Heb je je ooit afgevraagd waar OCR voor staat? Optical Character Recognition is een krachtige technologie die afbeeldingen van tekst omzet in machine-leesbare gegevens. Hoewel OCR enorme voordelen biedt voor het digitaliseren van documenten en het extraheren van informatie, zijn er ook nadelen. Terwijl je deze technologie verkent, is het cruciaal om zowel de mogelijkheden als de beperkingen te begrijpen. In dit artikel ontdek je de betekenis van OCR en duik je in de mogelijke nadelen. Door een uitgebreid begrip van Optical Character Recognition te krijgen, ben je beter uitgerust om te bepalen of en hoe je deze technologie in je eigen workflows en projecten kunt implementeren.
Wat betekent OCR en wat is een OCR?
Wat betekent OCR?
OCR staat voor Optical Character Recognition, een technologie die computers in staat stelt om verschillende soorten documenten te herkennen en om te zetten. In wezen is OCR het proces van het scannen van gedrukt of handgeschreven tekst en het omzetten ervan in machine-gecodeerde tekst. Dit maakt de tekst doorzoekbaar, bewerkbaar en eenvoudig overdraagbaar. Begrijpen wat OCR betekent, is essentieel voor iedereen die werkt met document scanning en tekstherkenningstechnologieën.
Wat is een OCR?
Voor degenen die niet bekend zijn met de term, is "wat is een OCR" een veelgestelde vraag, die verwijst naar Optical Character Recognition, een technologie die computers in staat stelt om tekst uit afbeeldingen of gescande documenten te lezen.
OCR zet gedrukt of handgeschreven tekst om in machine-leesbare gegevens, waardoor de kloof tussen papier en digitale formaten wordt overbrugd. Deze technologie maakt gebruik van geavanceerde algoritmen om lettervormen, woordstructuren en zelfs hele zinnen te detecteren. Hierdoor transformeert het statische afbeeldingen in bewerkbare en doorzoekbare tekstbestanden.
OCR-technologie is fundamenteel gebaseerd op computer vision en patroonherkenningstechnologieën. OCR staat voor het scannen van documenten of afbeeldingen die tekst bevatten en het gebruik van geavanceerde algoritmen om de tekst te identificeren en om te zetten in een digitaal, bewerkbaar formaat. Een van de belangrijkste momenten in de geschiedenis van OCR-technologie was in 1974, toen Ray Kurzweil een omni-font OCR-systeem ontwikkelde dat tekst in vrijwel elk lettertype kon herkennen. In de loop der jaren is OCR geëvolueerd van eenvoudige sjabloonmatching naar meer geavanceerde systemen.
Ondanks zijn mogelijkheden staat OCR-technologie momenteel voor bepaalde beperkingen. Deze omvatten uitdagingen bij het herkennen van tekst in afbeeldingen van slechte kwaliteit, moeilijkheden bij het omgaan met complexe lay-outs of achtergronden, en variërende nauwkeurigheid bij het omgaan met verschillende lettertypen, talen of handschriften. Bovendien kunnen OCR-systemen moeite hebben met documenten die gekleurde achtergronden hebben, wazig of scheef zijn, en met cursief handschrift.
Begrijpen van Optical Character Recognition-software
Optical Character Recognition-software is een transformerende technologie die verschillende soorten documenten omzet in bewerkbare en doorzoekbare gegevens. Het speelt een cruciale rol in het digitaliseren van onze wereld, waardoor informatie toegankelijker en beheersbaarder wordt. OCR-software maakt gebruik van een geavanceerd proces om afbeeldingen van tekst om te zetten in machine-leesbare gegevens.
Hoe werkt OCR-software?
1. Afbeeldingsacquisitie
De reis van OCR begint met het vastleggen van een afbeelding van het document. Dit kan worden gedaan met een scanner of een digitale camera. De afbeelding wordt vervolgens omgezet in een digitaal formaat dat een computer kan verwerken.
2. Voorverwerking en afbeeldingsverbetering
De tweede stap omvat het verbeteren van de afbeeldingskwaliteit. Zodra de afbeelding is verkregen, ondergaat deze voorverwerking om de kwaliteit te verbeteren voor een betere herkenning. Deze stap kan het aanpassen van het contrast, de helderheid en de scherpte van de afbeelding omvatten, evenals het verwijderen van ruis of irrelevante elementen. Deze voorverwerkingsfase is cruciaal voor het bereiken van nauwkeurige resultaten, vooral bij het omgaan met scans of foto's van lage kwaliteit.
3. Tekstdetectie
OCR-software analyseert de voorverwerkte afbeelding om gebieden te detecteren die tekst bevatten. Dit doet het door te zoeken naar patronen en vormen die kenmerkend zijn voor tekst, zoals lijnen van verschillende diktes en hoogtes.
4. Tekensegmentatie
Zodra tekstgebieden zijn gedetecteerd, breekt de software de tekst op in kleinere eenheden, zoals blokken, regels, woorden of zelfs individuele tekens. OCR-software analyseert de afbeelding pixel voor pixel om patronen te identificeren die tekens vormen. Het splitst de afbeelding op in kleinere segmenten en isoleert elk teken.
5. Tekstherkenning en extractie
De software vergelijkt deze geïsoleerde vormen met een enorme database van bekende tekenpatronen om te bepalen wat elk teken is. De software extraheert kenmerken van de tekens, zoals het aantal lijnen, krommingen of hoeken. Deze kenmerken helpen de OCR om verschillende tekens te herkennen en van elkaar te onderscheiden.
6. Post-processing
Nadat de tekens zijn geïdentificeerd, doorloopt het OCR-systeem een post-processing fase waarin eventuele potentiële fouten worden gecorrigeerd en de tekst wordt opgemaakt voor output. De gecorrigeerde tekst wordt vervolgens geëxporteerd naar het gewenste formaat, zoals een Word-document of een doorzoekbare PDF.
Toepassingen van Optical Character Recognition-software
OCR is een essentieel hulpmiddel geworden in de digitale transformatie van veel industrieën, waarbij processen worden gestroomlijnd en de toegankelijkheid en nauwkeurigheid van gegevens worden verbeterd. Je komt OCR misschien vaker tegen dan je denkt. Van het scannen van visitekaartjes tot het digitaliseren van oude boeken, OCR speelt een cruciale rol in verschillende sectoren. OCR-technologie heeft een breed scala aan toepassingen:
-
Documentdigitalisering: OCR wordt gebruikt om gedrukte materialen zoals oude boeken, kranten en historische documenten om te zetten in digitale formaten, waardoor ze doorzoekbaar worden en voor toekomstige generaties worden bewaard.
-
Formulierverwerking: Bedrijven maken gebruik van OCR om automatisch gegevens uit formulieren te extraheren, wat handmatige gegevensinvoer vermindert en de efficiëntie in verschillende sectoren zoals financiën en gezondheidszorg verhoogt.
-
Factuurverwerking: OCR-technologie kan tekst op facturen lezen en automatisch de gegevens invoeren in financiële systemen, waardoor boekhoud- en administratieprocessen worden gestroomlijnd.
-
Toegankelijkheid: OCR maakt tekst-naar-spraakfunctionaliteit mogelijk, waardoor audioversies van tekst worden gemaakt voor visueel gehandicapte personen, waardoor gedrukte materialen toegankelijker worden.
-
Mobiele applicaties: OCR is geïntegreerd in apps voor taken zoals het scannen van visitekaartjes, het herkennen van tekst in foto's en het faciliteren van realtime vertalingen.
-
Doorzoekbaarheid: OCR verbetert de doorzoekbaarheid van gescande documenten door tekst uit afbeeldingen of PDF's te extraheren, waardoor het gemakkelijk is om informatie op te zoeken en te vinden.
-
Kentekenherkenning: Gebruikt voor parkeer- en verkeersbeheer, kan OCR kentekens herkennen, waardoor efficiënte monitoring en handhaving mogelijk is.
-
Bedrijfsvoering: OCR stroomlijnt bedrijfsprocessen door gegevensinvoer uit documenten zoals facturen, ontvangstbewijzen en inkooporders te automatiseren, evenals het versnellen van wervingsprocessen door sollicitaties en cv's te scannen en te verwerken.
-
Juridische en gezondheidszorgsectoren: Advocatenkantoren gebruiken OCR om zaakdossiers en juridische documenten te digitaliseren voor eenvoudigere informatieopslag, terwijl zorgverleners het gebruiken om patiëntendossiers en medische formulieren om te zetten in elektronische gezondheidsdossiers (EHR's), wat de gegevensbeheer en patiëntenzorg verbetert.
-
Onderwijs: In educatieve instellingen wordt OCR gebruikt om digitale leerboeken en leermaterialen te creëren, waardoor de toegankelijkheid voor studenten met diverse behoeften wordt verbeterd en een inclusieve leeromgeving wordt ondersteund.
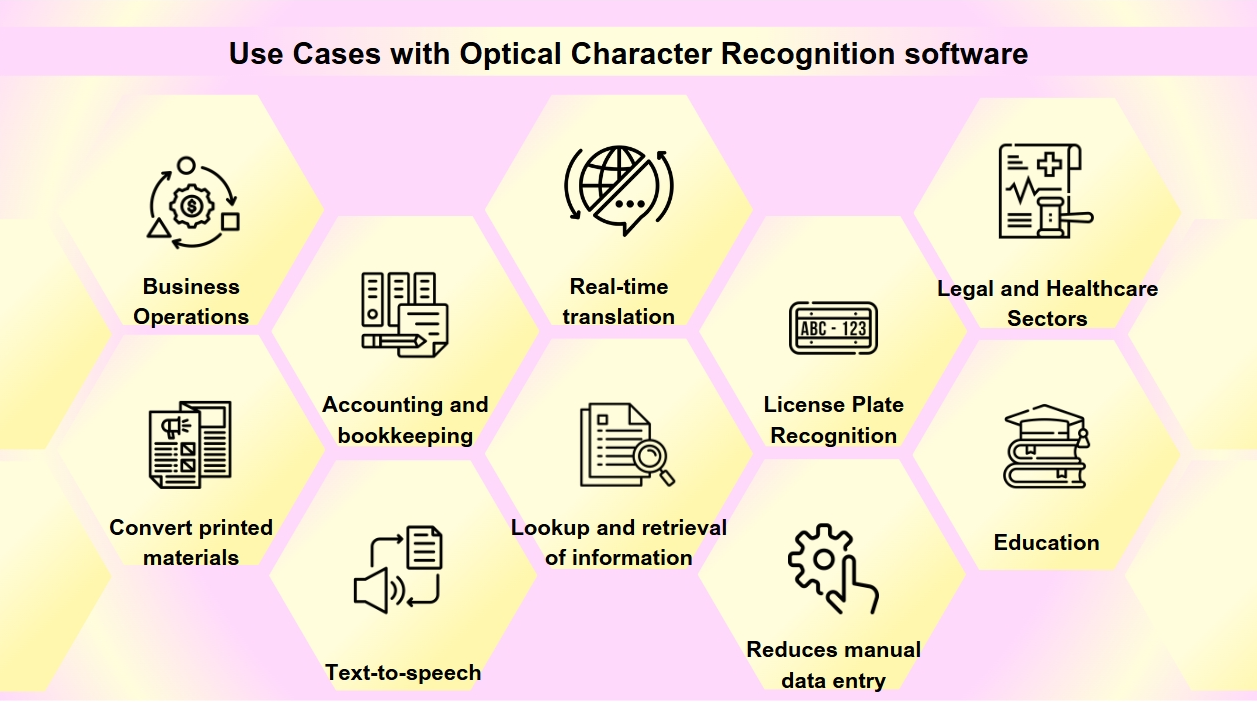
Naarmate OCR-technologie vordert, blijft het een vitale rol spelen in het toegankelijker en efficiënter maken van informatie in het digitale tijdperk.
De nadelen van OCR: Beperkingen en tekortkomingen
Nauwkeurigheidsuitdagingen
Hoewel Optical Character Recognition (OCR) technologie een lange weg heeft afgelegd, staat het nog steeds voor aanzienlijke obstakels bij het bereiken van perfecte nauwkeurigheid. Handgeschreven tekst, ongebruikelijke lettertypen of afbeeldingen van slechte kwaliteit kunnen leiden tot misinterpretaties en fouten. Zelfs kleine variaties in de vormen of groottes van tekens kunnen OCR-systemen in verwarring brengen, wat resulteert in onleesbare output die handmatige correctie vereist.
Taal- en formaatbeperkingen
De meeste OCR-oplossingen presteren goed met standaardtalen en -formaten, maar hebben moeite met gespecialiseerde inhoud. Technische documenten, wiskundige vergelijkingen of teksten met meerdere talen kunnen aanzienlijke uitdagingen opleveren. Bovendien kan OCR falen wanneer het wordt geconfronteerd met complexe lay-outs, tabellen of documenten met ingewikkelde opmaak, waardoor cruciale structurele informatie verloren kan gaan.
Hulpbronnenintensiteit
Het implementeren en onderhouden van een effectief OCR-systeem kan hulpbronnenintensief zijn. Hoogwaardige OCR-software gaat vaak gepaard met een stevig prijskaartje, en de hardware die nodig is om grote volumes documenten te verwerken kan kostbaar zijn. Bovendien kan de tijd en moeite die nodig zijn om personeel op te leiden, het systeem te optimaliseren en de output van OCR handmatig te controleren en te corrigeren, de middelen van de organisatie onder druk zetten.
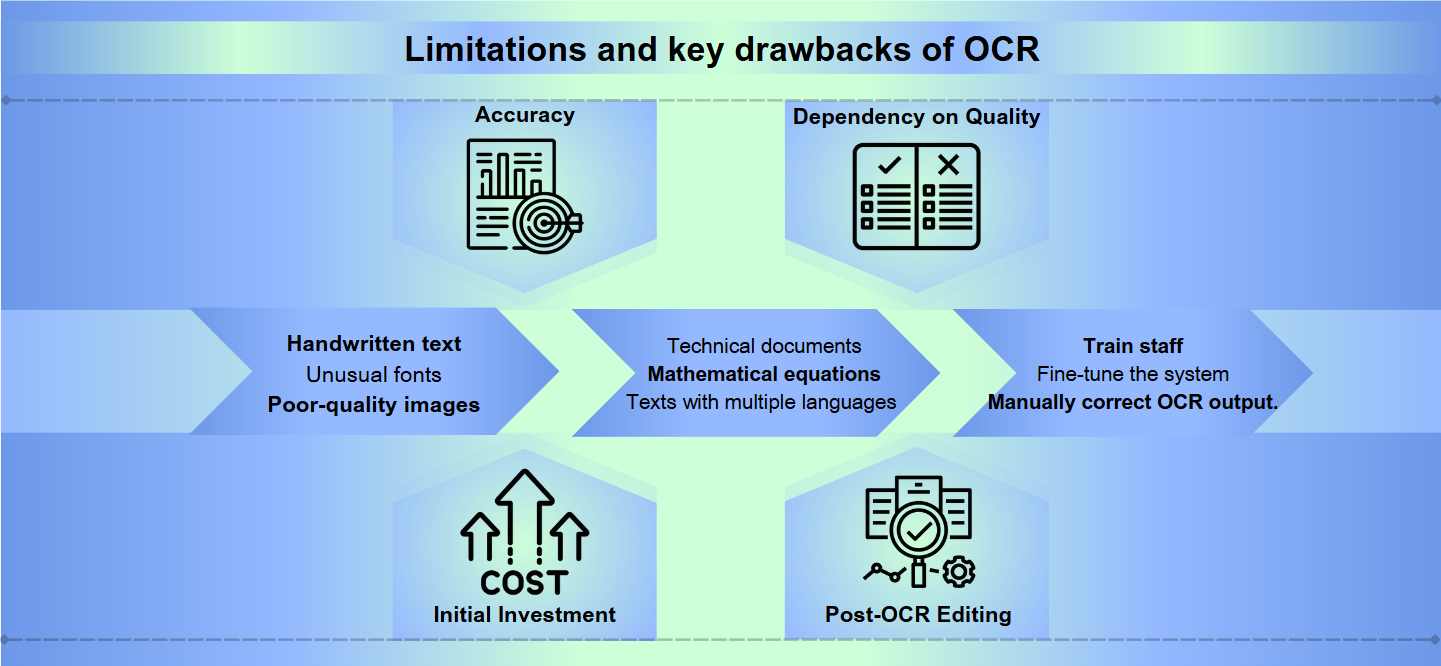
Belangrijkste nadelen van OCR
-
Nauwkeurigheid: OCR-software kan moeite hebben met nauwkeurigheid, vooral bij het omgaan met afbeeldingen van slechte kwaliteit, complexe lay-outs of handgeschreven tekst. Fouten kunnen variëren van het verkeerd lezen van tekens tot het overslaan van hele tekstgedeelten.
-
Afhankelijkheid van kwaliteit: De effectiviteit van OCR is sterk afhankelijk van de kwaliteit van het oorspronkelijke document. Vervaagde inkt, vlekken of gekreukt papier kunnen leiden tot onnauwkeurige vertalingen.
-
Initiële investering: Het opzetten van een OCR-systeem kan een aanzienlijke initiële investering vereisen, inclusief niet alleen de software, maar ook compatibele hardware zoals scanners.
-
Post-OCR-bewerking: Vaak vereist de output van OCR-processen handmatige controle en correctie, wat tijdrovend kan zijn.
Vision Language Model overwint de beperkingen van OCR
Naarmate de technologie vordert, komen er innovatieve oplossingen naar voren om de tekortkomingen van traditionele Optical Character Recognition (OCR) aan te pakken. Een dergelijke doorbraak is het Vision Language Model (VLM), dat computer vision en natuurlijke taalverwerking combineert om tekstextractie en -begrip te revolutioneren.
Verbeterd contextueel begrip
VLM's zijn uitstekend in het begrijpen van de context rondom tekst, in tegenstelling tot de geïsoleerde tekenherkenning van OCR. Door visuele elementen naast tekst te analyseren, kunnen deze modellen complexe lay-outs, handgeschreven notities en zelfs gedeeltelijk verborgen tekst met opmerkelijke nauwkeurigheid interpreteren.
Meertalige en multimodale mogelijkheden
Terwijl OCR vaak moeite heeft met diverse talen en scripts, tonen VLM's indrukwekkende veelzijdigheid. Ze kunnen naadloos meerdere talen verwerken en zelfs visuele inhoud zoals diagrammen of grafieken interpreteren, wat een meer omvattend begrip van documenten biedt.
Adaptief leren en continue verbetering
In tegenstelling tot statische OCR-systemen maken VLM's gebruik van machine learning om zich aan te passen en in de loop van de tijd te verbeteren. Terwijl ze nieuwe gegevens en scenario's tegenkomen, verfijnen deze modellen hun prestaties en worden ze steeds beter in het omgaan met verschillende documenttypes en -formaten.
Door de beperkingen van OCR te overwinnen, banen Vision Language Models de weg voor nauwkeuriger, efficiënter en intelligenter documentverwerking in verschillende sectoren.
Kies Vision Language Model: Probeer AnyParser
Bouwend op de vooruitgangen van Vision Language Models (VLM), komt AnyParser naar voren als een geavanceerde oplossing die de beperkingen van traditionele OCR-technologie overstijgt. Ontwikkeld door het CambioML-team, is AnyParser een krachtige documentparser die een nauwkeurige en configureerbare API gebruikt om informatie uit verschillende ongestructureerde gegevensbronnen zoals PDF's, afbeeldingen en grafieken te extraheren en deze om te zetten in gestructureerde formaten.
Technische basis en mogelijkheden
AnyParser is verankerd op de robuuste basis van grote taalmodellen (LLM's), wat zorgt voor hoge nauwkeurigheid bij het extraheren van tekst, tabellen, grafieken en lay-out uit documenten. Het valt op door zijn vermogen om de oorspronkelijke lay-out en opmaak te behouden, een functie die bijzonder nuttig is voor documenten met complexe lay-outs of die de oorspronkelijke esthetiek vereisen.
Privacy en beveiliging
Met de nadruk op gebruikersprivacy verwerkt AnyParser gegevens lokaal, waardoor gevoelige informatie wordt beschermd. Deze functie is een aanzienlijk voordeel voor bedrijven en individuen die met vertrouwelijke gegevens werken.
Aanpasbaarheid en flexibiliteit
AnyParser biedt een hoge mate van configureerbaarheid, waardoor gebruikers aangepaste extractieregels kunnen instellen en outputformaten kunnen definiëren die aan hun specifieke behoeften voldoen. Deze aanpasbaarheid maakt het een ideaal hulpmiddel voor een breed scala aan toepassingen, van AI-engineering tot financiële analyse.
Conclusie
Zoals je hebt geleerd, biedt OCR-technologie krachtige mogelijkheden voor het digitaliseren van tekst, maar het is niet zonder beperkingen. Hoewel optische tekenherkenning de efficiëntie aanzienlijk kan verbeteren, moet je de potentiële nadelen zorgvuldig afwegen. Overweeg de nauwkeurigheidsproblemen, opmaakuitdagingen en hulpbronnenvereisten voordat je een OCR-oplossing implementeert. Uiteindelijk hangt de beslissing om OCR te gebruiken af van jouw specifieke behoeften en omstandigheden. Door zowel de voordelen als de nadelen te begrijpen, kun je een weloverwogen keuze maken over de vraag of OCR geschikt is voor jouw organisatie. Terwijl OCR blijft evolueren, blijf op de hoogte van nieuwe ontwikkelingen die huidige tekortkomingen kunnen aanpakken en zelfs groter potentieel voor deze transformerende technologie kunnen ontsluiten.
Oproep tot Actie
Omarm de kracht van Vision Language Models door AnyParser gratis uit te proberen om je PDF's naar Google Sheets te converteren op https://www.cambioml.com/sandbox. Krijg een gratis consult over hoe VLM's je gegevensextractieworkflow kunnen verbeteren.