ビジョン言語モデル(VLM)は、文書分析の分野に革命をもたらしており、従来の光学文字認識(OCR)システムに内在する多くの限界に対処しています。OCRは画像からテキストをデジタル化するための基盤技術ですが、複雑なシナリオでは重大な課題に直面しています。これには、低品質の画像における精度の問題、限られた文脈理解、混合言語の処理の難しさ、視覚要素の解釈の不可能性が含まれます。VLMは、先進的なコンピュータビジョンと自然言語処理の能力を組み合わせることで、有望な解決策を提供します。本記事では、VLMがどのようにOCRの短所を克服し、デジタル時代の文書処理においてより堅牢で多用途なソリューションを提供しているかを探ります。
OCRとは?文書解析におけるOCRのプロセスは?
光学文字認識(OCR)は、スキャンした紙の文書、PDFファイル、またはデジタルカメラで撮影した画像など、さまざまな種類の文書を編集可能で検索可能なデータに変換する技術です。このプロセスは文書処理やPDFデータ抽出において重要であり、機械がデジタル画像内の印刷または手書きのテキスト文字を認識できるようにします。
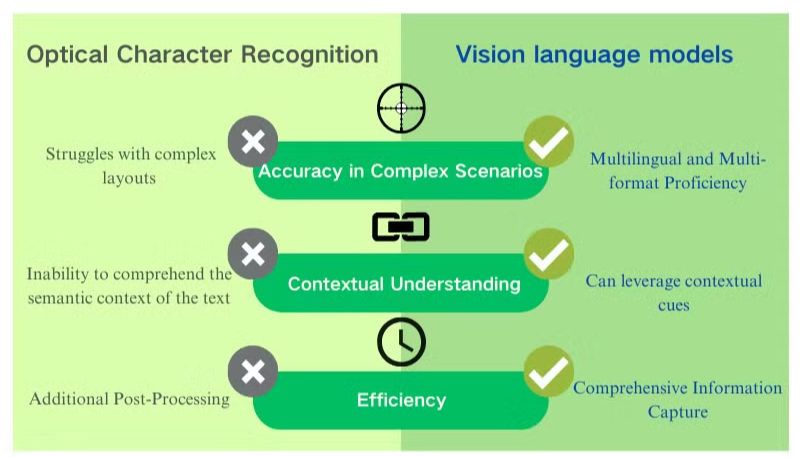
OCRプロセス
OCRプロセスは通常、いくつかのステップを含みます:
- 画像取得:文書をスキャンまたは撮影してデジタル画像を作成します。
- 前処理:画像をクリーンアップし、ノイズを除去し、明るさとコントラストを調整します。
- テキスト検出:システムが画像内のテキストを含む領域を特定します。
- 文字セグメンテーション:テキスト領域内の個々の文字を分離します。
- 文字認識:各文字を分析し、既知の文字のデータベースと比較します。
- 後処理:認識されたテキストを言語的および文脈的情報を使用してエラーをチェックします。
OCRは文書解析能力を大幅に向上させましたが、複雑なレイアウト、低品質の画像、さまざまなフォントの処理において依然として限界に直面しています。ここで、ビジョン言語モデルのような先進技術が、画像や文書からのデータ抽出における精度と理解を向上させるために登場します。
従来のOCR技術の限界
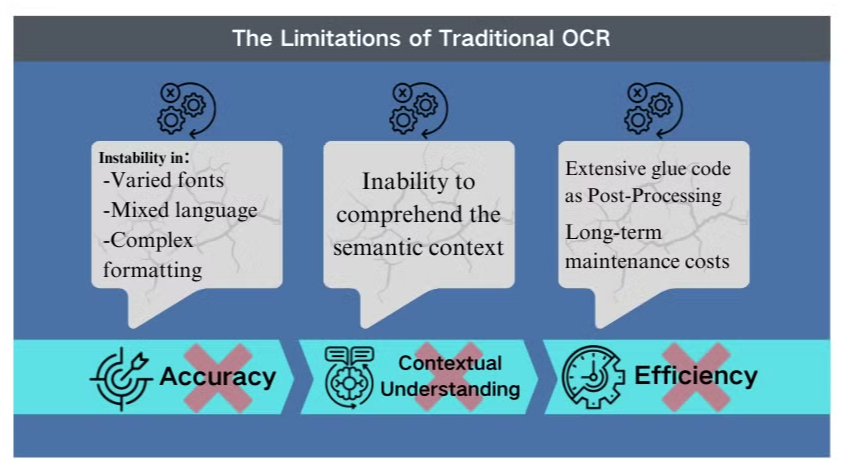
複雑なシナリオにおける精度の課題
従来の光学文字認識(OCR)技術は、基本的なテキスト抽出には有益ですが、複雑な文書レイアウトや低品質の画像に直面すると、重大な障害に直面します。これらのシステムは、さまざまなフォント、混合言語、または複雑なフォーマットの文書を処理する際に精度を維持するのに苦労します。たとえば、OCRは画像が多いプレゼンテーションや密にフォーマットされたPDFからデータを抽出しようとすると失敗することがあります。
文脈理解の欠如
従来のOCRの最も顕著な限界の1つは、処理するテキストの意味的文脈を理解できないことです。この欠点は、法的契約や医療報告書など、微妙な解釈が必要なシナリオで特に明らかになります。文脈を考慮せずに文字認識に焦点を当てるOCRは、あいまいな文字や業界特有の用語を扱う際に重大な誤解を招く可能性があります。
後処理の非効率性
OCRの限界は、しばしば広範な後処理作業を必要とします。この追加のステップは、文書処理に必要な時間とリソースを大幅に増加させる可能性があります。さらに、従来のOCRシステムは、チャート、テーブル、またはその他の非テキスト要素から情報を抽出する際に通常は不十分であり、文書抽出プロセスをさらに複雑にします。これらの非効率性は、文書分析とデータ抽出に対するより高度なソリューション、つまりビジョン言語モデルの必要性を強調しています。
ビジョン言語モデルとは何か、そしてそれがOCRをどのように改善するか
ビジョン言語モデルは、従来の光学文字認識(OCR)システムに内在する多くの限界に対処する文書処理技術の重要な飛躍を表しています。これらの先進的なモデルは、コンピュータビジョンと自然言語処理を組み合わせて、文書の視覚的要素とテキスト要素の両方を同時に理解します。
精度と文脈理解の向上
低品質の画像や複雑なレイアウトに苦しむOCRとは異なり、ビジョン言語モデルは多様な文書フォーマットの解釈に優れています。これらは、困難なシナリオに直面しても、画像、PDF、およびその他の視覚コンテンツからデータを正確に抽出できます。この精度の向上は、文書全体の文脈を考慮する能力に起因しており、個々の文字や単語にのみ焦点を当てるのではありません。
包括的なデータ抽出
ビジョン言語モデルは、単純なテキスト認識を超えて、包括的なPDFデータ抽出機能を提供します。これらは、文書内のテーブル、チャート、および図を特定して解釈し、複雑なレイアウトの整合性を保持します。この文書分析への全体的アプローチにより、より微妙で完全な情報の取得が可能となり、抽出されたデータの下流アプリケーションに対する有用性が大幅に向上します。
多言語および多フォーマットの能力
ビジョン言語モデルの重要な利点の1つは、複数の言語や文書フォーマットを処理する柔軟性です。非ラテン文字や混合言語の文書に苦しむOCRシステムとは異なり、これらのモデルはさまざまな言語やスクリプトにわたってコンテンツをシームレスに処理できるため、グローバルな文書処理ニーズにとって非常に貴重です。
文書理解におけるビジョン言語モデルの主な利点
ビジョン言語モデルは、文書処理やデータ抽出において従来のOCRに対して重要な利点を提供します。これらのAI駆動システムは、視覚的およびテキストの理解を組み合わせて、さまざまな文書タイプで優れた結果を提供します。
精度と文脈理解の向上
ビジョン言語モデルは、複雑なレイアウト、低品質の画像、および多様なフォントを処理するのに優れています。あいまいな文字に苦しむOCRとは異なり、これらのモデルは文脈の手がかりを活用してテキストを正確に解釈します。この能力は、特に複雑な構造や画像品質が悪い文書において、PDFデータ抽出の精度を劇的に向上させます。
包括的な情報キャプチャ
OCRがテキスト認識のみに焦点を当てるのに対し、ビジョン言語モデルは画像、テーブル、およびチャートからデータを抽出できます。この全体的なアプローチにより、文書処理フェーズで重要な情報が見落とされることはありません。テキストと視覚要素の両方をキャプチャすることで、これらのモデルは文書内容のより完全な理解を提供します。
多言語および多フォーマットの能力
ビジョン言語モデルは、さまざまな言語やフォーマットの文書を処理する際に驚くべき柔軟性を示します。混合言語の文書や非ラテン文字をシームレスに処理でき、従来のOCRシステムの重大な限界を克服します。この柔軟性は、多様な文書タイプや言語を扱うグローバル企業にとって非常に貴重です。
VLMによって可能になった実世界のアプリケーション、OCRが失敗したもの
ビジョン言語モデルは、従来のOCRシステムの重要な限界に対処し、金融、人事、その他の分野における文書処理を革命化しています。これらの先進的なAIモデルは、業界全体でのデジタルトランスフォーメーションの取り組みを変革し、優れた精度と文脈理解を提供します。
財務文書処理の革命
ビジョン言語モデルは、従来のOCRの限界を克服し、金融における文書処理を変革しています。これらの先進的なモデルは、複雑な財務諸表、請求書、受領書からデータを抽出するのに優れています。OCRとは異なり、文脈を理解し、あいまいな文字(例:ゼロとアルファベットのOを区別する)や、グローバルな財務文書にしばしば存在する混合言語を正確に解釈できます。
インテリジェントな文書分析による人事業務の向上
人事部門では、ビジョン言語モデルが履歴書、従業員記録、パフォーマンスレビューからのPDFデータ抽出において非常に貴重です。これらのモデルは、文書の意味的構造を理解できるため、より正確な情報取得と分析を可能にします。この能力は、さまざまなフォーマットや手書きのメモに苦しむOCRの課題を克服し、採用プロセスや従業員データ管理を大幅に効率化します。
コンプライアンスとリスク管理の改善
ビジョン言語モデルは、金融および人事の両方におけるコンプライアンスとリスク管理に特に効果的です。これらは、規制文書、契約、およびポリシーから重要な情報をOCRよりも高い精度で抽出し解釈できます。この強化された文書処理能力は、法的要件の遵守を確保し、より効率的なリスク評価手続きを実現します。
結論
結論として、ビジョン言語モデルは文書処理技術における重要な飛躍を表し、従来のOCRシステムに内在する多くの限界に対処しています。視覚的およびテキストの理解を組み合わせることで、これらの先進的なモデルは、複雑なレイアウト、混合言語、低品質の画像など、さまざまな困難なシナリオで優れたパフォーマンスを提供します。組織が業務をデジタル化し、文書リポジトリから価値を抽出するより効率的な方法を模索し続ける中で、ビジョン言語モデルは開発者やエンジニアリーダーにとって強力なツールとして浮上しています。文脈を理解し、多様なフォーマットを処理し、より正確な結果を提供する能力は、洗練されたRAGパイプラインや企業全体の検索機能を実現するための重要な要素として位置づけられ、デジタルトランスフォーメーションの取り組みを新たな高みへと導きます。