OCRが何の略か考えたことはありますか?光学文字認識(Optical Character Recognition)は、テキストの画像を機械可読データに変換する強力な技術です。OCRは文書のデジタル化や情報の抽出において多大な利点を提供しますが、欠点も存在します。この技術を探求する際には、その能力と限界の両方を理解することが重要です。この記事では、OCRの意味を明らかにし、その潜在的な欠点について掘り下げます。光学文字認識について包括的に理解することで、自身のワークフローやプロジェクトにこの技術をどのように実装するかを判断するための準備が整います。
OCRとは何か、そしてOCRとは?
OCRとは何か?
OCRは光学文字認識(Optical Character Recognition)の略で、コンピュータがさまざまな種類の文書を認識し、変換することを可能にする技術です。OCRの本質は、印刷されたテキストや手書きのテキストをスキャンし、機械でエンコードされたテキストに変換するプロセスです。これにより、テキストは簡単に検索可能、編集可能、転送可能になります。OCRの意味を理解することは、文書スキャンやテキスト認識技術に関わるすべての人にとって重要です。
OCRとは?
この用語に不慣れな方のために、「OCRとは?」という質問は一般的で、光学文字認識(Optical Character Recognition)を指します。これは、コンピュータが画像やスキャンされた文書からテキストを読み取ることを可能にする技術です。
OCRは印刷されたテキストや手書きのテキストを機械可読データに変換し、紙とデジタル形式の間のギャップを埋めます。この技術は、文字の形状、単語の構造、さらには全体の文を検出するために高度なアルゴリズムを使用します。これにより、静的な画像を編集可能で検索可能なテキストファイルに変換します。
OCR技術は、基本的にコンピュータビジョンとパターン認識技術に基づいています。OCRは、テキストを含む文書や画像をスキャンし、高度なアルゴリズムを使用してテキストを特定し、デジタルで編集可能な形式に変換します。OCR技術の歴史の中で重要な瞬間の一つは、1974年にレイ・カーツワイルがほぼすべてのフォントのテキストを認識できるオムニフォントOCRシステムを開発したことです。年月が経つにつれて、OCRは単純なテンプレートマッチングからより洗練されたシステムへと進化しました。
その能力にもかかわらず、OCR技術は現在、特定の限界に直面しています。これには、品質の悪い画像でのテキスト認識の課題、複雑なレイアウトや背景の処理の難しさ、異なるフォント、言語、手書きに対する精度のばらつきが含まれます。さらに、OCRシステムは、色付きの背景を持つ文書、ぼやけているまたは歪んでいる文書、そして草書体の手書きに苦労することがあります。
光学文字認識ソフトウェアの理解
光学文字認識ソフトウェアは、さまざまな種類の文書を編集可能で検索可能なデータに変換する変革的な技術です。これは、私たちの世界をデジタル化する上で重要な役割を果たし、情報をよりアクセスしやすく、管理しやすくします。OCRソフトウェアは、テキストの画像を機械可読データに変換するための高度なプロセスを採用しています。
OCRソフトウェアの仕組み
1. 画像取得
OCRの旅は、文書の画像をキャプチャすることから始まります。これはスキャナーやデジタルカメラを使用して行うことができます。画像は、その後、コンピュータが処理できるデジタル形式に変換されます。
2. 前処理と画像強化
2番目のステップは、画像の品質を向上させることです。画像が取得されると、より良い認識のために品質を向上させるための前処理が行われます。このステップでは、画像のコントラスト、明るさ、シャープネスを調整し、ノイズや無関係な要素を取り除くことが含まれる場合があります。この前処理段階は、特に低品質のスキャンや写真を扱う際に正確な結果を得るために重要です。
3. テキスト検出
OCRソフトウェアは、前処理された画像を分析してテキストを含む領域を検出します。これは、異なる太さや高さの線など、テキストの特徴的なパターンや形状を探すことによって行われます。
4. 文字セグメンテーション
テキスト領域が検出されると、ソフトウェアはテキストをブロック、行、単語、または個々の文字のような小さな単位に分解します。OCRソフトウェアは、画像をピクセル単位で分析して文字を形成するパターンを特定します。画像を小さなセグメントに分解し、各文字を孤立させます。
5. テキスト認識と抽出
ソフトウェアは、これらの孤立した形状を既知の文字パターンの広範なデータベースと比較して、各文字が何であるかを判断します。ソフトウェアは、文字の特徴(線の数、曲線、角度など)を抽出します。これらの特徴は、OCRが異なる文字を認識し、区別するのに役立ちます。
6. ポストプロセッシング
文字が特定された後、OCRシステムはポストプロセッシング段階を経て、潜在的なエラーを修正し、出力用にテキストをフォーマットします。修正されたテキストは、その後、Word文書や検索可能なPDFなどの希望する形式にエクスポートされます。
光学文字認識ソフトウェアのユースケース
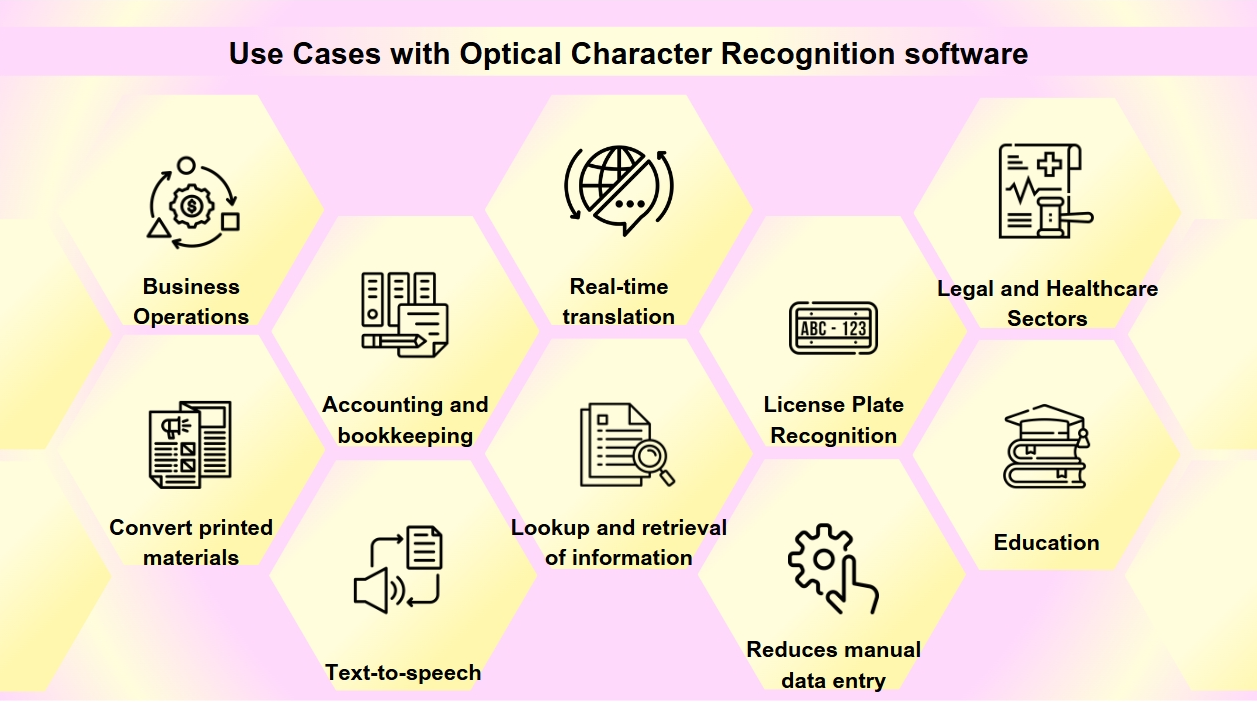
OCRは、多くの業界のデジタルトランスフォーメーションにおいて不可欠なツールとなり、プロセスを合理化し、データのアクセス性と正確性を向上させています。あなたは、思っている以上に頻繁にOCRに出会うかもしれません。名刺のスキャンから古い本のデジタル化まで、OCRはさまざまな業界で重要な役割を果たしています。OCR技術には多くの応用があります:
-
文書デジタル化: OCRは、古い本、新聞、歴史的文書などの印刷物をデジタル形式に変換し、検索可能にし、将来の世代のために保存します。
-
フォーム処理: 企業はOCRを利用してフォームから自動的にデータを抽出し、手動データ入力を減らし、金融や医療などのさまざまな分野で効率を向上させます。
-
請求書処理: OCR技術は、請求書のテキストを読み取り、自動的にデータを財務システムに入力し、会計や簿記プロセスを合理化します。
-
アクセシビリティ: OCRはテキストから音声への機能を可能にし、視覚障害者向けにテキストの音声版を作成し、印刷物をよりアクセスしやすくします。
-
モバイルアプリケーション: OCRは、名刺のスキャン、写真内のテキストの認識、リアルタイム翻訳の促進などのタスクに統合されています。
-
検索可能性: OCRは、画像やPDFからテキストを抽出することでスキャンされた文書の検索可能性を向上させ、情報の簡単な検索と取得を可能にします。
-
ナンバープレート認識: 駐車場や交通管理に使用され、OCRはナンバープレートを認識し、効率的な監視と執行を可能にします。
-
ビジネスオペレーション: OCRは、請求書、領収書、発注書などの文書からのデータ入力を自動化し、ビジネスプロセスを合理化し、求人応募や履歴書のスキャンと処理を迅速化します。
-
法律および医療分野: 法律事務所はOCRを使用してケースファイルや法的文書をデジタル化し、情報の取得を容易にし、医療提供者は患者記録や医療フォームを電子健康記録(EHR)に変換するために利用し、データ管理と患者ケアを向上させます。
-
教育: 教育機関では、OCRを使用してデジタル教科書や学習資料を作成し、多様なニーズを持つ学生のアクセスを向上させ、包括的な学習環境をサポートします。
OCR技術が進化するにつれて、情報をよりアクセスしやすく、デジタル時代において効率的に扱うための重要な役割を果たし続けます。
OCRの欠点:限界と欠点
精度の課題
光学文字認識(OCR)技術は大きな進歩を遂げましたが、完全な精度を達成するには依然として重大な障害があります。手書きのテキスト、異常なフォント、または品質の悪い画像は、誤解釈やエラーを引き起こす可能性があります。文字の形状やサイズのわずかな違いでも、OCRシステムを混乱させ、手動での修正が必要な混乱した出力をもたらすことがあります。
言語と形式の制約
ほとんどのOCRソリューションは標準的な言語や形式に優れていますが、専門的なコンテンツには苦労します。技術文書、数学的方程式、または複数の言語を含むテキストは、重大な課題を引き起こす可能性があります。さらに、OCRは複雑なレイアウト、表、または複雑なフォーマットの文書に直面すると、重要な構造情報を失う可能性があります。
リソース集約型
効果的なOCRシステムを実装し、維持することはリソース集約型になる可能性があります。高品質のOCRソフトウェアはしばしば高額であり、大量の文書を処理するために必要なハードウェアも高価です。さらに、スタッフのトレーニング、システムの微調整、OCR出力の手動レビューと修正に必要な時間と労力は、組織のリソースに負担をかける可能性があります。
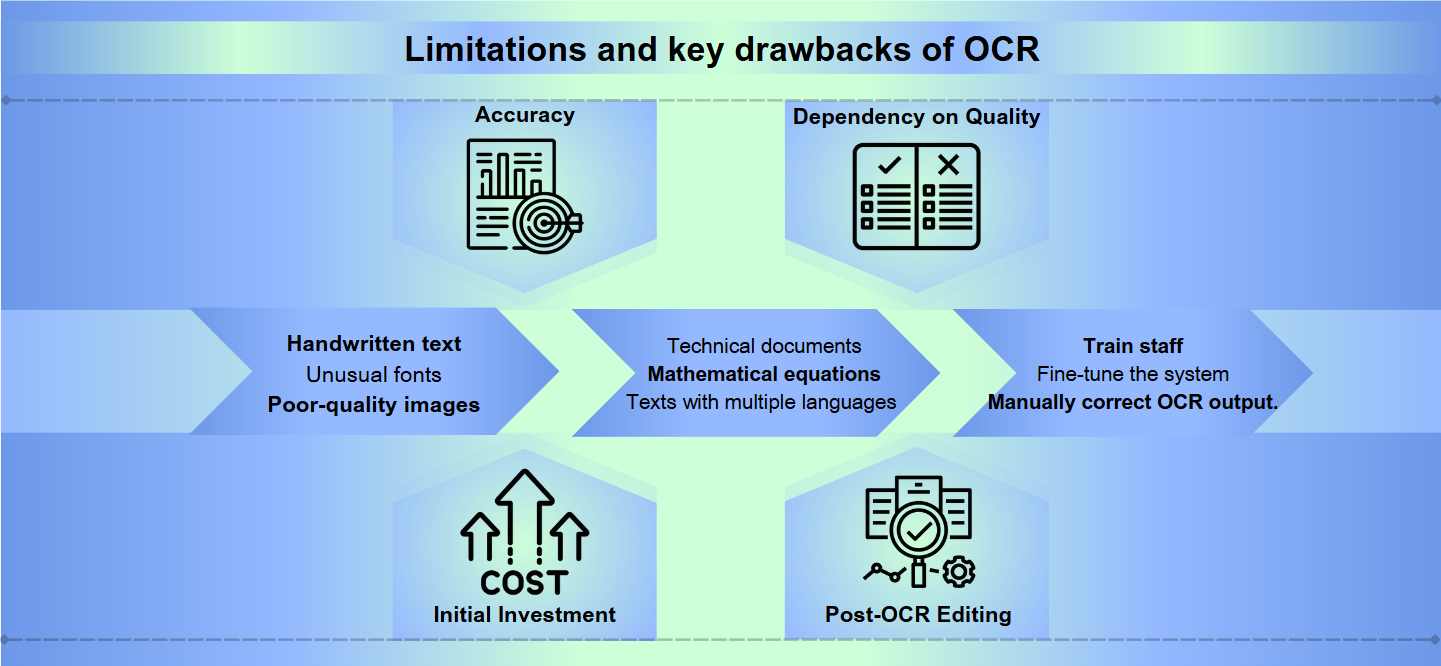
OCRの主な欠点
-
精度: OCRソフトウェアは、特に品質の悪い画像、複雑なレイアウト、または手書きのテキストを扱う際に精度に苦しむことがあります。エラーは、文字の誤読からテキストの全体のセクションをスキップすることまで多岐にわたります。
-
品質への依存: OCRの効果は、元の文書の品質に大きく依存します。色あせたインク、にじみ、またはしわのある紙は、不正確な翻訳を引き起こす可能性があります。
-
初期投資: OCRシステムのセットアップには、ソフトウェアだけでなく、スキャナーなどの互換性のあるハードウェアも含めて、かなりの初期コストが必要です。
-
OCR後の編集: 多くの場合、OCRプロセスからの出力は手動でのレビューと修正を必要とし、時間がかかることがあります。
OCRの限界を克服するビジョン言語モデル
技術が進化する中で、従来の光学文字認識(OCR)の欠点に対処する革新的なソリューションが登場しています。その一つがビジョン言語モデル(VLM)であり、コンピュータビジョンと自然言語処理を組み合わせてテキストの抽出と理解を革命的に変えます。
コンテキストの理解の向上
VLMは、OCRの孤立した文字認識とは異なり、テキストの周囲のコンテキストを理解するのに優れています。視覚要素とテキストを分析することで、これらのモデルは複雑なレイアウト、手書きのメモ、さらには部分的に隠れたテキストを驚くべき精度で解釈できます。
多言語および多モーダル能力
OCRが多様な言語やスクリプトに苦労する一方で、VLMは印象的な柔軟性を示します。これらは複数の言語をシームレスに処理し、図やチャートのような視覚コンテンツを解釈することもでき、文書のより包括的な理解を提供します。
適応学習と継続的改善
静的なOCRシステムとは異なり、VLMは機械学習を活用して時間とともに適応し、改善します。新しいデータやシナリオに遭遇することで、これらのモデルはパフォーマンスを洗練させ、さまざまな文書タイプや形式を扱う能力を高めていきます。
OCRの限界を克服することで、ビジョン言語モデルは、業界全体でより正確で効率的かつインテリジェントな文書処理の道を切り開いています。
ビジョン言語モデルを選ぶ:AnyParserを試してみる
ビジョン言語モデル(VLM)の進歩を基に、AnyParserは従来のOCR技術の限界を超えた洗練されたソリューションとして登場します。CambioMLチームによって開発されたAnyParserは、PDF、画像、チャートなどのさまざまな非構造化データソースから情報を抽出し、構造化された形式に変換するための正確で構成可能なAPIを利用した強力な文書解析ツールです。
技術基盤と能力
AnyParserは、大規模言語モデル(LLM)の強力な基盤に基づいており、文書からのテキスト、表、チャート、レイアウトの抽出において高い精度を確保しています。特に複雑なレイアウトや元の美的感覚を保持する必要がある文書にとって、この元のレイアウトとフォーマットを維持する能力が際立っています。
プライバシーとセキュリティ
ユーザーのプライバシーを重視し、AnyParserはデータをローカルで処理し、機密情報を保護します。この機能は、機密データを扱う企業や個人にとって大きな利点です。
カスタマイズ性と柔軟性
高い構成可能性を提供するAnyParserは、ユーザーがカスタム抽出ルールを設定し、特定のニーズに合った出力形式を定義できるようにします。この適応性は、AIエンジニアリングから金融分析まで、幅広いアプリケーションに理想的なツールとなります。
結論
ご覧のように、OCR技術はテキストをデジタル化するための強力な能力を提供しますが、限界もあります。光学文字認識は効率を劇的に向上させることができますが、潜在的な欠点を慎重に考慮する必要があります。OCRソリューションを実装する前に、精度の問題、フォーマットの課題、リソースの要件を検討してください。最終的に、OCRを利用するかどうかの決定は、あなたの具体的なニーズと状況に依存します。利点と欠点の両方を理解することで、OCRがあなたの組織にとって適切かどうかを判断するための情報に基づいた選択ができるようになります。OCRが進化し続ける中で、現在の短所に対処し、この変革的な技術のさらなる可能性を引き出す新しい開発に注意を払いましょう。
行動を促す呼びかけ
ビジョン言語モデルの力を活用し、AnyParserを無料で試してPDFをGoogle Sheetsに変換してみてください。詳細はhttps://www.cambioml.com/sandboxをご覧ください。VLMがあなたのデータ抽出ワークフローをどのように向上させるかについての無料相談を受けてみましょう。