 評価指標 from Ragas
評価指標 from Ragas
今日のデータ駆動型の環境において、金融サービスのような業界は、特に非構造化テキストとテーブルやチャートのような構造化データの両方を含む文書からの正確で効率的な情報抽出に大きく依存しています。従来の光学式文字認識(OCR)モデルは広く使用されていますが、複雑な文書形式を扱う際にはしばしば限界があり、高度なAIアプリケーションにおいて最適なパフォーマンスを発揮できません。このギャップを認識したCambioMLとEpsillaは、データ抽出タスクにおける精度とリコールを大幅に向上させることを約束する最先端の知識取得システムを導入しました。
はじめに:OCRの限界を克服する
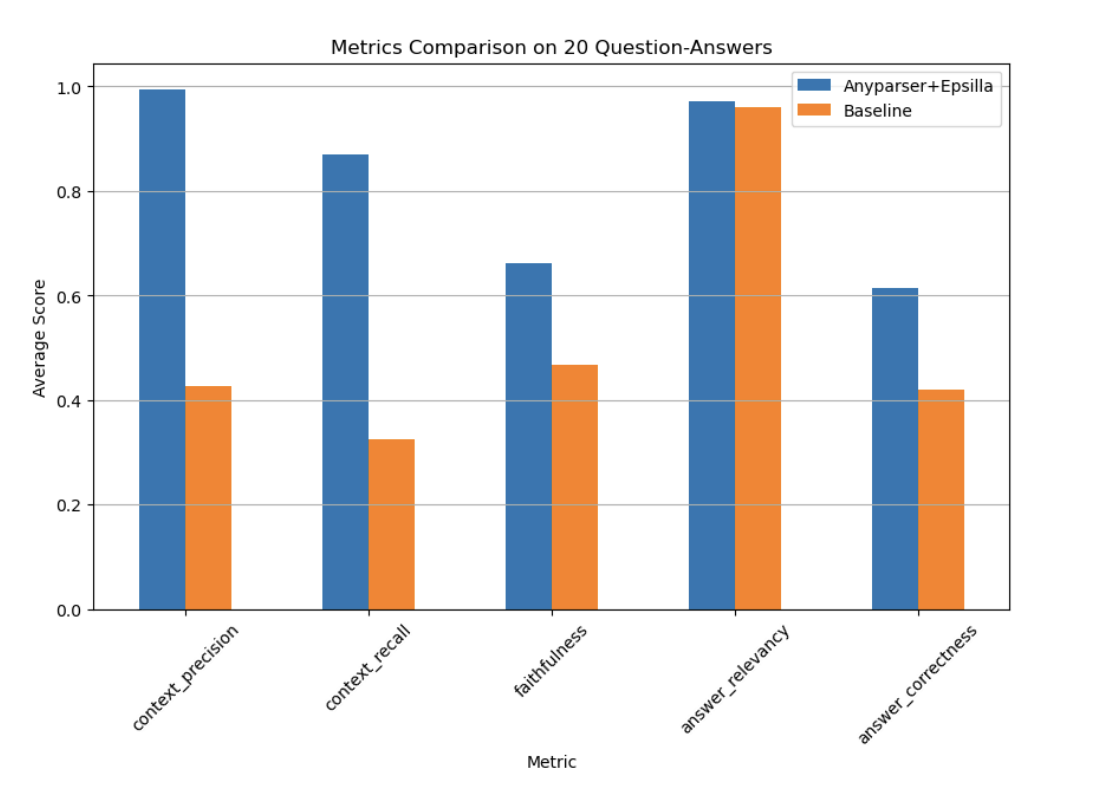
OCRベースのモデルは、テキストの検出には効果的ですが、レイアウト情報の抽出やテーブルやチャートからのデータの正確な取得には苦労します。これらの限界は、金融や医療のように精度が最重要である業界で特に顕著です。これらの課題に対処するために、CambioMLとEpsillaは、最先端のテーブル抽出モデルとリトリーバル拡張生成(RAG)技術を統合した新しいアプローチを開発しました。この新しいシステムは、従来のRAGシステムと比較して最大2倍の精度と2.5倍のリコールを達成し、文書の質問応答における新しい基準を設定しています。
AnyParser:テーブル抽出の革命
このブレークスルーの中心には、さまざまなデータソースから情報を抽出するのに優れた高度な視覚言語モデル(VLM)によって駆動されるAnyParserがあります。従来のモデルがOCRに大きく依存しているのとは異なり、AnyParserは視覚的およびテキストベースのエンコーダの組み合わせを使用して、文書から最も小さな詳細までをキャプチャし、重要なデータが見逃されないようにします。このアプローチは、精度が重要な金融および医療文書からの高解像度データの抽出に特に有益です。
Epsilla:柔軟なRAGプラットフォーム
AnyParserを補完するのがEpsillaで、さまざまなRAGパイプラインを最適化するために設計されたノーコードのRAG-as-a-Serviceプラットフォームです。Epsillaは、高度なチャンク化、インデックス作成、クエリの洗練技術を通じて知識取得プロセスを強化します。キーワードベースおよびセマンティック検索方法を統合することで、Epsillaは非常に正確で文脈に関連した結果を提供し、大規模言語モデル(LLM)アプリケーションに最適なソリューションとなっています。
実験と評価:実世界への影響
評価指標 from Ragas
AnyParserとEpsillaの効果を検証するために、AppleやMetaのような企業の10-K金融文書でシステムがテストされました。結果は印象的で、システムは文脈の精度、リコール、忠実性、回答の正確性を含むすべての主要評価指標で著しく高いパフォーマンスを示しました。場合によっては、システムは従来のRAGシステムを最大2.7倍も上回り、複雑なデータ抽出タスクの処理における優位性を強調しました。
一般的な使用ケースと主な利点
-
精度:構造化データと非構造化データの両方を使用可能な形式に変換する高精度。
-
プライバシー:顧客のデータセンター内でシステムを展開する能力により、完全なデータセキュリティを確保。
-
スケーラビリティ:大量の文書を迅速に処理し、より迅速な意思決定を可能にします。
結論:知識取得の新時代
AnyParserとEpsillaの導入は、知識取得技術における重要な進展を示しています。高度な抽出モデルと堅牢なRAGインフラストラクチャを組み合わせることで、この統合ソリューションは精度と効率を向上させるだけでなく、現代の企業が求める柔軟性とプライバシーも提供します。技術が進化し続ける中で、このシステムの応用と利点は広範で有望であり、正確なデータ抽出に依存する業界にとってゲームチェンジャーとなるでしょう。
詳細なホワイトペーパーについては、こちらのリンクをご覧ください。