In het domein van databeheer houdt parsing in het omzetten van de inhoud—zoals tekst, afbeeldingen, tabellen en metadata—naar een bruikbaar formaat (bijv. platte tekst, gestructureerde data of afbeeldingen) dat verder kan worden verwerkt of geanalyseerd. Dit is vooral duidelijk in het domein van PDF-parsing, waar we de wereld van parsing betreden, een cruciaal proces dat ruwe informatie transformeert in gestructureerde, bruikbare data. Deze uitgebreide gids duikt in de intricaties van PDF-parsing, verduidelijkt de definitie ervan, het spectrum van data dat het kan extraheren, de hindernissen die het tegenkomt, de veelzijdige toepassingen en de overvloed aan methoden die beschikbaar zijn om het volledige potentieel te benutten. Je zult verschillende parsingmethoden verkennen, met een bijzondere focus op PDF-parsing en hoe tools zoals AnyParser zich onderscheiden van de rest.
Begrijpen van PDF Parser: Wat is Parsing?
Wat is parsing: nauwkeurige datacapturering
In essentie verwijst PDF-parsing naar het proces van het extraheren en interpreteren van data uit PDF (Portable Document Format) bestanden. Aangezien PDF's voornamelijk zijn ontworpen voor weergave in plaats van gestructureerde dataopslag, houdt parsing in dat de inhoud—zoals tekst, afbeeldingen, tabellen en metadata—wordt omgezet naar een bruikbaar formaat (bijv. platte tekst, gestructureerde data of afbeeldingen) dat verder kan worden verwerkt of geanalyseerd. Parsing omvat een hoog niveau van analyse om specifieke elementen binnen een PDF te pinpointen en op te halen, en strekt zich verder uit dan alleen tekst en afbeeldingen naar lettertypen, lay-outs, tabellen en metadata. Dit proces is niet slechts een technische kwestie, maar een noodzaak in industrieën die zo divers zijn als financiën, recht, logistiek en gezondheidszorg, waar het hergebruik van informatie van groot belang is.
Data die uit PDF's kan worden Geparsed
De data die uit PDF's kan worden geëxtraheerd is gevarieerd en uitgebreid, waaronder:
-
Tekstparagrafen: Sequenties van woorden en tekens.
-
Enkele Gegevensvelden: Individuele elementen zoals datums, volgnummer en namen.
-
Tabulaire Data: Informatie georganiseerd in tabellen en lijsten.
-
Afbeeldingen: Grafische inhoud die in de PDF is ingebed.
-
Geavanceerde Elementen: Koppen, objecten, kruisverwijzingstabellen, trailers en metadata, die meer geavanceerde parsingtools vereisen.
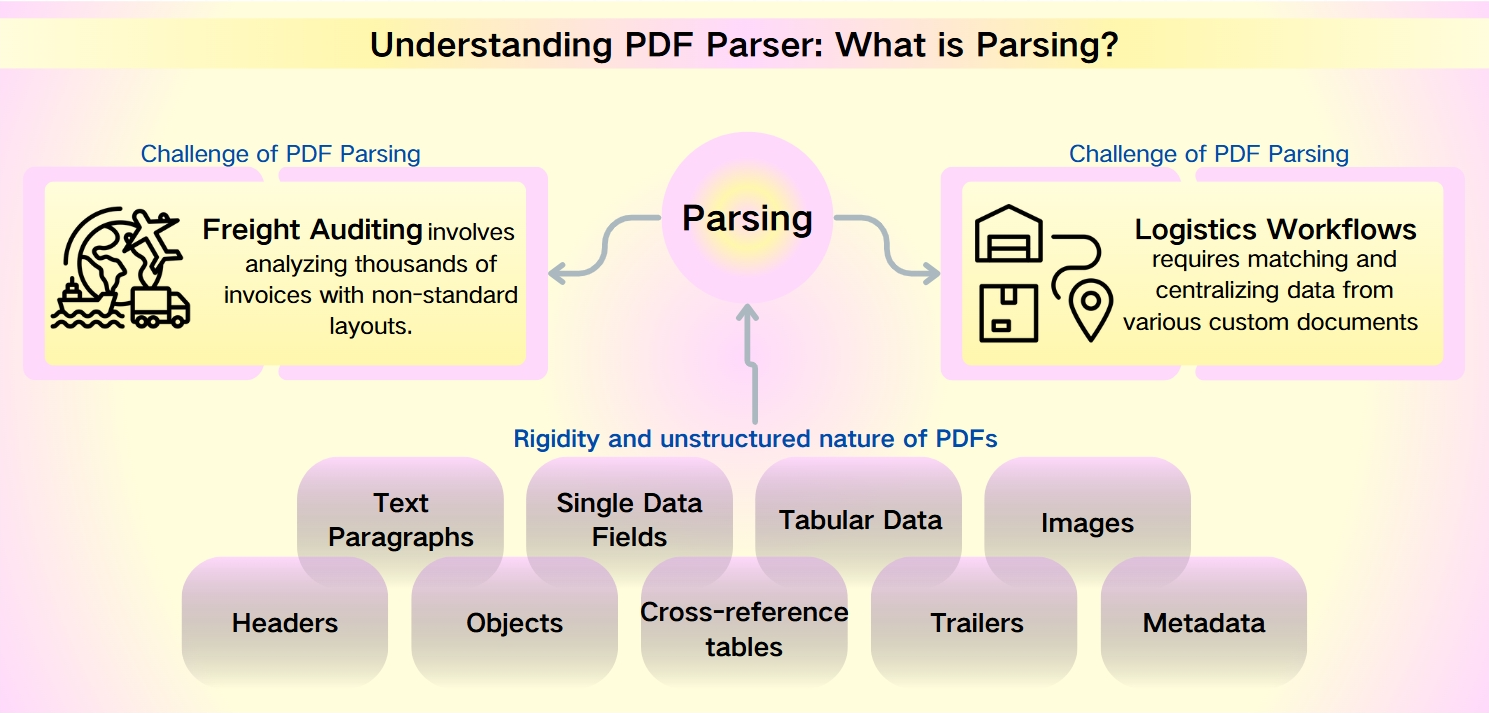
Uitdagingen van PDF Parsing: ongestructureerde aard van PDF metadata
Ondanks de robuustheid van PDF's—kenmerkend door hun beveiliging, apparaatcompatibiliteit en compacte bestandsgroottes—vormt het extraheren van data uit hen een aanzienlijke uitdaging. De rigiditeit en ongestructureerde aard van PDF's belemmeren snelle analyse en informatieophaling. Dit is vooral uitgesproken in scenario's zoals vrachtcontrole en logistieke workflows, waar niet-standaard lay-outs en volumineuze datasets de complexiteit vergroten.
Vrachtcontrole omvat het analyseren van duizenden facturen met niet-standaard lay-outs. Logistieke workflows vereisen het matchen en centraliseren van gegevens uit verschillende aangepaste documenten zoals paklijsten, commerciële facturen en vrachtbrieven.
Het Belang van Parsing
Parsing speelt een cruciale rol in verschillende velden, van webontwikkeling tot datacapturering. Het stelt bedrijven in staat waardevolle inzichten te extraheren uit ongestructureerde gegevensbronnen, zoals PDF-documenten, HTML-bestanden en XML-gegevens. Parsing faciliteert:
-
Verbeterde besluitvorming door datagestuurde inzichten.
-
Verhoogde data-accuraatheid en consistentie.
-
Gestroomlijnde gegevensverwerking en -analyse.
-
Efficiënte informatieophaling en -opslag.
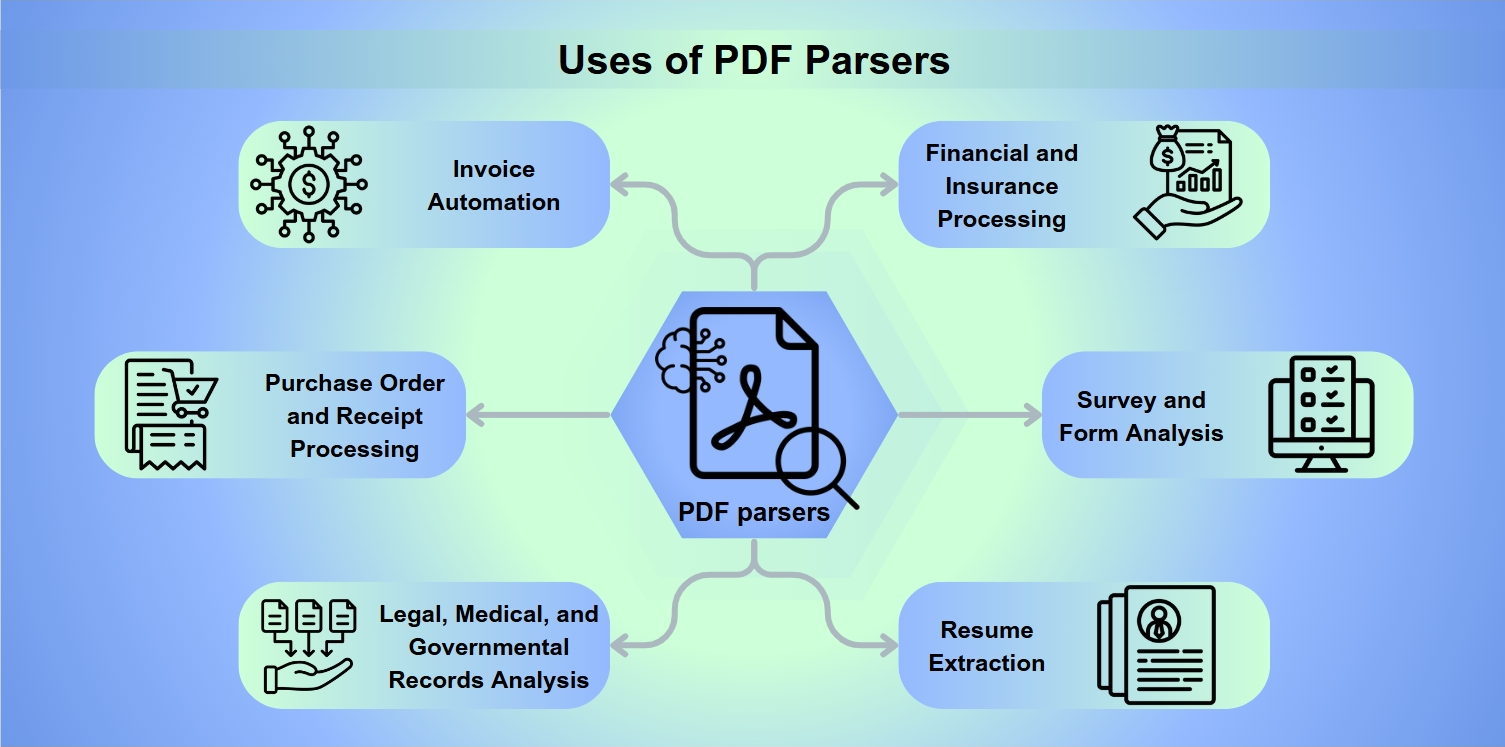
Toepassingen van PDF Parsers
PDF-parsers zijn onmisbare tools in een scala van toepassingen, waaronder:
-
Factuurautomatisering: Het stroomlijnen van de verwerking en betaling van facturen.
-
Verwerking van inkooporders en ontvangstbewijzen: Het vergemakkelijken van terugbetalingen en vergoedingen.
-
Analyse van juridische, medische en overheidsdocumenten: Het mogelijk maken van diepgaande data-extractie voor analyse.
-
Financiële en verzekeringsverwerking: Het beoordelen van risico's en het analyseren van balansen.
-
Enquête- en formulieranalyse: Het verzamelen en interpreteren van formulierreacties.
-
CV-extractie: Recruiters helpen bij het shortlist van kandidaten.
Vergelijking van Verschillende Parsingmethoden
Data parsingmethoden zijn in de loop der tijd aanzienlijk geëvolueerd. Traditionele benaderingen van datacapturering vertrouwen vaak op reguliere expressies (regex) om specifieke patronen uit tekst te extraheren. Hoewel krachtig, kan regex complex en moeilijk te onderhouden worden voor ingewikkelde parsingtaken. Een andere veelvoorkomende techniek is stringmanipulatie, waarbij tekst wordt gesplitst en verwerkt op basis van scheidingstekens of specifieke tekens. Deze methoden, hoewel nog steeds nuttig in bepaalde scenario's, kunnen moeite hebben met ongestructureerde of inconsistente gegevensformaten.
Het landschap van PDF-parsing wordt bediend door een verscheidenheid aan methoden, elk met zijn unieke voordelen en nadelen:
-
Online PDF-converters/parsers: Zoals Zamzar en Smallpdf, bieden gemak en snelheid maar zijn beperkt in functionaliteit en mogelijk onveilig.
-
Adobe Acrobat: Behoudt structuur en opmaak maar kan handmatige aanpassingen na conversie vereisen.
-
Kopiëren en plakken: Biedt volledige controle, maar is arbeidsintensief en foutgevoelig.
-
Geautomatiseerde platforms: Moderne parsingtechnologieën zoals AnyParser maken gebruik van machine learning en natuurlijke taalverwerking (NLP) om complexere datastructuren aan te pakken.
Deze AI-gedreven benaderingen kunnen context en semantiek begrijpen, waardoor ze bijzonder effectief zijn voor het parseren van ongestructureerde tekst of documenten met variërende indelingen. Sommige geavanceerde parsers maken gebruik van deep learning-modellen om relevante informatie met hoge nauwkeurigheid te identificeren en te extraheren, zelfs uit eerder ongeziene documentlay-outs.
Hoe PDF Parsing uit te Voeren: De Beste Gratis PDF Parser voor het Extraheren van PDF Metadata
Begrijpen van PDF Metadata
PDF-metadata bevat cruciale informatie over een document, waaronder de titel, auteur, aanmaakdatum en zoekwoorden. Het efficiënt extraheren van deze metadata is essentieel voor het organiseren, doorzoeken en beheren van grote verzamelingen PDF-bestanden. Een robuuste PDF-parser kan dit proces stroomlijnen, tijd besparen en de productiviteit van de workflow verbeteren.
Belangrijke Kenmerken van Top PDF Parsers
De beste gratis PDF-parsers bieden een combinatie van nauwkeurigheid, snelheid en veelzijdigheid. Ze moeten in staat zijn om verschillende PDF-formaten aan te kunnen, waaronder gescande documenten en die met complexe lay-outs. Zoek naar parsers die niet alleen basismetadata kunnen extraheren, maar ook aangepaste velden en verborgen informatie. Bovendien bieden top-tier parsers vaak opties voor pdf-data-extractors voor batchverwerking en integratie met andere softwaresystemen.
Kenmerken van AnyParser
AnyParser, ontwikkeld door CambioML, is bijzonder opmerkelijk vanwege zijn nauwkeurigheid, privacy en configureerbaarheid. De mogelijkheid van AnyParser om meerdere bestandsformaten aan te kunnen, de gebruiksvriendelijke interface en de schaalbaarheid maken het een uitstekende keuze voor bedrijven van elke omvang. Bovendien stelt de API een naadloze integratie in bestaande workflows mogelijk, waardoor de algehele efficiëntie van documentbeheer wordt verbeterd. Hier zijn enkele van de belangrijkste kenmerken die AnyParser een uitstekende keuze maken voor PDF-parsing:
-
Precisie: AnyParser is ontworpen om tekst, cijfers en symbolen nauwkeurig te extraheren terwijl de oorspronkelijke lay-out en opmaak behouden blijven. Het maakt gebruik van geavanceerde taalmiddelen om het begrip van documenten en informatie-extractie te verbeteren, met tot wel 2x hogere nauwkeurigheid vergeleken met traditionele OCR-modellen.
-
Privacy: Het ondersteunt zowel on-prem als cloud data parsing, waardoor gevoelige informatie privé en veilig blijft.
-
Configureerbaarheid: Gebruikers kunnen extractieregels en uitvoerformaten aanpassen aan specifieke behoeften.
-
Multi-source Ondersteuning: AnyParser ondersteunt een verscheidenheid aan documenttypes, waaronder PDF's, afbeeldingen en grafieken.
-
Gestructureerde Output: Geëxtraheerde informatie kan worden omgezet in gestructureerde formaten zoals Markdown, Excel of JSON, wat verdere verwerking en analyse vergemakkelijkt.
-
Cloud-gebaseerde Implementatieopties: AnyParser SDK kan in de cloud, datacenters of privé worden geïmplementeerd, wat flexibiliteit en schaalbaarheid biedt.
-
Gebruiksvriendelijke Interface: De tool biedt een eenvoudige API waarmee complexe documentparsingtaken met slechts een paar regels code kunnen worden uitgevoerd.
-
Hoge Prestatie: Geoptimaliseerde algoritmen zorgen voor snelle verwerking van een groot aantal documenten, 5X sneller dan gegeneraliseerde LLM's zoals GPT4o.
-
Gemeenschapssteun: Als een open-source project profiteert AnyParser van een actieve gemeenschap en verwelkomt bijdragen.
-
Gratis Gebruikskwantum: AnyParser biedt een gratis gebruikskwantum met elk account, zodat gebruikers de mogelijkheden van de tool kunnen testen voordat ze zich aan een betaald plan verbinden.
-
Klantfeedback: Gebruikers hebben AnyParser geprezen om zijn hoge nauwkeurigheid, privacybescherming en efficiëntie in data-extractie, met casestudy's die aanzienlijke tijdsbesparingen en verbeterde datakwaliteit aantonen.
Deze voordelen maken AnyParser een waardevolle pdf-data-extractor voor documentparsing en informatie-extractie, vooral voor zakelijke gebruikers die hoge precisie en beveiliging vereisen. Met voortdurende technologische vooruitgang en actieve betrokkenheid van de gemeenschap is AnyParser goed gepositioneerd om een steeds vitalere rol te spelen op het gebied van documentparsing en informatie-extractie.
Technische Uitleg van PDF Parsers
PDF-parsing deelt conceptuele grond met web scraping, maar mist de gestructureerde hiërarchie van HTML. Terwijl webdocumenten worden geparsed via toegankelijke HTML-tags, presenteren PDF's een platte array van tekens en pixels, wat meer geavanceerde algoritmen en bibliotheken voor data-extractie vereist.
PDF Parser vs Python PDF Parser: Belangrijkste Verschillen
Een PDF-parser is vaak een standalone tool als een pdf-data-extractor of bibliotheek die specifiek is ontworpen voor het extraheren van data uit PDF-bestanden. Deze parsers bieden doorgaans gebruiksvriendelijke interfaces en vereisen minimale programmeerkennis. Aan de andere kant zijn Python PDF-parsers modules of bibliotheken die in Python-scripts worden geïntegreerd, wat meer flexibiliteit biedt maar programmeerkennis vereist.
Ontwikkelaars kunnen het parsingproces verfijnen, geavanceerde tekstanalyse implementeren en PDF-data-extractie naadloos integreren in bredere Python-toepassingen. PDF-parsers, hoewel beperkter in maatwerk dan Python PDF-parsers, bieden vaak vooraf gebouwde functies voor veelvoorkomende gebruikssituaties, waardoor ze ideaal zijn voor gebruikers die snelle resultaten nodig hebben zonder uitgebreide programmering.
Voordelen van AnyParser met VLM voor Data Parsing
-
Hoge Precisie: De VLM's van AnyParser zorgen ervoor dat data-extractie hoge trouw behoudt, zelfs met complexe documentlay-outs.
-
Snelheid: Het leidt in conversiesnelheid, waardoor de productiviteit wordt verhoogd door de tijd die nodig is om documenten te verwerken te verminderen.
-
Gebruiksvriendelijk: AnyParser biedt een eenvoudige interface, waardoor het toegankelijk is voor gebruikers van alle niveaus.
-
Veelzijdigheid: Naast PDF's fungeert AnyParser als een krachtige afbeelding naar Excel-converter, die diverse documenttypes ondersteunt.
Conclusie
PDF-parsing is meer dan alleen een technisch proces; het is een toegangspoort tot het transformeren van hoe bedrijven omgaan met data. Ondanks de uitdagingen heeft de evolutie van softwareoplossingen het toegankelijker dan ooit gemaakt. Of je nu te maken hebt met factuurverwerking of complexe data-analyse, het kiezen van de juiste PDF-parser is essentieel. Het gaat erom de tool te vinden die de perfecte balans biedt tussen nauwkeurigheid, beveiliging en efficiëntie om je datagestuurde initiatieven te versterken.
Begin Vandaag Nog je Gratis Proefperiode
Klaar om je documentverwerking te revolutioneren? Probeer AnyParser GRATIS zonder creditcard vereist op https://www.cambioml.com/sandbox. De gratis proefperiode stelt je in staat om tot 10 pagina's per document te verwerken, met een maximale bestandsgrootte van 10 MB. Ervaar zelf hoe de PDF-parser van AnyParser je benadering van ongestructureerde data en documentextractie kan transformeren. Mis deze kans niet om je data-analysecapaciteiten te verbeteren en je workflow te stroomlijnen met state-of-the-art AI-technologie.