構造化データと非構造化データとは
デジタル情報時代において、データは常に生成され、企業はデータの分析と処理を通じて価値を創出します。そのため、データの収集と記録、データの処理と分析は、ビジネス運営において重要な二つのタスクとなっています。データ収集の過程では、非構造化データにしばしば遭遇します。これらのデータの出所や形式は多様であり、単純に分類したり検索したりすることが難しいです。効果的なデータ取り込みは、組織が生のデータを実用的な洞察に効率的に変換するために不可欠です。データ処理の過程では、構造化データがより多く遭遇します。構造化データは明確な構造を持ち、情報が明確に定義されており、簡単に整理、検索、分析することができます。したがって、非構造化データを構造化データに変換することは、企業がデータの価値を活用するための重要なステップです。
構造化データ
構造化データとは、事前に定義されたデータモデルまたはスキーマに適合するデータです。これは、財務業務、販売およびマーケティングの数値、科学的モデリングなどの離散的な数値データを扱う際に特に便利です。
構造化データは通常、定量的であり、簡単に検索できるように整理されています。これには、名前、住所、クレジットカード番号、電話番号、星評価、銀行情報など、リレーショナルデータベースでSQLを使用して簡単にクエリできるデータが含まれます。
実世界のアプリケーションにおける構造化データの例には、フライト予約時のフライトおよび予約データ、SalesforceのようなCRMシステムにおける顧客の行動や嗜好が含まれます。構造化データは、離散的で短い非連続的な数値およびテキスト値の関連コレクションに最適であり、在庫管理、CRMシステム、ERPシステムに使用されます。
構造化データは、リレーショナルデータベース、グラフデータベース、空間データベース、OLAPキューブなどに保存されます。その最大の利点は、整理、クリーンアップ、検索、分析が容易であることですが、主な課題は、すべてのデータが規定されたデータモデルに適合しなければならないことです。
非構造化データ
非構造化データとは、属性を識別するための基盤となるモデルがないデータです。これは、データが構造化データ形式に収まらない場合に使用されます。例えば、ビデオ監視、企業文書、ソーシャルメディアの投稿などです。
非構造化データの例には、電子メール、画像、ビデオファイル、音声ファイル、ソーシャルメディアの投稿、PDFなど、さまざまな形式が含まれます。データの約80〜90%が非構造化であり、企業がそれを活用できれば競争優位性の大きな可能性を秘めています。
実世界のアプリケーションにおける非構造化データの例には、顧客の質問に答え情報を提供するためにテキスト分析を行うチャットボットや、投資決定のために株式市場の変化を予測するために使用されるデータが含まれます。非構造化データは、属性が変化するか不明なデータ、オブジェクト、またはファイルの関連コレクションに最適であり、プレゼンテーションまたはワードプロセッシングソフトウェアやメディアの表示または編集ツールとともに使用されます。ソーシャルメディアの投稿や顧客フィードバックなどの非構造化補足サービスデータは、構造化形式に変換することで貴重な洞察を提供できます。
非構造化データは通常、データレイク、NoSQLデータベース、データウェアハウス、アプリケーションに保存されます。非構造化データの最大の利点は、簡単に構造化データに形作ることができないデータを分析できる能力ですが、主な課題は分析が難しいことです。非構造化データの主な分析技術は、文脈や使用されるツールによって異なります。
構造化データと非構造化データの違い
構造化データの利点と非構造化データの欠点
構造化データは、簡単に検索でき、機械学習アルゴリズムに使用できるという利点があり、企業や組織がデータを解釈するためにアクセスしやすくなります。また、非構造化データよりも構造化データを分析するためのツールが多く存在します。一方、非構造化データは、データサイエンティストがデータを準備し分析する専門知識を必要とし、組織内の他の従業員がアクセスできなくなる可能性があります。さらに、非構造化データを扱うためには特別なツールが必要であり、そのためアクセスの難しさが増します。
構造化データ分析と非構造化データ分析
構造化データ分析は、データが厳密にフォーマットされているため、特定のデータエントリを検索し、特定し、エントリを作成、削除、または編集するためにプログラミングロジックを使用できるため、通常はより簡単です。これにより、構造化データのデータ管理と分析の自動化がより効率的になります。対照的に、非構造化データ分析には事前に定義された属性がないため、検索や整理が難しくなります。非構造化データ分析は、前処理、操作、分析のために複雑なアルゴリズムを必要とし、分析プロセスにおいてより大きな課題をもたらします。非構造化補足サービスデータの分析には、意味のある情報を抽出するために高度なパース技術が必要です。
構造化データ管理と非構造化データ管理
構造化データの管理は、一般的にその整理された予測可能な性質のため、より効率的です。コンピュータ、データ構造、プログラミング言語は構造化データをより容易に理解できるため、その使用において最小限の課題が生じます。これに対して、非構造化データ管理は、ストレージに関して二つの重要な課題を抱えています。非構造化データ管理は通常、構造化データ管理よりも大きな処理に直面しており、分析も構造化データ管理の分析ほど簡単ではありません。非構造化データを理解し管理するためには、コンピュータシステムがまずそれを理解可能なコンポーネントに分解する必要があり、これはより複雑なプロセスです。
構造化データと非構造化データの違いの要約
構造化データは定義されており、検索可能で、日付、電話番号、製品SKUなどのデータを含みます。これにより、整理、クリーンアップ、検索、分析が容易になり、非構造化データと比較しても、写真、ビデオ、ポッドキャスト、ソーシャルメディアの投稿、電子メールなど、分類や検索が難しいその他すべてを含む非構造化データよりも優れています。構造化データと非構造化データの違いを説明する一文:世界のデータのほとんどは非構造化ですが、構造化データの管理と分析の容易さは、データを整然と整理し迅速にアクセスできるアプリケーションにおいて大きな優位性を与えます。
構造化データと非構造化データの例
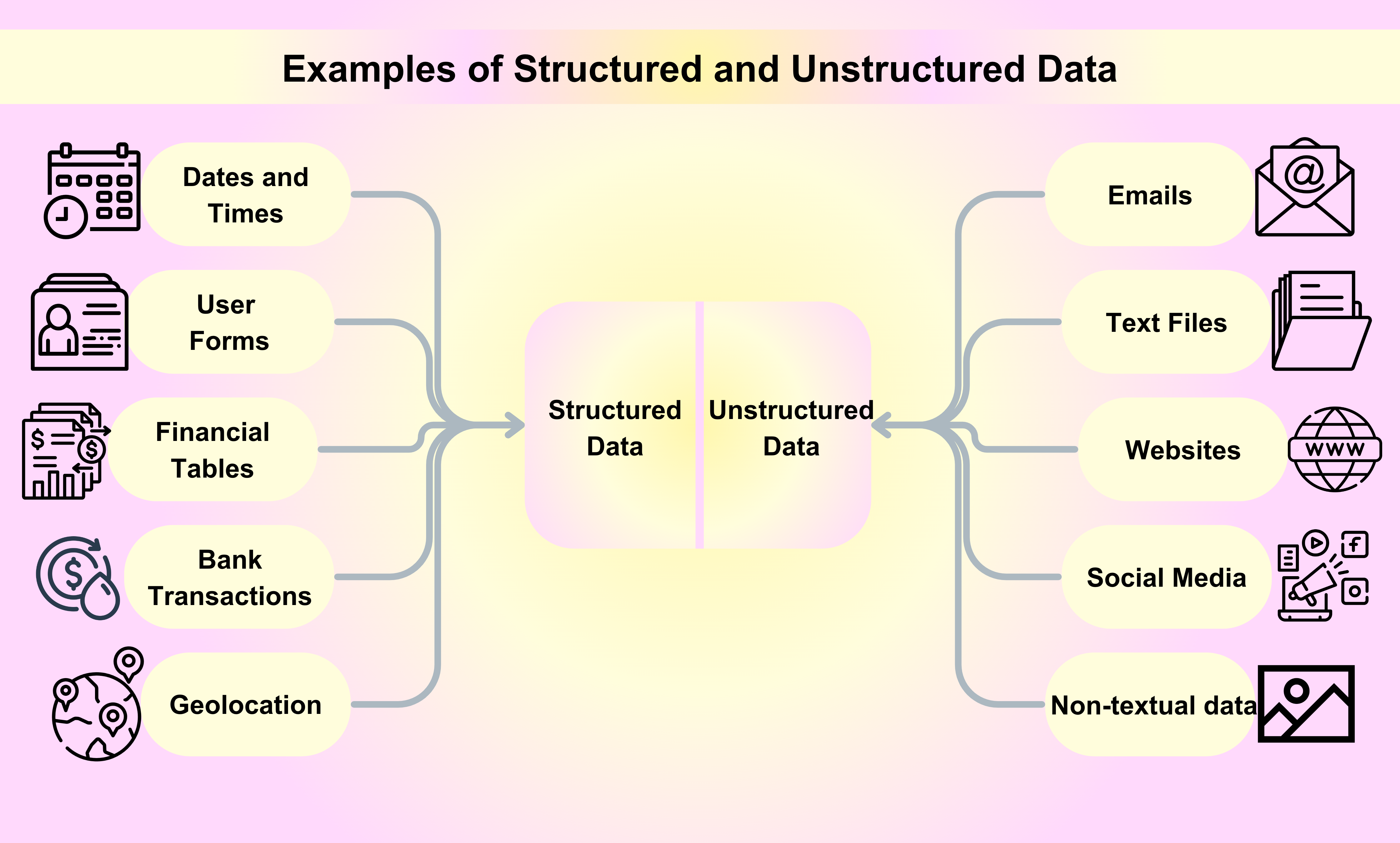
構造化データの例
-
日付と時刻:日付と時刻は特定のフォーマットに従い、機械が読み取り分析しやすくなっています。例えば、日付はYYYY-MM-DDの形式で構造化され、時刻はHH:MM:SSの形式で構造化されます。
-
顧客名と連絡先情報:サービスにサインアップしたり、オンラインで製品を購入したりすると、名前、メールアドレス、電話番号、その他の連絡先情報が収集され、構造化された形で保存されます。
-
金融取引:クレジットカード取引、銀行預金、送金などの金融取引はすべて構造化データの例です。各取引には、シリアル番号、取引日、金額、関与する当事者などの特定の情報が含まれています。
-
株式情報:株価、取引量、市場資本などの株式情報も構造化データの一例です。この情報は体系的に整理され、リアルタイムで更新されます。
-
ジオロケーション:GPS座標やIPアドレスを含むジオロケーションデータは、ナビゲーションシステムから位置ベースのマーケティングキャンペーンまで、さまざまなアプリケーションで使用されます。
非構造化データの例
-
電子メール:電子メールは、ビジネスや個人の目的で毎日使用される最も一般的な非構造化データの例の一つです。
-
テキストファイル:非構造化データの例には、ワードプロセッシングファイル、スプレッドシート、PDFファイル、レポート、プレゼンテーションが含まれます。
-
ウェブサイト:YouTube、Instagram、Flickrなどのウェブサイトからのコンテンツは、非構造化データの例と見なされます。
-
ソーシャルメディア:Facebook、Twitter、LinkedInなどのソーシャルメディアプラットフォームから生成されるデータは、非構造化データの例です。
-
メディア:デジタル画像、音声録音、ビデオは、非構造化データの例として考えられる大量の非テキストデータを表します。
構造化データ分析の技術
-
SQLクエリ:構造化データは、SQL(Structured Query Language)を使用して効率的にクエリでき、リレーショナルデータベースに保存されたデータの迅速な取得と操作を可能にします。
-
データウェアハウジング:構造化データは、複数のソースからデータを統合し、複雑なクエリと分析をサポートするデータウェアハウスに保存できます。
-
機械学習アルゴリズム:アルゴリズムは、構造化データを処理してパターンを特定し、予測を行うことができます。
構造化データは理解しやすく操作しやすいため、幅広いユーザーにアクセス可能です。構造化データは効率的なストレージ、取得、分析を可能にし、意思決定プロセスを迅速化します。構造化データシステムは、大量のデータを処理できるようにスケールし、データが増加してもパフォーマンスを維持します。
非構造化データ分析の技術
-
自然言語処理(NLP):NLP技術は、テキストデータを分析し、大量の非構造化テキストから意味のある情報や洞察を抽出するために使用されます。
-
機械学習:機械学習アルゴリズムは、画像や音声ファイルなどの非構造化データのパターンを認識するように訓練できます。
-
データレイク:非構造化データは、データレイクに保存され、生のデータをそのままの形式で保存し、分析が必要になるまで待機させることができます。
非構造化データ分析の技術の例から、非構造化データの分析はより複雑であり、専門的なツールと技術を必要とします。非構造化データの処理には、通常、かなりの計算リソースとストレージ容量が必要です。非構造化データには不整合、エラー、または無関係な情報が含まれている可能性があり、データ品質を確保することが難しいです。データ取り込みの効率化は、組織が大量のデータを管理し分析する能力を大幅に向上させることができます。
非構造化データを構造化データに変換する必要性の例
-
顧客フィードバック分析:顧客のレビューやフィードバックを非構造化テキストから構造化データに変換することで、企業は感情分析を行い、顧客満足度のトレンドを特定できます。
-
医療記録:医師のメモや画像レポートなどの非構造化医療記録を構造化することで、電子健康記録(EHR)システムとの統合が改善され、患者ケアが向上します。
-
コンプライアンスと報告:データ取り込みのプロセスには、さまざまなソースからデータを抽出、ロード、変換して分析に適した形式にすることが含まれます。組織は、規制要件を遵守し、正確な報告を促進するために、非構造化データを構造化形式に変換する必要がある場合があります。
-
市場調査:調査やフォーカスグループからの非構造化データを構造化データに変換することで、市場動向や消費者行動を分析するのに役立ちます。
AnyParserが非構造化データを構造化データにパースする方法
CambioMLが開発したAnyParserは、PDF、画像、チャートなどのさまざまな非構造化データソースから情報を抽出し、構造化形式に変換するための強力なドキュメントパースツールです。高度なビジョン言語モデル(VLM)を活用して、高い精度と効率でデータ抽出を実現します。
主な機能
-
精度:元のレイアウトと形式を維持しながら、テキスト、数値、記号を正確に抽出します。
-
プライバシー:データをローカルで処理し、ユーザーのプライバシーと機密情報を保護します。
-
設定可能性:ユーザーがカスタム抽出ルールと出力形式を定義できるようにします。
-
マルチソースサポート:PDF、画像、チャートなどのさまざまな非構造化データソースからの抽出をサポートします。
-
構造化出力:抽出された情報をMarkdown、CSV、JSONなどの構造化形式に変換します。
AnyParserを使用して非構造化データをパースする手順
-
ドキュメントをアップロード:AnyParserのWebインターフェースに非構造化データファイル(例:PDF、画像)をアップロードします。ファイルをドラッグ&ドロップするか、スクリーンショットを貼り付けて迅速に処理できます。
-
抽出オプションを選択:抽出したいデータの種類を選択します。たとえば、PDFからテーブルを抽出する必要がある場合は、「テーブルのみ」オプションを選択します。
-
ドキュメントを処理:AnyParserのAPIエンジンがドキュメントを処理し、必要な情報を正確に検出して抽出します。このツールは、高度なVLM技術を使用して関連するデータポイントを特定し、構造化形式に変換します。
-
プレビューと確認:AnyParserのプレビュー機能を使用して抽出されたデータを確認します。初期の抽出と元のドキュメントを比較して、正確性を確認します。
-
ダウンロードまたはエクスポート:抽出に満足したら、構造化データファイル(例:CSV、Excel)をダウンロードするか、Google Sheetsなどのプラットフォームに直接エクスポートします。
AnyParserを使用する利点
-
効率と精度:データ抽出タスクを自動化し、手動作業を削減し、エラーを最小限に抑えます。
-
データセキュリティ:機密情報がローカルで処理され、データプライバシー基準に準拠します。
-
柔軟なカスタマイズ:ユーザーは特定のニーズに合わせて抽出パラメータと出力形式を調整できます。
-
分析の焦点を強化:データ抽出を簡素化し、専門家がより価値の高い分析に集中できるようにします。
アプリケーション
-
AIエンジニア:PDFからテキストとレイアウト情報を抽出してAIモデルを開発および訓練します。
-
金融アナリスト:PDFテーブルから数値データを抽出して正確な財務分析を行います。
-
データサイエンティスト:大量の非構造化ドキュメントを処理して洞察やトレンドを発見します。
-
企業:契約書やレポートなどのさまざまなドキュメントの処理と分析を自動化し、運用効率を向上させます。
AnyParserを活用することで、ユーザーは複雑な非構造化データを構造化された編集可能なファイルに変換し、データ分析と管理のためにワークフローにシームレスに統合できます。
結論
デジタル時代において、AnyParserのようなツールを使用して非構造化データを構造化形式に変換することは、企業が洞察を解き放ち、競争優位性を得るために重要です。AnyParserは、非構造化補足サービスデータをパースするために利用でき、ビジネスインテリジェンスシステムへの統合を容易にします。このプロセスを効率化することで、組織はデータの完全な潜在能力を効率的に活用し、より良い意思決定と戦略的計画を推進できます。