In de huidige datagestuurde wereld is het converteren van complexe documenten van PDF naar CSV-formaat een cruciale taak voor veel professionals. Als je worstelt met bankafschriften, medische rapporten of verzendorders in PDF-vorm, ben je waarschijnlijk op zoek naar een efficiënte oplossing.
Maak kennis met Vision Language Models (VLM's), een geavanceerde technologie die traditionele OCR-methoden overtreft. Door zowel visueel als contextueel begrip te benutten, bieden VLM's een krachtig hulpmiddel voor het transformeren van ingewikkelde, gestructureerde documenten in machineleesbare formaten.
Deze gids leidt je door het proces van het benutten van VLM's om je PDF's om te zetten in CSV- of Excel-bestanden met behulp van AnyParser, waardoor je workflow wordt gestroomlijnd en waardevolle gegevensinzichten worden vrijgemaakt. Met AnyParser kun je eenvoudig PDF naar CSV, PDF naar Excel converteren, of zelfs Word naar CSV converteren met slechts een paar klikken op onze Playground.
De sterke behoeften van PDF naar CSV-conversie en de beperkingen van traditionele OCR-modellen
De groeiende vraag naar PDF naar CSV-conversie
In de huidige datagestuurde wereld is de behoefte om PDF naar CSV te converteren steeds crucialer geworden. Bedrijven en individuen zijn op zoek naar efficiënte manieren om statische PDF-documenten om te zetten in dynamische, analyseerbare spreadsheets. Dit conversieproces is essentieel voor het extraheren van waardevolle informatie uit verschillende documenten zoals bankafschriften, medische rapporten en verzendorders. De mogelijkheid om Word naar Excel te converteren of een PDF naar CSV-converter te gebruiken, kan het databeheer en de analyseprocessen aanzienlijk stroomlijnen.
Tekortkomingen van conventionele OCR-technologie
Hoewel traditionele Optical Character Recognition (OCR)-modellen lange tijd zijn gebruikt voor teksterkenning, schieten ze vaak tekort bij het omgaan met complexe documenten. Deze beperkingen worden duidelijk wanneer geprobeerd wordt om ingewikkelde PDF's naar Google Sheets of andere spreadsheetformaten te converteren. OCR-systemen hebben moeite met:
- Het nauwkeurig interpreteren van scans of afbeeldingen van lage kwaliteit
- Het omgaan met meerkolomsindelingen en tabellen
- Het herkennen van diverse lettertypen en talen
- Het behouden van de oorspronkelijke documentstructuur
Deze uitdagingen benadrukken de behoefte aan meer geavanceerde oplossingen die het PDF naar CSV-conversieproces naadloos kunnen afhandelen, waarbij zowel de inhoud als de context van de oorspronkelijke documenten behouden blijft.
Stapsgewijze gids voor het converteren van PDF-documenten met AnyParser
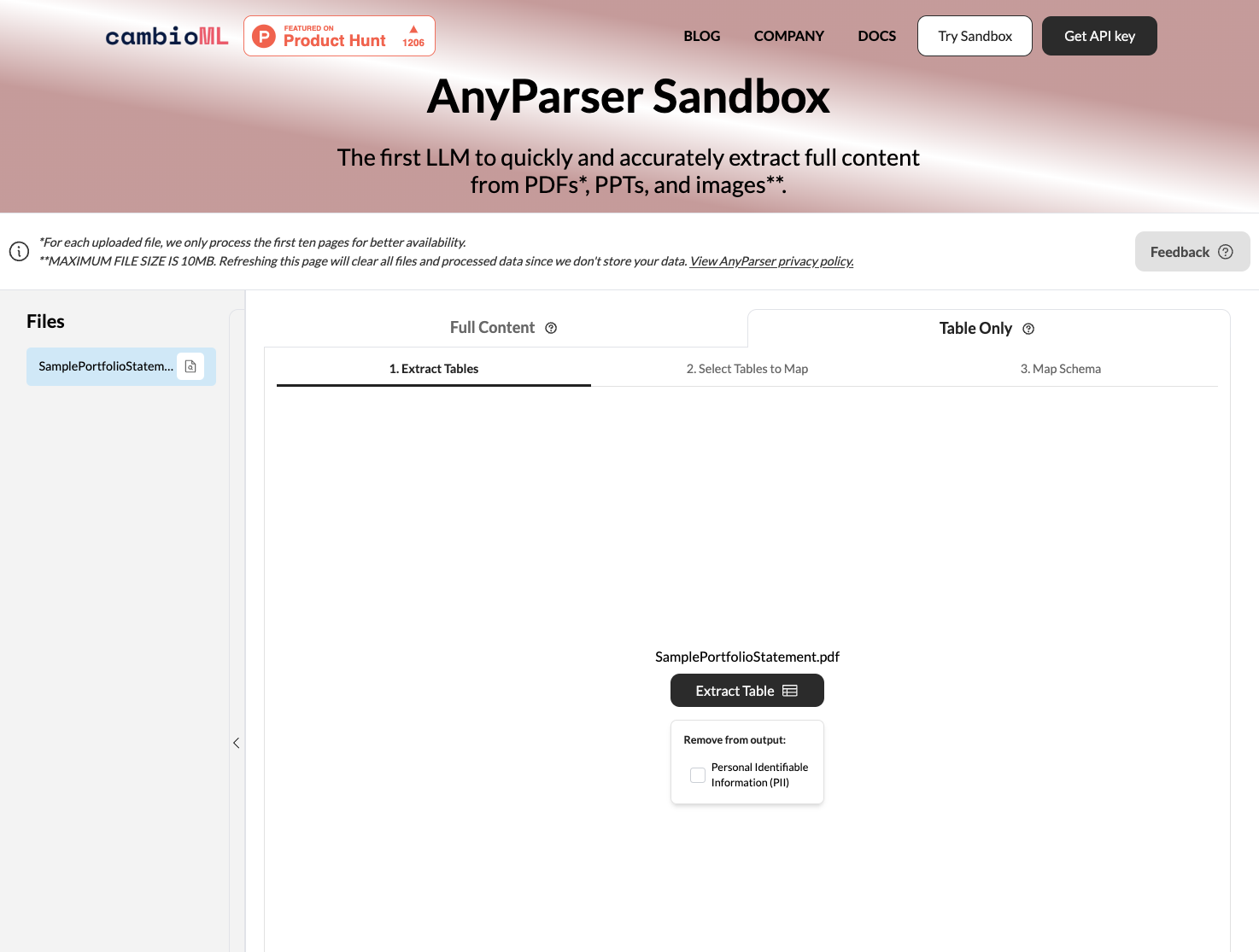
AnyParser is een krachtig PDF naar CSV-conversietool dat gebruikmaakt van geavanceerde Vision Language Models om nauwkeurig gegevens uit complexe PDF-documenten te extraheren. Hier zijn de basisstappen om AnyParser te gebruiken voor het converteren van je PDF-bestanden:
-
Upload je PDF of Word. Sleep je PDF-documenten eenvoudig naar de webinterface van AnyParser of plak de PDF-screenshot in de AnyParser UI.
-
Selecteer "Alleen Tabel" en klik op "Extract". De AnyParser API-engine detecteert automatisch de tabellen in de PDF en extrahert deze met hoge nauwkeurigheid. De geëxtraheerde gegevens worden opgeslagen in een .csv-bestand dat je kunt downloaden of met één klik naar Google Sheets kunt exporteren.
-
Voorbeeld en vergelijk. Bekijk de geëxtraheerde gegevens in de voorbeeldweergave om ervoor te zorgen dat deze aan je verwachtingen voldoen. Bekijk de initiële extractie van AnyParser en vergelijk deze zij aan zij in de UI.
-
Exporteer naar CSV of Excel. Zodra je tevreden bent met de extractie, download je het .csv-bestand om de gegevens in je eigen applicaties en systemen te gebruiken. De geëxtraheerde gegevens kunnen eenvoudig worden geïmporteerd in spreadsheets en databases voor verdere analyse.
Door deze eenvoudige stappen te volgen en de kracht van Vision Language Models te benutten, stelt AnyParser je in staat om zelfs de meest complexe PDF-documenten efficiënt om te zetten in gestructureerde, bewerkbare CSV-bestanden die je kunt analyseren en integreren in je workflows.
Bekijk deze video voor een stapsgewijze videodemonstratie!
Toepassingen van VLM voor PDF naar CSV/Excel-conversie in de echte wereld
Vision Language Models (VLM's) revolutioneren de manier waarop we PDF naar CSV en Excel-formaten converteren, en bieden krachtige oplossingen voor verschillende industrieën. Door deze geavanceerde modellen te benutten, kun je complexe documenten efficiënt omzetten in gestructureerde, machineleesbare gegevens.
Verwerking van financiële documenten
In de banksector excelleren VLM's in het converteren van PDF naar CSV voor bankafschriften. Deze modellen kunnen nauwkeurig transactiegegevens, rekeningnummers en saldo-informatie extraheren, zelfs uit documenten met ingewikkelde indelingen of meerdere valuta's. Deze mogelijkheid stroomlijnt financiële analyses en reconciliatieprocessen.
Beheer van medische dossiers
Voor zorgprofessionals bieden VLM's een onschatbaar hulpmiddel om Word naar Excel te converteren voor medische rapporten. Door complexe medische terminologie nauwkeurig te interpreteren en de structuur van laboratoriumresultaten te behouden, vergemakkelijken VLM's de creatie van uitgebreide patiëntendatabases. Deze transformatie maakt het gemakkelijker om trends te analyseren en de patiëntenzorg te verbeteren.
Optimalisatie van logistiek en supply chain
In de logistieke sector blinken VLM's uit bij het converteren van verzendorders van PDF naar Google Sheets. Deze modellen kunnen cruciale informatie extraheren, zoals afleveradressen, artikelbeschrijvingen en trackingnummers, waarbij de integriteit van tabulaire gegevens behouden blijft. Deze conversie maakt efficiënt voorraadbeheer en route-optimalisatie mogelijk.
Door gebruik te maken van een PDF naar CSV-converter aangedreven door VLM's, kun je de efficiëntie van gegevensverwerking in verschillende sectoren aanzienlijk verbeteren. Deze geavanceerde modellen bieden ongeëvenaarde nauwkeurigheid bij het omgaan met meertalige documenten, complexe indelingen en zelfs scans van lage kwaliteit, waardoor ze een onmisbaar hulpmiddel zijn voor moderne bedrijven.
Hoe Vision Language Models werken om OCR-uitdagingen te overwinnen
Vision Language Models (VLM's) revolutioneren de manier waarop we PDF naar CSV converteren en complexe documenten omzetten in machineleesbare formaten. In tegenstelling tot traditionele OCR, benutten VLM's zowel visueel als linguïstisch begrip om de meest uitdagende aspecten van documentconversie aan te pakken.
Interpreteren van complexe indelingen
VLM's excelleren in het ontcijferen van ingewikkelde documentstructuren, waardoor ze ideaal zijn voor het converteren van Word naar Excel of het omgaan met bankafschriften met verschillende indelingen. Door de ruimtelijke relaties tussen tekstelementen te analyseren, kunnen VLM's tabellen nauwkeurig reconstrueren en de integriteit van de indeling behouden. Bijvoorbeeld, VLM's kunnen een PDF met een factuur correct interpreteren die meerdere tabellen met verschillende aantallen kolommen en rijen bevat, terwijl conventionele OCR de rijen en kolommen in de war zal brengen.
Contextueel begrip
Een van de belangrijkste voordelen van VLM's is hun vermogen om de semantische betekenis van documentinhoud te begrijpen. Dit contextuele bewustzijn stelt nauwkeurigere extractie mogelijk bij het gebruik van een PDF naar CSV-converter, vooral voor domeinspecifieke documenten zoals medische CBC-rapporten of logistieke verzendorders. Bijvoorbeeld, VLM's kunnen medische rapporten correct classificeren op basis van hun inhoud, zelfs begrijpen dat "leukocyten" het aantal "witte bloedcellen (WBC's)" is!
Meertalige capaciteit
VLM's doorbreken taalbarrières door naadloos meerdere scripts en talen binnen een enkel document te verwerken. Dit maakt ze bijzonder nuttig voor internationale bedrijven die met diverse documenttypes werken. Bijvoorbeeld, VLM's kunnen gegevens extraheren uit een PDF met tekst in zowel het Engels als het Frans.
Ruisreductie
Scans of afbeeldingen van lage kwaliteit vormen vaak uitdagingen voor traditionele OCR-systemen. VLM's kunnen echter effectief ruis filteren en zich concentreren op relevante informatie, wat zorgt voor een hoge kwaliteit output bij het converteren van documenten naar Google Sheets of andere formaten. Bijvoorbeeld, VLM's kunnen nauwkeurig gegevens extraheren uit een vervaagde of vervaagde PDF-document.
Veelgestelde vragen over het converteren van PDF naar CSV met Vision Language Models
Hoe verschilt VLM-gebaseerde conversie van traditionele OCR?
Vision Language Models (VLM's) bieden aanzienlijke voordelen ten opzichte van traditionele OCR bij het converteren van PDF naar CSV of Excel. In tegenstelling tot OCR kunnen VLM's complexe indelingen nauwkeurig interpreteren, context begrijpen en meerdere talen naadloos verwerken. Dit maakt ze ideaal voor het converteren van bankafschriften, medische CBC-rapporten en logistieke verzendorders in machineleesbare formaten.
Welke soorten documenten werken het beste met VLM-conversie?
VLM's excelleren in het converteren van gestructureerde documenten met tabellen, grafieken en gemengde inhoud. Ze zijn bijzonder effectief voor financiële overzichten, medische rapporten en verzendmanifesten. De PDF naar CSV-converter aangedreven door VLM's kan de integriteit van tabellen behouden en gegevens extraheren uit zelfs scans van lage kwaliteit of complexe meertalige documenten.
Hoe nauwkeurig is VLM-gebaseerde conversie in vergelijking met handmatige gegevensinvoer?
VLM-gebaseerde oplossingen zoals AnyParser kunnen de nauwkeurigheid aanzienlijk verbeteren in vergelijking met handmatige gegevensinvoer of traditionele OCR. Door zowel visueel als contextueel begrip te benutten, kunnen deze tools fouten bij het converteren van Word naar Excel of PDF naar Google Sheets met tot 50% verminderen. Deze nauwkeurigheid is cruciaal voor het behouden van gegevensintegriteit in financiële, medische en logistieke toepassingen.
Kunnen VLM's verschillende bestandsindelingen naast PDF's verwerken?
Ja, geavanceerde VLM-gebaseerde tools kunnen verschillende bestandsindelingen verwerken. Terwijl PDF naar CSV-conversie gebruikelijk is, kunnen deze modellen ook gegevens extraheren uit afbeeldingen, Word-documenten, PowerPoint-presentaties en gescande documenten. Deze veelzijdigheid maakt VLM's een krachtige oplossing voor uitgebreide documentverwerkingsbehoeften in verschillende sectoren.
Conclusie
Wanneer je begint met het benutten van Vision Language Models voor PDF naar CSV-conversie, onthoud dan dat succes ligt in een goed gestructureerde aanpak. Door robuuste preprocessing, nauwkeurige documentclassificatie en grondige post-processing toe te passen, kun je het volledige potentieel van VLM's voor je gegevensextractiebehoeften benutten. Of je nu te maken hebt met complexe bankafschriften, ingewikkelde medische rapporten of gedetailleerde verzendorders, VLM's bieden een krachtige oplossing om ongestructureerde gegevens om te zetten in bruikbare inzichten. Omarm deze geavanceerde technologie om je workflows te stroomlijnen, de gegevensnauwkeurigheid te verbeteren en nieuwe mogelijkheden in documentverwerking te ontsluiten. Met VLM's tot je beschikking ben je goed uitgerust om zelfs de meest uitdagende PDF-conversietaken efficiënt en effectief aan te pakken.
Oproep tot actie
Laten we vooruitgaan door deze inzichten te implementeren. Overweeg om contact op te nemen met experts in Vision Language Models zoals het team van AnyParser om:
- Probeer AnyParser gratis om je PDF naar CSV te converteren op https://www.cambioml.com/sandbox
- Als je de voorkeur geeft aan een no-code ervaring om grote hoeveelheden PDF's naar Excel te converteren, kijk op https://www.energent.ai
- Krijg een gratis consult over hoe VLM's je gegevensextractieworkflow kunnen verbeteren
Het benutten van de volledige kracht van Vision Language Models vereist het gebruik van de ervaring en best practices van conversiespecialisten. Zet de volgende stap door contact op te nemen met brancheleiders om je overgang naar een meer geautomatiseerd, nauwkeurig en inzichtelijk gegevensextractieproces te versnellen.