複雑なPDFをMarkdownに変換することは難しい場合があります。PDFからテキストを抽出するためのオープンソースライブラリは多数存在しますが、表やチャートのような複雑な要素を含むPDFの場合、結果はしばしば期待外れです。GPTやClaudeのような人気の大規模言語モデルはこれらのタスクを処理できますが、遅くなることがあり、時には不正確な出力を生成することもあります。従来のOCRツールは、よりシンプルな文書には効果的ですが、元のコンテンツの正確な構造と意味を維持するのに苦労することがよくあります。一方、ビジョン言語モデルは時折幻覚を起こし、誤ったパース結果をもたらすことがあります。このブログでは、「パース」とは何かを説明し、複数のモデルを使用した比較分析の結果を詳細に説明します。
パースとは何か?
PDFパースの文脈において、「パース」とは、PDFファイルから特定のデータを抽出するプロセスを指し、PDFパーサーと呼ばれる専門のソフトウェアを使用します。PDFパーサーはPDF文書の内容を分析し、テキスト、画像、フォント、レイアウト、さらにはメタデータなどの要素を特定します。抽出されたデータは、XML、JSON、Excel/CSVなどの異なる形式に整理され、データ分析、記録保持、ワークフローの自動化など、さまざまな目的で使用されます。
パースとは何かを理解することは、特に異なるPDFからMarkdownへの変換ツールを比較する際に、パースソリューションの効果を評価するために重要です。PDFパーサーは単なるテキスト抽出以上のものであり、文書の意味構造を認識し、維持することが求められます。
これらのパースソリューションの品質をどのように測定するか?
私たちは、異なるモデルのパフォーマンスを評価するために、単語レベルの指標を定義しました。主な要素として以下の点に焦点を当てています:
-
精度、再現率、F値:パースの質と完全性を評価します。
-
BLEUスコアとANLS:言語とレイアウト構造を評価するのに役立ちます。
-
編集距離、ジェンセン・シャノン発散、ジャッカード距離:OCRドメイン特有の指標で、コンテンツ再現の正確さを理解するのに特に役立ちます。
私たちのビジョン言語モデルであるAnyParserは、特に表や意味的要素を含む複雑なレイアウトにおいて、速度と精度を兼ね備えた優れたパフォーマンスを示しています。AnyParserは他のソリューションを上回り、GPT/Claudeのようなモデルに対して20倍の速度向上を実現し、より高い精度を達成しています。
主要なパースモデルとの広範な比較結果
統計的オブジェクト
AnyParserの能力を真に示すために、業界の主要なパースモデルおよび著名な大規模言語モデル(LLM)に対して広範な比較を行いました。評価には以下が含まれます:
1. 大規模言語モデル
- AnyParser
- OpenAIのGPT-4o
- GoogleのGemini 1.5 Pro
- AnthropicのClaude 3.5 Sonnet
2. OCRベースのサービス
- LlamaParse
- Amazon Textract
- Google Cloud Document AI
- Azure Document Intelligence
結果の提示と分析
実験1
まず、以下の5つの指標(BLEU、精度、再現率、F値、ANLS)に基づいて、異なる文書AIモデルのパフォーマンスを厳密に比較する一連の実験を行います。これらの指標の数学的定義は付録に記載されています。
比較対象のモデルは、AnyParser-base、AnyParser-pro、Textract、Llama-Parse、GPT4o、Gemini-1.5-pro、GCP-DocAI、Azure-DocAIです。
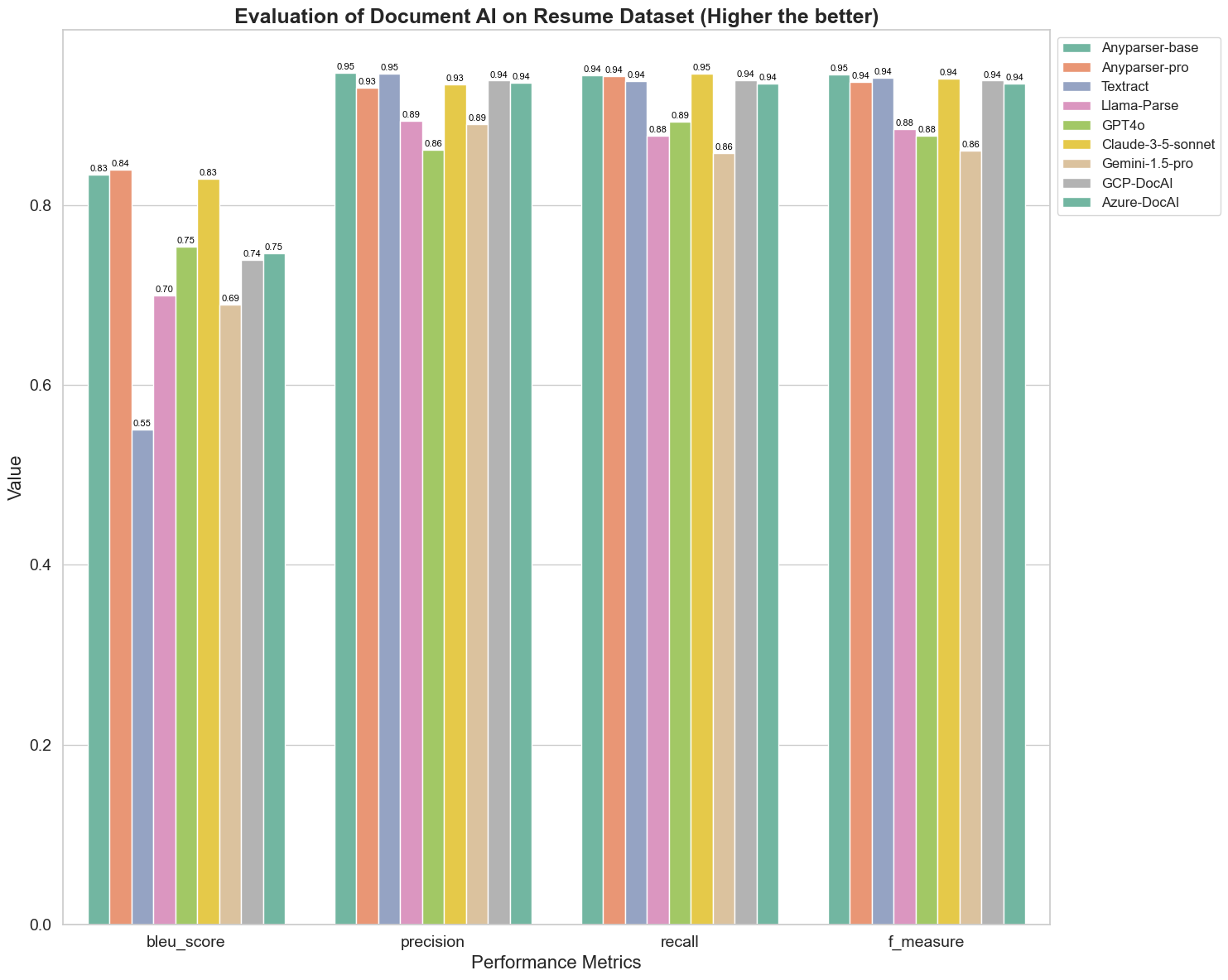
BLEUは、バイリンガル通訳の質を評価するために使用され、モデルが発話を処理する際の質をテストします。これらのパースモデルのBLEU評価方法に基づく結果を比較すると、AnyParser-baseとAnyParser-proのスコアが他のモデルのスコアよりも大幅に高く、Amazon Textractが最低スコアを記録し、他のモデルのスコアは比較的平均的なレベルにあることがわかります。
認識精度は通常、精度と再現率で表されます。精度は、モデルによって正しいと判断された結果の中で実際に正しい結果の割合を示し、再現率は、実際に正しい結果の中でモデルによって正しく判断された結果の割合を示します。これらのパースモデルの精度と再現率を比較すると、Llama-Parse、GPT4o、Gemini-1.5-proを除くすべてのモデルが高いレベルにあることがわかります。その中でも、AnyParserとAmazon Textractは精度が際立っており、AnyParser-baseとAnyParser-proは再現率が際立っています。モデルの精度が高いスコアは、モデルが生成結果においてより多くの正確な情報を出力していることを示し、再現率が高いスコアは、モデルがサンプルから正確な情報を取得する能力が高いことを示します。スコアの結果は、AnyParserがPDFからテキストを抽出する際の認識精度において明確な優位性を持っていることを示しています。
F値は、これらの2つの指標における精度と再現率の包括的な評価指標です。F値に基づいてこれらのパースモデルのスコアを比較すると、AnyParser-base、AnyParser-pro、Amazon Textract、GCP-DocAI、Azure-DocAIの5つのモデルが他のモデルと比較して認識精度において優れた強みを持っていることがより直感的にわかります。AnyParserはF値において最高のスコアを持ち、PDFからテキストを抽出する際の認識精度における明らかな優位性をさらに示しています。
ANLSは、元のテキストとターゲットテキストの文字レベルでの正確さと類似性を測定する際に一般的に使用される評価指標であり、モデルのパースレベルを測定するのにも非常に有用です。AnyParser-base、AnyParser-pro、Azure-DocAIの高いスコアは、これらのモデルが他のモデルと比較して高いパースレベルを反映しています。
全体として、AnyParser-baseとAnyParser-proは他のモデルを上回っています。
実験2
異なる文書AIモデルのパフォーマンスを、編集距離、ジェンセン・シャノン発散、ジャッカード距離の3つの異なる指標で比較します。これらの指標は、モデルの出力と参照文書との類似性を測定するために使用されます。値が低いほど、パフォーマンスが良いことを示します。
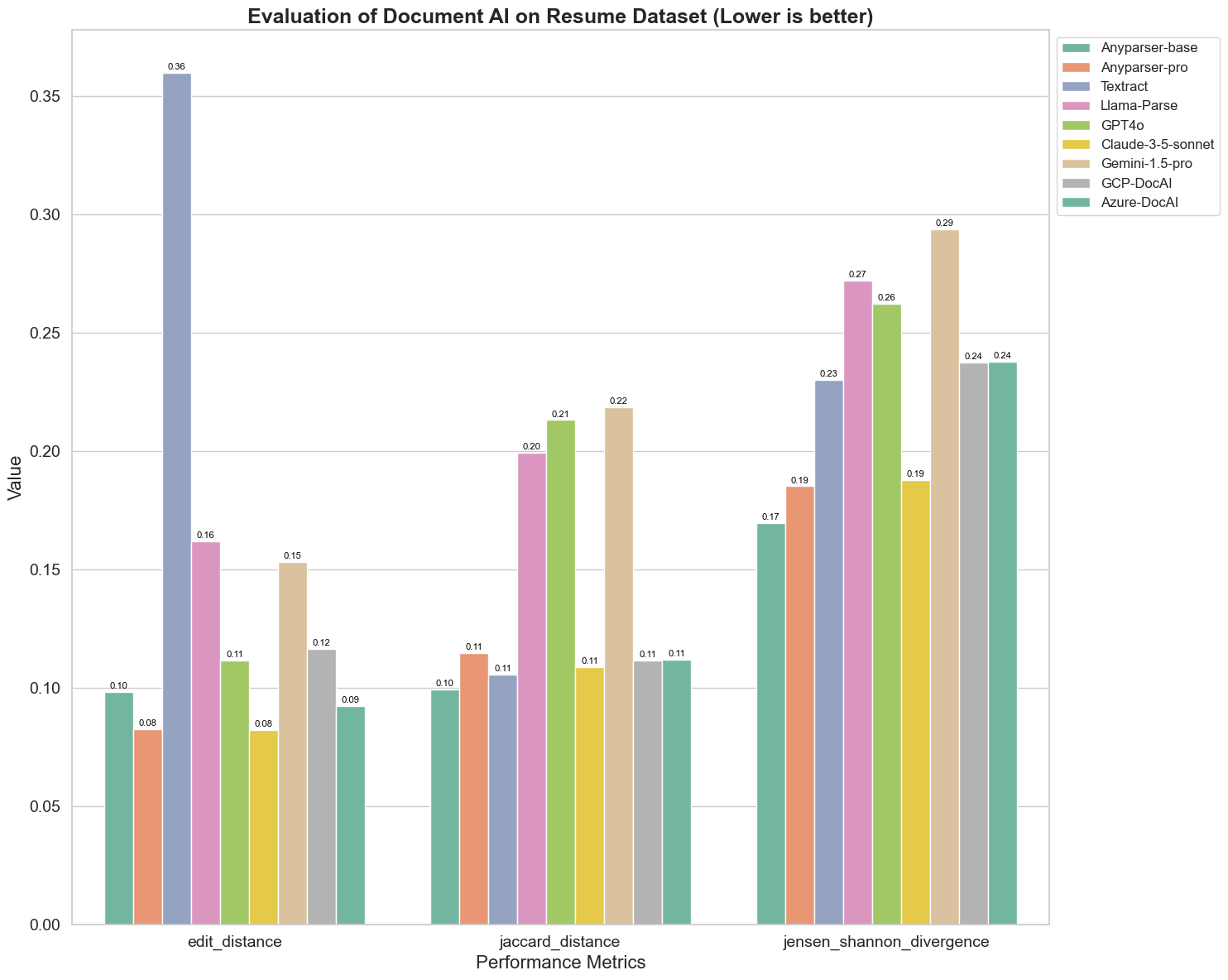
以下はチャートからの重要な観察結果です:
-
編集距離:AnyParser-baseとAnyParser-proのモデルは、最も低い編集距離を示し、出力が参照文書に最も近いことを示唆しています。
-
ジェンセン・シャノン発散:AnyParser-baseとAnyParser-proは最も低い発散を持ち、単語分布の観点から出力が参照文書に最も類似していることを示しています。
-
ジャッカード距離:Llama-parse、GPT4O、Gemini-1.5を除くすべてのモデルは、最も低いジャッカード距離を示し、使用された単語のセットにおいて出力が参照文書と最も高い重複を持っていることを示しています。
結論
全体として、私たちの厳密なテストは、AnyParser-baseとAnyParser-proがさまざまな指標で一般的に優れたパフォーマンスを示し、正確な文書処理の可能性を示唆しています。プロットから、著名なAmazon Textractのような従来のOCRモデルがビジョン言語モデルに比べてはるかに低いスコアを記録していることがわかります。しかし、異なるモデルのパフォーマンスは使用される指標によって異なるため、AIモデルを比較する際には複数の評価基準を考慮することの重要性が強調されます。
オープンソース評価パイプラインの紹介
評価を効率化するために、パースモデルを比較するための業界標準の方法を提供する評価パイプラインを作成しました。私たちの例では、履歴書パースが一般的なHRドメインでの使用を示しています。ペアの画像-Markdownファイルを使用して生成した128の履歴書からなる多様な合成データセットを構築しました。GPT-4を使用してHTMLコンテンツを生成し、それを画像にレンダリングし、抽出されたテキストを比較のための真実データとして使用しました。
そして、最も素晴らしい点は、この評価フレームワークをGitHubでオープンソース化したことです!開発者でもビジネスユーザーでも、私たちのパイプラインを使用することで、自分のデータセットに対する異なるモデルのパース品質を評価し、比較することができます。
Githubリポジトリでクイックスタートガイドを見つけ、異なるパースモデルがどのように互いに比較されるかを確認してください。私たちは、モデルの強みをオープンに示すことで、信頼性が高く、迅速で正確なパース機能を求めるより多くのユーザーを引き付けられると信じています。
付録 - 指標
1. 精度
精度は、パースされたコンテンツの正確さを測定し、取得された要素の中でどれだけが正しかったかを示します。パースにおいては、抽出されたすべての単語の中で正しく抽出された単語の割合です。
精度 = 真陽性 (TP) / (真陽性 (TP) + 偽陽性 (FP))
- 真陽性 (TP):パーサーによって正しく識別された単語。
- 偽陽性 (FP):パーサーによって誤って識別された単語。
2. 再現率
再現率は、パースの完全性、つまり元の文書からどれだけの関連単語が取得されたかを示します。
再現率 = 真陽性 (TP) / (真陽性 (TP) + 偽陰性 (FN))
- 偽陰性 (FN):パーサーによって見逃された元の文書の単語。
3. F値 (F1スコア)
F1スコアは、精度と再現率の調和平均であり、両方の指標のバランスを取ってパース品質の全体的な測定を提供します。
F1スコア = 2 × (精度 × 再現率) / (精度 + 再現率)
4. BLEUスコア (バイリンガル評価補助)
BLEUスコアは、パースされたコンテンツと元のテキストとの類似性を測定し、単語の順序に特に重点を置きます。これは、パースされた文書における言語と構造の一貫性を評価するのに特に役立ち、元のテキストから順序が異なる出力にペナルティを与えます。
5. ANLS (平均正規化レーヴェンシュタイン類似度)
ANLSは、パースされたコンテンツと元の内容との類似性を定量化し、正規化された編集距離を使用します。これは、パースされたテキストと参照テキストの各単語ペアに対する正規化レーヴェンシュタイン類似度 (NLS) の平均を計算することによって求められます。NLSは次のように計算されます:
NLS = 1 - (レーヴェンシュタイン距離 (LD)(パースされた単語, 元の単語)) / max(パースされた単語の長さ, 元の単語の長さ)
次に、ANLSはすべての単語ペアにわたるNLSの平均です:
ANLS = (1/N) × Σ(NLS_i) for i=1 to N
6. 編集距離
編集距離は、パースされたテキストを元のテキストに変換するために必要な単語レベルの操作(挿入、削除、置換)の数を計算します。
7. ジェンセン・シャノン発散
ジェンセン・シャノン発散は、パースされた単語数と元の単語数の離散確率分布の類似性を測定し、単語頻度の違いを強調します。
JSD(P || Q) = (1/2) × KL(P || M) + (1/2) × KL(Q || M)
ここで、M = (1/2)(P + Q)、KL(P || Q)はカルバック・ライブラー発散です。
8. ジャッカード距離
ジャッカード距離は、パースされたコンテンツと元のコンテンツの単語のセット間の不一致を測定し、単語の重複を評価するのに役立ちます。
ジャッカード距離 = 1 - |A ∩ B| / |A ∪ B|
ここで、|A ∩ B|はAとBの間の共通要素の数、
|A ∪ B|は両方のセットにおけるユニークな要素の総数です。