェントなデータ構造化
VLMは単なるテキスト認識を超えて、文書の論理構造を理解します。この知性により、Google Sheetsに変換する際にデータをよりスマートに整理できます。テーブル、チャート、グループ化された情報は、元の文書の意図されたレイアウトやデータポイント間の関係を維持しながら、より正確に保存される可能性が高くなります。
継続的な学習と改善
静的なOCRシステムとは異なり、VLMは継続的な機械学習の進展から利益を得ます。新しいデータで微調整でき、パフォーマンスを継続的に改善し、進化する文書スタイルに適応します。これにより、PDFからシートへの変換プロセスは、時間とともにますます効率的で正確になります。
VLMは従来のOCRに対していくつかの利点を提供します:
- 複雑なレイアウトの解釈: VLMは複雑な文書構造を正確に解読し、レイアウトの整合性を保持します。
- 文脈理解: VLMはコンテンツの意味を把握し、より正確な抽出を可能にします。
- 多言語対応: VLMは文書内の複数の言語をシームレスに処理します。
- ノイズ除去: VLMは低品質のスキャンや画像からのノイズをフィルタリングし、高品質なデータ抽出を確保します。
PDFをGoogle Sheetsに変換する際のFAQ
すべてのPDFをGoogle Sheetsに変換できますか?
ほとんどのPDFはGoogle Sheetsに変換できますが、成功率はPDFの構造と内容によります。テーブル、スプレッドシート、構造化データは通常、うまく変換されます。しかし、複雑なレイアウトや画像が多いPDFは課題を引き起こすことがあります。
変換プロセスの精度はどのくらいですか?
PDFからGoogle Sheetsへの変換の精度は、使用するツールやPDFの複雑さによって異なります。AnyParserで使用されるようなVision Language Models(VLM)は、特に複雑なレイアウトや多言語コンテンツに対して、従来のOCR手法よりも高い精度を提供します。
変換プロセス中に私のデータは安全ですか?
AnyParserのような信頼できるツールを使用する際、データのセキュリティは最優先事項です。しかし、使用する変換サービスのプライバシーポリシーを確認することは常に賢明です。無料の未確認のオンラインコンバータに機密情報をアップロードすることは避けてください。
変換プロセスにはどのくらいの時間がかかりますか?
変換時間はPDFのサイズ、複雑さ、および使用するツールによって異なります。単純な1ページのPDFは数秒で変換できる場合がありますが、大きくて複雑な文書は数分かかることがあります。VLMを活用したツールは、従来のOCR手法よりもファイルを迅速に処理することが多いです。
結論
結論として、PDFファイルをGoogle Sheetsに変換することは、多くの専門家や企業にとって不可欠なタスクとなっています。AnyParserのようなツールを通じてVision Language Modelsの力を活用することで、このプロセスを効率化し、PDF文書から貴重なデータを引き出すことができます。VLM技術が従来のOCR手法に対して提供する利点は明らかで、精度と柔軟性が向上します。これらの変換技術をワークフローに実装する際には、さまざまな応用や可能性を探求することを忘れないでください。この知識を手に入れたことで、PDFデータをGoogle Sheets内で実行可能な洞察に効率的に変換し、生産性と意思決定能力を向上させる準備が整いました。
行動を呼びかける
Vision Language Modelsの力を活用し、AnyParserを無料で試してPDFをGoogle Sheetsに変換してみてください。https://www.cambioml.com/sandboxで、VLMがデータ抽出ワークフローをどのように向上させるかについての無料相談を受けることができます。
AnyParserのチームのような業界のリーダーとつながることで、より自動化され、正確で洞察に富んだデータ抽出プロセスへの移行を加速できます。この最先端の技術を活用して、ワークフローを効率化し、ドキュメント処理における新たな可能性を解き放ちましょう。