Vision Language Models (VLM's) revolutioneren het gebied van documentanalyse en pakken veel van de beperkingen aan die inherent zijn aan traditionele Optical Character Recognition (OCR) systemen. Hoewel OCR een hoeksteen technologie is voor het digitaliseren van tekst uit afbeeldingen, staat het voor aanzienlijke uitdagingen in complexe scenario's. Deze omvatten nauwkeurigheidsproblemen met afbeeldingen van lage kwaliteit, beperkte contextuele begrip, moeilijkheden met gemengde talen en het onvermogen om visuele elementen te interpreteren. VLM's bieden een veelbelovende oplossing door geavanceerde computer vision te combineren met mogelijkheden voor natuurlijke taalverwerking. Dit artikel verkent hoe VLM's de tekortkomingen van OCR overwinnen en robuustere en veelzijdigere oplossingen bieden voor documentverwerking in het digitale tijdperk.
Wat is OCR? Wat zijn de processen van OCR in documentparsering?
Optical Character Recognition (OCR) is een technologie die de conversie mogelijk maakt van verschillende soorten documenten, zoals gescande papieren documenten, PDF-bestanden of afbeeldingen vastgelegd door een digitale camera, naar bewerkbare en doorzoekbare gegevens. Dit proces is cruciaal in documentverwerking en PDF-gegevensextractie, waardoor machines gedrukte of handgeschreven teksttekens in digitale afbeeldingen kunnen herkennen.
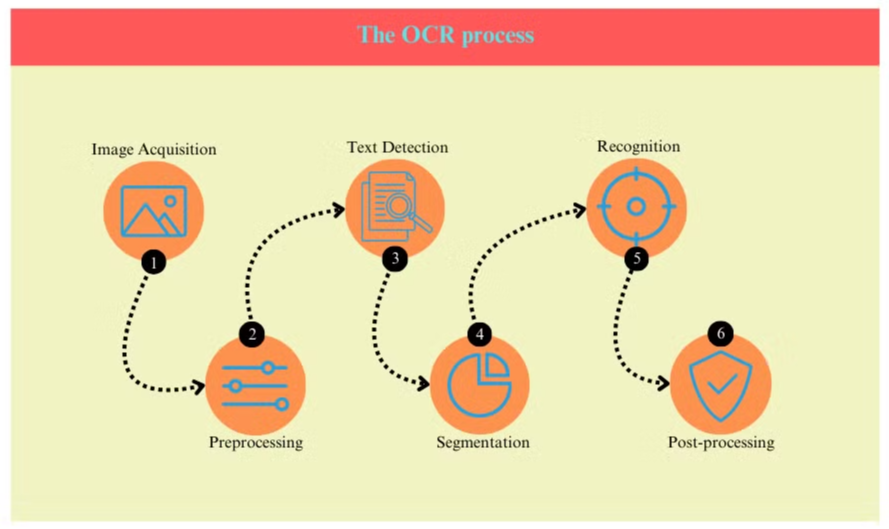
Het OCR-proces
Het OCR-proces omvat doorgaans verschillende stappen:
- Afbeeldingsverwerving: Het document wordt gescand of gefotografeerd om een digitale afbeelding te creëren.
- Voorverwerking: De afbeelding wordt opgeschoond, waarbij ruis wordt verwijderd en helderheid en contrast worden aangepast.
- Tekstdetectie: Het systeem identificeert gebieden die tekst bevatten binnen de afbeelding.
- Tekensegmentatie: Individuele tekens worden geïsoleerd binnen de tekstgebieden.
- Tekenherkenning: Elk teken wordt geanalyseerd en vergeleken met een database van bekende tekens.
- Nabehandeling: De herkende tekst wordt gecontroleerd op fouten met behulp van linguïstische en contextuele informatie.
Hoewel OCR de mogelijkheden voor documentparsering aanzienlijk heeft verbeterd, staat het nog steeds voor beperkingen bij het omgaan met complexe lay-outs, afbeeldingen van lage kwaliteit en verschillende lettertypen. Dit is waar geavanceerde technologieën zoals vision language models binnenkomen om de nauwkeurigheid en het begrip bij het extraheren van gegevens uit afbeeldingen en documenten te verbeteren.
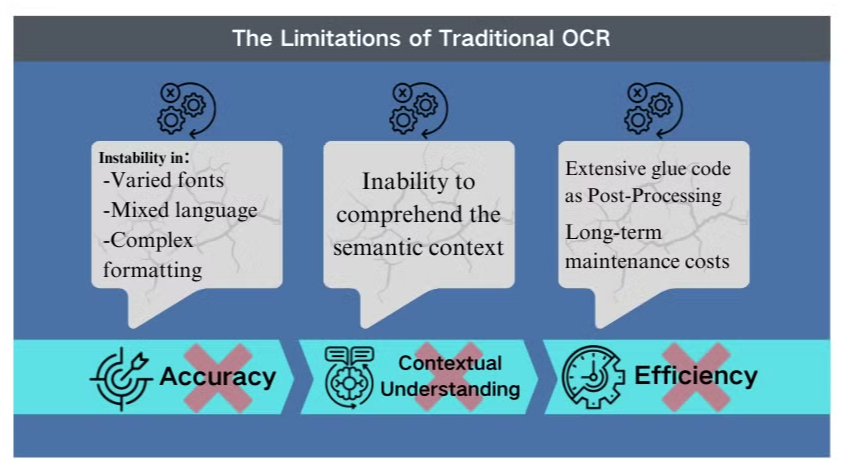
De Beperkingen van Traditionele OCR-technologie
Nauwkeurigheidsuitdagingen in Complexe Scenario's
Traditionele optical character recognition (OCR) technologie, hoewel nuttig voor basis tekstextractie, staat voor aanzienlijke obstakels wanneer geconfronteerd met ingewikkelde documentlay-outs of afbeeldingen van lage kwaliteit. Deze systemen hebben vaak moeite om de nauwkeurigheid te behouden bij het verwerken van documenten met verschillende lettertypen, gemengde talen of complexe opmaak. Bijvoorbeeld, OCR kan falen bij het proberen gegevens te extraheren uit afbeeldingsrijke presentaties of dicht opgemaakte PDF's.
Gebrek aan Contextueel Begrip
Een van de meest opvallende beperkingen van conventionele OCR is het onvermogen om de semantische context van de tekst die het verwerkt te begrijpen. Deze tekortkoming wordt bijzonder duidelijk in scenario's die een genuanceerde interpretatie vereisen, zoals juridische contracten of medische rapporten. De focus van OCR op tekenherkenning zonder contextueel bewustzijn kan leiden tot kritieke misinterpretaties, vooral bij het omgaan met ambiguïteit in tekens of branchespecifieke terminologie.
Inefficiënties in Nabehandeling
De beperkingen van OCR vereisen vaak uitgebreide nabehandelingsinspanningen. Deze extra stap kan de tijd en middelen die nodig zijn voor documentverwerking aanzienlijk verhogen. Bovendien schieten traditionele OCR-systemen vaak tekort wanneer ze worden belast met het extraheren van informatie uit grafieken, tabellen of andere niet-tekstuele elementen, wat het documentextractieproces verder bemoeilijkt. Deze inefficiënties benadrukken de noodzaak voor meer geavanceerde oplossingen, zoals vision language models, die een meer uitgebreide benadering van documentanalyse en gegevensextractie bieden.
Wat zijn Vision-Language Models en hoe verbeteren ze OCR
Vision language models vertegenwoordigen een significante sprong voorwaarts in documentverwerkingstechnologie, waarbij veel van de beperkingen van traditionele optical character recognition (OCR) systemen worden aangepakt. Deze geavanceerde modellen combineren computer vision met natuurlijke taalverwerking om zowel de visuele als tekstuele elementen van documenten gelijktijdig te begrijpen.
Verbeterde Nauwkeurigheid en Contextbegrip
In tegenstelling tot OCR, dat moeite heeft met afbeeldingen van lage kwaliteit en complexe lay-outs, excelleren vision language models in het interpreteren van diverse documentformaten. Ze kunnen nauwkeurig gegevens extraheren uit afbeeldingen, PDF's en andere visuele inhoud, zelfs wanneer ze worden geconfronteerd met uitdagende scenario's. Deze verbeterde nauwkeurigheid komt voort uit hun vermogen om de gehele context van een document in overweging te nemen, in plaats van zich uitsluitend te concentreren op individuele tekens of woorden.
Uitgebreide Gegevensextractie
Vision language models gaan verder dan eenvoudige tekstherkenning en bieden uitgebreide mogelijkheden voor PDF-gegevensextractie. Ze kunnen tabellen, grafieken en figuren binnen documenten identificeren en interpreteren, waarbij de integriteit van complexe lay-outs behouden blijft. Deze holistische benadering van documentanalyse maakt een meer genuanceerde en complete informatieverzameling mogelijk, wat de bruikbaarheid van geëxtraheerde gegevens voor downstream-toepassingen aanzienlijk verbetert.
Meertalige en Multi-format Vaardigheid
Een van de belangrijkste voordelen van vision language models is hun flexibiliteit in het omgaan met meerdere talen en documentformaten. In tegenstelling tot OCR-systemen die moeite kunnen hebben met niet-Latijnse scripts of gemengde taaldocumenten, kunnen deze modellen naadloos inhoud verwerken in verschillende talen en scripts, waardoor ze van onschatbare waarde zijn voor wereldwijde documentverwerkingsbehoeften.
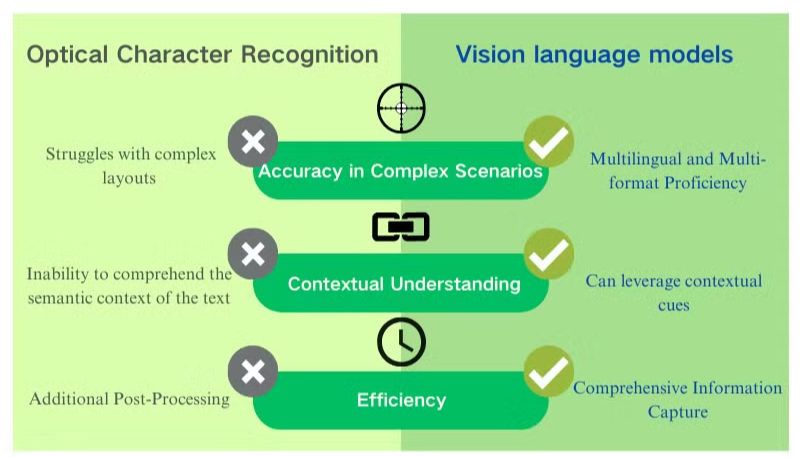
Belangrijke Voordelen van Vision-Language Models voor Documentbegrip
Vision language models bieden aanzienlijke voordelen ten opzichte van traditionele OCR voor documentverwerking en gegevensextractie. Deze AI-gestuurde systemen combineren visueel en tekstueel begrip om superieure resultaten te leveren voor verschillende documenttypes.
Verbeterde Nauwkeurigheid en Contextueel Begrip
Vision language models excelleren in het omgaan met complexe lay-outs, afbeeldingen van lage kwaliteit en diverse lettertypen. In tegenstelling tot OCR, dat moeite heeft met ambiguïteit in tekens, maken deze modellen gebruik van contextuele aanwijzingen om tekst nauwkeurig te interpreteren. Deze capaciteit verbetert de nauwkeurigheid van PDF-gegevensextractie aanzienlijk, vooral voor documenten met ingewikkelde structuren of slechte beeldkwaliteit.
Uitgebreide Informatie Vastlegging
Terwijl OCR zich uitsluitend richt op tekstherkenning, kunnen vision language models gegevens extraheren uit afbeeldingen, tabellen en grafieken. Deze holistische benadering zorgt ervoor dat kritieke informatie niet over het hoofd wordt gezien tijdens de documentverwerkingsfase. Door zowel tekstuele als visuele elementen vast te leggen, bieden deze modellen een completer begrip van de inhoud van documenten.
Meertalige en Multi-format Vaardigheid
Vision language models tonen opmerkelijke flexibiliteit in het verwerken van documenten in verschillende talen en formaten. Ze kunnen naadloos omgaan met gemengde taaldocumenten en niet-Latijnse scripts, wat een aanzienlijke beperking van traditionele OCR-systemen overwint. Deze veelzijdigheid maakt ze van onschatbare waarde voor wereldwijde ondernemingen die met diverse documenttypes en talen werken.
Toepassingen in de Praktijk Mogelijk Gemaakt door VLM die OCR niet kon
Vision language models revolutioneren documentverwerking in de financiën, human resources en andere sectoren door kritieke beperkingen van traditionele OCR-systemen aan te pakken. Deze geavanceerde AI-modellen transformeren digitale transformatie-inspanningen in verschillende industrieën door superieure nauwkeurigheid en contextueel begrip te bieden.
Revolutie in de Verwerking van Financiële Documenten
Vision language models transformeren documentverwerking in de financiën en overwinnen de beperkingen van traditionele OCR. Deze geavanceerde modellen excelleren in het extraheren van gegevens uit complexe financiële overzichten, facturen en ontvangstbewijzen met ingewikkelde lay-outs. In tegenstelling tot OCR kunnen ze de context begrijpen, ambiguïteit in tekens nauwkeurig interpreteren (bijv. het onderscheiden van een nul en de letter O) en gemengde talen die vaak in wereldwijde financiële documenten aanwezig zijn.
Verbetering van HR-Operaties door Intelligente Documentanalyse
In de HR-sector blijken vision language models van onschatbare waarde voor PDF-gegevensextractie uit cv's, werknemersdossiers en prestatiebeoordelingen. Deze modellen kunnen de semantische structuur van documenten begrijpen, wat zorgt voor nauwkeurigere informatieverzameling en -analyse. Deze capaciteit stroomlijnt het wervingsproces en het beheer van werknemersgegevens aanzienlijk, taken waarbij OCR vaak moeite heeft met verschillende formaten en handgeschreven notities.
Verbetering van Compliance en Risicobeheer
Vision-language models zijn bijzonder effectief in compliance en risicobeheer in zowel financiën als HR. Ze kunnen kritieke informatie extraheren en interpreteren uit regelgevende documenten, contracten en beleidslijnen met grotere nauwkeurigheid dan OCR. Deze verbeterde documentverwerkingscapaciteit zorgt voor een betere naleving van wettelijke vereisten en efficiëntere risicobeoordelingsprocedures.
Conclusie
Samenvattend vertegenwoordigen vision language models een significante sprong voorwaarts in documentverwerkingstechnologie, waarbij veel van de inherente beperkingen van traditionele OCR-systemen worden aangepakt. Door visueel en tekstueel begrip te combineren, bieden deze geavanceerde modellen superieure prestaties in een breed scala aan uitdagende scenario's, van complexe lay-outs tot gemengde talen en afbeeldingen van lage kwaliteit. Terwijl organisaties hun operaties blijven digitaliseren en efficiëntere manieren zoeken om waarde uit hun documentrepositories te extraheren, komen vision language models naar voren als een krachtig hulpmiddel voor ontwikkelaars en engineeringleiders. Hun vermogen om context te begrijpen, diverse formaten te verwerken en nauwkeurigere resultaten te leveren, positioneert hen als een belangrijke enabler voor geavanceerde RAG-pijplijnen en enterprise-wide zoekcapaciteiten, wat uiteindelijk digitale transformatie-initiatieven naar nieuwe hoogten drijft.